 什么是DPU 未來的DPU智能?卡硬件形態
什么是DPU 未來的DPU智能?卡硬件形態
1.什么是DPU
DPU(Data Processing Unit)是以數據為中心構造的專用處理器,采用軟件定義技術路線支撐基礎設施層資源虛擬化,支持存儲、安全、服務質量管理等 基礎設施層服務。2020年NVIDIA公司發布的DPU產品戰略中將其定位為數據中心繼CPU和GPU之后的“第三顆主力芯片”,掀起了一波行業熱潮。DPU的出現是異構計算的一個階段性標志。與GPU的發展類似,DPU是應用驅動的體系結構設計的又一典型案例;但與GPU不同的是,DPU面向的應用更加底層。DPU要解決的核心問題是基礎設施的“降本增效”,即將“CPU處理效率低 下、GPU處理不了”的負載卸載到專用DPU,提升整個計算系統的效率、降低 整體系統的總體擁有成本(TCO)。DPU的出現也許是體系結構朝著專用化路線發展的又一個里程碑。
關于DPU中“D”的解釋
DPU中的“D”有三種解釋:
(1)Data Processing Unit,即數據處理器。這種解釋把“數據”放在核心 位置,區別于信號處理器、基帶處理器等通信相關的處理器對應的“信號”, 也區別于GPU對應的圖形圖像類數據,這里的“數據”主要指數字化以后的各 種信息,特別是各種時序化、結構化的數據,比如大型的結構化表格,網絡流 中的數據包,海量的文本等等。DPU就是處理這類數據的專用引擎。
(2)Datacenter Processing Unit,即數據中心處理器。這種解釋把數據中心作為DPU的應用場景,特別是隨著WSC(Warehouse-scale Computer)的興起, 不同規模的數據中心成為了IT核心基礎設施。目前來看,DPU確實在數據中心 中使用前景非常廣闊。但是計算中心的三大部分:計算、網絡、存儲,計算部分是CPU占主導,GPU輔助;網絡部分是路由器和交換機,存儲部分是高密度 磁盤構成的的RAID系統和SSD為代表非易失性存儲系統。在計算和網絡中扮演 數據處理的芯片都可以稱之為Datacenter Processing Unit,所以這種說法相對比 較片面。
(3)Data-centric Processing Unit,即以數據為中心的處理器。Data-centric,即數據為中心,是處理器設計的一種理念,相對于“Control-centric”即控制為 中心。經典的馮諾依曼體系結構就是典型的控制為中心的結構,在馮諾依曼經 典計算模型中有控制器、計算器、存儲器、輸入和輸出,在指令系統中的表現 是具有一系列非常復雜的條件跳轉和尋址指令。而數據為中心的理念與數據流 (Data Flow)計算一脈相承,是一種實現高效計算的方法。同時,現在試圖打 破訪存墻(Memory Wall)的各種近存(Near-memory)計算、存內(Inmemory)計算、存算一體等技術路線,也符合數據為中心的設計理念。
以上三種關于“D”的解釋,從不同角度反映DPU的特征,都有一定的可取之處,筆者認為可以作為不同的三個維度來理解DPU的內涵。
DPU的作用
DPU最直接的作用是作為CPU的卸載引擎,接管網絡虛擬化、硬件資源池 化等基礎設施層服務,釋放CPU的算力到上層應用。以網絡協議處理為例,要 線速處理10G的網絡需要的大約4個Xeon CPU的核,也就是說,單是做網絡數據包處理,就可以占去一個8核高端CPU一半的算力。如果考慮40G、100G的高速網絡,性能的開銷就更加難以承受了。Amazon把這些開銷都稱之為 “Datacenter Tax”,即還未運行業務程序,先接入網絡數據就要占去的計算資源。AWS Nitro產品家族旨在將數據中心開銷(為虛擬機提供遠程資源,加密解密,故障跟蹤,安全策略等服務程序)全部從CPU卸載到Nitro加速卡上,將給上層應用釋放30%的原本用于支付“Tax”的算力!
