 文本糾錯是自然語言處理的第一道坎
文本糾錯是自然語言處理的第一道坎
文本糾錯是自然語言處理的一個重要任務,也是文本處理的第一道坎,一個錯誤的文本表述可能會引起后續語義的錯誤表達,并對后續的效果產生影響。
例如,以常見的輸入錯誤為例,十分豐富多彩,常見錯誤類型包括:
1、少字:微信跳一->微信跳一跳
2、多字:微信跳一跳跳->微信跳一跳
3、錯字:微信挑一挑->微信跳一跳
4、拼音:tiaoyitiao ->跳一跳
5、中英文混拼:held住-> hold住
6、中文拼音混拼:跳yi跳->跳一跳
7、知識錯誤:南山平安金融中心->福田平安金融中心
8、音轉:灰機->飛機
9、諧音字詞,如配副眼睛-配副眼鏡
10、混淆音字詞,如流浪織女-牛郎織女
11、字詞順序顛倒,如伍迪艾倫-艾倫伍迪
12、字詞補全,如愛有天意-假如愛有天意
13、形似字錯誤,如高梁-高粱
14、中文拼音全拼,如xingfu-幸福
15、中文拼音縮寫,如sz-深圳
而這些錯誤又可以進一步區分為有意或者無意兩種,無有意的錯誤可能是為了反識別或者惡意營銷等灰色產業服務。
因此,文本糾錯這塊就有諸多應用場景。
例如,寫作輔助上,在內容寫作平臺上內嵌糾錯模塊,可在作者寫作時自動檢查并提示錯別字情況。從而降低因疏忽導致的錯誤表述,有效提升作者的文章寫作質量,同時給用戶更好的閱讀體驗。
又如,搜索糾錯上,用戶經常在搜索時輸入錯誤,通過分析搜索query的形式和特征,可自動糾正搜索query并提示用戶,進而給出更符合用戶需求的搜索結果,有效屏蔽錯別字對用戶真實需求的影響。
再如,語音識別對話糾錯上,將文本糾錯嵌入對話系統中,可自動修正語音識別轉文本過程中的錯別字,向對話理解系統傳遞糾錯后的正確query,能明顯提高語音識別準確率,使產品整體體驗更佳。
而就技術而言,實際上可以對應的變成變體或者錯誤體的生成以及還原兩者,前者研究如何快速生成盡可能豐富的變體,后者研究如何返回正確的文本,十分有趣。
因此,本文主要圍繞NLP糾錯技術,做第一篇論述,從工業場景中的文本糾錯、魯棒性過濾以及惡意短信變體字還原大賽三個比賽進行介紹,并使用最簡單的編輯距離操作生成變體,供大家一起參考。
一、自然語言處理技術創新大賽—中文文本糾錯比賽
賽題背景:文本校對任務主要是針對文本中出現的錯誤進行檢測和糾正,屬于綜合性的自然語言處理研究子方向,能夠比較全面體現了自然語言處理的技術水平。過往文本校對相關評測使用的都是外國語言學習者撰寫的文本,這些文本的錯誤大多數都是一些中文母語寫作者不會犯的一些錯誤。
對于政務公文、新聞出版等行業來說,一款針對以中文為母語的用戶所使用的校對系統將會有更大的幫助。因此,本賽題主要選擇互聯網上中文母語寫作者撰寫的網絡文本作為校對評測數據,從拼寫錯誤、語法錯誤、語病錯誤等多個方面考察機器的認知智能能力。
賽題任務:賽題選擇網絡文本作為校對數據,從中檢測并糾正錯誤,實現中文文本校對系統。即給定一段文本,校對系統從中檢測出錯誤字詞、錯誤類型,并進行糾正。具體的輸入、輸出及錯誤類型為:
輸入:輸入文件包含若干行文本,每行文本對應句子ID和相應的待校對句。
輸出:輸出文件每行對應句子ID及相應的校對結果。校對結果中每處錯誤需包含錯誤位置、錯誤類型、錯誤字詞及正確字詞,每處錯誤及多處錯誤間均以英文逗號分隔。
錯誤類型:拼寫錯誤,包括別字及別詞;語法錯誤,包括冗余、缺失、亂序;語病錯誤,包括語義重復及句式雜糅。
舉例如下:

地址:https://2021aichina.caai.cn/track?id=5
二、中國人工智能大賽魯棒性過濾算法
第三屆中國人工智能大賽,重點聚焦算法治理、深度偽造音視頻檢測、網絡安全等方向,希望以競賽方式解決現實場景中需求問題。
賽題背景:構建魯棒的過濾算法在網絡空間內容治理領域具有重要的實際價值。信息產生、獲取、消費等環節的算法魯棒性欠缺,會嚴重影響正常的社會秩序。因此,算法魯棒性在算法安全治理中屬于非常重要的指標。
在信息生成和獲取的環節,過濾算法扮演著安全護衛的作用,把守網絡信息安全的第一關。過濾算法是指將用戶產生的特定信息進行自動識別和過濾的算法。目前,特定信息變換各種形式出現在互聯網中,這對于現有的過濾算法無疑是一個挑戰。
例如,中國人工智能大賽魯棒性過濾算法賽道過濾出了這樣一道賽題:

賽題任務:主辦方將收集上千條含特定信息和同比例正常信息的短文本,用以評價選手的過濾模型。測試文本根據所包含特定信息的變種難度不同設置相應的難度分數。本賽題將以參賽選手過濾模型識別出的特定信息樣本以及該樣本對應難度的積作為主要評價指標。
地址:https://ai.xm.gov.cn/competition/project-detail.html?id=e813904b755a439da1a6c5749bcf9b60&competeId=a8e0c40dbb2347fba8b3c9a6294efa5b
三、面向黑灰產治理的惡意短信變體字還原
賽題背景:惡意短信一直是黑灰產引流的重要渠道,信息中攜帶的微信號、QQ號、網址更是非法信息傳播的主要入口,業界通常做法是利用違法或不良信息檢測引擎在手機終端實現自動攔截。然而不法分子為逃避檢測,通過使用變體字發送惡意短信繞過攔截規則的情況越來越多。
由于變體字變換方式多,變換速度快,單純通過規則進行變體詞發現的效果有限,配套人工審核成本高且具有滯后性。如何精準和高效地還原變體字文本,提高非法信息的抽取能力,以及新型變體字還原的泛化性和時效性,就成為了解決這一難題的“關鍵之鑰”。
賽題任務:參賽團隊通過設計算法,實現對惡意短信中變體字的還原。參賽團隊需要對訓練集中的短信樣本進行分析,采用深度學習建模的方法將測試集中新出現的短信變體字還原為正常信息文本,即不含有變體字、干擾字符,所有變體字部分應使用常見簡體漢字、字符來表示,同時需要保證不包含變體字的正常文本不受影響。
例子如下;
變體句子:噂儆的碦戸:其鎃祝冊茺贈鎬888葒笣!禛朲對弈佰捆任你選!嶺:http://url.cn/5aLeqP2
還原后:尊敬的客戶:棋牌注冊充贈高888紅包!真人對弈百款任你選!領:url.cn5aLeqP2
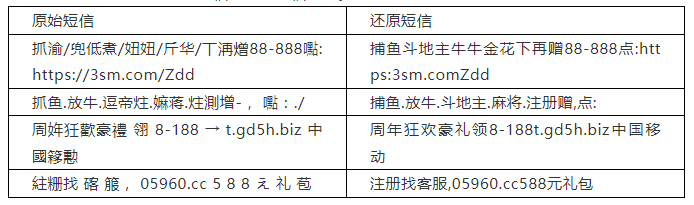
地址:https://beta-www.datafountain.cn/competitions/508
四、基于編輯距離生成變體小測試
實際上,基于編輯距離來生成的變體是最快速且簡單的方式,下面做了一個快速實現:
#詞典庫
vocab=set([line.rstrip()forlineinopen('vocab.txt')])
#print(vocab)
#生成所有的候選集合
defgenerate_edit_one(word):
"""
#假設使用26個字符
letters='abcdefghijklmnopqrstuvwxyz'
splits=[(word[:i],word[i:])foriinrange(len(word)+1)]
#inserts操作
inserts=[L+c+RforL,Rinsplitsforcinletters]
#delete操作
deletes=[L+R[1:]forL,RinsplitsifR]
#replace操作
replaces=[L+c+R[1:]forL,RinsplitsifRforcinletters]
candidates=set(inserts+deletes+replaces)
#過濾掉不存在詞典庫里的單詞
return[wordforwordincandidatesifwordinvocab]
defgenerate_edit_two(str):
"""
給定一個字符串,生成編輯距離不大于2的字符串
"""
return[e2fore1ingenerate_edit_one(str)fore2ingenerate_edit_one(e1)ife2invocab]
print('給定一個字符串,生成編輯距離為1的字符串','
',generate_edit_one('apple'))
print('給定一個字符串,生成編輯距離不大于2的字符串','
',generate_edit_two("apple"))
執行后,我們可以產生如下變體結果:

審核編輯 :李倩
-
模塊
+關注
關注
7文章
2725瀏覽量
47610 -
文本
+關注
關注
0文章
118瀏覽量
17098 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13599
原文標題:NLP糾錯 | 惡意短信變體字還原、魯棒性過濾與文本糾錯競賽概述與簡單變體實現
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論