 狀態向量模擬和cuStateVec庫的介紹
狀態向量模擬和cuStateVec庫的介紹
量子計算渴望為某些類型的經典難題提供更強大的計算能力和更快的結果。量子電路模擬對于理解量子計算和量子算法的發展至關重要。在量子電路中,量子器件由 N 量子位組成,通過對量子位應用一系列量子門和測量來執行計算。
從數學上來說, N 量子比特系統的量子態可以描述為一個復雜的 2 N – 維向量。在經典計算機上模擬量子電路最直觀的方法是狀態向量模擬,它將這個向量與其 2 N 復雜值直接存儲在內存中。該電路通過將向量乘以一系列矩陣來執行,這些矩陣對應于構成該電路的門序列。
然而,隨著狀態向量的維數隨著量子位的數量呈指數增長,完整描述狀態的內存需求將這種方法限制在 30 – 50 量子位的電路中。基于張量網絡的替代方法可以模擬更多的量子位,但通常在能夠有效模擬的電路的深度和復雜性方面受到限制。
NVIDIA cuQuantum SDK 具有用于狀態向量和張量網絡方法的庫。在本文中,我們將重點介紹狀態向量模擬和 cuStateVec 庫。有關張量網絡方法庫的更多信息,請參閱 利用 NVIDIA cuTensorNet 進行量子電路模擬 。
cuStateVec 圖書館
cuStateVec 庫提供了單個 GPU 原語來加速狀態向量模擬。由于狀態向量方法是模擬量子電路的基礎,大多數量子計算框架和庫都包含自己的狀態向量模擬器。為了便于與這些現有模擬器集成, cuStateVec 提供了一套 API ,以涵蓋常見用例:
測量
門應用
期望值
采樣器
狀態向量運動
測量
一個量子位可以存在于兩個態|0》和|1》的疊加中。當進行測量時,其中一個值被概率選擇和觀察,另一個值崩潰。 cuStateVec 測量 API 模擬量子位測量,并支持基于 Z 基產品的測量用例和批量單量子位測量。
門應用
量子電路有量子邏輯門來修改和準備量子態,以觀察理想的結果。量子邏輯門用酉矩陣表示。 cuStateVec gate 應用程序 API 提供了將量子邏輯門應用于某些矩陣類型的功能,包括:
稠密的
斜線的
廣義置換
泡利矩陣的矩陣指數
期望值
在量子力學中,計算算符和量子態的期望值。對于量子電路,我們還計算了給定電路和量子態的期望值。 cuStateVec 有一個 API ,可以用較小的內存占用計算期望值。
采樣器
狀態向量模擬在數值上將量子態保留在狀態向量中。通過計算每個狀態向量元素的概率,您可以有效地多次模擬多個量子位的測量,而不會破壞量子態。 cuStateVec sampler API 以較小的內存占用在 GPU 上執行采樣。
狀態向量運動
將狀態向量放置在 GPU 上,以加速 GPU 的模擬。要在 CPU 上分析模擬結果,請將生成的狀態向量復制到 CPU 。 cuStateVec 提供訪問器 API 來代表用戶執行此操作。在復制過程中,狀態向量元素的順序可以被重新安排,這樣你就可以將量子位重新排序為所需的量子位順序。
谷歌 Cirq / qsim 和 NVIDIA cuStateVec
宣布NVIDIA CuStEVEEC 文庫集成的第一個項目是 Google’s qsim ,一個優化的模擬器,用于他們的量子計算框架, Cirq 。 Google Quantum 人工智能團隊通過一個新的基于 cuStateVec 的 GPU 模擬后端擴展了 qsim ,以補充他們的 CPU 和 CUDA 模擬引擎。
使用 cuStateVec 為 Cirq 和 qsim 構建說明
要通過 Cirq 啟用 cuStateVec ,請從源代碼編譯 qsim ,并安裝 qsimcirq Python 包提供的 Cirq 綁定。
# Prerequisite: # Download cuQuantum Beta2 from https://developer.nvidia.com/cuquantum-downloads # Extract cuQuantum Beta2 archive and set the path to CUQUANTUM_ROOT $ tar -xf cuquantum-linux-x86_64-0.1.0.30-archive.tar.xz $ export CUQUANTUM_ROOT=`pwd`/cuquantum-linux-x86_64-0.1.0.30-archive $ ln -sf $CUQUANTUM_ROOT/lib $CUQUANTUM_ROOT/lib64 # Clone qsim repository from github and checkout v0.11.1 branch $ git clone https://github.com/quantumlib/qsim.git $ git checkout v0.11.1 # Build and install qsimcirq with cuStateVec $ pip install . # Install cirq $ pip install cirq
在本例中,我們運行一個電路,創建格林伯格 – 霍恩 – 齊林格( GHZ )狀態,并對實驗結果進行采樣。