") STMCube.AI的高級特性
STMCube.AI的高級特性
STM32Cube.AI是意法半導體AI生態(tài)系統(tǒng)的一部分,是STM32Cube的一個擴展包,它可以自動轉換和優(yōu)化預先訓練的神經(jīng)網(wǎng)絡模型并將生成的優(yōu)化庫集成到用戶項目中,從而擴展了STM32CubeMX的功能。它還提供幾種在桌面PC和STM32上驗證神經(jīng)網(wǎng)絡模型以及測量模型性能的方法,而無需用戶手工編寫專門的C語言代碼。
上一篇文章大致介紹了STMCube.AI的基本特性,以及其工作流程。
本文將更深入地介紹它的一些高級特性。將涉及以下主題:
運行時環(huán)境支持:Cube.AI vs TensorFlow Lite
量化支持
圖形流與存儲布局優(yōu)化
可重定位的二進制模型支持
運行時環(huán)境支持:Cube.AI vs TensorFlow Lite
STM32Cube.AI支持兩種針對不同應用需求的運行時環(huán)境:Cube.AI和TensorFlow Lite。作為默認的運行時環(huán)境,Cube.AI是專為STM32高度優(yōu)化的機器學習庫。而TensorFlow Lite for Microcontroller是由谷歌設計,用于在各種微控制器或其他只有幾KB存儲空間的設備上運行機器學習模型的。其被廣泛應用于基于MCU的應用場景。STM32Cube.AI集成了一個特定的流程,可以生成一個即時可用的STM32 IDE項目,該項目內(nèi)嵌TensorFlow Lite for Microcontrollers運行時環(huán)境(TFLm)以及相關的TFLite模型。這可以被看作是Cube.AI運行時環(huán)境的一個替代方案,讓那些希望擁有一個跨多個項目的通用框架的開發(fā)人員也有了選擇。
雖然這兩種運行時環(huán)境都是為資源有限的MCU而設計,但Cube.AI在此基礎上針對STM32的獨特架構進行了進一步優(yōu)化。因此,TensorFlow Lite更適合有跨平臺可移植性需求的應用,而Cube.AI則更適合對計算速度和內(nèi)存消耗有更高要求的應用。
下表展示了兩個運行時環(huán)境之間的性能比較(基于一個預訓練的神經(jīng)網(wǎng)絡參考模型)。評價指標是在STM32上的推斷時間和內(nèi)存消耗。
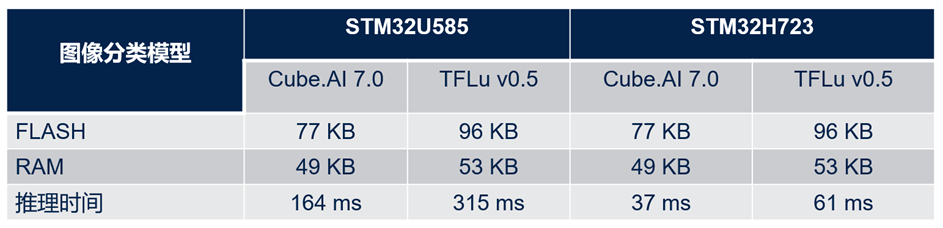
如表中所示,對于同一模型,Cube.AI運行時環(huán)境比TFLite運行時環(huán)境節(jié)約了大概20%的flash存儲和約8%的RAM存儲。此外,它的運行速度幾乎比TFLite運行時環(huán)境快了2倍。
對于TFLite模型,用戶可以在STM32Cube.AI的網(wǎng)絡配置菜單中對2個運行時環(huán)境進行選擇。
量化支持
量化是一種被廣泛使用的優(yōu)化技術,它將32位浮點模型壓縮為位數(shù)更少的整數(shù)模型,在精度只略微下降的情況下,減少了存儲大小和運行時的內(nèi)存峰值占用,也減少了CPU/MCU的推斷時間和功耗。量化模型對整數(shù)張量而不是浮點張量執(zhí)行部分或全部操作。它是面向拓撲、特征映射縮減、剪枝、權重壓縮等各種優(yōu)化技術的重要組成部分,可應用在像MCU一樣資源受限的運行時環(huán)境。
通常有兩種典型的量化方法:訓練后量化(PTQ)和量化訓練(QAT)。PTQ相對容易實現(xiàn),它可以用有限的具有代表性的數(shù)據(jù)集來量化預先訓練好的模型。而QAT是在訓練過程中完成的,通常具有更高的準確度。
