 利用NVIDIA Volta將文本實時生成自然語音
利用NVIDIA Volta將文本實時生成自然語音
這篇文章,旨在為具有深入學習專業水平的開發人員準備,將幫助您生成一個準備生產、人工智能、文本到語音的模型。
幾十年來,將文本實時轉換為高質量、自然發音的語音一直是一項具有挑戰性的任務。最先進的語音合成模型是基于參數神經網絡 1 。文本到語音( TTS )合成通常分兩步完成。
第一步將文本轉換成時間對齊的特征,如 mel-spe CTR 圖或 F0 頻率等語言特征;
第二步將時間對齊的功能轉換為音頻。
優化的 Tacotron2 模型 2 和新的 WaveGlow 模型 1 利用 NVIDIA Volta 上的 張量核 和圖靈 GPUs 將文本實時轉換為高質量的自然發音語音。生成的音頻具有清晰的人聲,沒有背景噪音。
下面是一個使用此模型可以實現的示例:
在遵循 Jupyter 筆記本 中的步驟之后,您將能夠為模型提供英語文本,并且它將生成一個音頻輸出文件。所有重現結果的腳本都發布在我們的 NVIDIA 深度學習示例 存儲庫的 GitHub 上,其中包含幾個使用張量核心的高性能培訓配方。此外,我們還開發了一個 Jupyter 筆記本 ,供用戶創建自己的容器映像,然后下載數據集,逐步重現訓練和推理結果。
模型
我們的 TTS 系統是兩個神經網絡模型的組合:
從“ 基于 Mel-Spe CTR 圖預測的條件波網自然合成 TTS ”改進的 Tacotron 2 (圖 1 )模型;
來自“ WaveGlow :一種基于流的語音合成生成網絡 ”的基于流的神經網絡模型。
Tacotron 2 和 WaveGlow 模型構成了一個 TTS 系統,用戶可以在沒有任何附加韻律信息的情況下從原始文本合成自然發音的語音。
Tacotron 2 型號
Tacotron 2 2 是一種直接從文本合成語音的神經網絡結構。該系統由一個遞歸的序列到序列特征預測網絡組成,該網絡將字符嵌入映射到 mel 尺度的 spe CTR 圖,然后由一個改進的 WaveNet 模型作為聲碼器,從這些 spe CTR 圖合成時域波形,如圖 1 所示。
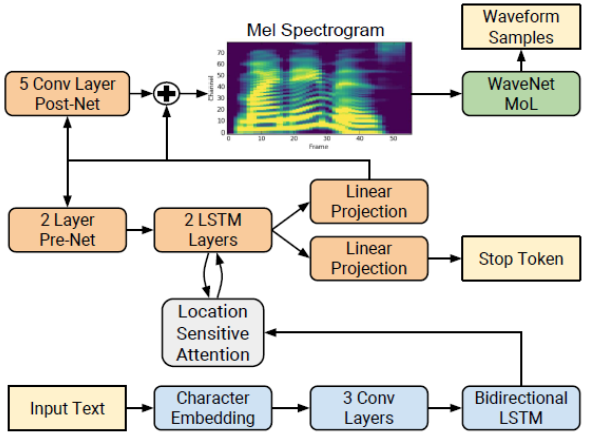
圖 1 : Tacotron 2 系統架構框圖 1
網絡由一個編碼器(藍色)和一個解碼器(橙色)組成。編碼器將一個字符序列轉換成一個隱藏的特征表示,作為解碼器的輸入來預測 spe CTR 圖。輸入文本(黃色)是使用學習的 512 維字符嵌入來呈現的,它通過三個卷積層(每個包含 512 個形狀為 5 × 1 的濾波器)的堆棧,然后進行批量規范化和 ReLU 激活。編碼器輸出被傳遞到注意力網絡( gray ),該網絡將完整編碼序列總結為每個解碼器輸出步驟的固定長度上下文向量。
解碼器是一個自回歸遞歸神經網絡,它從編碼的輸入序列中一次一幀地預測 mel-spe CTR 圖。前一個時間步的預測首先通過一個包含兩個完全連接的 256 個隱藏 ReLU 單元的層的小 pre 網絡。 prenet 輸出和注意力上下文向量被連接起來,并傳遞到一個由兩個 LSTM 層組成的堆棧,其中包含 1024 個單元。通過線性變換,將 LSTM 輸出與注意上下文向量的連接進行投影,以預測目標 spe CTR 圖幀。最后,將預測的 mel-spe CTR 圖通過一個 5 層卷積后網絡,該網絡預測一個殘差來加入預測,以改善整體重建。每個 post-net 層由 512 個形狀為 5 × 1 的過濾器組成,并進行批量標準化處理,除最后一層外,所有過濾器均激活。
我們實現的 Tacotron 2 模型與 1 中描述的模型不同,我們使用:
退出而不是分區,以使 LSTM 層正則化;
用 WaveGlow 模型 2 代替 WaveNet 來合成波形。
WaveGlow 模型
WaveGlow 1 是一種基于流的網絡,能夠從 mel-spe CTR 圖生成高質量的語音。 WaveGlow 結合了 Glow 5 和 WaveNet 6 的見解,以提供快速、高效和高質量的音頻合成,而無需自動回歸。 WaveGlow 只使用一個網絡實現,只使用一個單一的成本函數進行訓練:使訓練過程簡單而穩定。我們當前的模型以 55 * 22050 = 1212750 的速度合成樣本,這比每秒 22050 個樣本的“實時”要快 55 倍。平均意見得分( MOS )表明,它提供的音頻質量與在同一數據集上訓練的最佳公開可用 WaveNet 實現一樣好。
