 為MLPerf HPC v1.0實現的選定優化
為MLPerf HPC v1.0實現的選定優化
在 MLPerf HPC v1 . 0 中, NVIDIA 供電系統贏得了五項新的行業指標中的四項,這些指標主要關注 HPC 中的人工智能性能。作為一個全行業人工智能聯盟, MLPerf HPC 評估了一套性能基準,涵蓋了廣泛使用的人工智能工作負載。
在這一輪中,與 MLPerf 0 . 7 的強大擴展性結果相比, NVIDIA 在 CosmoFlow 上的性能提高了 5 倍,在 DeepCAM 上的性能提高了 7 倍。這一強大的表現得益于成熟的 NVIDIA AI 平臺和全套軟件。
提供豐富多樣的庫、 SDK 、工具、編譯器和探查器,很難知道在正確的情況下何時何地應用正確的資產。這篇文章詳細介紹了各種場景的工具、技術和好處,并概述了 CosmoFlow 和 DeepCAM 基準測試所取得的成果。
我們已經為 MLPerf Training v1.0 和 MLPerf Inference v1.1 發布了類似的指南,推薦用于其他面向基準測試的案例。
調整計劃
我們使用包括 NVIDIA DALI 在內的工具對代碼進行了優化,以加速數據處理,以及 CUDA Graphs 減少了小批量延遲,從而有效地擴展到 1024 個或更多 GPU 。我們還應用了 NVIDIA SHARP ,通過將一些操作卸載到網絡交換機來加速通信。
我們提交的文件中使用的軟件可從 MLPerf repository 獲得。我們定期向 NGC catalog 添加新工具和新版本,這是我們針對預訓練 AI 模型、行業應用程序框架、 GPU 應用程序和其他軟件資源的軟件中心。
主要性能優化
在本節中,我們將深入討論為 MLPerf HPC 1 . 0 實現的選定優化。
使用 NVIDIA DALI 庫進行數據預處理
在每次迭代之前,從磁盤獲取數據并進行預處理。我們從默認的數據加載器移到了 NVIDIA DALI library 。這為 GPU 提供了優化的數據加載和預處理功能。
