 高效框架互操作性第2部分:數據加載傳輸瓶頸和RDMA解決方案
高效框架互操作性第2部分:數據加載傳輸瓶頸和RDMA解決方案
高效的管道設計對數據科學家至關重要。在編寫復雜的端到端工作流時,您可以從各種構建塊中進行選擇,每種構建塊都專門用于特定任務。不幸的是,在數據格式之間重復轉換容易出錯,而且會降低性能。讓我們改變這一點!
在本系列文章中,我們將討論高效框架互操作性的不同方面:
在第一個職位中,討論了不同內存布局以及異步內存分配的內存池的優缺點,以實現零拷貝功能。
在這篇文章中,我們將重點介紹數據加載/傳輸過程中出現的瓶頸,以及如何使用遠程直接內存訪問( RDMA )技術來緩解這些瓶頸。
在第三篇文章中,我們深入討論了端到端管道的實現,展示了所討論的跨數據科學框架的最佳數據傳輸技術。
要了解有關框架互操作性的更多信息,請查看 NVIDIA GTC 2021 年會議上的演示。
數據加載和數據傳輸瓶頸
數據加載瓶頸
到目前為止,我們假設數據已經加載到內存中,并且使用了單個 GPU 。本節重點介紹了 MIG 在將數據集從存儲器加載到設備內存或使用單節點或多節點設置在兩個 GPU 之間傳輸數據時出現的幾個瓶頸。然后我們討論如何克服它們。
在傳統工作流(圖 1 )中,當數據集從存儲器加載到 GPU 內存時,數據將使用 CPU 和 PCIe 總線從磁盤復制到 GPU 內存。加載數據至少需要兩份數據副本。第一種情況發生在將數據從存儲器傳輸到主機內存( CPU RAM )時。將數據從主機內存傳輸到設備內存( GPU VRAM )時,會出現數據的第二個副本。
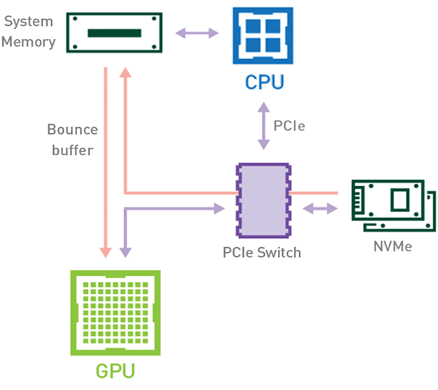
圖 1 :在傳統設置下,存儲器 CPU 內存和 GPU 內存之間的數據移動。
或者,使用利用 NVIDIA Magnum IO GPUDirect Storage 技術的基于 GPU 的工作流(見圖 2 ),數據可以使用 PCIe 總線直接從存儲器流向 GPU 存儲器,而無需使用 CPU 或主機存儲器。