DPU可以成為新的數據網關,將安全隱私提升到一個新的高度。在網絡環境下,網絡接口是理想的隱私的邊界,但是加密、解密算法開銷都很大,例如 國密標準的非對稱加密算法SM2、哈希算法SM3和對稱分組密碼算法SM4。如果用CPU來處理,就只能做少部分數據量的加密。在未來,隨著區塊鏈承載的業務的逐漸成熟,運行共識算法POW,驗簽等也會消耗掉大量的CPU算力。而這些都可以通過將其固化在DPU中來實現,甚至DPU將成為一個可信根。
DPU也可以成為存儲的入口,將分布式的存儲和遠程訪問本地化。隨著 SSD性價比逐漸可接受,部分存儲遷移到SSD器件上已經成為可能,傳統的面向 機械硬盤的SATA協議并不適用于SSD存儲,所以,將SSD通過本地PCIe或高速 網絡接入系統就成為必選的技術路線。NVMe(Non Volatile Memory Express) 就是用于接入SSD存儲的高速接口標準協議,可以通過PCIe作為底層傳輸協議,將SSD的帶寬優勢充分發揮出來。同時,在分布式系統中,還可通過NVMe over Fabrics(NVMe-oF)協議擴展到InfiniBand、Ethernet、或Fibre channel節點中,以RDMA的形式實現存儲的共享和遠程訪問。這些新的協議處理都可以集成在DPU中以實現對CPU的透明處理。進而,DPU將可能承接各種互連協議控制器的角色,在靈活性和性能方面達到一個更優的平衡點。
DPU將成為算法加速的沙盒,成為最靈活的加速器載體。DPU不完全是一顆固化的ASIC,在CXL、CCIX等標準組織所倡導CPU、GPU與DPU等數據一致性訪問協議的鋪墊下,將更進一步掃清DPU編程障礙,結合FPGA等可編程器件,可定制硬件將有更大的發揮空間,“軟件硬件化”將成為常態,異構計算 的潛能將因各種DPU的普及而徹底發揮出來。在出現“Killer Application”的領域都有可能出現與之相對應的DPU,諸如傳統數據庫應用如OLAP、OLTP, 5G 邊緣計算,智能駕駛V2X等等。
2.DPU的發展背景
DPU的出現是異構計算的又一個階段性標志。摩爾定律放緩使得通用CPU 性能增長的邊際成本迅速上升,數據表明現在CPU的性能年化增長(面積歸一 化之后)僅有3%左右1,但計算需求卻是爆發性增長,這幾乎是所有專用計算芯片得以發展的重要背景因素。以AI芯片為例,最新的GPT-3等千億級參數的超大型模型的出現,將算力需求推向了一個新的高度。DPU也不例外。隨著2019年我國以信息網絡等新型基礎設施為代表的“新基建”戰略帷幕的拉開,5G、千兆光纖網絡建設發展迅速,移動互聯網、工業互聯網、車聯網等領域發展日新月異。云計算、數據中心、智算中心等基礎設施快速擴容。網絡帶寬從主流 10G朝著25G、40G、100G、200G甚至400G發展。網絡帶寬和連接數的劇增使得數據的通路更寬、更密,直接將處于端、邊、云各處的計算節點暴露在了劇增的數據量下,而CPU的性能增長率與數據量增長率出現了顯著的“剪刀差”現象。所以,尋求效率更高的計算芯片就成為了業界的共識。DPU芯片就是在這樣的趨勢下提出的。
帶寬性能增速比(RBP)失調
摩爾定律的放緩與全球數據量的爆發這個正在迅速激化的矛盾通常被作為處理器專用化的大背景,正所謂硅的摩爾定律雖然已經明顯放緩,但“數據摩爾定律”已然到來。IDC的數據顯示,全球數據量在過去10年年均復合增長率接近50%,并進一步預測每四個月對于算力的需求就會翻一倍。因此必須要找到新的可以比通用處理器帶來更快算力增長的計算芯片,DPU于是應運而生。這個大背景雖然有一定的合理性,但是還是過于模糊,并沒有回答DPU之所以新的原因是什么,是什么“量變”導致了“質變”?
