 系統級芯片的指令集與運算架構詳解
系統級芯片的指令集與運算架構詳解
一、指令集

依據指令長度的不同,指令系統可分為復雜指令系統(Complex Instruction Set Computer,簡稱CISC )、精簡指令系統(Reduced Instruction Set Computer,簡稱 RISC)和超長指令字(Very Long Instruction Word,簡稱VLIW)指令集三種。CISC中的指令長度可變;RISC中的指令長度比較固定;VLIW本質上來講是多條同時執行的指令的組合,其“同時執行”的特征由編譯器指定,無須硬件進行判斷。超標量處理器是動態調度,由硬件發現指令級并行機會并負責正確調度,VLIW是靜態調度,由編譯器發現指令級并行機會并負責正確調度。
VLIW結構的最初思想是最大限度利用指令級并行(Instruction Level Parallelism,簡稱ILP),VLIW的一個超長指令字由多個互相不存在相關性(控制相關、數據相關等)的指令組成,可并行進行處理。VLIW可顯著簡化硬件實現,但增加了編譯器的設計難度。由于AI和DSP領域,數據基本上是數據流,沒有跳轉,因此特別適合靜態的VLIW,近期有不少AI芯片使用VLIW架構。
早期的CPU都采用CISC結構,如IBM的System360、Intel的8080和8086系列、Motorola的68000系列等。這與當時的時代特點有關,早期處理器設備昂貴且處理速度慢,設計者不得不加入越來越多的復雜指令來提高執行效率,部分復雜指令甚至可與高級語言中的操作直接對應。這種設計簡化了軟件和編譯器的設計,但也顯著提高了硬件的復雜性。
當硬件復雜度逐漸提高時,CISC結構出現了一系列問題。大量復雜指令在實際中很少用到,典型程序所使用的80%的指令只占指令集總指令數的20%,消耗大量精力的復雜設計只有很少的回報。同時,復雜的微代碼翻譯也會增加流水線設計難度,并降低頻繁使用的簡單指令的執行效率。針對CISC結構的缺點,RISC遵循簡化的核心思路。RISC簡化了指令功能,單個指令執行周期短;簡化了指令編碼,使得譯碼簡單;簡化了訪存類型,訪存只能通過load/store指令實現。RISC指令的設計精髓是簡化了指令間的關系,有利于實現高效的流水線、多發射等技術,從而提高主頻和效率。
RISC指令系統的最本質特征是通過load/store結構簡化了指令間關系,即所有運算指令都是對寄存器運算,所有訪存都通過專用的訪存指令(load/store)進行。這樣,CPU只要通過寄存器的比較就能判斷運算指令之間以及運算指令和訪存指令之間有沒有數據相關性,而較復雜的訪存指令相關判斷(需要對訪存的物理地址進行比較)則只在執行load/store指令的訪存部件上進行,從而大大簡化了指令間相關性判斷的復雜度,有利于CPU采用指令流水線、多發射、亂序執行等提高性能。因此,RISC不僅是一種指令系統類型,同時也是一種提高CPU性能的技術。X86處理器中將 CISC指令譯碼為類RISC的內部操作,然后對這些內部操作使用諸如超流水、亂序執行、多發射等高效實現手段。而以PowerPC為例的RISC處理器則包含了許多功能強大的指令。
