 人工智能的透明度和可解釋性義務
人工智能的透明度和可解釋性義務
2021 年 4 月 21 日,歐盟委員會向 h ARM 發布了一項法規提案,將 AI 系統的設計和營銷規則稱為人工智能法( AIA )。
監管機構認為人工智能系統存在風險。高風險人工智能系統將受到具體設計和實施義務的約束,以提高透明度。信用評分模型是高風險用例的一個例子。
在《人工智能法》出臺之前,關于透明度的原則已經出現在一些歐洲人工智能準則中。例如,在可信人工智能的道德準則中,數據、系統設計和業務模型應該是透明的。與透明度相關的是,人工智能系統的技術過程和相關的人類決策都必須是可解釋的。
歐盟 Horizon2020 研究與創新項目FIN-TECH中也討論了人工智能的透明度和可解釋性義務。
該項目開發了新的方法和用例,以管理風險,并在歐洲金融服務領域擴展數字金融和人工智能。 20 多所大學以及歐洲監管和金融服務界參與了研討會、培訓和用例演示,并對用例進行了反饋和評估。

圖 1 :歐盟 Horizon2020 項目FIN-TECH(左)和歐盟委員會(右)的標志。根據第 825215 號贈款協議( ICT-35-2018 主題,行動類型: CSA ),該項目獲得了歐盟地平線 2020 研究與創新計劃的資助。內容僅反映了作者的觀點,委員會不負責對其所含信息的任何使用。
該項目中評級最好的 AI 用例是用于信用風險管理的可解釋 AI ( XAI )方法,該方法旨在克服 AI 模型的可解釋性差距。該項目的評估系統根據歐洲監管當局、中央銀行、金融服務公司和金融科技公司的結構化反饋確定了該案例。
該用例在 Springer 上以“可解釋機器學習在信用風險管理中的應用”的形式發布,并使用夏普利值和SHAP( SHapley 加法解釋)來確定已經訓練過的 AI / ML 模型中決策的最重要變量。它的靈感來源于英格蘭銀行(“金融學中的機器學習可解釋性:在違約風險分析中的應用”)發布的一個模型。
基礎方法分析本地或全球解釋性數據,分組或集群,其中每個集群由具有非常相似解釋性數據的投資組合組成。通過這種方式,可以深入了解經過訓練的模型的內部工作原理,從而對其進行潛在的調試和控制。該方法還可以在解釋性數據中調查網絡和復雜系統的影響。
這是一種非常簡單的技術,工作流和算法組合可以應用于許多人工智能( AI )和機器學習( ML )應用程序。在描述該概念的好處和使用場景之前,我們將討論該方法的計算挑戰以及使用高性能計算( HPC )中使用的技術加速此類模型的需求。
加速建模、解釋性和可視化
與實際數據相比, FIN-TECH 中使用的原始數據集相當小。由于有必要在更大的數據集上測試模型,以了解金融機構大規模生產環境的影響, NVIDIA 的一個團隊在RAPIDS中實施了整個工作流,以快速處理大量數據。這種改進的性能允許更快的迭代,節省數據科學團隊的時間,并允許更快地獲得更好的結果。
RAPIDS 是一套開源 Python 庫,可以使用 GPU 加速來加速端到端數據科學工作流。在本用例中,它加速了整個工作流:
數據加載與預處理
Training
解釋(形狀值)
對 SHAP 值進行聚類
降維
可視化與過濾
該團隊處理了一組類似于解釋和加速貸款拖欠的機器學習上相關博客中的數據集的房利美數據集,其中包含數百萬個數據點。
SHAP 值被分組,但也可以通過網絡圖分析進行分析。 RAPIDS ‘ GPU – 加速庫cuML(機器學習算法)和cuGraph(圖形分析)非常適合此用例。這也適用于降維,以便以后在 2D 或 3D 中繪制形狀點云。此外,可以使用 GPU – 加速Plotly和其他工具構建以下過濾和可視化步驟。
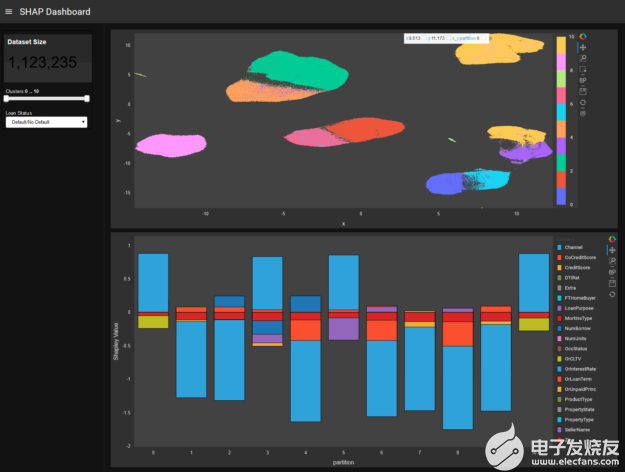
圖 2 :儀表板用戶可以與模型的 SHAP 值交互,并進一步分析模型級別的全貌或深入到模型的特定“區域”。為了便于解釋,上圖中的每一組點代表一組編號為 0 到 10 的類似貸款。每個簇在底部圖中具有特征,簇編號沿 x 軸。對于給定的簇,矩形的高度對應于數據集中的 Shapley 值和 credit customer mortgage loan 特征的顏色。從正 Shapley 值或負 Shapley 值,可以看出集群的功能如何使貸款減少(負方向)或增加(正方向),可能會默認。