從現在已經公布的各個廠商的DPU架構來看,雖然結構有所差異,但都不約而同強調網絡處理能力。從這個角度看,DPU是一個強IO型的芯片,這也是 DPU與CPU最大的區別。CPU的IO性能主要體現在高速前端總線(在Intel的體系里稱之為FSB,Front Side Bus),CPU通過FSB連接北橋芯片組,然后連接到主存系統和其他高速外設(主要是PCIe設備)。目前更新的CPU雖然通過集成 存儲控制器等手段弱化了北橋芯片的作用,但本質是不變的。CPU對于處理網絡處理的能力體現在網卡接入鏈路層數據幀,然后通過操作系統(OS)內核態,發起DMA中斷響應,調用相應的協議解析程序,獲得網絡傳輸的數據(雖然也有不通過內核態中斷,直接在用戶態通過輪詢獲得網絡數據的技術,如Intel的DPDK,Xilinx的Onload等,但目的是降低中斷的開銷,降低內核態到用戶態的切換開銷,并沒有從根本上增強IO性能)。可見,CPU是通過非常間接 的手段來支持網絡IO,CPU的前端總線帶寬也主要是要匹配主存(特別是 DDR)的帶寬,而不是網絡IO的帶寬。
相較而言,DPU的IO帶寬幾乎可以與網絡帶寬等同,例如,網絡支持 25G,那么DPU就要支持25G。從這個意義上看,DPU繼承了網卡芯片的一些特 征,但是不同于網卡芯片,DPU不僅僅是為了解析鏈路層的數據幀,而是要做直接的數據內容的處理,進行復雜的計算。所以,DPU是在支持強IO基礎上的具備強算力的芯片。簡言之,DPU是一個IO密集型的芯片;相較而言,DPU還是一個計算密集型芯片。
進一步地,通過比較網絡帶寬的增長趨勢和通用CPU性能增長趨勢,能發現一個有趣的現象:帶寬性能增速比(RBP,Ratio of Bandwidth and Performance growth rate)失調。RBP定義為網絡帶寬的增速比上CPU性能增速, 即RBP=BW GR/Perf. GR如圖1-1所示,以Mellanox的ConnectX系列網卡帶寬作為網絡IO的案例,以Intel的系列產品性能作為CPU的案例,定義一個新指標“帶 寬性能增速比”來反應趨勢的變化。
2010年前,網絡的帶寬年化增長大約是30%,到2015年微增到35%,然后在 近年達到45%。相對應的,CPU的性能增長從10年前的23%,下降到12%,并在近年直接降低到3%。在這三個時間段內,RBP指標從1附近,上升到3,并在近年超過了10!如果在網絡帶寬增速與CPU性能增速近乎持平,RGR~1,IO壓力尚未顯現出來,那么當目前RBP達到10倍的情形下,CPU幾乎已經無法直接應對網絡帶寬的增速。RBP指標在近幾年劇增也許是DPU終于等到機會“橫空出世”的重要原因之一。
異構計算發展趨勢的助?