RISC的設計初衷針對CISC CPU復雜的弊端,選擇一些可以在單個CPU周期完成的指令,以降低CPU的復雜度,將復雜性交給編譯器。舉個例子,CISC提供的乘法指令,調用時可完成內存a和內存b中的兩個數相乘,結果存入內存a,需要多個CPU周期才可以完成;而RISC不提供“一站式”的乘法指令,需調用四條單CPU周期指令完成兩數相乘:內存a加載到寄存器,內存b加載到寄存器,兩個寄存器中數相乘,寄存器結果存入內存a。按此思路,早期設計出的RISC指令集,指令數是比CISC少些,但后來,很多RISC的指令集中指令數反超了CISC,因此,引用指令的復雜度而非數量來區分兩種指令集。
CISC指令的格式長短不一,執行時的周期次數也不統一,而RISC結構剛好相反,它是定長的,故適合采用管線處理架構的設計,進而可以達到平均一周期完成一指令的方向努力。顯然,在設計上RISC較CISC簡單,同時因為CISC的執行步驟過多,閑置的單元電路等待時間增長,不利于平行處理的設計,所以就效能而言RISC較CISC還是站了上風,但RISC因指令精簡化后造成應用程式碼變大,需要較大的程式存儲空間,且存在指令種類較多等等的缺點。
對CPU內核結構的影響X86指令集早期通常只有8個通用寄存器。所以,CISC的CPU執行是大多數時間是在訪問存儲器中的數據,而不是寄存器中的。這就拖慢了整個系統的速度。RISC系統往往具有非常多的通用寄存器,早期多是27個,并采用了重疊寄存器窗口和寄存器堆等技術使寄存器資源得到充分的利用。
大部分情況下(90%)的時間內處理器都在運行少數的指令,其余的時間則運行各式各樣的復雜指令(復雜就意味著較長的運行時間),RISC就是將這些復雜的指令剔除掉,只留下最經常運行的指令(所謂的精簡指令集),然而被剔除掉的那些指令雖然實現起來比較麻煩,卻在某些領域確實有其價值,RISC的做法就是將這些麻煩都交給軟件,CISC的做法則是像現在這樣: 由硬件設計完成。因此RISC指令集對編譯器要求很高,而CISC則很簡單。對編程人員的要求也類似。
因此x86架構通常只需要一個復雜解碼器,簡單解碼器可以將一條x86指令(包括大部分SSE指令在內)翻譯為一條微指令(uop),而復雜解碼器則將一些特別的(單條)x86指令翻譯為1~4 條uops——在極少數的情況下,某些指令需通過額外的可編程microcode解碼器解碼為更多的uops (有時候甚至可達幾百個,因為一些IA指令很復雜,并且可以帶有很多的前綴/修改量,當然這種情況很少見)。
二、運算架構
馮諾伊曼架構與哈佛架構

