 詳解python正則表達式數量詞
詳解python正則表達式數量詞
這部分理解一下數量詞,為什么要用數量詞,想想都知道,如果你要匹配幾十上百的字符時,難道你要一個一個的寫,所以就出現了數量詞。
數量詞的詞法是:{min,max} 。min 和 max 都是非負整數。如果逗號有而 max 被忽略了,則 max 沒有限制。如果逗號和 max 都被忽略了,則重復 min 次。比如,\b[1-9][0-9]{3}\b,匹配的是 1000 ~ 9999 之間的數字( “\b” 表示單詞邊界),而 \b[1-9][0-9]{2,4}\b,匹配的是一個在 100 ~ 99999 之間的數字。
下面看一個實例,匹配出字符串中 4 到 7 個字母的英文
import re
a = 'java*&39android##@@python'
# 數量詞
findall = re.findall('[a-z]{4,7}', a)
print(findall)
輸出結果:
['java', 'android', 'python']
注意,這里有貪婪和非貪婪之分。那么我們先看下相關的概念:
貪婪模式:它的特性是一次性地讀入整個字符串,如果不匹配就吐掉最右邊的一個字符再匹配,直到找到匹配的字符串或字符串的長度為 0 為止。它的宗旨是讀盡可能多的字符,所以當讀到第一個匹配時就立刻返回。
懶惰模式:它的特性是從字符串的左邊開始,試圖不讀入字符串中的字符進行匹配,失敗,則多讀一個字符,再匹配,如此循環,當找到一個匹配時會返回該匹配的字符串,然后再次進行匹配直到字符串結束。
上面例子中的就是貪婪的,如果要使用非貪婪,也就是懶惰模式,怎么呢?
如果要使用非貪婪,則加一個 ? ,上面的例子修改如下:
import re
a = 'java*&39android##@@python'
# 貪婪與非貪婪
re_findall = re.findall('[a-z]{4,7}?', a)
print(re_findall)
輸出結果如下:
['java', 'andr', 'pyth']
從輸出的結果可以看出,android 只打印除了 andr ,Python 只打印除了 pyth ,因為這里使用的是懶惰模式。
當然,還有一些特殊字符也是可以表示數量的,比如:
?:告訴引擎匹配前導字符 0 次或 1 次
+:告訴引擎匹配前導字符 1 次或多次
*:告訴引擎匹配前導字符 0 次或多次
把這部分的知識點總結一下,就是下面這個表了:
| 貪 婪 | 惰 性 | 描 述 |
|---|---|---|
| ? | ?? | 零次或一次出現,等價于{0,1} |
| + | +? | 一次或多次出現 ,等價于{1,} |
| * | *? | 零次或多次出現 ,等價于{0,} |
| {n} | {n}? | 恰好 n 次出現 |
| {n,m} | {n,m}? | 至少 n 次枝多 m 次出現 |
| {n,} | {n,}? | 至少 n 次出現 |
審核編輯:湯梓紅
-
字符串
+關注
關注
1文章
585瀏覽量
20563 -
python
+關注
關注
56文章
4802瀏覽量
84889
發布評論請先 登錄
相關推薦
Linux grep命令詳解
Verilog表達式的位寬確定規則
通過工業智能網關實現中間變量表達式的快速配置
nginx中的正則表達式和location路徑匹配指南
TestStand表達式中常用的語法規則和運算符使用

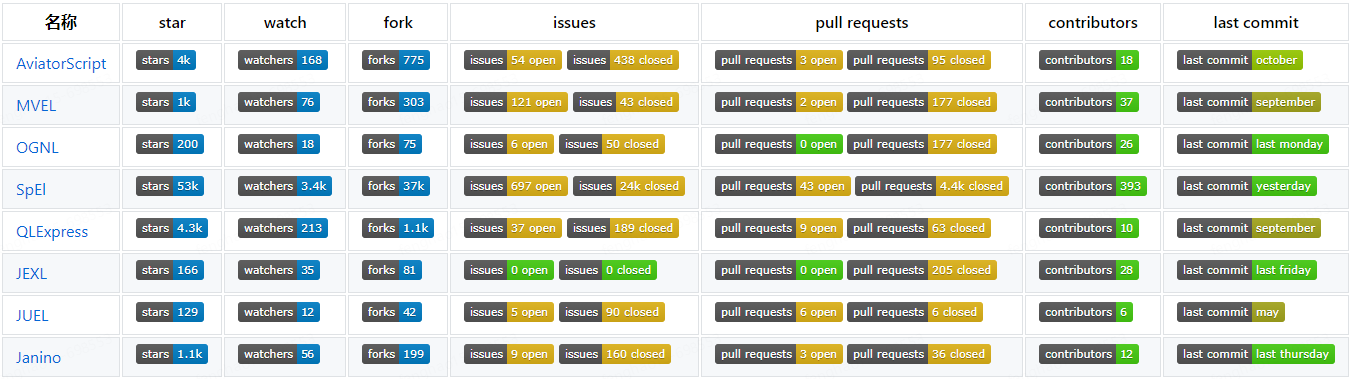
Java表達式引擎選型調研分析
鴻蒙原生應用元服務開發-倉頡基本概念表達式(二)
鴻蒙原生應用元服務開發-倉頡基本概念表達式(一)
求助,有關表達式選項卡(ADS)的問題求解
BGP路由過濾、引入與缺省路由的配置實踐





 工商網監
工商網監
評論