STM32Cube.AI通過兩種不同的方式直接或間接地支持這兩種量化方法:
首先,它可以用來部署一個由PTQ或QAT過程生成的TensorFlow Lite量化模型。在這種情況下,量化是由TensorFlow Lite框架完成的,主要是通過“TFLite converter” utility導出TensorFlow Lite文件。
其次,其命令行接口(CLI)還集成了一個內(nèi)部的訓練后量化(PTQ)的過程,支持使用不同的量化方案對預訓練好的Keras模型進行量化。與使用TFLite Converter工具相比,該內(nèi)部量化過程提供了更多的量化方案,并在執(zhí)行時間和精確度方面有更好的表現(xiàn)。
下表顯示了在STM32上部署量化模型(與原有浮點模型相比)的好處。此表使用FD-MobileNet作為基準模型,共有12層,參數(shù)大小145k,MACC操作數(shù)24M,輸入尺寸為224x224x3。
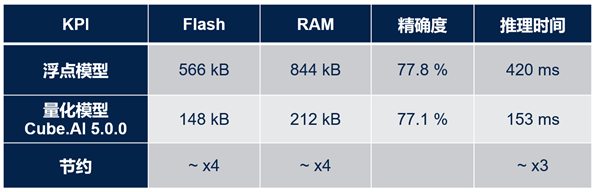
從表中很容易看出,量化模型節(jié)省了約4倍的flash存儲和RAM存儲,且運行速度提高了約3倍,而精確度僅僅下降了0.7%。
如果已經(jīng)安裝了X-Cube-AI包,用戶可以通過以下路徑找到關于如何使用命令行界面(CLI)進行量化的教程:
C:UsersusernameSTM32CubeRepositoryPacksSTMicroelectronicsX-CUBE-AI7.0.0Documentationquantization.html。
在文檔的末尾還附上了一個快速實踐示例:“量化一個MNIST模型”。
圖形流與存儲布局優(yōu)化
除了量化技術,STM32Cube.AI還通過使用其C代碼生成器的優(yōu)化引擎,針對推理時間優(yōu)化內(nèi)存使用(RAM & ROM)。該引擎基于無數(shù)據(jù)集的方法,無需驗證或測試數(shù)據(jù)集來應用壓縮和優(yōu)化算法。
第一種方法:權重/偏置項壓縮,采用k -均值聚類算法。該壓縮算法僅適用于全連接層。其優(yōu)勢是壓縮速度快,但是結果并不是無損的,最終的精度可能會受到影響。STM32Cube.AI提供“驗證”功能,用于對所生成的C模型中產(chǎn)生的誤差進行評估。
“壓縮”選項可以在STM32Cube.AI的網(wǎng)絡配置中激活,如下圖所示:
第二種方法:操作融合,通過合并層來優(yōu)化數(shù)據(jù)布局和相關的計算核。轉換或優(yōu)化過程中會刪除一些層(如“Dropout”、“Reshape”),而有些層(如非線性層以及卷積層之后的池化層)會被融合到前一層中。其好處是轉換后的網(wǎng)絡通常比原始網(wǎng)絡層數(shù)少,降低了存儲器中的數(shù)據(jù)吞吐需求。
最后一種方法是優(yōu)化的激活項存儲。其在內(nèi)存中定義一個讀寫塊來存儲臨時的隱藏層值(激活函數(shù)的輸出)。此讀寫塊可以被視為推理函數(shù)使用的暫存緩沖區(qū),在不同層之間被重復使用。因此,激活緩沖區(qū)的大小由幾個連續(xù)層的最大存儲需求決定。比如,假設有一個3層的神經(jīng)網(wǎng)絡,每一層的激活值分別有5KB, 12KB和3KB,那么優(yōu)化后的激活緩沖區(qū)大小將是12KB,而不是20KB。
可重定位的二進制模型支持