馮諾伊曼架構與哈佛架構最大區別是存儲總線,馮諾依曼架構的指令和數據是共用一條總線,也就是說,不能同時讀取指令和數據,必須在時間序列上分開。哈佛架構是指令和數據用不同的總線,可以同時讀取指令和數據。
早期的計算機設計中,程序和數據是倆個截然不同的概念,數據放在存儲器中,而程序作為控制器的一部分,這樣的計算機計算效率低,靈活性較差。馮。諾依曼結構中,將程序和數據一樣看待,將程序編碼為數據,然后與數據一同存放在存儲器中,這樣計算機就可以調用存儲器中的程序來處理數據了。這意味著無論什么程序,最終都是會轉換為數據的形式存儲在存儲器中,要執行相應的程序只需要從存儲器中依次取出指令、執行,而無需再從控制器中取出,馮。諾依曼結構的靈魂所在正是這里:這種設計思想導致了硬件和軟件的分離,即硬件設計和程序設計可以分開執行。
現代計算架構中,整個計算架構通常都采用馮諾依曼架構,在CPU內部采用類哈佛架構,在現代CPU內部的一級緩存中,指令和數據是分開存儲的,但指令和數據的尋址空間address space還是共享的,這不能算嚴格的哈佛架構,但思路是哈佛架構的思路。
馮諾依曼詳細架構
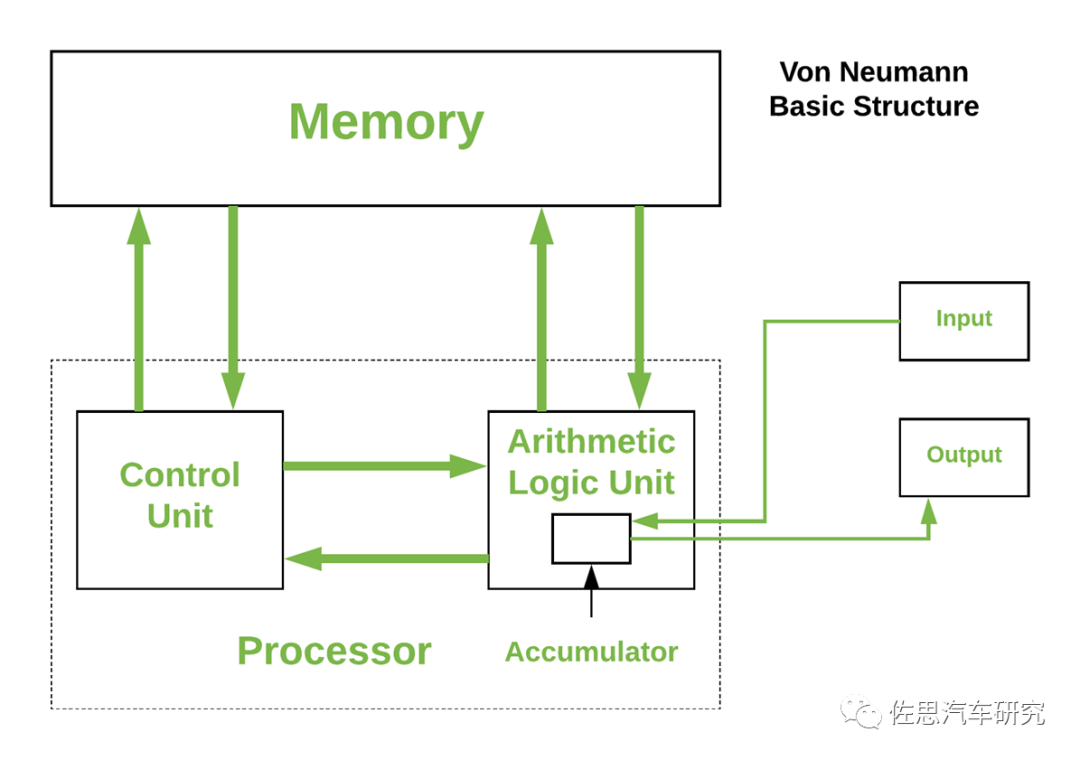
虛線框內再加上多級緩存就是現代意義上的CPU,鼠標鍵盤是輸入設備、顯示器是輸出設備;手機觸摸屏既是輸入設備又是輸出設備;服務器中網卡既是輸入設備又是輸出設備;所有的計算機程序都可以抽象為輸入設備讀取信息,通過CPU來執行存儲在存儲器中的程序,結果通過輸出設備反饋給用戶。
算術邏輯單元(Arithmetic Logic Unit,ALU)。ALU的主要功能就是在控制信號的作用下,完成加、減、乘、除等算術運算以及與、或、非、異或等邏輯運算以及移位、補位等運算。控制單元(Control Unit),是計算機的神經中樞和指揮中心,只有在控制器的控制下,整個計算機才能有條不紊地工作、自動執行程序。控制器的工作流程為:從內存中取指令、翻譯指令、分析指令,然后根據指令的內存向有關部件發送控制命令,控制相關部件執行指令所包含的操作。
計算機內部,程序和數據都是以二進制代碼的形式存儲的,均以字節為單位(8位)存儲在存儲器中,一個字節占用一個存儲單元,且每個存儲單元都有唯一的地址號。CPU可以直接使用指令對內部存儲器按照地址進行讀寫兩種操作,讀:將內存中某個存儲單元的內容讀出,送入CPU的某個寄存器中;寫:在控制器的控制下,將CPU中某寄存器內容傳到某個存儲單元中。要注意,內存中的數據和地址碼都是二進制數,但是倆者是不同的,一個地址碼可以指向一個存儲單元,地址是存儲單元的位置,數據是存儲單元的內容。地址碼的長度由內存單元的個數確定。
內存的存取速度會直接影響計算機的運算速度,由于CPU是高速器件,但是CPU的速度是受制于內存的存取速度的,所以為解決CPU與內存速度不匹配的問題,在CPU和內存直接設置了一種高速緩沖存儲器Cache。Cache是計算機中的一個高速小容量存儲器,其中存放的是CPU近期要執行的指令和數據,其存取速度可以和CPU的速度匹配,一般采用靜態RAM充當Cache即緩存。