由于數據只復制一次,因此總體執行時間縮短。不涉及此任務的 CPU 和主機內存也使這些資源可用于管道中其他基于 CPU 的作業。
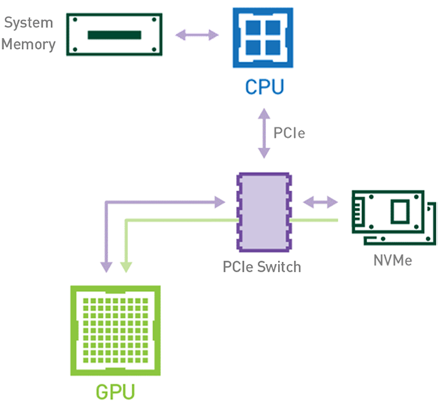
圖 2 :啟用 GPU 直接存儲技術時,存儲器和 GPU 內存之間的數據移動。
節點內數據傳輸瓶頸
某些工作負載要求位于同一節點(服務器)中的兩個或多個 GPU 之間進行數據交換。在 NVIDIA GPUDirect Peer to Peer 技術不可用的情況下,來自源 GPU 的數據將首先通過 CPU 和 PCIe 總線復制到主機固定共享內存。然后,數據將通過 CPU 和 PCIe 總線從主機固定共享內存復制到目標 GPU 。請注意,數據在到達目的地之前復制了兩次,更不用說 CPU 和主機內存都參與了這個過程。圖 3 描述了前面描述的數據移動。