DALI 庫使用 CPU 和 GPU 的組合,而不是在 CPU 上執行數據加載和預處理并將結果移動到 GPU 。這將為即將到來的迭代帶來更有效的數據預處理。優化后, CosmoFlow 和 DeepCAM 的速度都顯著加快。 DeepCAM 實現了超過 50% 的端到端性能提升。
此外, DALI 還為即將到來的迭代提供異步數據加載,以消除關鍵路徑的 I / O 開銷。啟用此模式后,我們看到 DeepCAM 額外增加了 70% 。
將通道應用于最后的 NHWC 布局
默認情況下, DeepCAM 基準使用 NCHW 布局作為激活張量。我們使用 PyTorch 的通道 last ( NHWC 布局)支持來避免額外的轉置內核。 cuDNN 中的大多數卷積核都針對 NHWC 布局進行了優化。
因此,在框架中使用 NCHW 布局需要額外的轉置內核,以便從 NCHW 轉換到 NHWC ,從而實現高效的卷積運算。在框架中使用 NHWC 布局避免了這些冗余拷貝,并在 DeepCAM 模型上實現了約 10% 的性能提升。 NHWC support 在 PyTorch 框架中以 beta 模式提供。
CUDA 圖
CUDA 圖形允許啟動由一系列內核組成的單個圖形,而不是單獨啟動從 CPU 到 GPU 的每個內核。此功能最大限度地減少了 CPU 在每次迭代中的參與,通過最大限度地減少延遲(尤其是在強擴展場景中)顯著提高了性能。
MXNet 先前添加了 CUDA 圖形支持,而 CUDA Graphs support 最近也添加到了 PyTorch 。 PyTorch 中的 CUDA 圖形支持使 DeepCAM 在強擴展場景中的端到端性能提高了約 15% ,這對延遲和抖動最為敏感。
使用 MPI 進行高效的數據暫存
在伸縮性較弱的情況下,分布式文件系統的性能無法滿足 GPU 的需求。為了增加總存儲帶寬,我們將數據集放入 DeepCAM 的節點本地 NVME 內存中。
由于各個實例都很小,我們可以靜態地分割數據,因此每個節點只需要準備完整數據集的一小部分。該解決方案如圖 1 所示。這里,我們用 M 表示實例數,用 N 表示每個實例的秩數。
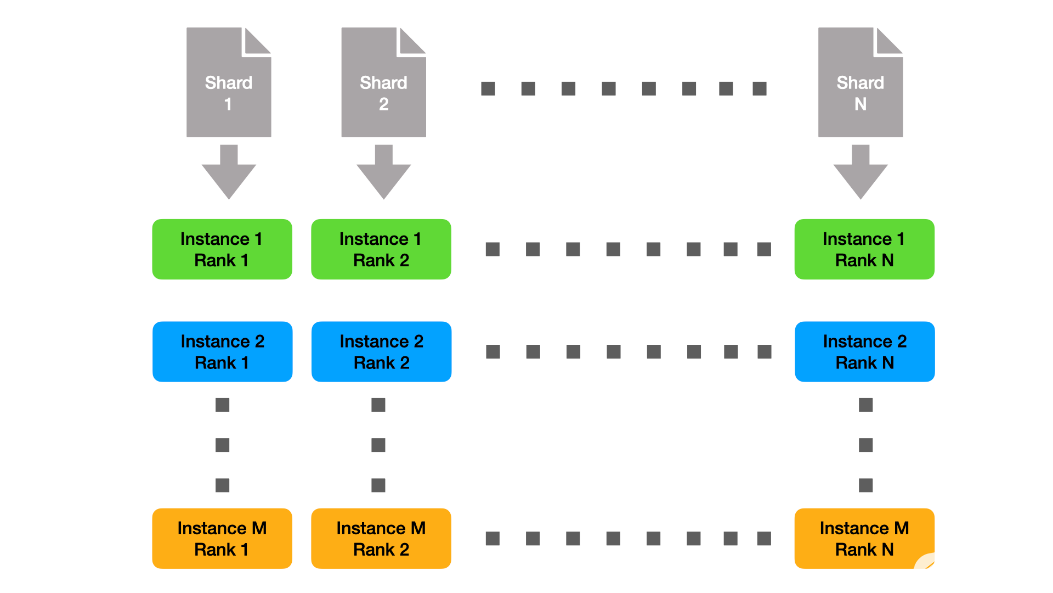
圖 1 :將列組聚集到碎片中。