內存按工作方式的不同又可以分為倆部分:RAM:隨機存儲器,可以被CPU隨機讀取,一般存放CPU將要執行的程序、數據,斷電丟失數據。ROM:只讀存儲器,只能被CPU讀,不能輕易被CPU寫,用來存放永久性的程序和數據,比如:系統引導程序、監控程序等。具有掉電非易失性。
哈佛架構
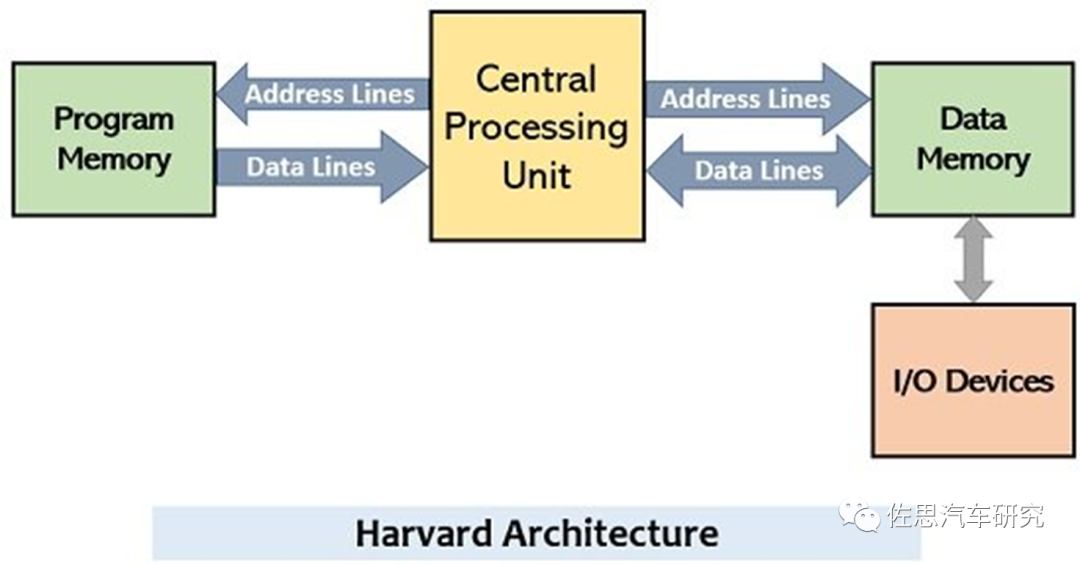
通常哈佛架構有四條總線,處理器與存儲器之間有兩條總線,一條是尋址,一條是數據,哈佛架構的指令(即編程Program)和數據分開存儲,也就是四條總線。
典型的哈佛架構是DSP,通常我們把馮諾依曼架構的處理器叫GPP,即通用型處理器。DSP是為單一密集計算任務如視頻編解碼、FIR濾波器,這些任務拆解到底層通常是乘法或乘積累加。DSP為了進行這些密集計算任務,添加了一些固定算法指令,比如單周期乘加指令、逆序加減指令(FFT時特別有用,不是ARM的那種逆序),塊重復指令(減少跳轉延時)等等,甚至將很多常用的由幾個操作組成的一個序列專門設計一個指令可以一周期完成(比如一指令作一個乘法,把結果累加,同時將操作數地址逆序加1),極大地提高了信號處理的速度。由于數字處理的讀數、回寫量非常大,為了提高速度,采用指令、數據空間分開的方式,以兩條總線來分別訪問兩個空間,同時,一般在DSP內部有高速RAM,數據和程序要先加載到高速片內RAM中才能運行。DSP為提高數字計算效率,犧牲了存儲器管理的方便性,對多任務的支持要差的多,所以DSP不適合于作多任務控制作用。
像乘積累加計算,早期GPP(通用處理器)處理一般是用加法代替乘法,要n多CPU周期,盡管CPU主頻很快,但還是要相當時間,所以早期CPU會特設一個乘法器專門做乘法。乘法都如此麻煩,乘積累加就更麻煩,通常做一次乘法會發生4次存儲器訪問,用掉至少四個指令周期。再做加法,再用掉兩個指令周期,而DSP只需要一個指令周期。
現在典型的高性能GPP實際上已包含兩個片內高速緩存,一個是數據,一個是指令,它們直接連接到處理器核,以加快運行時的訪問速度。從物理上說,這種片內的雙存儲器和總線的結構幾乎與哈佛結構的一樣了。然而從邏輯上講,兩者還是有重要的區別。GPP使用控制邏輯來決定哪些數據和指令字存儲在片內的高速緩存里,其程序員并不加以指定(也可能根本不知道)。與此相反,DSP使用多個片內存儲器和多組總線來保證每個指令周期內存儲器的多次訪問。在使用DSP時,程序員要明確地控制哪些數據和指令要存儲在片內存儲器中,哪些要放在片外。也就是說GPP的數據和指令程序員無法修改,有時可能出現錯誤,也會導致效率的下降,不過由于在一個尋址空間內,即便出現錯誤,帶來的后果也只是延遲,效率降低。而DSP不同,它是非常靈活的,可以保證任何狀況下效率都是最高,當然缺點是萬一數據和指令錯誤,可能會出現中斷乃至系統崩潰,因此DSP只能執行比較簡單純粹的任務。
