 Transformers研究方向
Transformers研究方向
BERT 通過改變 NLP 模型的訓練方式迎來了 NLP 領域的 ImageNet 時刻。自此之后的預訓練模型分別嘗試從mask 范圍,多語言,下文預測,模型輕量化,預訓練方式,模型大小,多任務等方向謀求新突破,有的效果明顯,有的只是大成本小收益。
自 2018 年 BERT 提出之后,各種預訓練模型層出不窮,模型背后的著眼點也各有不同,難免讓人迷糊。本文旨在從以下幾個方面探討系列 Transformers 研究方向:
擴大遮罩范圍(MaskedLM)
其他預訓練方式
輕量化
多語言
越大越好?
多任務
要說 BERT 為什么性能卓越,主要是它改變了 NLP 模型的訓練方式。先在大規模語料上訓練出一個語言模型,然后將這個模型用在閱讀理解/情感分析/命名實體識別等下游任務上
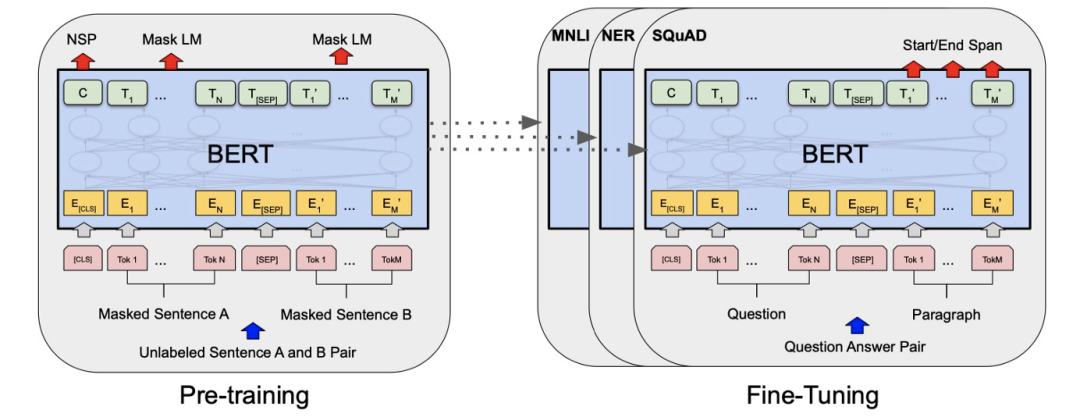
Yann LeCun 將 BERT 的學習方式稱為“自監督學習”,強調模型從輸入內容中學習,又對其中部分內容進行預測的特點。而 BERT 本身實際算是是基于 Transformer 編碼器部分改進而來的多任務模型,會同時執行遮罩語言模型學習以及下文預測任務,以此習得潛藏語義。
擴大遮罩范圍改進 MaskedLM
遮罩語言模型里的“遮罩”,通常是分詞后一小段連續的 MASK 標記

相比于從上下文中猜整個詞,給出 ##eni 和 ##zation 猜到 tok 顯然更容易些。