DPU首先作為計算卸載的引擎,直接效果是給CPU“減負”。DPU的部分功能可以在早期的TOE(TCP/IP Offloading Engine)中看到。正如其名,TOE 就是將CPU的處理TCP協議的任務“卸載”到網卡上。傳統的TCP軟件處理方式雖然層次清晰,但也逐漸成為網絡帶寬和延遲的瓶頸。軟件處理方式對CPU的占用,也影響了CPU處理其他應用的性能。TCP卸載引擎(TOE)技術,通過將TCP協議和IP協議的處理進程交由網絡接口控制器進行處理,在利用硬件加速為網絡時延和帶寬帶來提升的同時,顯著降低了 CPU 處理協議的壓力。具體有三個方面的優化:1)隔離網絡中斷,2)降低內存數據拷貝量,3)協議解析硬件化。這三個技術點逐漸發展成為現在數據平面計算的三個技術,也是DPU普遍需要支持的技術點。例如,NVMe協議,將中斷策略替換為輪詢策略,更充分的開發高速存儲介質的帶寬優勢;DPDK采用用戶態調用,開發“Kernelbypassing”機制,實現零拷貝(Zeor-Copy);在DPU中的面向特定應用的專用核,例如各種復雜的校驗和計算、數據包格式解析、查找表、IP安全(IPSec)的支持等,都可以視為協議處理的硬件化支持。所以,TOE基本可以被視為DPU的雛形。
延續TOE的思想,將更多的計算任務卸載至網卡側來處理,促進了智能網卡(SmartNIC)技術的發展。常見的智能網卡的基本結構是以高速網卡為基本 功能,外加一顆高性能的FPGA芯片作為計算的擴展,來實現用戶自定義的計算邏輯,達到計算加速的目的。然而,這種“網卡+FPGA”的模式并沒有將智能網卡變成一個絕對主流的計算設備,很多智能網卡產品被當作單純的FPGA加速卡來使用,在利用FPGA優勢的同時,也繼承了所有FPGA的局限性。DPU是對現有的SmartNIC的一個整合,能看到很多以往SmartNIC的影子,但明顯高于之前任何一個SmartNIC的定位。
Amazon的AWS在2013研發了Nitro產品,將數據中心開銷(為虛機提供遠程 資源,加密解密,故障跟蹤,安全策略等服務程序)全部放到專用加速器上執 行。Nitro架構采用輕量化Hypervisor配合定制化的硬件,將虛擬機的計算(主要是CPU和內存)和I/O(主要是網絡和存儲)子系統分離開來,通過PCIe總線連接,節省了30%的CPU資源。阿里云提出的X-Dragon系統架構,核心是MOC卡,有比較豐富的對外接口,也包括了計算資源、存儲資源和網絡資源。MOC卡的核心X-Dragon SOC,統一支持網絡,IO、存儲和外設的虛擬化,為虛擬機、裸金屬、容器云提供統一的資源池。
可見,DPU其實在行業內已經孕育已久,從早期的網絡協議處理卸載,到后續的網絡、存儲、虛擬化卸載,其帶來的作用還是非常顯著的,只不過在此 之前DPU“有實無名”,現在是時候邁上一個新的臺階了。
3.DPU發展歷程
隨著云平臺虛擬化技術的發展,智能網卡的發展基本可以分為三個階段(如圖1-2所示):
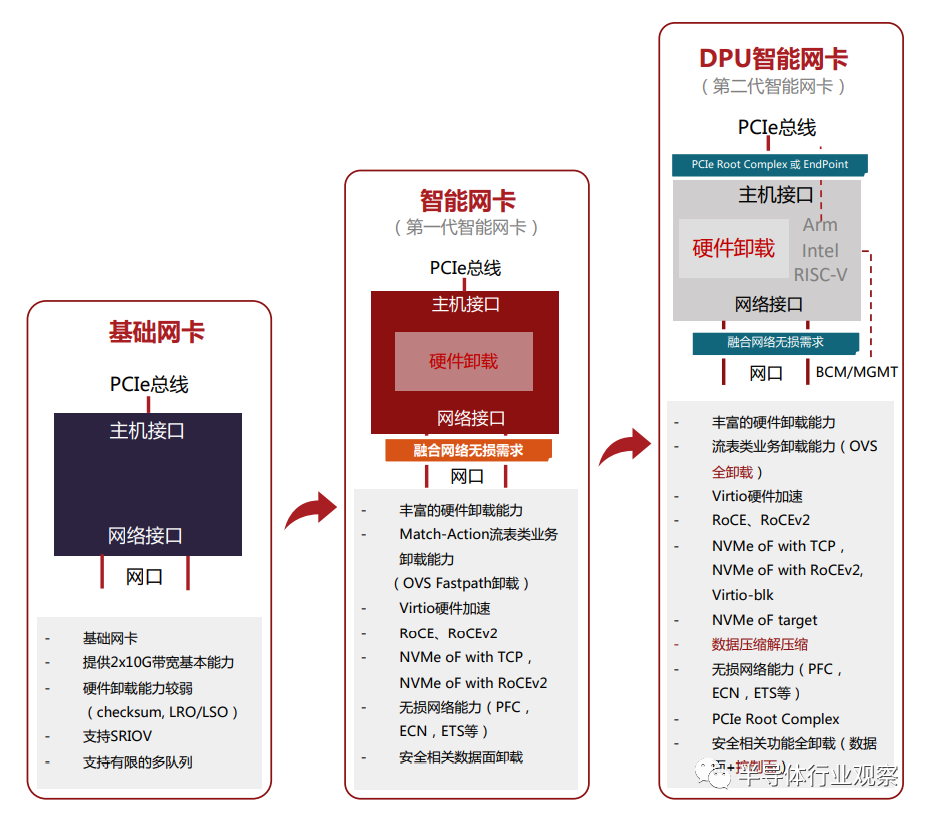
圖1-2 智能?卡發展的三個階段
第?階段:基礎功能?卡
基礎功能網卡(即普通網卡)提供2x10G或2x25G帶寬吞吐,具有較少的硬 件卸載能力,主要是Checksum,LRO/LSO等,支持SR-IOV,以及有限的多隊列能力。在云平臺虛擬化網絡中,基礎功能網卡向虛擬機(VM)提供網絡接入的方式主要是有三種:由操作系統內核驅動接管網卡并向虛擬機(VM)分發網絡 流量;由OVS-DPDK接管網卡并向虛擬機(VM)分發網絡流量;以及高性能場景下通過SR-IOV的方式向虛擬機(VM)提供網絡接入能力。
