") sql優(yōu)化,一定要用好Explain
sql優(yōu)化,一定要用好Explain
Part1前言
- 環(huán)境:Mysql 8.0.21
- Mysql 版本不同 explain 執(zhí)行結(jié)果會不相同
Part2Explain的作用?
EXPLAIN 語句提供有關(guān)MySQL如何執(zhí)行語句的信息。EXPLAIN 可以作用于SELECT、DELETE、INSERT、REPLACE和UPDATE語句
explain 為 select語句中使用的每個表返回一行信息。它按 mysql 在處理語句時讀取的順序列出輸出的表。mysql 使用嵌套循環(huán)連接方法解析所有連接,這意味著 mysql 從第一個表中讀取一行,然后在第二個表中、第三個表中找到匹配的行,依此類推。處理完所有表后,Mysql 輸出所選列,并在表列表中回溯,直到找到一個有更多匹配行的表。從該表中讀取下一行,并繼續(xù)處理下一個表。
explain 輸出列信息
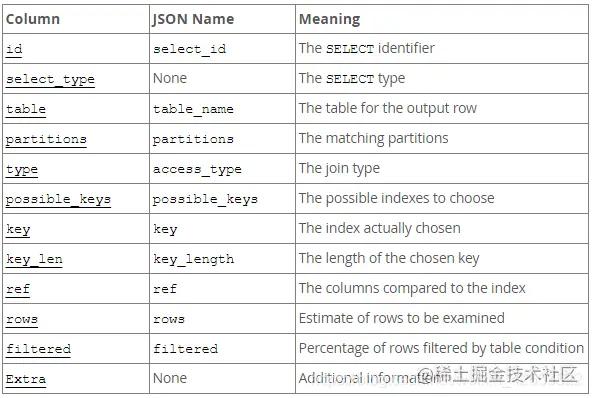
1.1 id
這是查詢中 select 的序列號,如果該行引用其他行的并集結(jié)果,則該行可以為 Null
id 列的值代表著表的執(zhí)行順序,一共分為三種情況:
1.1.1 id相同
EXPLAINSELECTs.*,t.*FROMstudents,teachert

可以看到,explain 命令為 select 標(biāo)識符語句中每個表生成了一行信息,其中 id 相同,代表著 兩個表的執(zhí)行順序從上到下,與 sql 中執(zhí)行的順序無關(guān)。
1.1.2 id不同
EXPLAINSELECT*FROMteachertWHEREid=(SELECTs.tidFROMstudentsWHEREs.id="2")

嵌套子查詢的兩個表的執(zhí)行順序是不同的,所以 explain 解析出的查詢信息 id 是不同的。其中,id 越大代表優(yōu)先級越大,越先被執(zhí)行。
1.1.3 id有相同有不同
EXPLAINSELECTs.id,s.NAME,c.id,c.NAMEFROMclassc,studentsWHEREs.tid=(SELECTt.idFROMteachertWHEREt.id="1")

如果 id 有相同,可以認為是一組,從結(jié)果集中顯示的順序從上往下執(zhí)行(與 SQL 中聲明順序無關(guān));id 值越大,優(yōu)先級越高,越先執(zhí)行。
1.2 select_type
select 的類型,所有的情況見下表: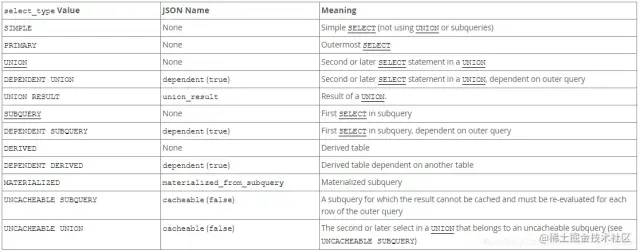
1.2.1 SIMPLE
簡單查詢,查詢中不包含子查詢或者union等任何復(fù)雜查詢 [詳情見示例1.1.1]
1.2.2 PRIMARY
查詢中若包含任何復(fù)雜的子查詢,則最外層被標(biāo)記為 primary,俗稱:雞蛋殼。[詳情見示例1.1.2]
1.2.3 UNION
EXPLAINSELECT`NAME`FROMtb_employees_chinaUNIONSELECT`NAME`FROMtb_employees_usa

union 之后的 select 被標(biāo)記為 union,而 union 前的select 被標(biāo)記為primary ;若 union 包含在 from 子句的子查詢中,外層 select 將被標(biāo)記為derived
1.2.4 UNION RESULT
兩種 union 合并的結(jié)果。[詳情見示例 1.2.3]
1.2.5 DEPENDENT UNION
EXPLAINSELECT`NAME`FROMtb_employees_chinaWHERE`NAME`IN(SELECT`NAME`FROMtb_employees_chinaUNIONSELECT`NAME`FROMtb_employees_usa)