也正因單詞自身標識間的聯系和詞與詞間的聯系不同,所以 BERT 可能學不到詞語詞間的相關關系。而只是預測出詞的一部分也沒什么意義,預測出整個詞才能學到更多語義內容。所以拓展遮罩范圍就顯得十分重要了:
字詞級遮罩——WWM
短語級遮罩——ERNIE
縮放到特定長度——N-gram 遮罩/ Span 遮罩
短語級遮罩使用時得額外提供短語列表,但加上這樣的人工信息可能會干擾模型導致偏差。T5 嘗試了不同跨度的遮罩,似乎長一些的會好點
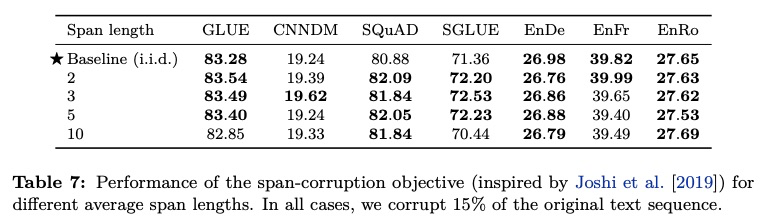
可以看到初期擴大跨度是有效的,但不是越長越好。SpanBERT 有一個更好的解決方案,通過概率采樣降低對過長遮罩的采納數量。
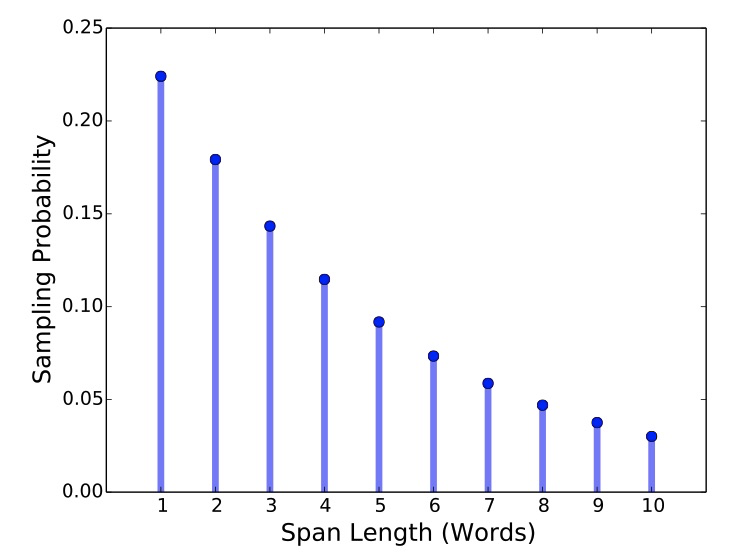
從 SpanBERT 的實驗結果來看隨機跨度效果不錯
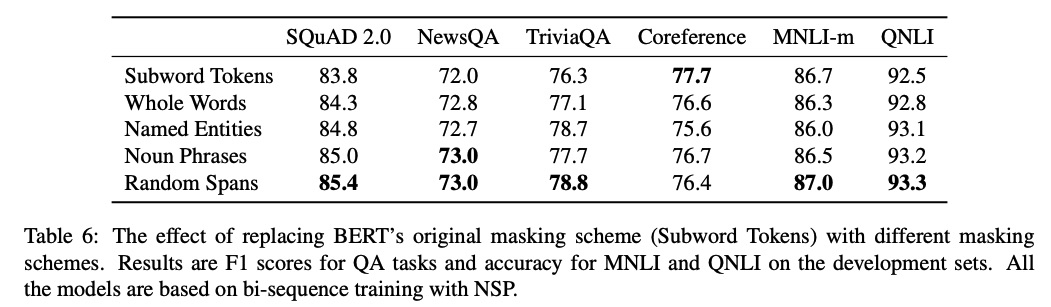
此外,也有模型嘗試改進遮罩比例。Google 的 T5 嘗試了不同的遮罩比例,意外的是替代項都不如原始設置表現好
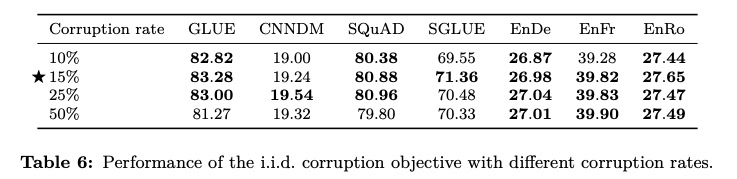
下文預測
準確地講應該是下一句預測(NextSentencePrediction,NSP),通過判斷兩個句子間是否是上下文相關的來學習句子級知識。從實驗結果來看,BERT 并沒有帶來明顯改進