WaveGlow 是一種生成模型,它通過從分布中采樣來生成音頻。為了使用神經網絡作為生成模型,我們從一個簡單的分布中提取樣本,在我們的例子中,是一個零均值的球面高斯分布,其維數與我們期望的輸出相同,然后將這些樣本通過一系列層將簡單分布轉換為具有期望分布的分布。在這種情況下,我們根據 mel-spe CTR 圖對音頻樣本的分布進行建模。
如圖 2 所示,對于通過網絡的前向傳遞,我們將八個音頻樣本組作為向量,“壓縮”操作,如 Glow 5 所示。然后我們通過幾個“流程步驟”處理這些向量。這里的流動步驟由可逆的 1 × 1 卷積和仿射耦合層組成。在仿射耦合層中,一半的信道作為輸入,然后產生乘法和加法項,用于縮放和平移剩余的信道。

圖 2 : WaveGlow 網絡 2
啟用自動混合精度
混合精度 通過以半精度格式執行操作,同時以單精度( FP32 )存儲最少的信息,從而在網絡的關鍵部分盡可能多地保留信息,從而顯著提高了計算速度。啟用混合精度利用了 Volta 和 Turing GPUs 上的 張量核 ,在訓練時間上提供了顯著的加速——在運算最密集的模型架構上,整體加速高達 3 倍。
使用 混合精度訓練 之前需要兩個步驟:
在適當的情況下移植模型以使用 FP16 數據類型;
手動添加損耗縮放以保持較小的漸變值。
通過使用 PyTorch 中的自動混合精度( AMP )庫, APEX 中啟用了混合精度,該庫在檢索時將變量強制轉換為半精度,同時以單精度格式存儲變量。為了在反向傳播中保持較小的梯度值,應用漸變時必須包含 損耗標度 步驟。在 PyTorch 中,通過使用 AMP 提供的 scale _ loss ()方法,可以很容易地應用損耗縮放。要使用的縮放值可以是 dynamic 或 fixed 。
通過在訓練腳本中添加– amp run 標志,可以啟用張量核心的混合精度訓練,您可以在我們的 Jupyter 筆記本 中看到示例。
培訓業績
表 1 和表 2 比較了采用 PyTorch -19 。 06-py3 NGC 容器 在帶有 8-V100 16GB GPUs 的 NVIDIA DGX-1 上使用改進的 Tacotron 2 和 WaveGlow 模型的訓練性能。在整個訓練周期內,平均性能數( Tacotron 2 的輸出 mel spe CTR 圖每秒, WaveGlow 每秒輸出樣本數)。

表 2 : WaveGlow 模型的訓練性能結果
如表 1 和表 2 所示,使用張量核進行混合精度訓練可以實現顯著的加速,并且可以有效地擴展到 4 / 8 GPUs 。混合精度訓練也保持了與單精度訓練相同的精度,并允許更大的批量。語音質量取決于模型大小和訓練集大小;使用具有自動混合精度的張量核,可以在相同的時間內訓練出質量更高的模型。
考慮到高質量所需的模型大小和培訓量, GPUs 提供了一個最合適的硬件架構,并將吞吐量、帶寬、可伸縮性和易用性進行了最佳組合。
推理性能
表 3 和表 4 分別顯示了從 1-V100 和 1-T4 GPU 上的 1000 次推理運行中收集的 Tacotron2 和 WaveGlow 文本到語音系統的推理統計數據。從 Tacotron2 推斷開始到 WaveGlow 推斷結束,測量潛伏期。這些表包括平均延遲、標準偏差和延遲置信區間(百分比值)。吞吐量是以每秒生成的音頻樣本數來衡量的。 RTF 是一個實時因子,它告訴我們在 1 秒鐘的壁時間內產生了多少秒的語音。
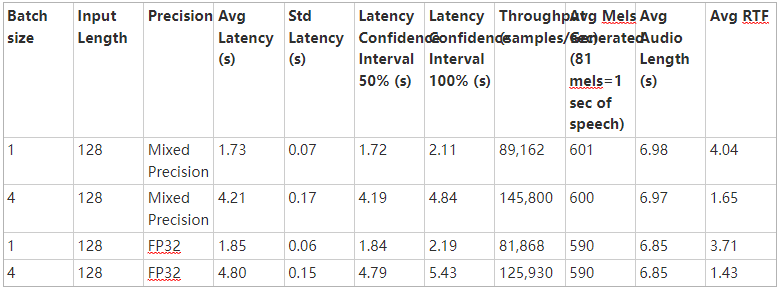
表 3 : 1-V100 GPU 上 Tacotron2 和 WaveGlow 系統的推斷統計
與 FP32 相比,我們可以看到混合精度推理具有較低的平均延遲和延遲置信區間(百分比值),同時實現更高的吞吐量并生成更長的平均 RTF ( 1 秒壁時間內的語音秒數)。