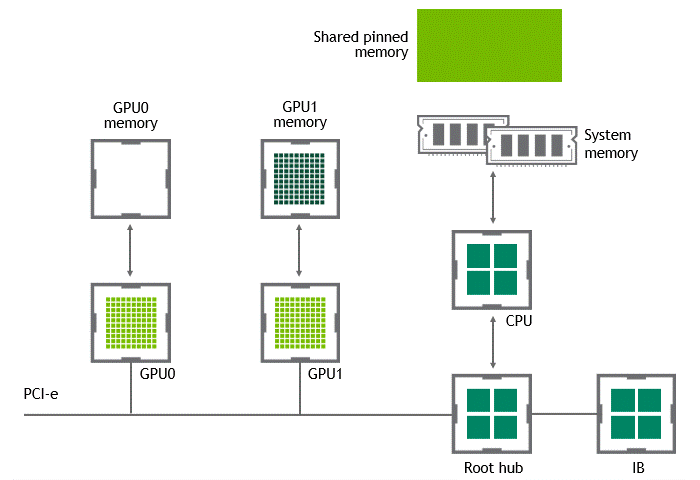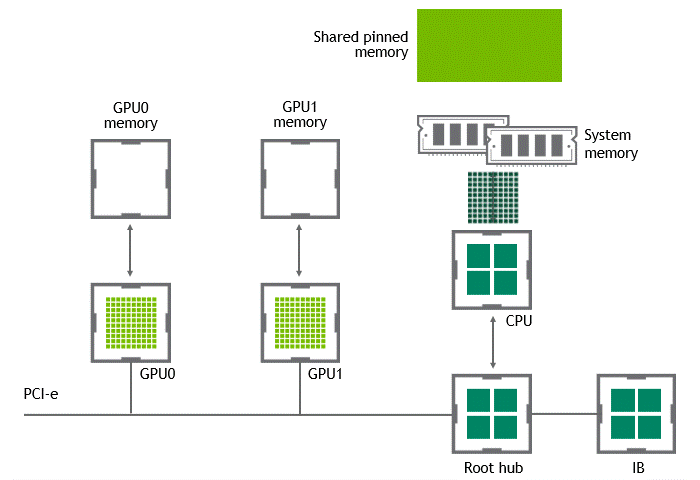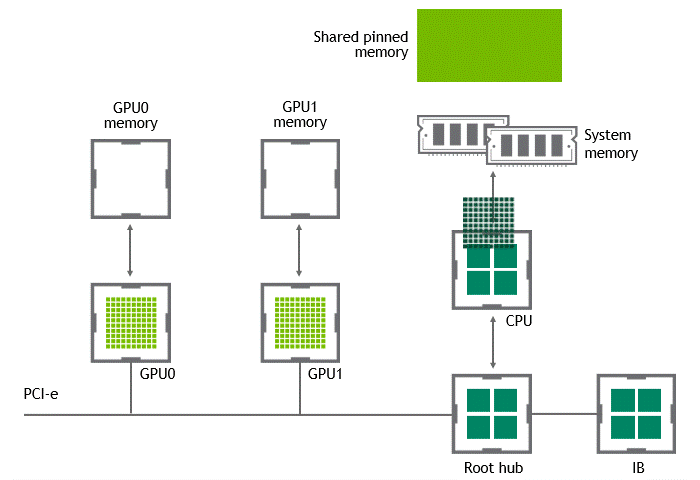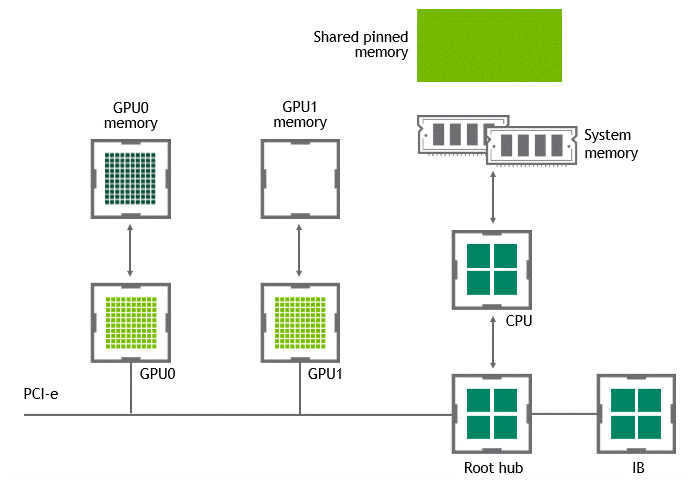
圖 3 :當 NVIDIA GPU 直接 P2P 不可用時,同一節點中兩個 GPU 之間的數據移動。
當 GPU 直接對等技術可用時,將數據從源 GPU 復制到同一節點中的另一 GPU 不再需要將數據臨時轉移到主機內存中。如果兩個 GPU 都連接到同一 PCIe 總線, GPU 直接 P2P 允許在不涉及 CPU 的情況下訪問其相應的內存。前者將執行相同任務所需的復制操作數量減半。圖 4 描述了剛才描述的行為。
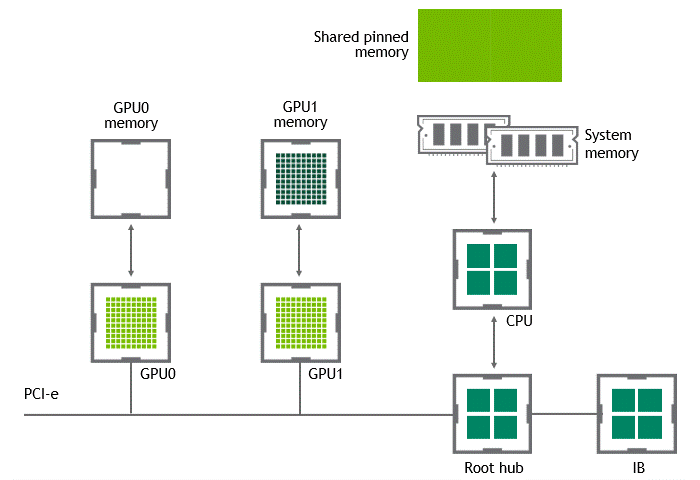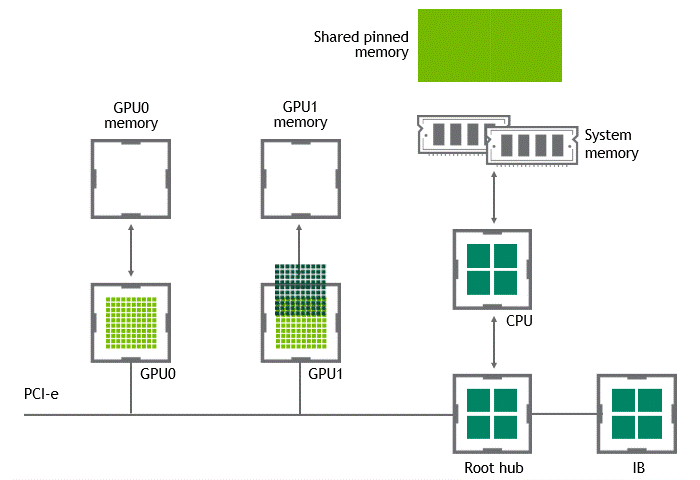