首先要滿足 UNION 的條件,以及 union 中的第二個或以后的 select ,依賴于外部查詢。
1.2.6 SUBQUERY
EXPLAINSELECT*FROMtb_employees_chinaWHEREid=(SELECTidFROMtb_employees_chinaWHERE`name`="lisi")

子查詢中的第一個 select 被標(biāo)識為 subquery
1.2.7 DEPENDENT SUBQUERY
在子查詢中的 select ,依賴于外部查詢 [詳情見示例1.2.4] 此示例中子查詢的第一個 select 被標(biāo)識為 dependent subquery
1.2.8 DERIVED
在 from 子句中包含的子查詢被標(biāo)記為 derived ,mysql 會遞歸這些子查詢,把結(jié)果放在臨時表中(臨時表會增加系統(tǒng)負擔(dān),但有時不得不用)。
注:此實例中,mysql 環(huán)境為:5.7
EXPLAINSELECT*FROM(SELECTidFROMtb_coursetc)temp
 由于 Mysql 8.0 在 Mysql 5.7 基礎(chǔ)上做了優(yōu)化,上述實例在 8.0 版本環(huán)境 explain ,子查詢是不會被標(biāo)識為 derived 的,暫時沒有找到 mysql 8.0 derived 的實例。(后續(xù)發(fā)現(xiàn)會做補充)
由于 Mysql 8.0 在 Mysql 5.7 基礎(chǔ)上做了優(yōu)化,上述實例在 8.0 版本環(huán)境 explain ,子查詢是不會被標(biāo)識為 derived 的,暫時沒有找到 mysql 8.0 derived 的實例。(后續(xù)發(fā)現(xiàn)會做補充)
1.2.9 DEPENDENT DERIVED
在 derived 的基礎(chǔ)上,依賴于外部查詢。
1.2.10 MATERIALIZED
注:此實例中,mysql 環(huán)境為:5.7
EXPLAINSELECT*FROMtb_classWHERE`NAME`IN(SELECT`NAME`FROMtb_class)

將子查詢結(jié)果集中的記錄保存到臨時表的過程稱之為物化(Materialize)。那個存儲子查詢結(jié)果集的臨時表稱之為物化表
在查詢優(yōu)化器執(zhí)行包含子查詢的語句時,選擇將子查詢物化之后與外層查詢進行連接查詢時,該子查詢會被標(biāo)識為 MATERIALIZED
執(zhí)行計劃的第三條記錄的 id 值為2,說明該條記錄最先被執(zhí)行,并且是個單表查詢,它被標(biāo)識為 MATERIALIZED ,查詢優(yōu)化器是要把子查詢先轉(zhuǎn)換為物化表。執(zhí)行計劃的第二條記錄,也就是id 為1,table 為的記錄,此條記錄就是 id 為 2 對應(yīng)的子查詢執(zhí)行之后產(chǎn)生的物化表,再將tb_class 與 該物化表(兩個 id 為 1 的表)連接查詢。
1.2.11 UNCACHEABLE SUBQUERY
無法緩存其結(jié)果的子查詢,必須為外部查詢的每一行重新計算結(jié)果
1.2.12 UNCACHEABLE UNION
union 中第二個或以后的 select ,屬于不可緩存的子查詢
1.3 table
輸出行所引用的表的名稱,除表名稱外還有三種 case
-
:id值為 M 和 N 之間的并集 [詳情見示例1.2.4] - :id 值為 N 的派生表結(jié)果 [詳情見示例1.2.8]
- :id 值為 N 的物化的子查詢的結(jié)果 [詳情見示例1.2.10]
1.4 type
官方全稱是join type,意為:連接類型。Mysql 8.0 中 type 類型達到了12種,下面著重介紹常用的 6 種。從上到下,效率依次是增強的,我們應(yīng)該盡量優(yōu)化我們的 sql,使它的 type盡量更優(yōu),當(dāng)然還要綜合考慮實際情況。
1.4.1 all(Full Table Scan)
全盤掃描,對表中的每行組合都執(zhí)行一次完整的表掃描,如果表是第一個沒有標(biāo)記 const 的表,通常可以通過索引來避免 ALL,這些索引允許基于先前表中的常量值或列值從表中檢索行。
ALL 是一種暴力和原始的查找方法,非常耗時低效。但Mysql官方介紹了一些情況可以使用ALL掃描:
- 該表很小,以至于執(zhí)行表掃描要比打擾key查找快得多,對于少于10行且行長較短的表,是比較常見的
- 對于索引列,ON 或者 WHERE 子句中沒有可用的限制
- 正在將索引列與常量值進行比較
- 正在通過另一列使用基數(shù)較低的鍵(許多行與鍵值匹配),這種情況下,Mysql假定通過使用鍵可能需要進行多次鍵查找,并且表掃描會更快。
對于小型表,表掃描通常是合適的,并且對于性能的影響可以忽略不計,對于大型表,一定要進行優(yōu)化查詢。
SELECT*FROM`tb_employees_china`WHERE`name`="zhangsan"
 這是因為 name 列既不是主鍵也沒有索引,所以采用全盤掃描的方式查找。
這是因為 name 列既不是主鍵也沒有索引,所以采用全盤掃描的方式查找。
1.4.2 index(Full Index Scan)
index 與 all 都是全盤掃描,區(qū)別就是 index 掃描的是索引樹,這種掃描根據(jù)索引回表取數(shù)據(jù),和 all 相比,他們都是取得了全表的數(shù)據(jù),而且 index 要先讀索引而且要回表隨機取數(shù)據(jù),index 不會比 all 快。
SELECTidFROM`tb_employees_usa`

