 如何通過explain來驗證sql的執行順序
如何通過explain來驗證sql的執行順序
關于 sql 語句的執行順序網上有很多資料,但是大多都沒進行驗證,并且很多都有點小錯誤,尤其是對于 select 和 group by 執行的先后順序,有說 select 先執行,有說 group by 先執行,到底它倆誰先執行呢?
今天我們通過 explain 來驗證下 sql 的執行順序。
在驗證之前,先說結論,Hive 中 sql 語句的執行順序如下:
from 。. where 。. join 。. on 。. select 。. group by 。. select 。. having 。. distinct 。. order by 。. limit 。. union/union all
可以看到 group by 是在兩個 select 之間,我們知道 Hive 是默認開啟 map 端的 group by 分組的,所以在 map 端是 select 先執行,在 reduce 端是 group by先執行。
下面我們通過一個 sql 語句分析下:
select
sum(b.order_amount) sum_amount,
count(a.userkey) count_user
from user_info a
left join user_order b
on a.idno=b.idno
where a.idno 》 ‘112233’group by a.idno
having count_user》1limit 10;
上面這條 sql 語句是可以成功執行的,我們看下它在 MR 中的執行順序:
Map 階段:
執行 from,進行表的查找與加載;
執行 where,注意:sql 語句中 left join 寫在 where 之前的,但是實際執行先執行 where 操作,因為 Hive 會對語句進行優化,如果符合謂詞下推規則,將進行謂詞下推;
執行 left join 操作,按照 key 進行表的關聯;
執行輸出列的操作,注意: select 后面只有兩個字段(order_amount,userkey),此時 Hive 是否只輸出這兩個字段呢,當然不是,因為 group by 的是 idno,如果只輸出 select 的兩個字段,后面 group by 將沒有辦法對 idno 進行分組,所以此時輸出的字段有三個:idno,order_amount,userkey;
執行 map 端的 group by,此時的分組方式采用的是哈希分組,按照 idno 分組,進行order_amount 的 sum 操作和 userkey 的 count 操作,最后按照 idno 進行排序(group by 默認會附帶排序操作);
Reduce 階段:
執行 reduce 端的 group by,此時的分組方式采用的是合并分組,對 map 端發來的數據按照 idno 進行分組合并,同時進行聚合操作 sum(order_amount)和 count(userkey);
執行 select,此時輸出的就只有 select 的兩個字段:sum(order_amount) as sum_amount,count(userkey) as count_user;
執行 having,此時才開始執行 group by 后的 having 操作,對 count_user 進行過濾,注意:因為上一步輸出的只有 select 的兩個字段了,所以 having 的過濾字段只能是這兩個字段;
執行 limit,限制輸出的行數為 10。
上面這個執行順序到底對不對呢,我們可以通過 explain 執行計劃來看下,內容過多,我們分階段來看。
首先看下 sql 語句的執行依賴:

我們看到 Stage-5 是根,也就是最先執行 Stage-5,Stage-2 依賴 Stage-5,Stage-0 依賴 Stage-2。
首先執行 Stage-5:
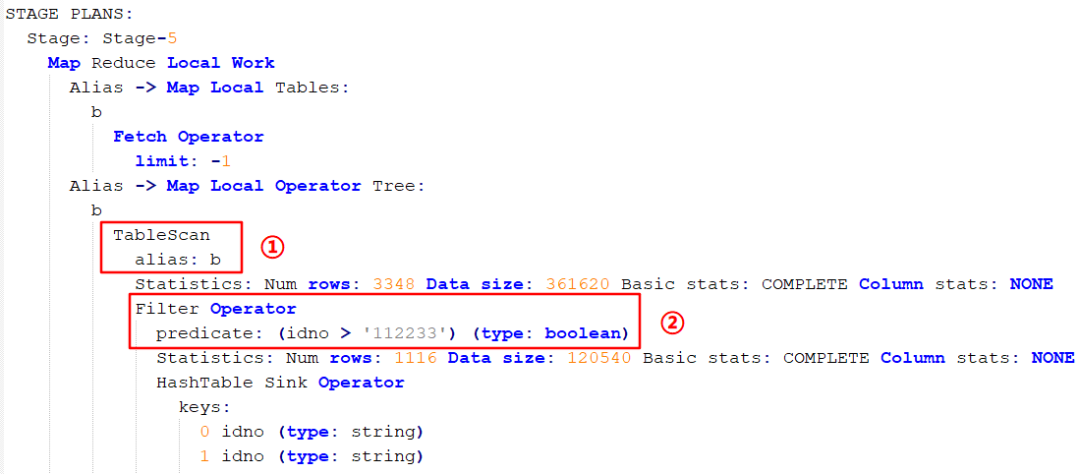
圖中標 ① 處是表掃描操作,注意先掃描的 b 表,也就是 left join 后面的表,然后進行過濾操作(圖中標 ② 處),我們 sql 語句中是對 a 表進行的過濾,但是 Hive 也會自動對 b 表進行相同的過濾操作,這樣可以減少關聯的數據量。
接下來執行 Stage-2:
首先是 Map 端操作:
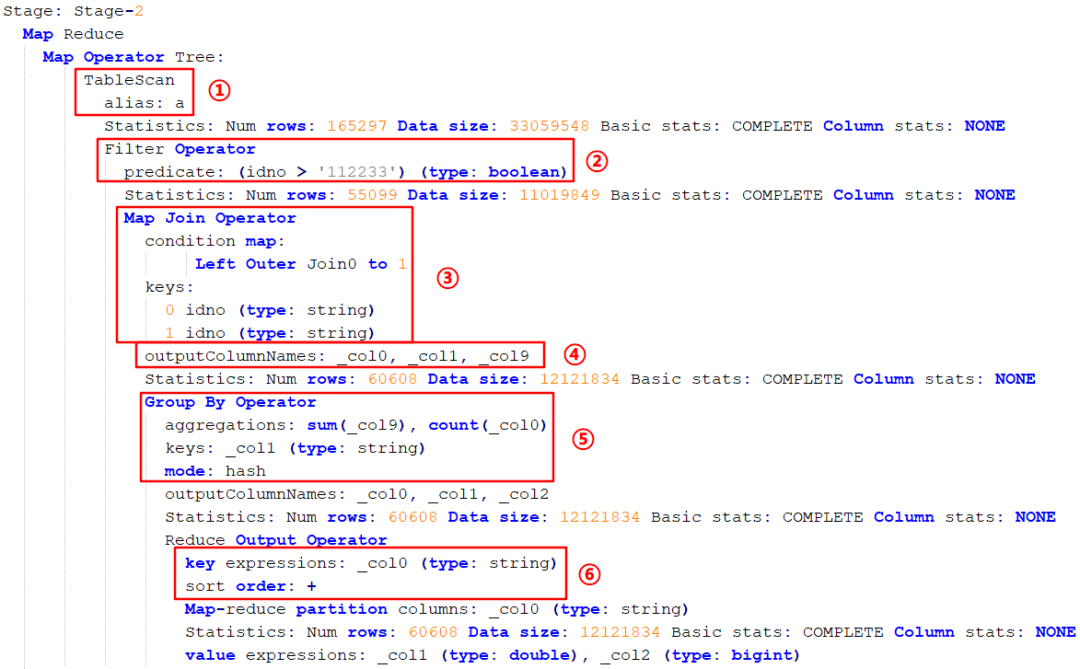
先掃描 a 表(圖中標 ① 處);接下來進行過濾操作 idno 》 ‘112233’(圖中標 ② 處);然后進行 left join,關聯的 key 是 idno(圖中標 ③ 處);執行完關聯操作之后會進行輸出操作,輸出的是三個字段,包括 select 的兩個字段加 group by 的一個字段(圖中標 ④ 處);然后進行 group by 操作,分組方式是 hash(圖中標 ⑤ 處);然后進行排序操作,按照 idno 進行正向排序(圖中標 ⑥ 處)。
然后是 Reduce 端操作:

首先進行 group by 操作,注意此時的分組方式是 mergepartial 合并分組(圖中標 ① 處);然后進行 select 操作,此時輸出的字段只有兩個了,輸出的行數是 30304 行(圖中標 ② 處);接下來執行 having 的過濾操作,過濾出 count_user》1 的字段,輸出的行數是 10101 行(圖中標 ③ 處);然后進行 limit 限制輸出的行數(圖中標 ④ 處);圖中標 ⑤ 處表示是否對文件壓縮,false 不壓縮。
執行計劃中的數據量只是預測的數據量,不是真實運行的,所以數據可能不準!
最后是 Stage-0 階段:

限制最終輸出的行數為 10 行。
總結
通過上面對 SQL 執行計劃的分析,總結以下幾點:
每個 stage 都是一個獨立的 MR,復雜的 hive sql 語句可以產生多個 stage,可以通過執行計劃的描述,看看具體步驟是什么。
對于 group by 的 key,必須是表中的字段,對于 having 的 key,必須是 select 的字段。
order by 是在 select 后執行的,所以 order by 的 key 必須是 select 的字段。
select 最好指明字段,select * 會增加很多不必要的消耗(CPU、IO、內存、網絡帶寬)。
責任編輯:haq
-
SQL
+關注
關注
1文章
767瀏覽量
44173 -
數據庫
+關注
關注
7文章
3821瀏覽量
64506
原文標題:Hive SQL 語句的正確執行順序
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
通過Skyvia Connect SQL終端節點訪問任何數據
淺談SQL優化小技巧
常用SQL函數及其用法
SQL與NoSQL的區別
大數據從業者必知必會的Hive SQL調優技巧
IP 地址在 SQL 注入攻擊中的作用及防范策略
如何在SQL中創建觸發器
什么是 Flink SQL 解決不了的問題?
SQL全外連接剖析
為什么需要監控SQL服務器?
plc梯形圖順序執行的原則是什么
觸發器的觸發順序是什么

查詢SQL在mysql內部是如何執行?





 工商網監
工商網監
評論