第?階段:硬件卸載?卡
可以認為是第一代智能網卡,具有豐富的硬件卸載能力,比較典型的有 OVS Fastpath硬件卸載,基于RoCEv1和RoCEv2的RDMA網絡硬件卸載,融合網 絡中無損網絡能力(PFC,ECN,ETS等)的硬件卸載,存儲領域NVMe-oF的硬件卸載,以及安全傳輸的數據面卸載等。這個時期的智能網卡以數據平面的卸載為主。
第三階段:DPU智能?卡
可以認為是第二代智能網卡,在第一代智能網卡基礎上加入CPU,可以用來卸載控制平面的任務和一些靈活復雜的數據平面任務。目前DPU智能網卡的 特點首先是支持PCIe Root Complex模式和Endpoint模式,在配置為PCIe Root Complex模式時,可以實現NVMe存儲控制器,與NVMe SSD磁盤一起構建存儲服務器;
另外,由于大規模的數據中心網絡的需要,對無損網絡的要求更加嚴格,需要解決數據中心網絡中Incast流量、“大象”流等帶來的網絡擁塞和時延問題,各大公有云廠商紛紛提出自己的應對方法,比如阿里云的高精度擁塞控制(HPCC,High Precision Congestion Control),AWS的可擴展可靠數據報(SRD,Scalable Reliable Datagram)等。
DPU智能網卡在解決這類問題時將會引入更為先進的方法,如Fungible的TrueFabric,就是在DPU智能網卡上的新式解決方案。還有,業界提出了Hypervisor中的網絡,存儲和安全全棧卸載的發展方向,以Intel為代表提出了IPU,將基礎設施的功能全部卸載到智能網卡中,可以全面釋放之前用于Hypervisor管理的CPU算力。
未來的DPU智能?卡硬件形態
隨著越來越多的功能加入到智能網卡中,其功率將很難限制在75W之內, 這樣就需要獨立的供電系統。所以,未來的智能網卡形態可能有三種形態:
(1)獨立供電的智能網卡,需要考慮網卡狀態與計算服務之間低層信號識 別,在計算系統啟動的過程中或者啟動之后,智能網卡是否已經是進入服務狀 態,這些都需要探索和解決。
(2)沒有PCIe接口的DPU智能網卡,可以組成DPU資源池,專門負責網絡 功能,例如負載均衡,訪問控制,防火墻設備等。管理軟件可以直接通過智能 網卡管理接口定義對應的網絡功能,并作為虛擬化網絡功能集群提供對應網絡 能力,無需PCIe接口。
(3)多PCIe接口,多網口的DPU芯片。例如Fungible F1芯片,支持16個雙 模PCIe控制器,可以配置為Root Complex模式或Endpoint模式,以及8x100G網絡 接口。通過PCIe Gen3 x8接口可以支撐8個Dual-Socket計算服務器,網絡側提供 8x100G帶寬的網口。
DPU作為一種新型的專用處理器,隨著需求側的變化,必將在未來計算系統中成為一個重要組成部分,對于支撐下一代數據中心起到至關重要的作用。
4.DPU與CPU、GPU的關系
CPU是整個IT生態的定義者,無論是服務器端的x86還是移動端的ARM,都 各自是構建了穩固的生態系統,不僅形成技術生態圈,還形成了閉合價值鏈。