程序員在寫程序時,必須保證處理器能夠有效地使用其雙總線。此外,DSP處理器幾乎都不具備數據高速緩存。這是因為DSP的典型數據是數據流。也就是說,DSP處理器對每個數據樣本做計算后,就丟棄了,幾乎不再重復使用。
DSP算法的一個共同的特點,即大多數的處理時間是花在執行較小的循環上,也就容易理解,為什么大多數的DSP都有專門的硬件,用于零開銷循環。所謂零開銷循環是指處理器在執行循環時,不用花時間去檢查循環計數器的值、條件轉移到循環的頂部、將循環計數器減1。與此相反,GPP的循環使用軟件來實現。某些高性能的GPP使用轉移預報硬件,幾乎達到與硬件支持的零開銷循環同樣的效果。
GPP的程序通常并不在意處理器的指令集是否容易使用,因為他們一般使用像C或C++等高級語言。而對于DSP的程序員來說,不幸的是主要的DSP應用程序都是用匯編語言寫的(至少部分是匯編語言優化的)。這里有兩個理由:首先,大多數廣泛使用的高級語言,例如C,并不適合于描述典型的DSP算法。其次,DSP結構的復雜性,如多存儲器空間、多總線、不規則的指令集、高度專門化的硬件等,使得難于為其編寫高效率的編譯器。即便用編譯器將C源代碼編譯成為DSP的匯編代碼,優化的任務仍然很重。典型的DSP應用都具有大量計算的要求,并有嚴格的開銷限制,使得程序的優化必不可少(至少是對程序的最關鍵部分)。因此,考慮選用DSP的一個關鍵因素是,是否存在足夠的能夠較好地適應DSP處理器指令集的程序員。
除DSP外,MCU一般也是哈佛架構,因為MCU所需要的數據和指令體積都很小,分開存儲也不會增加多少成本。MCU的運算能力一般較弱,運行頻率較低,一般只有幾十MHz到300MHz,因此運算需要高效率,馮諾依曼架構不適合。再有就是MCU一般是嵌入式系統,電池供電,對功耗要求高,需要低功耗,需要高效率的哈佛架構。
三、FPGA
大部分FPGA器件采用了查找表(Look Up Table,LUT)結構。查找表的原理類似于ROM,其物理結構是靜態存儲器(SRAM),N個輸入項的邏輯函數能夠由一個2^N位容量的SRAM實現, 函數值存放在SRAM中,SRAM的地址線起輸入線的作用,地址即輸入變量值,SRAM的輸出為邏輯函數值。由連線開關實現與其它功能塊的連接。
RAM基本的作用就是存儲代碼和數據供CPU在需要的時候調用。可是這些數據并非像用袋子盛米那么簡單。更像是圖書館中用有格子的書架存放書籍一樣。不但要放進去還要可以在需要的時候準確地調用出來。盡管都是書可是每本書是不同的。對于RAM等存儲器來說也是一樣的,盡管存儲的都是代表0和1的代碼,可是不同的組合就是不同的數據。讓我們又一次回到書和書架上來,假設有一個書架上有10行和10列格子(每行和每列都有0-9的編號),有100本書要存放在里面,那么我們使用一個行的編號+一個列的編號就能確定某一本書的位置。假設已知這本書的編號87,那么我們首先鎖定第8行。然后找到第7列就能準確的找到這本書了。