而如果 type 為 index,并且 Extra 為 Using index ,如上圖這種情況,就使用了覆蓋索引,也就是無需回表,當(dāng)前的索引樹滿足了當(dāng)前的查詢需求。
1.4.3 range
range指的是有范圍的索引掃描,相對于 index的索引掃描,它有范圍限制,因此要優(yōu)于 index,range一定是基于索引的,一般常見的范圍查找:between...and,<,>,in ,or 都屬于索引范圍掃描。
1.4.4 ref
出現(xiàn)該連接類型的條件是,查找條件列使用了索引而且不為主鍵和 Unique,也就是使用了普通索引,而非主鍵索引和唯一索引。這樣,即使使用索引快速查找到了第一條數(shù)據(jù),也不能停止掃描,要進行目標(biāo)值附近的小范圍掃描,好處是不需要掃全表,因為索引是有序的,即使有重復(fù)值,也是一個非常小的范圍內(nèi)掃描。
將以下表中 tb_employees_usa 中 name 字段新建索引后執(zhí)行以下語句。
explainselect*fromtb_employees_usawhere`name`='rose';

1.4.5 eq_ref
eq_ref 與 ref 相比厲害的地方在于,eq_ref 知道這種類型的查找結(jié)果集只有一個,只有使用了主鍵或者唯一索引進行查找的情況,結(jié)果集才會是一個。在查找前就已經(jīng)知道結(jié)果集一定只有一個,所以,當(dāng)首次查找到值時,就立即停止了查詢。這種連接類型每次都進行著精確查詢,無需過多的掃描,因此查找效率更高。
select*fromtb_employees_usajointb_employees_chinausing(id);

1.4.6 const
通常情況下,如果將一個主鍵放置到 where 子句作為查詢條件,MySQL 優(yōu)化器會把這個查詢優(yōu)化為一個常量,也就是 const
select*fromtb_employees_usawhere`id`='3';