GPU是執行規則計算的主力芯片,如圖形渲染。經過NVIDIA對通用GPU (GPGPU)和CUDA編程框架的推廣,GPU在數據并行的任務如圖形圖像、深度學習、矩陣運算等方面成為了主力算力引擎,并且成為了高性能計算最重要的輔助計算單元。2021年6月公布的Top500高性能計算機(超級計算機)的前10 名中,有六臺(第2、3、5、6、8、9名)都部署有NVIDIA的GPU。
數據中心與超極計算機不同,后者主要面向科學計算,如大飛機研制,石油勘探、新藥物研發、氣象預報、電磁環境計算等應用,性能是主要指標,對接入帶寬要求不高;但數據中心面向云計算商業化應用,對接入帶寬,可靠性、災備、彈性擴展等要求更高,與之相適應發展起來的虛擬機、容器云、并行編程框、內容分發網等等技術,都是為了更好的支撐上層商業應用如電商、支付、視頻流、網盤、辦公OA等。但是這些IaaS和PaaS層的服務開銷極大, Amazon曾公布AWS的系統開銷在30%以上。如果需要實現更好的QoS,在網絡、存儲、安全等基礎設施服務上的開銷還會更高。
這些基礎層應用類型與CPU架構匹配程度不高導致計算效率低下。現有的 CPU的架構有兩個大類:多核架構(數個或數十幾個核)和眾核架構(數百個核以上),每種架構支持唯一的規范通用指令集之一,如x86、ARM等。以指令集為界,軟件和硬件被劃分開來分別獨立發展,迅速的催生了軟件產業和微處理器產業的協同發展。但是,隨著軟件復雜度的上升,軟件的生產率 (Productivity)得到更多的重視,軟件工程學科也更加關注如何高效地構建大型軟件系統,而非如何用更少的硬件資源獲得盡可能高的執行性能。業界有個被戲稱的“安迪比爾定律”,其內容是“What Andy gives, Bill takes away”,安迪(Andy)指英特爾前CEO安迪·格魯夫,比爾(Bill)指微軟前任CEO比爾· 蓋茨,意為硬件提高的性能,很快被軟件消耗掉了。
正如CPU在處理圖像處理時不夠高效一樣,現在有大量的基礎層應用CPU處理起來也比較低效,例如網絡協議處理,交換路由計算,加密解密,數據壓 縮等這類計算密集的任務,還有支持分布式處理的數據一致性協議如RAFT等。這些數據或者通過從網絡IO接入系統,或者通過板級高速PCIe總線接入系統,再通過共享主存經由DMA機制將數據提供給CPU或GPU來處理。既要處理大量的上層應用,又要維持底層軟件的基礎設施,還要處理各種特殊的IO類協議,復雜的計算任務讓CPU不堪重負。
這些基礎層負載給“異構計算”提供了一個廣闊的發展空間。將這些基礎層負載從CPU上卸載下來,短期內可以“提質增效”,長遠來看還為新的業務增長提供技術保障。DPU將有望成為承接這些負載的代表性芯片,與CPU和 GPU優勢互補,建立起一個更加高效的算力平臺。可以預測,用于數據中心的DPU的量將達到和數據中心服務器等量的級別,每年千萬級新增,算上存量的替代,估算五年總體的需求量將突破兩億顆,超過獨立GPU卡的需求量。每臺服務器可能沒有GPU,但必須有DPU,好比每臺服務器都必須配網卡一樣。
5.DPU的產業化機遇
數據中心作為IT基礎設施最重要的組成部分在過去10年成為了各大高端芯片廠商關注的焦點。各大廠商都將原有的產品和技術,用全新的DPU的理念重 新封裝后,推向了市場。