請注意,跨實例,具有相同列組 ID 的每個列組使用相同的數據碎片。這意味著在本機上,每個數據碎片被讀取 M 次。為了減輕文件系統的壓力,我們創建了與實例正交的數據子硬盤,如圖 2 所示。
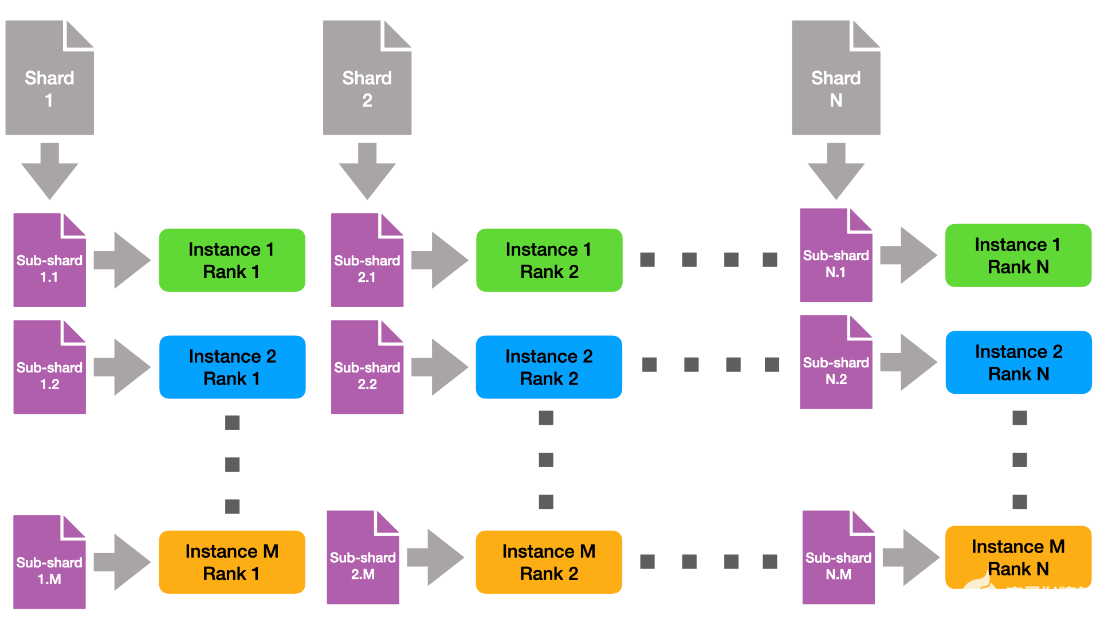
圖 2 :亞硬化的演示。
這樣,每個文件從全局文件系統只讀一次。最后,每個實例都需要接收所有數據。為此,我們創建了與實例內通訊器正交的新 MPI 通訊器,也就是說,我們將具有相同列組 id 的所有實例列組組合到相同的實例間通訊器中。然后,我們可以使用 MPI allgather 將各個子硬盤組合成原始碎片的 M 個副本。
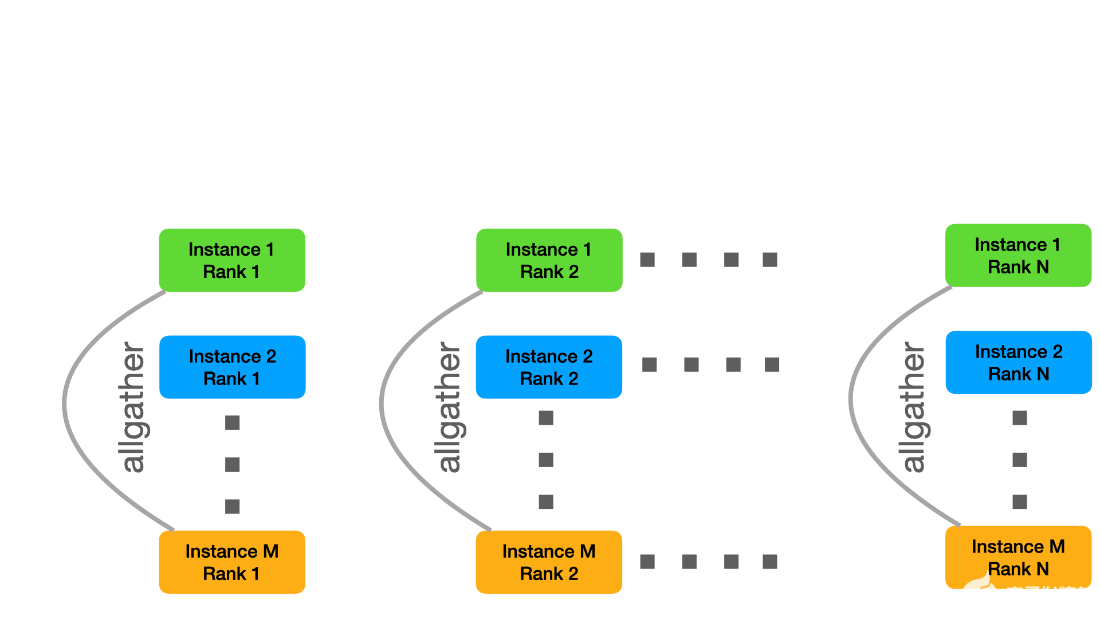
圖 3 :子硬塊的分布。
我們不按順序執行這些步驟,而是使用批處理來創建一個管道,該管道與子硬盤的數據讀取和分發重疊。為了提高讀寫性能,我們進一步實現了一個小型輔助工具,它使用 O _ DIRECT 來提高 I / O 帶寬。
優化使 DeepCAM 基準測試的端到端加速比超過 2 倍。這在提交文件 repository 中提供。
損失函數的混合編程
使用命令式編程可以靈活地定義和運行模型,這樣定義一個機器學習模型就像寫一個python程序。與此相對的是符號式編程,它會先定義計算過程,然后再執行。這種編程方法允許執行引擎進行各種優化,但丟失了命令式方法的靈活性。
MXNet 框架采用了合并這兩種方法的混合式編程。命令式定義的計算可以被編譯成符號式,并在可能時進行優化。CosmoFlow 將模型混合式編程進行了擴展,把損失函數也包含進來。
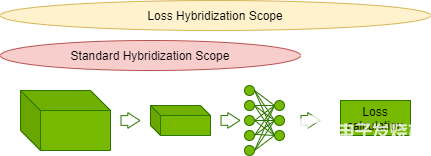
圖 4 :損失函數的模型混合式。
這允許將損耗計算中的元素操作與 CosmoFlow 模型的縮放激活輸出進行融合,從而減少總體迭代延遲。優化使 CosmoFlow 的端到端性能提高了近 5% 。
節間均采用夏普處理,降低了集體成本
SHARP 允許將集合操作從 CPU 卸載到節間網絡結構中的交換機。這有效地將 allreduce 操作的 InfiniBand 網絡的節間帶寬增加了一倍。這種優化可使 MLPerf HPC 基準測試的性能提高高達 5% ,特別是在強擴展場景中。