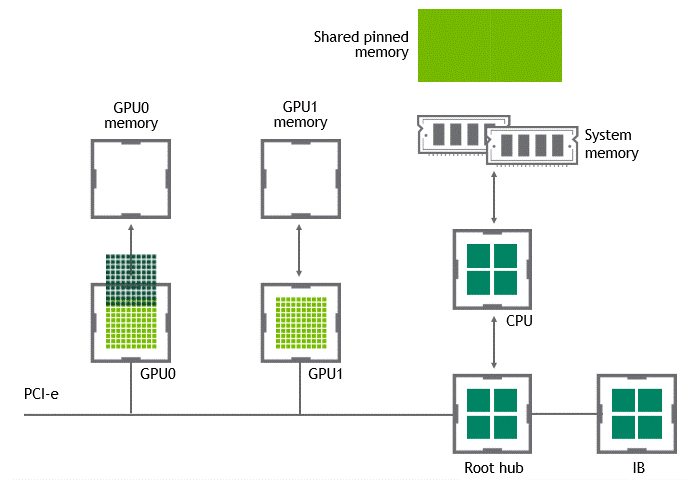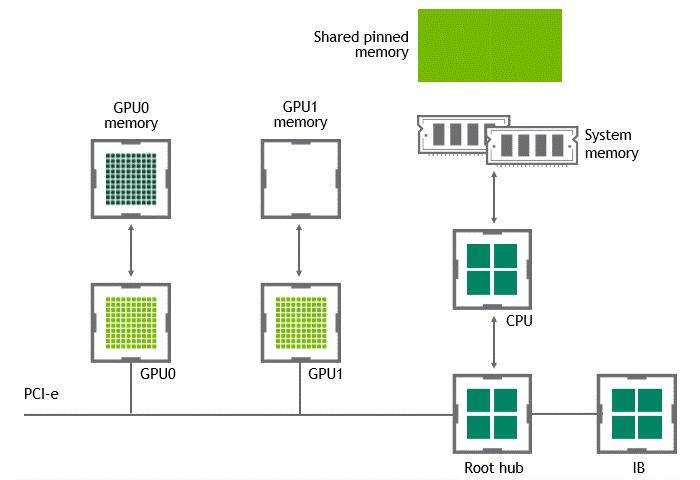
圖 4 :啟用 NVIDIA GPU 直接 P2P 時,同一節點中兩個 GPU 之間的數據移動。
節點間數據傳輸瓶頸
在 NVIDIA GPUDirect Remote Direct Memory Access 技術不可用的多節點環境中,在不同節點的兩個 GPU 之間傳輸數據需要五個復制操作:
第一次復制發生在將數據從源 GPU 傳輸到源節點中主機固定內存的緩沖區時。
然后,該數據被復制到源節點的 NIC 驅動程序緩沖區。
在第三步中,數據通過網絡傳輸到目標節點的 NIC 驅動程序緩沖區。
將數據從目標節點 NIC 的驅動程序緩沖區復制到目標節點中主機固定內存的緩沖區時,會發生第四次復制。
最后一步需要使用 PCIe 總線將數據復制到目標 GPU 。