NVIDIA收購Mellanox后,憑借原有的ConnectX系列高速網卡技術,推出其 BlueField系列DPU,成為DPU賽道的標桿。作為算法加速芯片頭部廠商的Xilinx 在2018年還將“數據中心優先(Datacenter First)”作為其全新發展戰略。發布了Alveo系列加速卡產品,旨在大幅提升云端和本地數據中心服務器性能。2019年4月,Xilinx宣布收購Solarflare通信公司,將領先的FPGA、MPSoC和ACAP解 決方案與 Solarflare 的超低時延網絡接口卡( NIC )技術以及應用加速軟件相結合,從而實現全新的融合SmartNIC解決方案。Intel 2015年底收購了Xilinx的競爭 對手——Altera,在通用處理器的基礎上,進一步完善硬件加速能力。Intel 2021年6月新發布的IPU產品(可以被視為Intel版本的DPU),將FPGA與Xeon D系列處理器集成,成為了DPU賽道有力的競爭者。IPU是具有強化的加速器和以太網連接的高級網絡設備,它使用緊密耦合、專用的可編程內核加速和管理基礎架構功能。IPU提供全面的基礎架構分載,并可作為運行基礎架構應用的主機的控制點,從而提供一層額外防護。幾乎同一時間,Marvall發布了OCTEON 10 DPU產品,不僅具備強大的轉發能力,還具有突出的AI處理能力。
在同一時期,一些傳統并不涉足芯片設計的互聯網廠商,如海外的Google、Amazon,國內的阿里巴巴等巨頭紛紛啟動了自研芯片的計劃,而且研發重點都是面向數據處理器的高性能專用處理器芯片,希望以此改善云端的服務器的成本結構,提高單位能耗的性能水平。數據研究預測DPU在云計算市場的應用需求最大,且市場規模隨著云計算數據中心的迭代而增長,到2025年單中國的市場容量都將達到40億美元的規模。
來源:本篇內容來自專用數據處理器(DPU)技術 白皮書,中國科學院計算技術研究所,鄢貴海等”。版權歸原作者所有
編輯:jq
-
DPU
+關注
關注
0文章
358瀏覽量
24181 -
PCIe
+關注
關注
15文章
1239瀏覽量
82655 -
智能網卡
+關注
關注
1文章
53瀏覽量
12235
原文標題:DPU技術發展概況
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
中科馭數分析DPU在云原生網絡與智算網絡中的實際應用
IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
中科馭數:DPU是構建高效智算中心基礎設施的必選項
中科馭數CEO鄢貴海:從計算系統的三個視角重新審視DPU的核心價值

芯片軟件全上陣 DPU“全家桶”來了!中科馭數成功舉辦2024產品發布會

中科馭數發布高性能DPU芯片K2-Pro
基于芯啟源NFP3800DPU芯片的深信服安全加速卡XSX40FNN網卡

NVIDIA DPU編程入門開課儀式在澳門科技大學成功舉辦
DPU技術賦能下一代AI算力基礎設施
明天線上見!DPU構建高性能云算力底座——DPU技術開放日最新議程公布!
中科馭數DPU技術開放日秀“肌肉”:云原生網絡、RDMA、安全加速、低延時網絡等方案組團亮相


KPU FLEXFLOW? -2100R是中科馭數完全自研的首款具備RDMA功能的DPU加速卡#RDMA
FPGA-Based DPU網卡的發展和應用
AMD Kria KR260 DPU配置教程2





 工商網監
工商網監
評論