非可重定位方法(或“靜態(tài)”方法)指的是:生成的神經(jīng)網(wǎng)絡C文件被編譯并與最終用戶應用程序堆棧靜態(tài)鏈接在一起。
如下圖所示,所有對象(包括神經(jīng)網(wǎng)絡部分和用戶應用程序)根據(jù)不同的數(shù)據(jù)類型被一起鏈接到不同的部分。在這種情況下,當用戶想要對功能進行部分更新時(比如只更新神經(jīng)網(wǎng)絡部分),將需要對整個固件進行更新。
相反,可重定位二進制模型指定一個二進制對象,該對象可以安裝和執(zhí)行在STM32內(nèi)存子系統(tǒng)的任何位置。它是所生成的神經(jīng)網(wǎng)絡C文件的編譯后的版本,包括前向核函數(shù)以及權重。其主要目的是提供一種靈活的方法來更新AI相關的應用程序,而無需重新生成和刷寫整個終端用戶固件。
生成的二進制對象是一個輕量級插件。它可以從任何地址(位置無關的代碼)運行,其數(shù)據(jù)也可放置于內(nèi)存中的任何地方(位置無關的數(shù)據(jù))。
STM32Cube.AI簡單而高效的AI可重定位運行時環(huán)境可以將其實例化并使用它。STM32固件中沒有內(nèi)嵌復雜的資源消耗型動態(tài)鏈接器,其生成的對象是一個獨立的實體,運行時不需要任何外部變量或函數(shù)。
下圖的左側部分是神經(jīng)網(wǎng)絡的可重定位二進制對象,它是一個自給自足的獨立實體,鏈接時將被放置于終端用戶應用程序的一個單獨區(qū)域中(右側部分)。它可以通過STM32Cube.AI的可重定位運行時環(huán)境被實例化以及動態(tài)鏈接。因此,用戶在更新AI模型時只需要更新這部分二進制文件。另外,如果有進一步的靈活性需求,神經(jīng)網(wǎng)絡的權重也可以選擇性地被生成為獨立的目標文件。
可重定位網(wǎng)絡可以在STM32Cube.AI的高級設置中激活
最后,作為意法半導體人工智能生態(tài)系統(tǒng)的核心工具,STM32Cube.AI提供許多基本和高級功能,以幫助用戶輕松創(chuàng)建高度優(yōu)化和靈活的人工智能應用。如需詳細了解特定解決方案或技術細節(jié),請隨時關注我們的后續(xù)文章。
責任編輯:haq
-
mcu
+關注
關注
146文章
17263瀏覽量
351973 -
STM32
+關注
關注
2270文章
10918瀏覽量
356803 -
AI
+關注
關注
87文章
31325瀏覽量
269671 -
模型
+關注
關注
1文章
3279瀏覽量
48980
原文標題:AI技術專題之五:專為STM32 MCU優(yōu)化的STM32Cube.AI庫
文章出處:【微信號:STMChina,微信公眾號:意法半導體中國】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
【書籍評測活動NO.55】AI Agent應用與項目實戰(zhàn)
數(shù)字電機控制的未來:一個MCU上的多個電機、嵌入式AI和高級算法


昆侖萬維天工AI發(fā)布升級版AI高級搜索功能
《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第二章AI for Science的技術支撐學習心得
安達發(fā)|APS高級排程高級物料需求計劃

下一代高功能新一代AI加速器(DRP-AI3):10x在高級AI系統(tǒng)高級AI中更快的嵌入處理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論