1.5 possible_keys
查詢可能使用到的索引都會在這里列出來
1.6 key
查詢真正使用到的索引
1.7 key_len
key_len 表示使用的索引長度,key_len可以衡量索引的好壞,key_len越小索引效果越好,那么 key_len 長度是如何計算的呢?
| 列類型 | 是否為空 | 長度 | key_len | 備注 |
|---|---|---|---|---|
| tinyint | 允許Null | 1 | key_len = 1+1 | 允許NULL,key_len長度加1 |
| tinyint | 不允許Null | 1 | key_len = 1 | 不允許NULL |
| int | 允許Null | 4 | key_len = 4+1 | 允許NULL,key_len長度加1 |
| int | 不允許Null | 4 | key_len = 4 | 不允許NULL |
| bigint | 允許Null | 8 | key_len = 8+1 | 允許NULL,key_len長度加1 |
| bigint | 不允許Null | 8 | key_len = 8 | 不允許NULL |
| char(1) | 允許Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 1*3 + 1 | 允許NULL,字符集utf8,key_len長度加1 |
| char(1) | 不允許Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 1*3 | 不允許NULL,字符集utf8 |
| varchar(10) | 允許Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 10*3 + 2 + 1 | 動態(tài)列類型,key_len長度加2,允許NULL,key_len長度加1 |
| varchar(10) | 不允許Null | utf8mb4=4,utf8=3,gbk=2 | key_len = 10*3 + 2 | 動態(tài)列類型,key_len長度加2 |
拿我們上述的執(zhí)行計劃來看,計算一個索引的長度。 其中,索引名稱為
其中,索引名稱為 idx_name 的索引類型是 varchar(30),根據(jù)上述圖表得知,varchar(30) key_len 為:30*3+2+1 = 93
key_len還可用于判斷聯(lián)合索引是否生效以及覆蓋了哪個聯(lián)合索引,我們舉個實例來看。
我們將 tb_employees_usa 表的索引全部刪除,新建聯(lián)合索引 (name,age)
執(zhí)行以下SQL,查看執(zhí)行計劃
explainselect*fromtb_employees_usawherename='rose';

key_len 值為93,經(jīng)計算,此 SQL 使用了聯(lián)合索引其中的單個索引 name
再執(zhí)行如下SQL,查看執(zhí)行計劃
explainselect*fromtb_employees_usawherename='rose';

key_len 值為98,經(jīng)計算,此 SQL 使用了聯(lián)合索引。
1.8 ref
ref字段的值是列或者常數(shù),指的是這個列或常數(shù)與 key 的值一起從表中選擇行數(shù)據(jù)。如上述實例
select*fromtb_employees_usajointb_employees_chinausing(id);
ref 字段值為 test.tb_employees_usa.id,代表 tb_employees_usa 的 id 列與 tb_employees_china 的主鍵一起篩選行數(shù)據(jù)。
如 where 子句中條件是等值常量,則 ref 值為 const
1.9 rows
用來表示在SQL執(zhí)行過程中會被掃描的行數(shù),該數(shù)值越大,意味著需要掃描的行數(shù),相應(yīng)的耗時更長。但是需要注意的是EXPLAIN 中輸出的 rows 只是一個估算值,不能完全對其百分之百相信。
1.10 filtered
表示存儲引擎返回的數(shù)據(jù)在 server 層過濾后,剩下多少滿足查詢的記錄數(shù)量的比例,此值是百分比,不是具體記錄數(shù)量。
1.11 Extra
性能從好到壞排列:
usingindex>usingwhere>usingtemporary>usingfilesort
-
using index:表示覆蓋索引,不需要回表操作 -
using where:列數(shù)據(jù)是從僅僅使用了 -
using temporary:表示 MySQL 需要使用臨時表來存儲結(jié)果集,常見于排序和分組查詢 -
using filesort:MySQL 中無法利用索引完成的排序操作稱為“文件排序”,一般有此值建議使用索引進行優(yōu)化 -
using join buffer:強調(diào)了在獲取連接條件時沒有使用索引,并且需要連接緩沖區(qū)來存儲中間結(jié)果,如果出現(xiàn)此值,應(yīng)該根據(jù)具體情況添加索引來改進性能 -
distinct:在select部分使用了distinc關(guān)鍵字
-End-
審核編輯 :李倩
-
SQL
+關(guān)注
關(guān)注
1文章
766瀏覽量
44169 -
MySQL
+關(guān)注
關(guān)注
1文章
816瀏覽量
26614
原文標(biāo)題:sql優(yōu)化,你一定要用好Explain
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
宏定義下的“GPIO_”是什么作用,一定要用嗎
為什么第一盞燈一定要用0xfe,其他的燈也一定要用該數(shù)值才有效?
全網(wǎng)最全面、最細致的EXPLAIN解讀
SQL后悔藥,SQL性能優(yōu)化和SQL規(guī)范優(yōu)雅
5G基站測試為什么一定要用終端仿真器?資料下載

如何通過explain來驗證sql的執(zhí)行順序

電路設(shè)計降壓,一定要用變壓器嗎?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論