繼續使用 MLPerf HPC
科學家們正在加速取得突破,部分原因是人工智能和高性能計算相結合,能夠比傳統方法更快、更準確地提供洞察力。
MLPerf HPC v1 . 0 反映了超級計算行業對客觀、同行評審的方法的需求,以測量和比較與 HPC 相關用例的 AI 培訓性能。在這一輪中, NVIDIA 計算平臺通過損壞所有三個性能基準來證明清晰的領導,同時也證明了兩個吞吐量測量的最高效率。
關于作者
Sukru Burc Eryilmaz 是 NVIDIA 計算機體系結構的高級架構師,他致力于在單節點和超級計算機規模上改進神經網絡訓練的端到端性能。他從斯坦福大學獲得博士學位,并從比爾肯特大學獲得學士學位。
-
NVIDIA
+關注
關注
14文章
5026瀏覽量
103280 -
計算機
+關注
關注
19文章
7520瀏覽量
88249 -
MLPerf
+關注
關注
0文章
35瀏覽量
647
發布評論請先 登錄
相關推薦
APView500PV電能質量在線監測裝置安裝使用說明書V1.0
ESP32-CAM Wi-Fi+BT SoC模組 V1.0
浪潮信息AI存儲性能測試的領先之道

浪潮信息AS13000G7榮獲MLPerf? AI存儲基準測試五項性能全球第一
第四章:對廣東龍芯2K0300-蜂鳥板-v1.0視頻教程我的感觸
qdprobot for mixly軟件及模塊操作教程v1.0
TC397_TFT v1.0開發板編譯燒錄任意ADS程序會進Context Maneger Error Trap如何解決?
芯海應用筆記:CSU3AF10 IAP功能設計指南_V1.0
2024年,RISC-V能在HPC上實現突破嗎?
OK3568-C開發板_AMP_Linux4.19.232+QT5.15.8_用戶編譯手冊_V1.0
賽昉系列:OK7110-C_Qt5.15.2+Linux5.15.0_編譯手冊_V1.0
賽昉系列:OK7110-C_Qt5.15.2+Linux5.15.0_軟件手冊_V1.0
軟通動力天鶴數據復制服務系統V1.0獲得華為技術認證書





 工商網監
工商網監
評論