例如,可以顯示整個模型的形狀簇,并進一步分析特定簇和數據點,在更細粒度的級別上查看特征貢獻和交互。此外,顏色代碼可以從形狀視圖切換到高亮顯示真實和預測的類標簽,并顯示特征。
此外,最近的Captum和Captum軟件包中提供的 GPU 解釋程序加速了任何 cuML 或 scikit 學習模型的預測后解釋。對于基于樹的模型,如 XGBoost , SHAP Explainer 可以計算輸入特征的 Shapley 值。深度學習模型可以使用 SHAP GradientExplainer 或 Captum GradientShap 方法來計算 Shapley 值,方法是計算關于輸入特征和添加高斯隨機噪聲的特征的梯度。 SHAP 和 Captum 都使用 GPU s 來加速 Shapley 值的計算。
對模型的深入研究
本文介紹的基于機器學習的可視化過程處理另一個任意 AI / ML 模型的結果。它為已經訓練過的、可能不透明的機器學習模型提供了更多的 i NSight 、控制和透明度。
它采用了一種模型不可知的方法,旨在以可變重要性(個人輸入變量貢獻)的形式確定人工智能系統的決策標準,并應用于信用風險評估和管理以及投資組合構建等其他金融領域。
關鍵概念是模型的夏普里值分解,這是合作博弈論中的一個收益分配概念。到目前為止,它是唯一植根于經濟基礎的 XAI (可解釋 AI )方法。它提供了對預測概率的變量貢獻的細分,從 0 到 1 。這意味著每個數據點(例如,投資組合中的信貸或貸款客戶)不僅由輸入特征(機器學習模型的輸入)表示,而且還由這些輸入特征對經過訓練的機器學習模型的二進制預測的貢獻 0 或 1 表示。
Shapley 解釋值可用于基于降維技術(如 PCA 、 MDS 、 t-SNE )的可視化映射,或用于表示學習(如聚類和圖形分析)(如社區檢測和網絡中心度測量)。這些數據驅動的學習表示揭示了數據點的分段(客戶)其中每個集群包含非常相似的決策標準,而其他集群中的數據點顯示非常不同的決策標準。
層次聚類,尤其是圖論和網絡分析非常適合研究復雜系統,如信貸組合的 Shapley 解釋值。這些系統具有突發性、自組織性的特點。該方法將(可能不透明的) AI / ML 模型的可變貢獻結果視為一個復雜系統,并通過圖論和聚類分析進一步分析其性質。通過這種方式,用戶可以更好、更深入地了解 AI / ML 模型到底學到了什么,因為不同的解釋數據點被分組(集群)或作為具有特定鏈接結構的網絡進行排列。
可以分析和理解集群和網絡結構內部的以下現象:趨勢、異常、熱點、緊急效應和引爆點。由于該方法是模型不可知的,因此它可以應用于任何 AI / ML 模型。這還可以對基于相同數據訓練的多個模型進行比較。
在下文中,我們描述了基于 SHAP 集群和交互式可解釋性儀表板的擬議方法的一些用例場景:
數據點的組或簇表示 AI / ML 模型的類似決策。
聚類間相交處的數據點指向模糊決策,可進一步研究。
對默認和非默認的預測量幾乎相等的集群可能會指出機器學習模型中的錯誤或問題。
客戶細分:數據點不僅可以通過其輸入變量(代表客戶相似性的聚類)進行聚類,還可以通過其在決策中的變量貢獻進行聚類。
提出的可解釋性模型的目標是傳統銀行以及 P2P 貸款/眾籌的“ fintech ”平臺中信貸組合的風險管理、評估和評分功能。
指導方針和法規需要模型解釋
AI HLEG 起草的道德準則提出了一種以人為中心的 AI 方法,并列出了 AI 系統應滿足的幾個關鍵要求,以便被認為是可信的。
提出的 SHAP 聚類有助于縮小人工智能的解釋鴻溝。監管人員將調整其方法和技能,以支持在銀行業引入 AI / ML 。銀行需要弄清楚人類在模型監管中的位置,并且必須向監管人員合理解釋其 AI / ML 系統的實際功能以及目的。