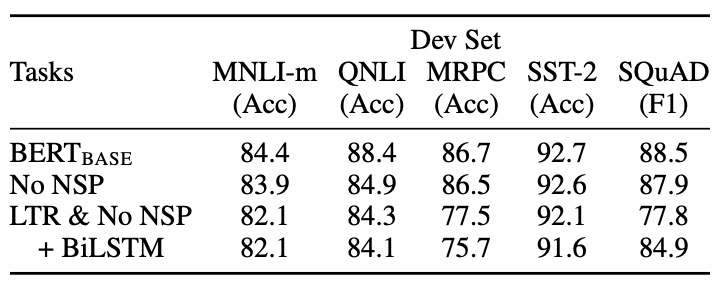
BERT 的欠佳表現給了后來者機會,幾乎成了兵家必爭之地。XLNET / RoBERTa / ALBERT 等模型都在這方面進行了嘗試
RoBERTa
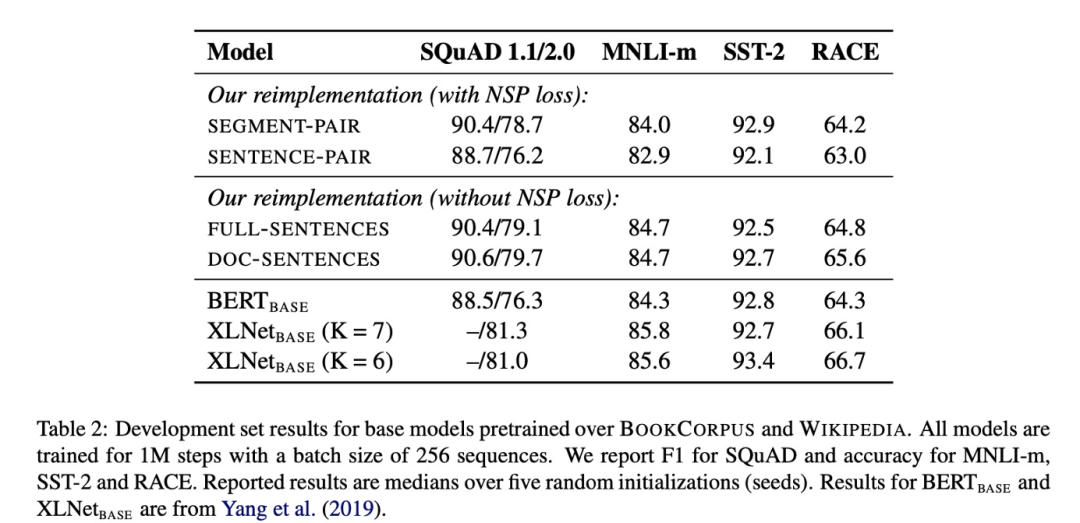
ALBERT
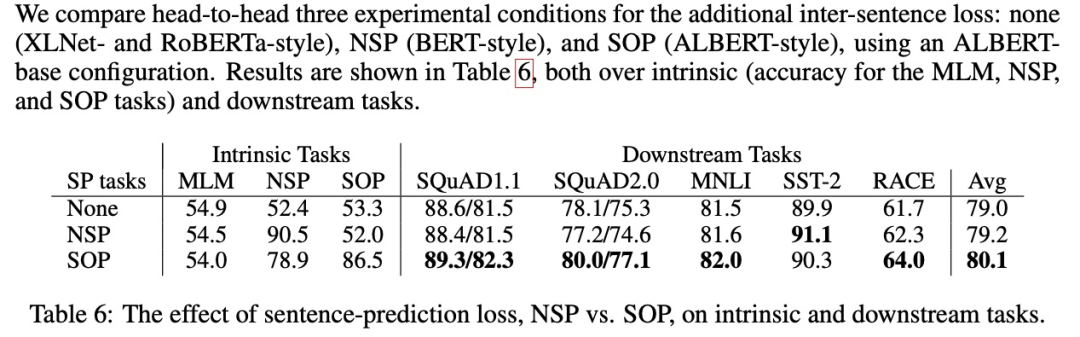
XLNet
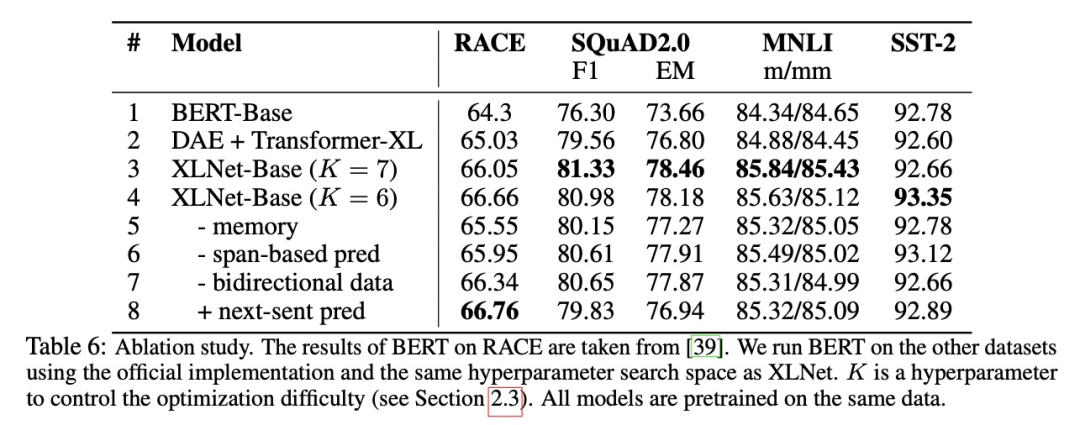
可以看出 NSP 帶來的更多的是消極影響。這可能是 NSP 任務設計不合理導致的——負樣本是從容易辨析的其他文檔中抽出來的,這導致不僅沒學到知識反而引入了噪聲。同時,NSP 將輸入分成兩個不同的句子,缺少長語句樣本則導致 BERT 在長句子上表現不好。
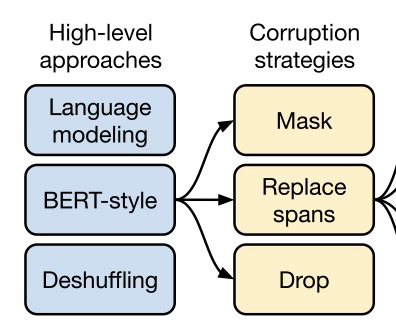
其他預訓練方式
NSP 表現不夠好,是不是有更好的預訓練方式呢?各家都進行了各種各樣的嘗試,私以為對多種預訓練任務總結的最好的是 Google 的 T5 和 FaceBook 的 BART
T5 的嘗試

BART 的嘗試
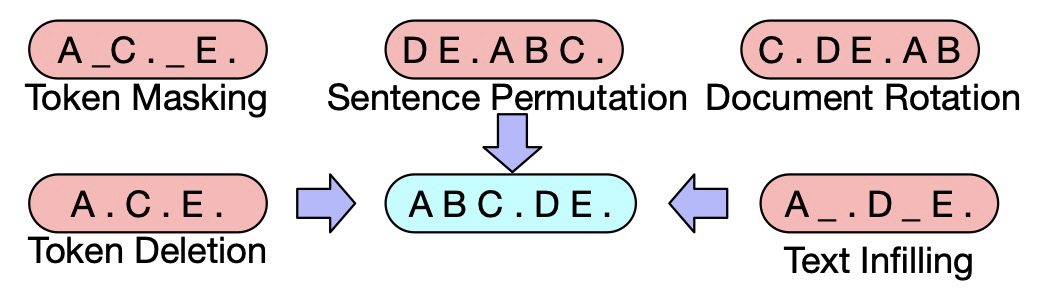
各家一般都選語言模型作為基線,而主要的嘗試方向有
擋住部分標識,預測遮擋內容
打亂句子順序,預測正確順序