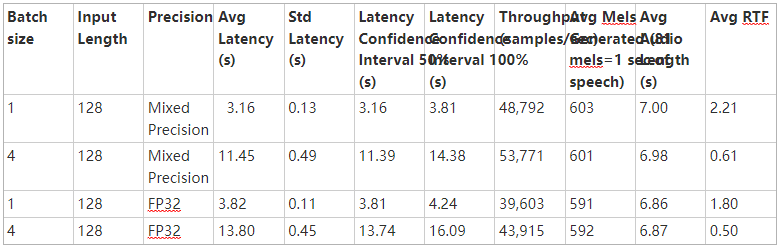
表 4 : 1-T4 GPU 上 Tacotron2 和 WaveGlow 系統的推斷統計
一步一步運行 Jupyter 筆記本
為了達到上述結果:
按照 GitHub 上的腳本操作或逐步運行 Jupyter 筆記本 來訓練 Tacotron 2 和 WaveGlow v1 。 5 模型。在 Jupyter 筆記本 中,我們提供了完全自動化的腳本來下載和預處理 LJ 語音數據集 ;
數據準備步驟完成后,使用提供的 Dockerfile 構建修改后的 Tacotron 2 和 WaveGlow 容器,并在容器中啟動一個分離的會話;
要使用帶張量核心的 AMP 或使用 FP32 訓練我們的模型,請使用 Tacrotron 2 的默認參數和使用單個 GPU 或多個 GPUs 的 WaveGlow 模型執行訓練步驟。
Training
Tacotron2 和 WaveGlow 模型分別獨立地進行訓練,兩個模型在訓練過程中通過短時傅立葉變換( STFT )得到 mel-spe CTR 圖。這些 mel-spe CTR 圖用于 Tacotron 2 情況下的損耗計算,以及在波輝光的情況下作為網絡的調節輸入。
整個驗證數據集的平均損失是訓練損失的平均值。對于 Tacotron 2 模型,性能是以每秒的總輸入令牌數來報告的,而對于 WaveGlow 模型,則是以每秒的總輸出樣本數來報告的。在輸出日志中,這兩個度量值都被記錄為 train _ iter _ items / sec (每次迭代后)和 train _ epoch _ items / sec (在 epoch 上的平均值)。結果在整個訓練周期內取平均值,并在訓練中包含的所有 GPUs 上求和。
默認情況下,我們的訓練腳本將使用張量 cCores 啟動混合精度訓練。您可以通過刪除– fp16 run 標志來更改此行為。
Inference
在訓練了 Tacotron 2 和 WaveGlow 模型,或者下載了各自模型的預先訓練的檢查點之后,您可以執行以文本為輸入的推理,并生成一個音頻文件。
您可以根據文本文件的長度自定義文本文件的內容,可能需要將– max decoder steps 選項增加到 2000 。 Tacotron 2 模型是在 LJ 語音數據集 上訓練的,音頻樣本不超過 10 秒,相當于 860 個 mel spe CTR 圖。因此,這種推斷在生成相似長度的音頻樣本時可以很好地工作。我們將 mel-spe CTR 圖長度限制設置為 2000 (約 23 秒),因為實際上它仍然可以生成正確的聲音。如果需要,用戶可以將較長的短語分成多個句子,并分別合成它們。
關于作者
Maggie Zhang 是 NVIDIA 的深度學習工程師,致力于深度學習框架和應用程序。她在澳大利亞新南威爾士大學獲得計算機科學和工程博士學位,在那里她從事 GPU / CPU 異構計算和編譯器優化。
Grzegorz Karch 是 NVIDIA 深度學習軟件組的高級 CUDA 算法工程師,專注于語音合成的生成模型。 Grzegorz 擁有德國斯圖加特大學計算機科學博士學位,在那里他的研究集中在科學可視化上。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5024瀏覽量
103265 -
深度學習
+關注
關注
73文章
5507瀏覽量
121298
發布評論請先 登錄
相關推薦
如何使用自然語言處理分析文本數據
NVIDIA推出全新生成式AI模型Fugatto
語音識別與自然語言處理的關系
ASR與自然語言處理的結合
如何使用 Llama 3 進行文本生成
NVIDIA文本嵌入模型NV-Embed的精度基準
nlp自然語言處理基本概念及關鍵技術
語音識別和自然語言處理的區別和聯系
Transformer模型在語音識別和語音生成中的應用優勢
自然語言處理是什么技術的一種應用
NVIDIA生成式AI研究實現在1秒內生成3D形狀

Cadence與NVIDIA聯合推出利用加速計算和生成式AI重塑設計
NVIDIA Isaac將生成式AI應用于制造業和物流業





 工商網監
工商網監
評論