決策必須是知情的,而且必須有人參與監督。 SHAP 聚類方法使用戶能夠理解做出決策的原因。“為什么”不是因果關系,而是表示為輸入變量的數值貢獻。用戶可以查看特定的數據點或集群,并查看輸入變量、變量對預測的貢獻以及預測本身。
一個看似合理的解釋可能會出現,使基于機器的決策與“有意義”的人類敘事相協調。模型可以更好地控制,因為它提供了關于如何在全局層面(全局變量重要性)和局部層面(數據點)上做出所有決策的反饋。集群步驟甚至為特定集群的成員提供了可變的貢獻,對于一組客戶也是如此。用戶可以根據輸入變量識別這組客戶的屬性,以便了解這組客戶的決策過程。所有這些分析功能和工具加上交互式視覺探索,使用戶能夠更好地理解完全黑盒模型的結果。更好的理解導致更有效的控制。
為確保可追溯性,應納入符合最佳標準的文件編制機制。除其他外,這包括用于模型培訓和驗證的數據集文檔、任何數據標簽的過程和輸出,以及人工智能系統所做決策的明確記錄。
SHAP 聚類方法允許追溯和記錄對決策的可變貢獻。形狀信息的聚類是該方法添加的新信息之一,因此可用于豐富可追溯性和文檔。此外,可以記錄基于新信息改進模型的步驟。
有關該方法及其用例的更多閱讀,請參見出版物“財務風險管理和可解釋、可信、負責任的人工智能’。
結論
SHAP 聚類提供了機器學習模型的局部、全局和組級決策的解釋。這里提供的擴展允許對解釋進行進一步分析。這允許從業者為基于機器學習的決策構建一個敘述和解釋,以滿足業務、監管和客戶需求。
也許解釋性最重要的方面是受眾。模型解釋的受眾中有許多類型的人和角色:模型構建者、模型檢查者、合規和治理官、風險經理、產品所有者、高級經理、主管、客戶和監管機構。數據科學團隊可以理解原始和聚集的 SHAP 信息,銀行或金融科技公司中的大多數其他人都可以通過培訓理解。這同樣適用于監事。對于客戶/和客戶而言,提及哪些變量最重要(可能應告知客戶決策/拒絕的原因)或客戶可以做些什么來改進某些變量以獲得積極決策,這一切都可以從 SHAP 數據中得出。形狀信息提供了一個通用、一致和準確的視圖和語言來描述 AI 模型。
關于作者
Jochen Papenbrock 位于德國法蘭克福,在過去的15年中,Jochen一直在金融服務業人工智能領域擔任各種角色,擔任思想領袖、實施者、研究者和生態系統塑造者。
Mark J. Bennett 是 NVIDIA 的高級數據科學家,他專注于金融機器學習的加速。他擁有南加州大學計算機科學碩士學位和博士學位。來自加州大學洛杉磯分校的計算機科學,并為愛荷華大學和芝加哥大學教授研究生業務分析。
Emanuel Scoullos 是 NVIDIA 金融服務和技術團隊的數據科學家,他專注于 FSI 內的 GPU 應用。此前,他在反洗錢領域的一家初創公司擔任數據科學家,應用數據科學、分析和工程技術構建機器學習管道。他獲得了博士學位。普林斯頓大學化學工程碩士和羅格斯大學化學工程學士學位。
Miguel Martinez 是 NVIDIA 的高級深度學習數據科學家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導過 Udacity 人工智能納米學位的學生。他有很強的金融服務背景,主要專注于支付和渠道。作為一個持續而堅定的學習者, Miguel 總是在迎接新的挑戰。
John Ashley 目前領導 NVIDIA 的全球金融服務和技術團隊。在此之前,他啟動并領導了 NVIDIA 的專業服務深度學習實踐和 NVIDIA 深度學習專業服務合作伙伴計劃,致力于幫助客戶和合作伙伴采用并提供深度學習解決方案。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4991瀏覽量
103138 -
機器學習
+關注
關注
66文章
8421瀏覽量
132706 -
深度學習
+關注
關注
73文章
5504瀏覽量
121213
發布評論請先 登錄
相關推薦
人工智能推理及神經處理的未來

嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
動態代理IP的匿名性和透明度,為主要考慮關鍵!






 工商網監
工商網監
評論