刪掉部分標識,預測哪里被刪除了
隨機挑選些標識,之后將所有內容前置,預測哪里是正確的開頭
加上一些標識,預測哪里要刪
替換掉一些標識,預測哪里是被替換過的
試驗結果如下
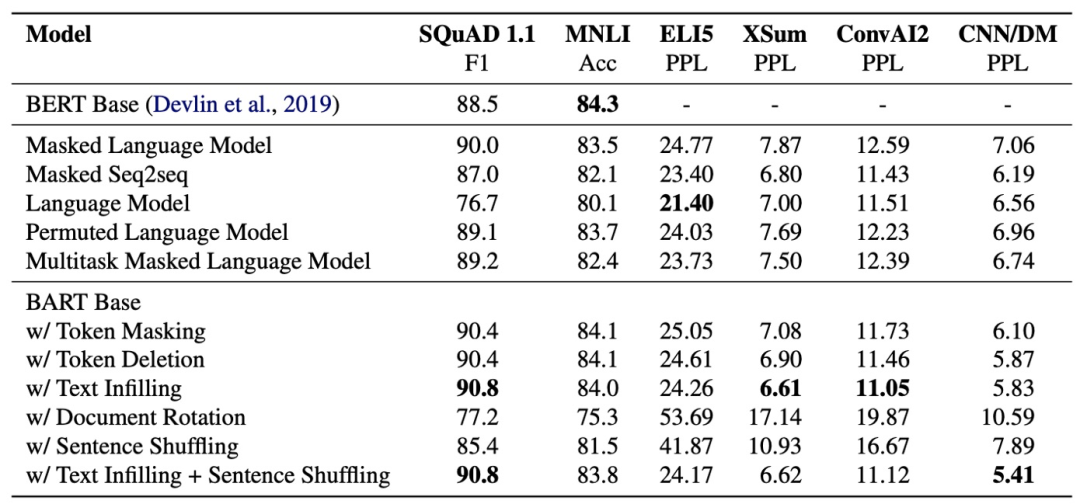
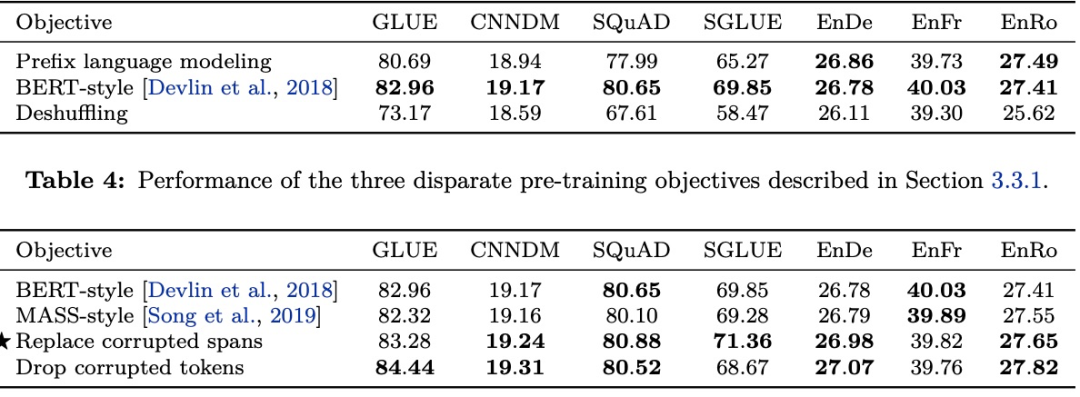
實驗表明遮罩模型就是最好的預訓練方法。要想效果更好點,更長的遮罩和更長的輸入語句似乎是個不錯的選擇。而為了避免泄露具體擋住了多少個詞,每次只能標記一個遮罩,對一個或多個詞做預測
輕量化
BERT 模型本身非常大,所以為了運行更快,模型輕量化也是一大研究方向。一網打盡所有 BERT 壓縮方法[1]對此有細致描述,主要分幾個方向:
修剪——刪除部分模型,刪掉一些層 / heads 等
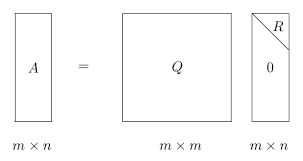
矩陣分解——對詞表 / 參數矩陣進行分解
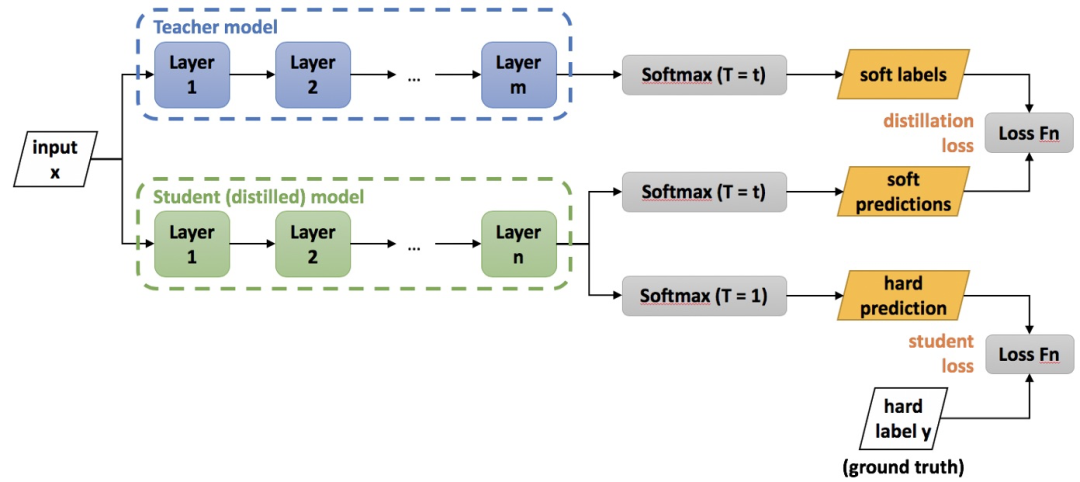
知識蒸餾——師生結構,在其他小模型上學習
參數共享——層與層間共享權重
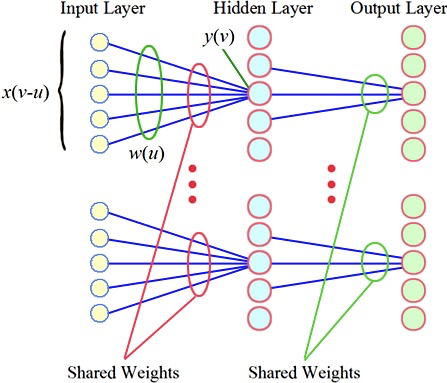
多語言
數據集在不同語言間分布的非常不均勻,通常是英語數據集很多,其他語言的相對少些,繁體中文的話問題就更嚴重了。而 BERT 的預訓練方法并沒有語言限制,所以就有許多研究試圖喂給預訓練模型更多語言數據,期望能在下游任務上取得更好的成績。