這樣總共進行了五次復制操作。真是一次旅行,不是嗎?圖 5 描述了前面描述的過程。
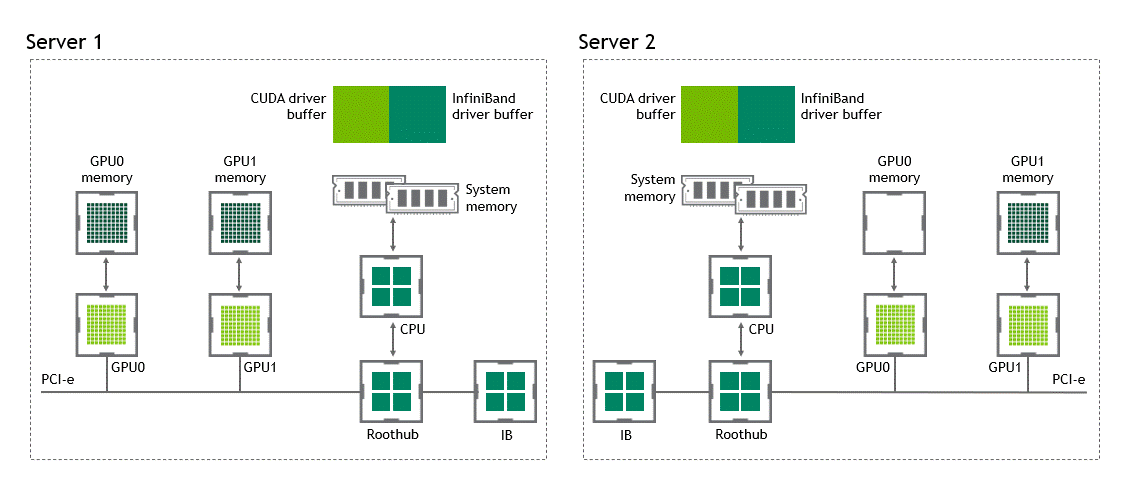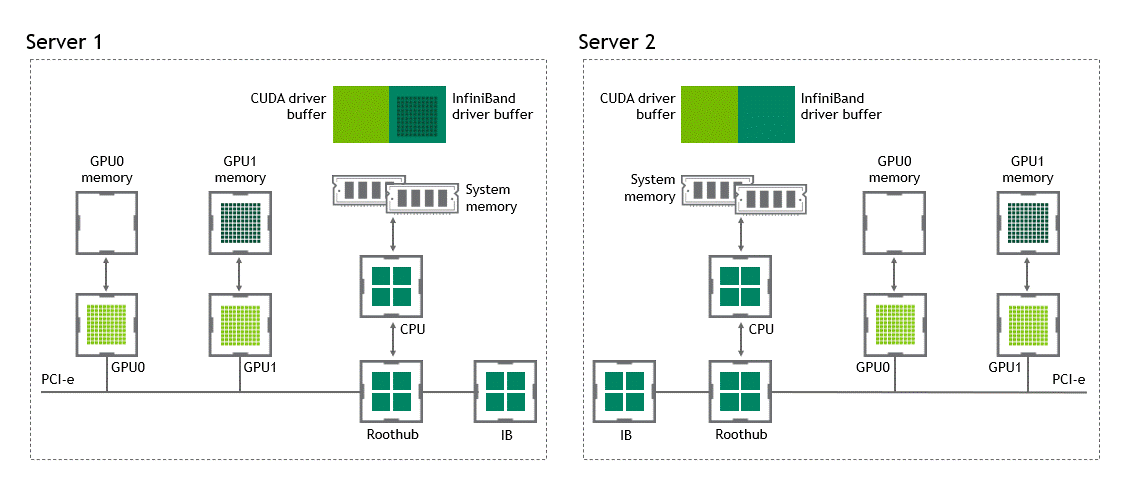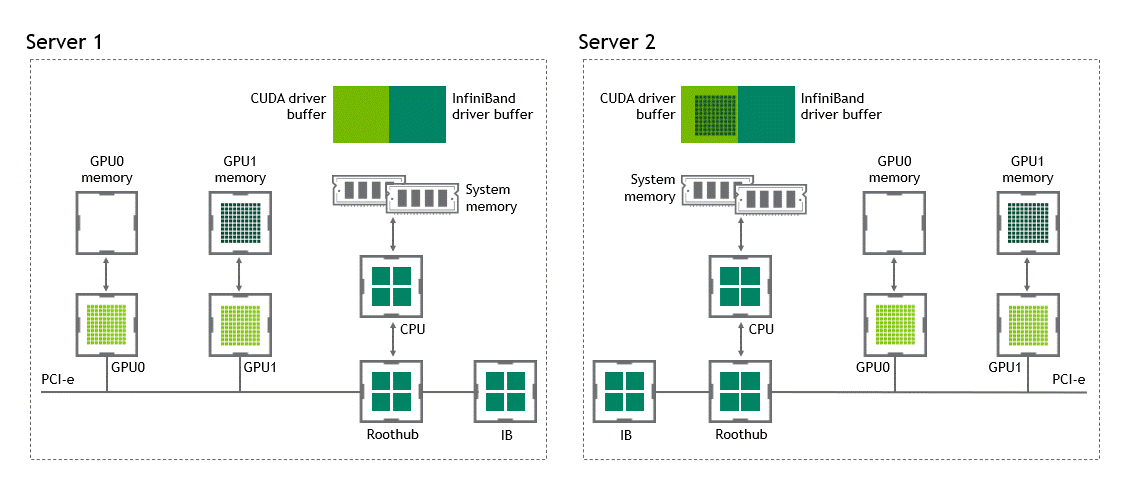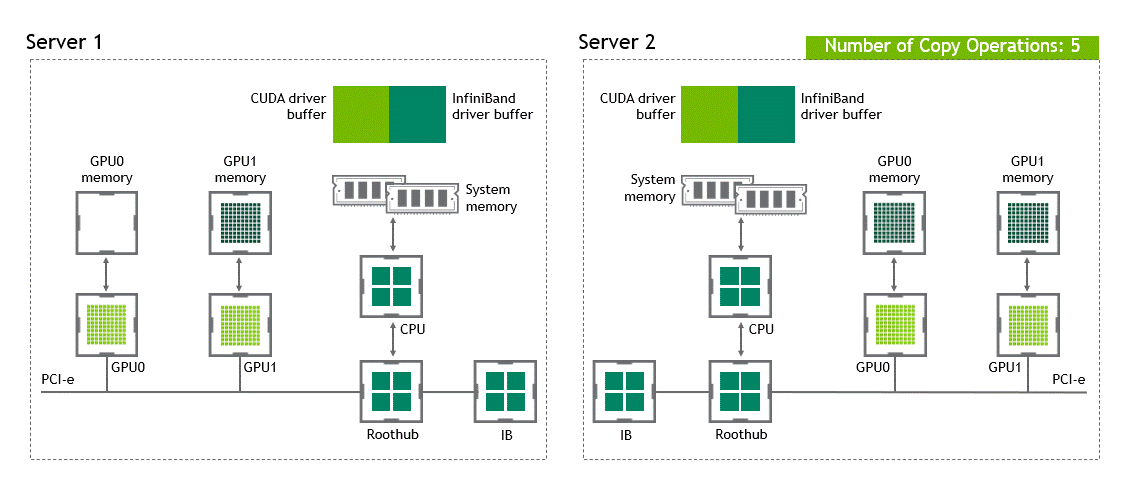
圖 5 :當 NVIDIA GPU 直接 RDMA 不可用時,不同節點中兩個 GPU 之間的數據移動。
啟用 GPU 直接 RDMA 后,數據拷貝數將減少到一個。共享固定內存中不再有中間數據拷貝。我們可以在一次運行中直接將數據從源 GPU 復制到目標 GPU 。與傳統設置相比,這為我們節省了四個不必要的復制操作。圖 6 描述了這個場景。
