 插入排序算法的復雜性、性能、分析
插入排序算法的復雜性、性能、分析
算法在數據科學和機器學習領域很常見。算法為社交媒體應用程序、谷歌搜索結果、銀行系統等提供動力。因此,數據科學家和 機器學習 實踐者在分析、設計和實現算法方面擁有直覺是至關重要的。
當應用于大規模計算任務時,高效算法為公司節省了數百萬美元,并減少了內存和能源消耗。本文介紹了一種簡單的算法,插入排序。
雖然知道如何實現算法是必不可少的,但本文也包括了數據科學家在選擇利用時應該考慮的插入算法的細節。因此,本文提到了算法復雜性、性能、分析、解釋和利用等因素。
為什么?
重要的是要記住為什么數據科學家應該在解釋和實現之前研究數據結構和算法。
數據科學和 ML 庫和包抽象了常用算法的復雜性。此外,由于抽象,需要 100 行代碼和一些邏輯推導的算法被簡化為簡單的方法調用。這并沒有放棄數據科學家研究算法開發和數據結構的要求。
當給定一組要使用的預構建算法時,確定哪種算法最適合這種情況需要了解基本算法的參數、性能、限制和魯棒性。數據科學家可以在分析并在某些情況下重新實現算法后了解所有這些信息。
選擇正確的特定于問題的算法和排除算法故障的能力是理解算法的兩個最重要的優勢。
K-Means 、 BIRCH 和 Mean Shift 都是常用的 clustering 算法,數據科學家決不具備從頭開始實施這些算法的知識。盡管如此,數據科學家仍有必要了解每種算法的特性及其對特定數據集的適用性。
例如,基于質心的算法有利于高密度數據集,在這些數據集中可以清楚地定義集群。相反,在處理噪聲數據集時,首選基于密度的算法,如 DBSCAN (基于密度的帶噪聲應用程序空間聚類)。
在排序算法的上下文中,數據科學家遇到了數據湖和數據庫,在這些數據湖和數據庫中,如果對包含的數據進行排序,則遍歷元素以識別關系的效率更高。
識別適用于數據集的庫子例程需要了解各種排序算法和首選的數據結構類型。使用數組時,快速排序算法是有利的,但如果數據以鏈表形式顯示,則合并排序的性能更高,尤其是在大數據集的情況下。不過,兩者都使用分而治之的策略對數據進行排序。
出身背景
什么是排序算法?
排序問題是數據科學家和其他軟件工程師面臨的一個眾所周知的編程問題。排序問題的主要目的是按升序或降序排列一組對象。排序算法是執行的順序指令,用于將列表或數組中的元素有效地重新排序為所需的順序。
分類的目的是什么?
在數據領域中,數據集中元素的結構化組織支持高效遍歷和快速查找特定元素或組。在宏觀層面上,使用高效算法構建的應用程序轉化為引入我們生活的簡單性,如導航系統和搜索引擎。
插入排序是什么?
插入排序算法涉及基于列表中每個元素與其相鄰元素的迭代比較創建的排序列表。
指向當前元素的索引指示排序的位置。排序開始時(索引= 0 ),將當前值與左側相鄰的值進行比較。如果該值大于當前值,則不修改列表;如果相鄰值和當前值是相同的數字,也會出現這種情況。
但是,如果當前值左側的相鄰值較小,則相鄰值位置將向左移動,并且僅當其左側的值較小時才停止向左移動。
該圖說明了插入算法在未排序列表上執行的步驟。下圖中的列表按升序排列(從低到高)。
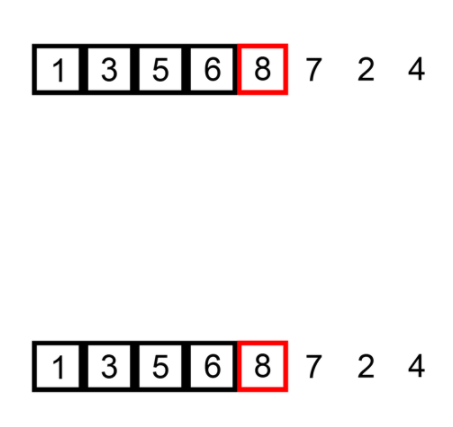
圖 1 : GIF 中的插入排序 (此文件在 Creative Commons 下獲得許可)。
算法步驟和實現( Python 和 JavaScript )
臺階
要按升序排列元素列表,插入排序算法需要以下操作:
從未排序元素的列表開始。
從第一項到最后一項遍歷未排序元素的列表。
在每個步驟中,將當前元素與前面所有位置左側的元素進行比較。
如果當前元素小于前面列出的任何元素,則將其向左移動一個位置。
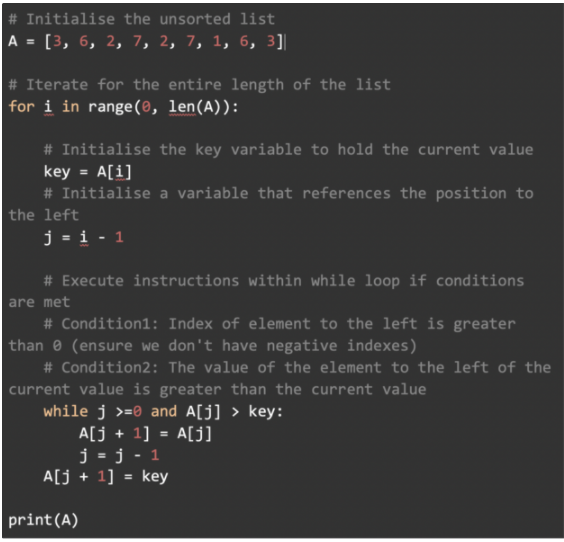
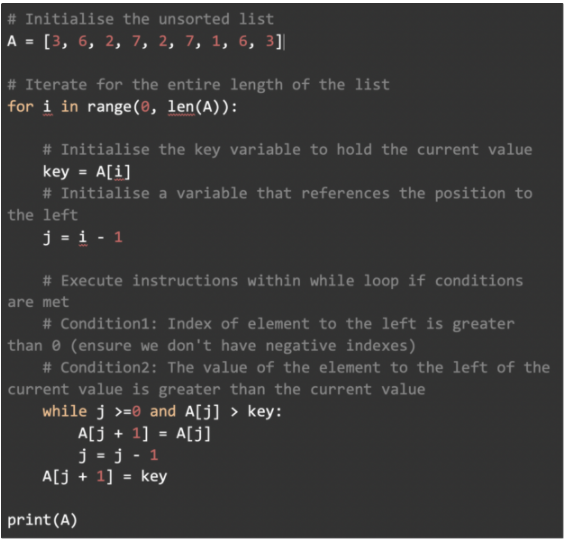
Python 實現
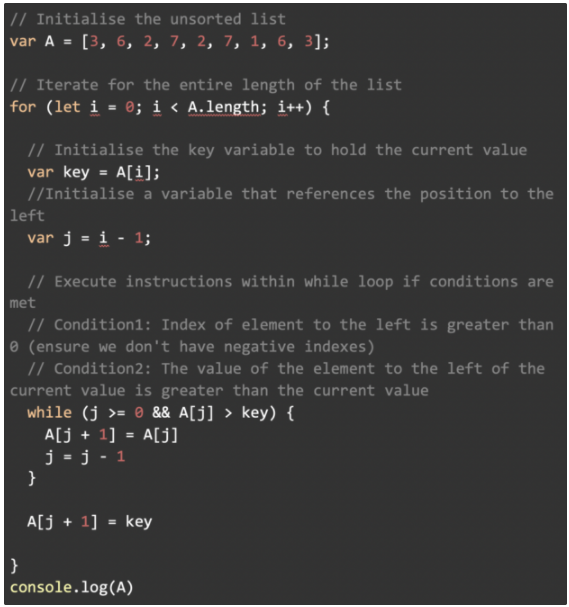
JavaScript 實現
性能和復雜性
在計算機科學領域,“大 O ”表示法是一種測量算法復雜性的策略。在這里,我們不會對大 O 符號太過技術化。不過,值得注意的是,計算機科學家使用這個數學符號來根據時間和空間需求對算法進行量化。
大 O 表示法是根據輸入定義的函數。字母“ n ”通常表示函數輸入的大小。簡單地說, n 表示列表中的元素數。在不同的場景中,實踐者關心函數的最壞情況、最佳情況或平均復雜度。
插入排序算法的最壞情況(和平均情況)復雜度為 O ( n 2)。這意味著,在最壞的情況下,對列表進行排序所需的時間與列表中元素數量的平方成正比。
插入排序算法的最佳時間復雜度為 O ( n )時間復雜度。這意味著對列表進行排序所需的時間與列表中元素的數量成正比;當列表的順序已經正確時,就是這種情況。在這種情況下,只有一次迭代,因為當列表已經有序時,內部循環操作是微不足道的。
插入排序常用于排列小列表。另一方面,插入排序并不是處理包含大量元素的大型列表的最有效方法。值得注意的是,在使用鏈表時,最好使用插入排序算法。雖然該算法可以應用于數組中結構化的數據,但其他排序算法,如快速排序,也可以應用于其他排序算法。
總結
最簡單的排序方法之一是插入排序,它涉及一次一個元素構建一個排序列表。通過將每個未檢查的元素插入排序列表中,在小于它和大于它的元素之間進行排序。正如本文所演示的,這是一個簡單的算法,可以在多種語言中掌握和應用。
通過清晰地描述插入排序算法,伴隨著所涉及的算法程序的逐步分解。數據科學家能夠更好地實現插入排序算法,并探索其他類似的排序算法,如快速排序和氣泡排序等。
對于許多數據科學家來說,算法可能是一個敏感的話題。這可能是由于主題的復雜性。“算法”一詞有時與復雜性有關。有了適當的工具、培訓和時間,即使是最復雜的算法,當您有足夠的時間、信息和資源時也很容易理解。算法是數據科學中使用的基本工具,不容忽視。
關于作者
Richmond Alake 是一名機器學習和計算機視覺工程師,他與多家初創公司和公司合作,整合深度學習模型,以解決商業應用中的計算機視覺任務。
審核編輯:郭婷
-
計算機
+關注
關注
19文章
7494瀏覽量
87965 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646
發布評論請先 登錄
相關推薦
芯片的失效性分析與應對方法

集成電路電磁兼容性及應對措施相關分析(一) — 電子系統性能要求與ESD問題
光伏連接器外殼:超越簡單塑料的復雜性與重要性

時間復雜度為 O(n^2) 的排序算法

淺談邏輯分析儀的技術原理和應用領域
為什么電路要設計得這么復雜?
飛凌OK-全志T527開發板nbench性能測試
戴爾科技如何幫助客戶克服多云環境的復雜性


FPGA實現雙調排序算法的探索與實踐

C語言實現經典排序算法概覽

解決選擇合適安全控制器的復雜性





 工商網監
工商網監
評論