谷歌的 BERT-Multilingual 就是一例,在不添加中文數據的情況下,該模型在下游任務上的表現已經接近中文模型

有研究[2]對多語言版 BERT 在 SQuAD(英語閱讀理解任務)和 DRCD(中文閱讀理解任務)上進行了測試。最終證明可以取得接近 QANet 的效果,同時多語言模型不用將數據翻譯成統一語言,這當然要比多一步翻譯過程的版本要好。
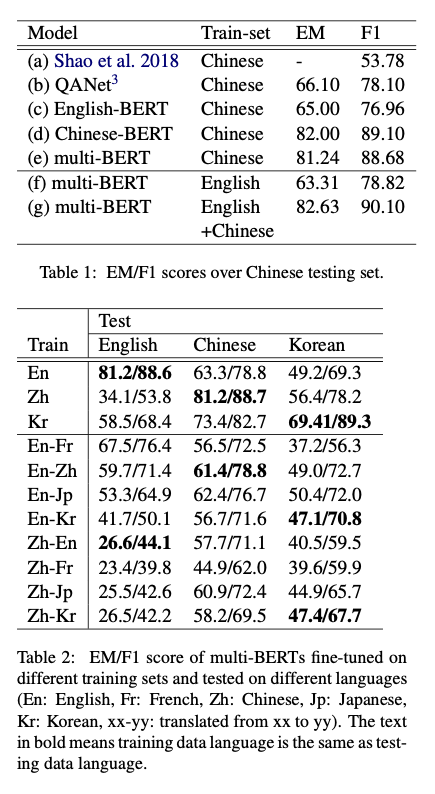
從上面的結果可以看出無論是用 Embedding 還是 Transformer 編碼器,BERT 都學到了不同語言間的內在聯系。另有研究[3]專門針對 BERT 聯通不同語言的方式進行了分析。
首先,在相同的 TLM 預訓練模型中對不同語言建立關聯
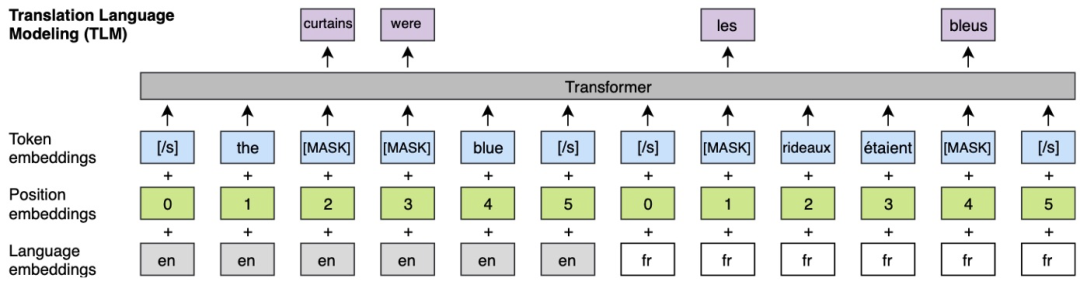
然后,通過控制是否共享組件來分析哪個部分對結果影響最大
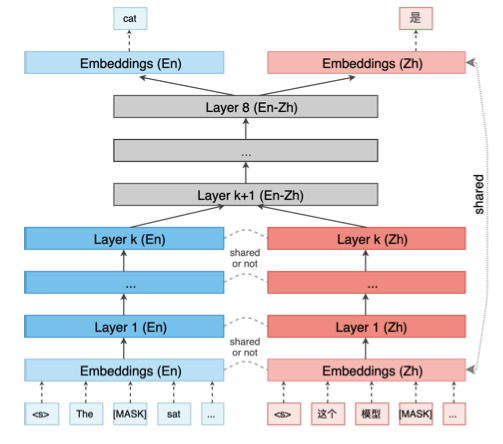
結果是模型間共享參數是關鍵
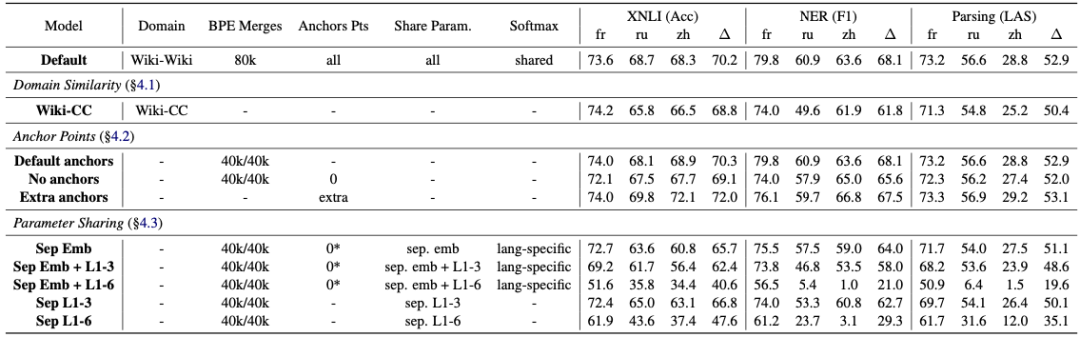
這是因為 BERT 是在學習詞和相應上下文環境的分布,不同語言間含義相同的詞,其上下文分布應該很接近

而 BERT 的參數就是在學習期間的分布,所以也就不難理解模型在多語言間遷移時的驚人表現了
越大越好?