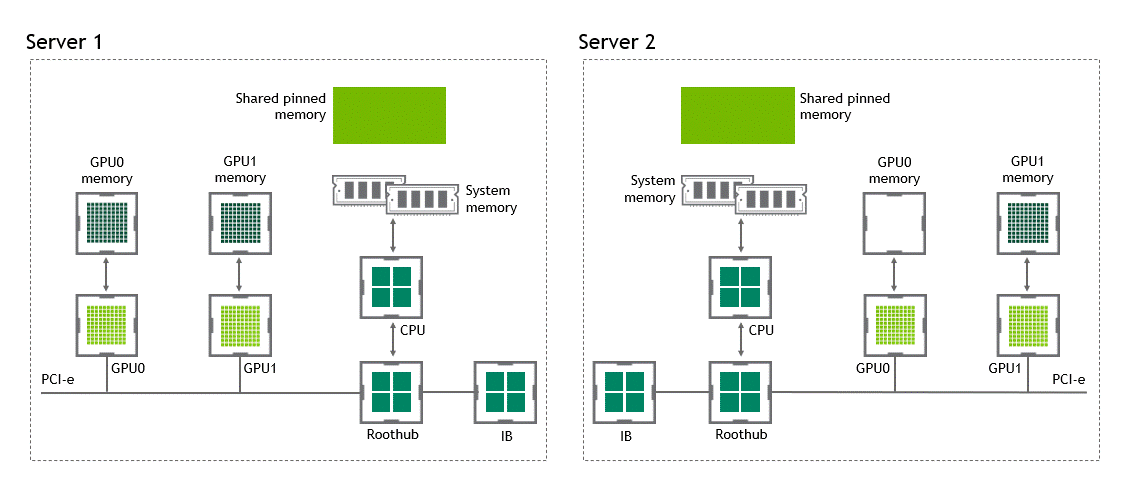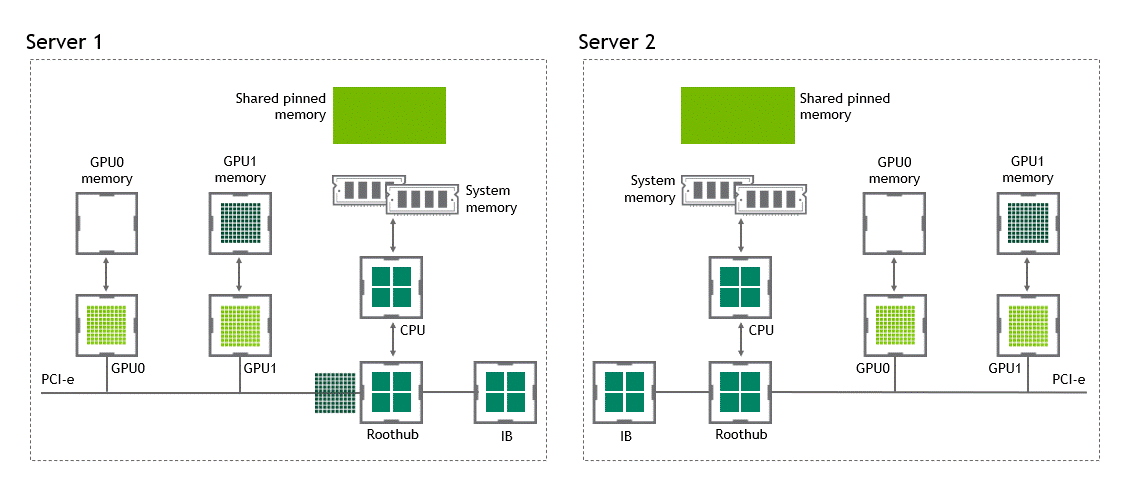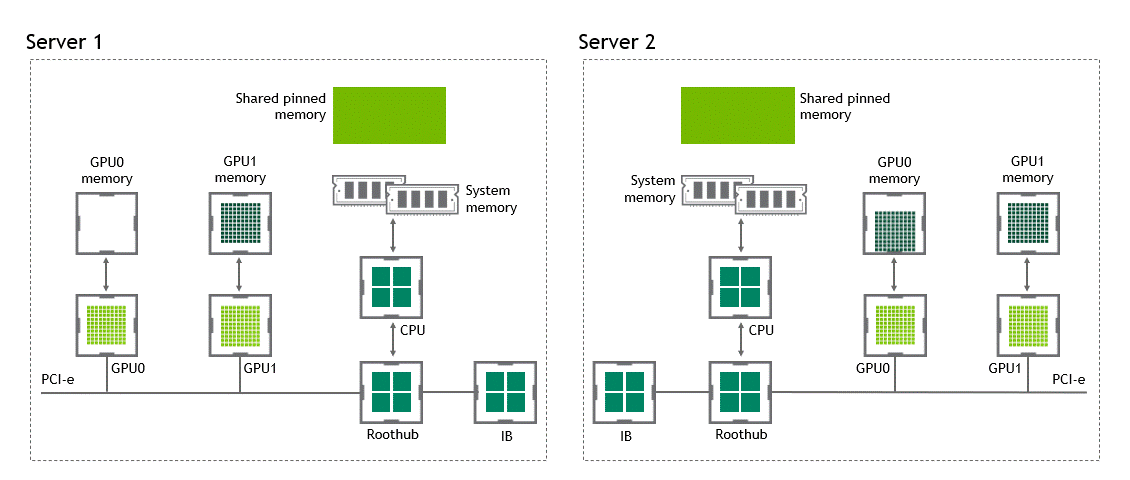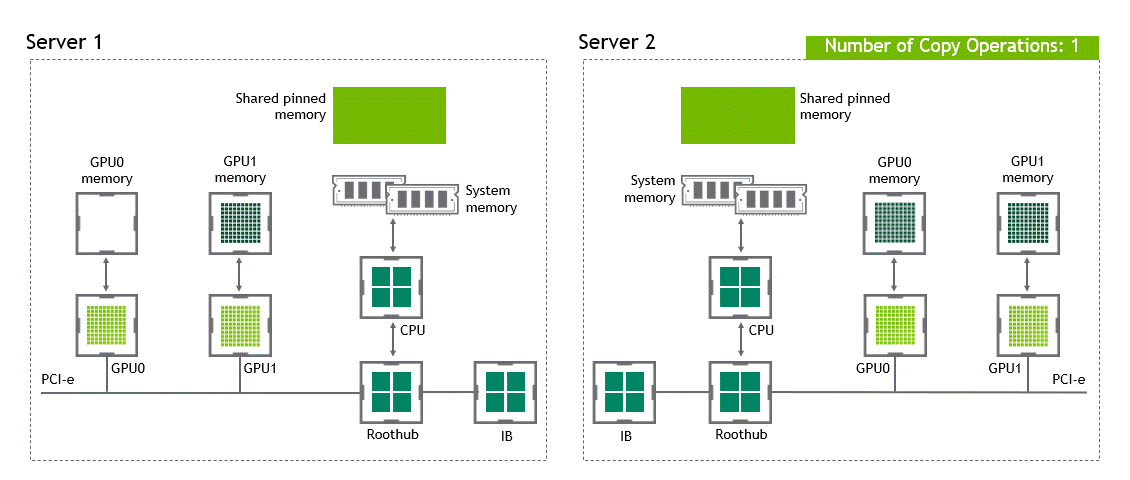
圖 6 :當 NVIDIA GPU 直接 RDMA 可用時,不同節點中兩個 GPU 之間的數據移動。
結論
在我們的第二篇文章中,您已經了解了如何利用 NVIDIA GPU 直接功能來進一步加快管道的數據加載和數據分發階段。
在我們三部曲的第三部分中,我們將深入研究醫學數據科學管道的實現細節,該管道用于連續測量的心電(ECG)流中的心跳異常檢測。
關于作者
Christian Hundt 在德國美因茨的 Johannes Gutenberg 大學( JGU )獲得了理論物理的文憑學位。在他的博士論文中,他研究了時間序列數據挖掘算法在大規模并行架構上的并行化。作為并行和分布式體系結構組的博士后研究員,他專注于各種生物醫學應用的高效并行化,如上下文感知的元基因組分類、基因集富集分析和胸部 mri 的深層語義圖像分割。他目前的職位是深度學習解決方案架構師,負責協調盧森堡的 NVIDIA 人工智能技術中心( NVAITC )的技術合作。
Miguel Martinez 是 NVIDIA 的高級深度學習數據科學家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導過 Udacity 人工智能納米學位的學生。他有很強的金融服務背景,主要專注于支付和渠道。作為一個持續而堅定的學習者, Miguel 總是在迎接新的挑戰。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5047瀏覽量
103326 -
深度學習
+關注
關注
73文章
5509瀏覽量
121324
發布評論請先 登錄
相關推薦

互操作性對智能家居的重要性






 工商網監
工商網監
評論