在RAM存儲器中也是利用了相似的原理。如今讓我們回到RAM存儲器上,對于RAM存儲器而言數據總線是用來傳入數據或者傳出數據的。由于存儲器中的存儲空間是假設前面提到的存放圖書的書架一樣通過一定的規則定義的,所以我們能夠通過這個規則來把數據存放到存儲器上相應的位置。而進行這樣的定位的工作就要依靠地址總線來實現了。對于CPU來說,RAM就像是一條長長的有非常多空格的細線。每一個空格都有一個唯一的地址與之相應。假設CPU想要從RAM中調用數據,首先需要給地址總線發送地址數據定位要存取的數據,然后等待若干個時鐘周期之后,數據總線就會把傳輸數據給CPU。
FPGA是基于邏輯門和觸發器的,它是并行執行方式,沒有取指到執行這種操作。簡單而言,就是通過燒寫文件去配置查找表的內容,從而在相同的電路情況下實現了不同的邏輯功能,數字電路中所有邏輯門和觸發器均可以實現,適合真正意義上的并行任務處理。FPGA程序在編譯后實際上是轉換為內部的連線表,相當于FPGA內部提供了大量的與非門、或非門、觸發器等基本數字邏輯器件,編程決定了有多少器件被使用以及它們之間的連接方式。通過編程,用戶可對FPGA內部的邏輯模塊和I/O模塊重新配置,以實現用戶的邏輯。它還具有靜態可重復編程和動態在系統重新配置的特性,使得硬件的功能可以像軟件一樣通過編程來修改。只要FPGA規模夠大,這些數字器件理論上能形成一切數字系統,包括MCU,甚至CPU。因FPGA是純數字電路,在抗干擾和速度性能上有很大優勢。
FPGA沒有取指到執行這種操作,效率極高,功耗很低,又是天生的并行計算結構。但是FPGA采用的是統計型連線結構。這類器件具有較復雜的可編程布線資源,內部包含多種長度的金屬連線,從而使片內互連十分靈活。因此每次編程后的連線可不盡相同。但是這些布線資源消耗了很大一部分芯片面積,而ASIC只需要選用最短長度的布線即可,面積大大縮小,同樣密度,ASIC大約可以縮小40%的面積,這就意味著FPGA比ASIC要貴40%左右,FPGA的算力達到一定程度后,再增加算力,價格會飛速增長。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19313瀏覽量
230054 -
FPGA
+關注
關注
1629文章
21748瀏覽量
603913 -
芯片
+關注
關注
456文章
50889瀏覽量
424242
原文標題:深入了解汽車系統級芯片SoC連載之五:指令集與運算架構
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CPU、架構、指令集與芯片的關系與區別

thumb指令集是什么_thumb指令集與arm指令集的區別

mips指令集指的是什么
指令集架構與開源架構
處理器架構與指令集
嵌入式系統的概念與范圍開發 指令集架構要怎么選才合適?






 工商網監
工商網監
評論