盡管 BERT 采用了大模型,但直覺上數據越多,模型越大,效果也就應該更好。所以很多模型以此為改進方向
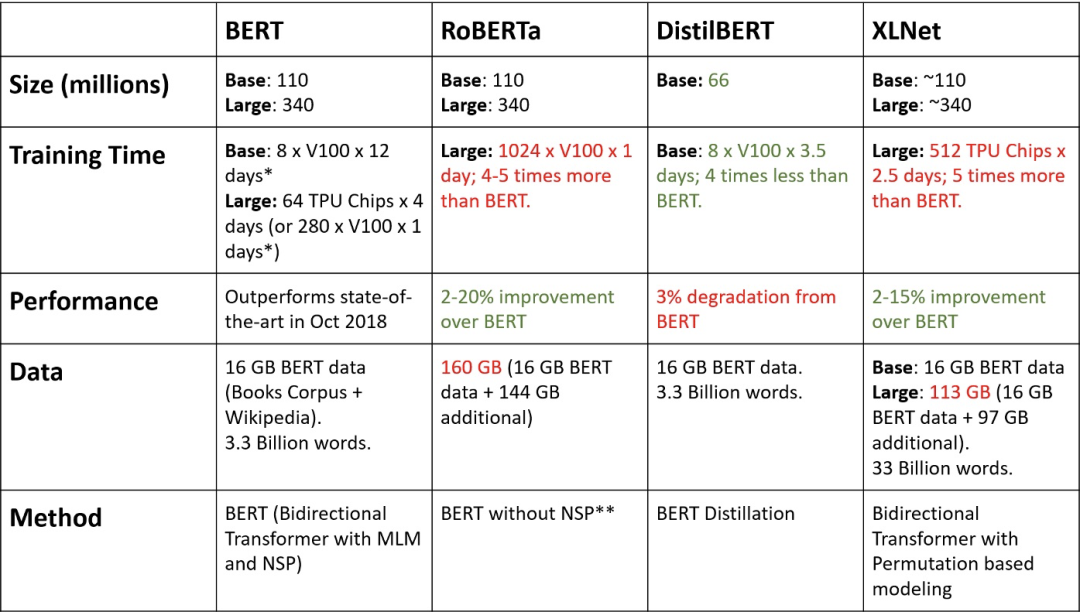
T5 更是憑借 TPU 和金錢的魔力攀上頂峰

然而更大的模型似乎并沒有帶來太多的回報
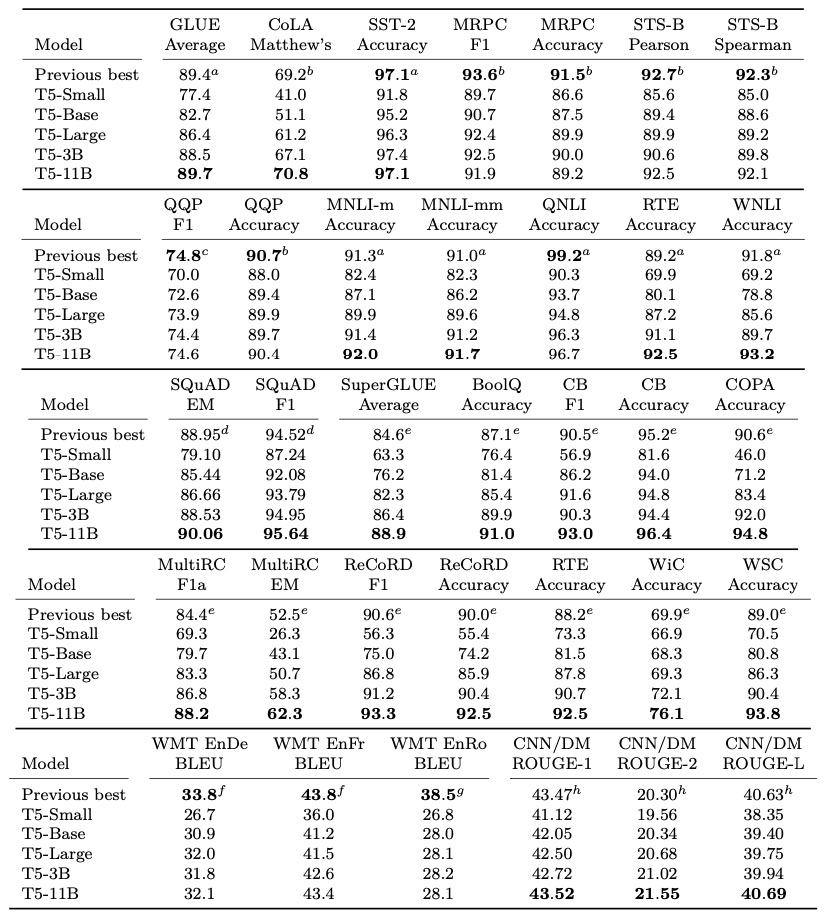
所以,簡單增大模型規模并不是最高效的方法。
此外,選用不同的訓練方法和目標也是一條出路。比如,ELECTRA 采用新型訓練方法保證每個詞都能參與其中,從而使得模型能更有效地學習表示(representation)
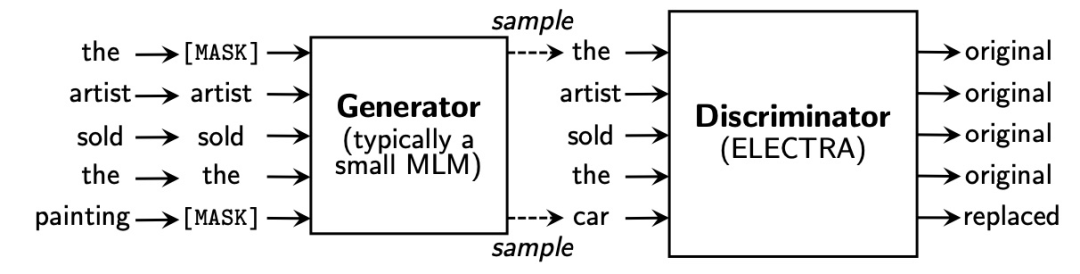
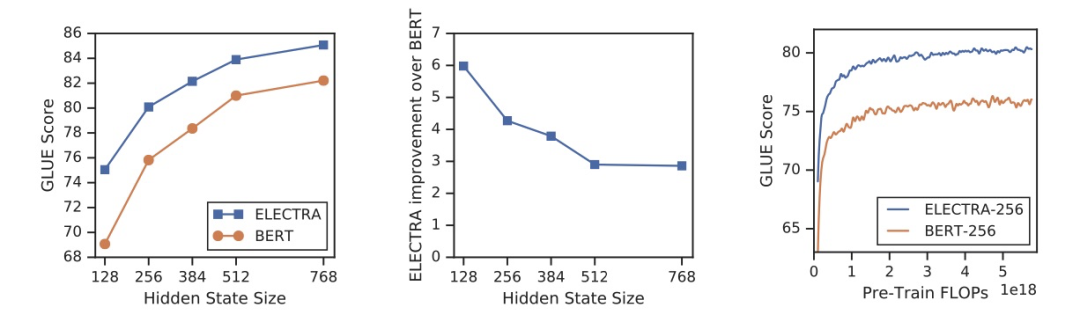
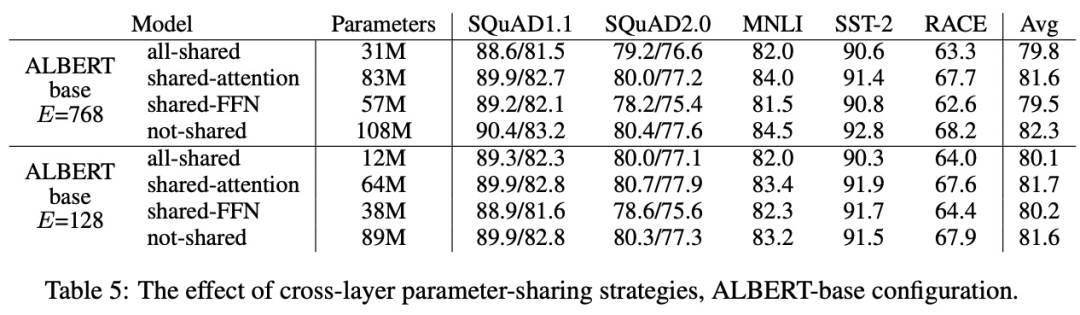
ALBERT 使用參數共享降低參數量,但對性能沒有顯著影響
多任務
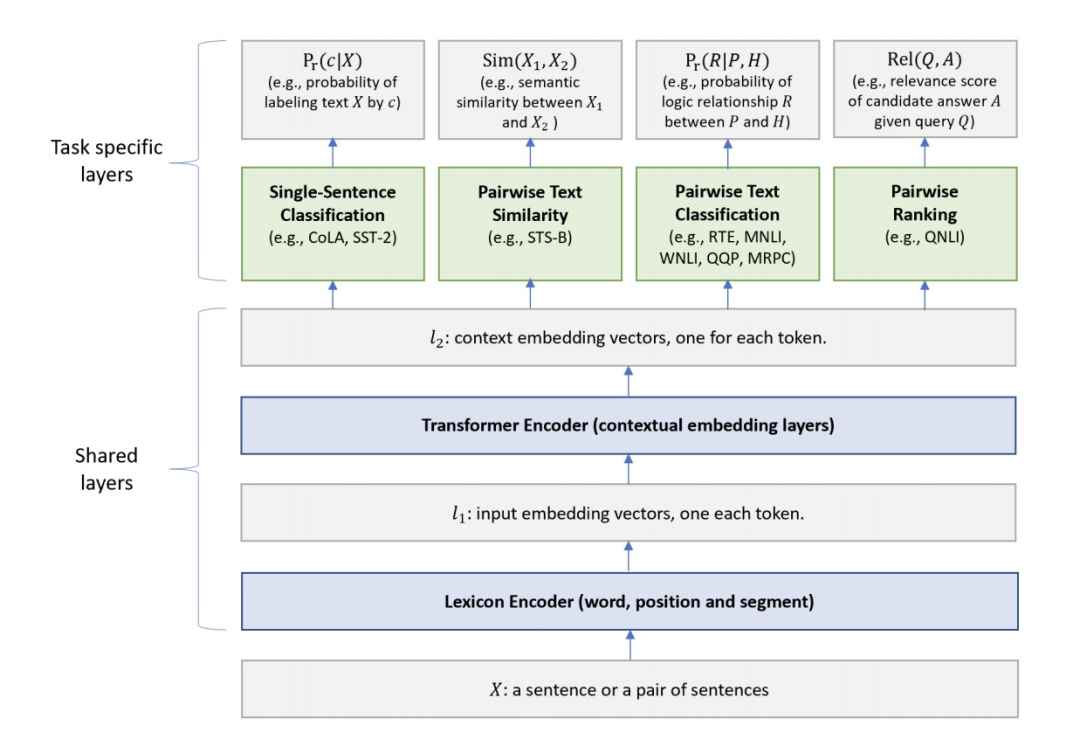
BERT 是在預訓練時使用多任務,我們同樣可以在微調時使用多任務。微軟的用于自然語言理解的多任務深度神經網絡[4](MTDNN)就是這么做的
相交于 MTDNN,GPT-2 更加激進:不經微調直接用模型學習一切,只用給一個任務標識,其余的交給模型。效果出眾但仍稱不上成功
T5 對此做了平衡
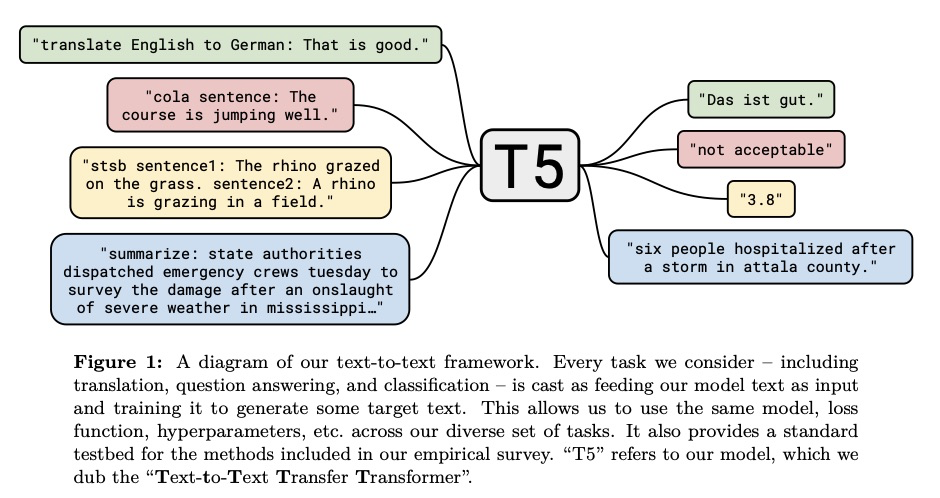
谷歌的 T5 類似于 GPT-2,訓練一個生成模型來回答一切問題。同時又有點像 MTDNN,訓練時模型知道它是在同時解決不同問題,它是一個訓練/微調模型
同時,大體量預訓練模型都面臨相同的兩個難題:數據不均衡和訓練策略選定
不均衡數據
不同任務可供使用的數據量是不一致的,這導致數據量小的任務表現會很差。數據多的少采樣,數據少的多采樣是一種解決思路。BERT 對多語言訓練采用的做法就是一例
為平衡這兩個因素,訓練數據生成(以及 WordPiece 詞表生成)過程中,對數據進行指數平滑加權。換句話說,假如一門語言的概率是
,比如 意味著在混合了所有維基百科數據后, 21% 的數據是英文的。我們通過因子 S 對每個概率進行指數運算并重新歸一化,之后從中采樣。我們的實驗中, ,所以像英語這樣的富文本語言會被降采樣,而冰島語這樣的貧文本語言會過采樣。比如,原始分布中英語可能是冰島語的 1000 倍,平滑處理后只有 100 倍
訓練策略
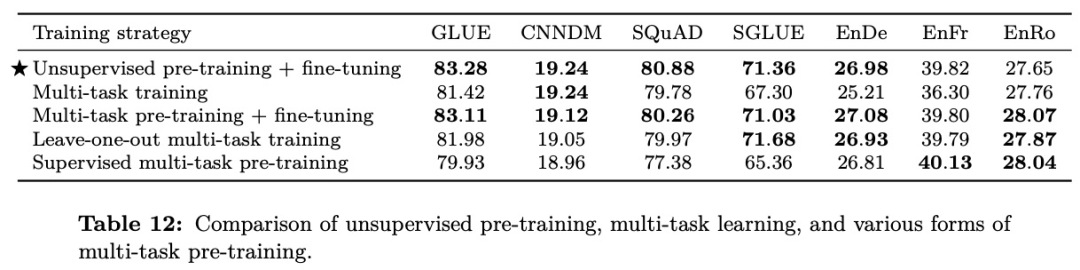
無監督預訓練+微調:在 T5 預訓練后對各任務進行微調
多任務訓練:所有任務和 T5 預訓練一同訓練學習,并直接在各任務上驗證結果
多任務預訓練+微調:所有任務和 T5 預訓練一同訓練學習,然后對各任務微調訓練數據,再驗證結果
留一法多任務訓練:T5 預訓練和目標任務外的所有任務一同進行多任務學習,然后微調目標任務數據集,再驗證結果
有監督多任務預訓練:在全量數據上進行多任務訓練,然后對各任務微調結果
可以看到先在海量數據上進行訓練,然后對特定任務數據進行微調可以緩解數據不平衡問題。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3643瀏覽量
134525 -
模型
+關注
關注
1文章
3244瀏覽量
48845 -
nlp
+關注
關注
1文章
488瀏覽量
22038
原文標題:BERT 之后的故事
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
非球面透鏡背后的焦點研究
如何使用 Llama 3 進行文本生成
光路元件的位置和方向
電流的方向是從正極到負極嗎
電流方向和電荷運動方向的關系
計算機視覺的主要研究方向
線圈磁場方向的判斷方法用什么定則
感應電動勢的方向與磁力線方向導體運動方向
Transformers內部運作原理研究
Transformers的功能概述
使用基于Transformers的API在CPU上實現LLM高效推理





 工商網監
工商網監
評論