以下 Python 腳本通過調用三個不同的模擬器來獲取|0…00>和|1…11>中的振幅:
- Cirq 內置模擬器
- 基于 CPU 的模擬器共享
- 使用 cuStateVec 加速拆分
我們啟用了兩個基于 CIRQS 和 77YC 的 CPU 插槽,這兩個插槽分別用于基于 CPU 的 CPU 模擬器。對于 cuStateVec 加速模擬,我們使用單個 A100 GPU 。
import cirq
import qsimcirq
n_qubits = 32
qubits = cirq.LineQubit.range(n_qubits)
circuit = cirq.Circuit()
circuit.append(cirq.H(qubits[0]))
circuit.append(cirq.CNOT(qubits[idx], qubits[idx + 1]) \ for idx in range(n_qubits - 1))
# Cirqs = cirq.sim.Simulator()
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cirq.sim : {result}')
# qsim(CPU)
options = qsimcirq.QSimOptions(max_fused_gate_size=4, cpu_threads=512)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'qsim(CPU) : {result}')
# qsim(cuStateVec)
options = qsimcirq.QSimOptions(use_gpu=True, max_fused_gate_size=4, gpu_mode=1)
s = qsimcirq.QSimSimulator(options)
result = s.compute_amplitudes(circuit, [0, 2**n_qubits-1])
print(f'cuStateVec: {result}')
以下控制臺輸出顯示,通過使用 CPU SIMD 指令和 OpenMP 進行優化, qsim 的 CPU 版本比 Cirq 的模擬器快 5.1x 。通過使用 cuStateVec 版本,模擬速度進一步加快,比 Cirq 的模擬器快 30.04 倍,比 qsim 的 CPU 版本快 5.9 倍。
cirq.sim : [0.70710677+0.j 0.70710677+0.j], 87.51 s qsim(CPU) : [(0.7071067690849304+0j), (0.7071067690849304+0j)], 17.04 s cuStateVec: [(0.7071067690849304+0j), (0.7071067690849304+0j)], 2.88 s
績效結果
下圖顯示了一些常用電路的門應用的初步性能結果。所有量子位計數的模擬都會加速。然而,隨著量子位數量的增加,模擬速度顯著加快,對于最大的電路,模擬速度大約是 10-20 倍。這種性能為探索更大量子電路的開發和評估提供了機會。
A100 與 64 核 CPU 上的 Cirq / qsim + cuStateVec
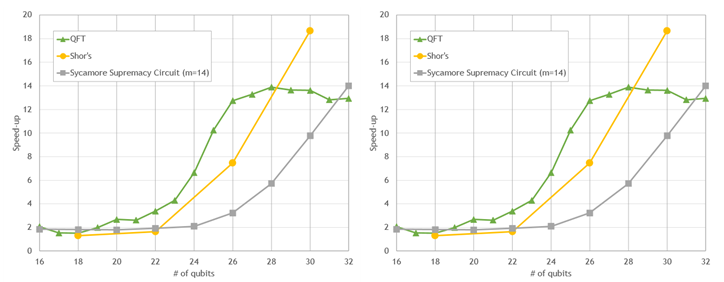
圖 1 。與 64 核 EPYC 7742 CPU 上的 Cirq / qsim 相比,在單個 NVIDIA A100 GPU 上使用 cuStateVec 的流行量子電路的模擬性能
相對于 EPYC 7742 中的 64 個 CPU 內核,一個 NVIDIA A100 上的 VQE 加速
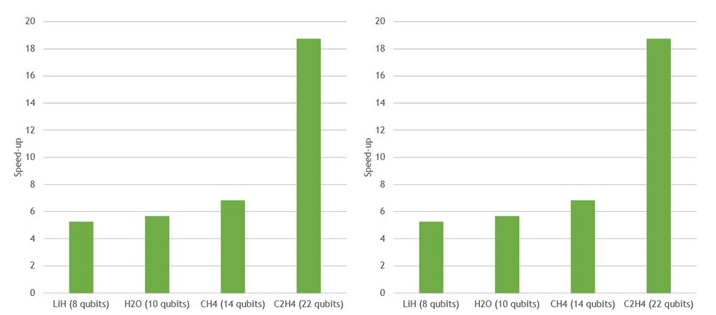
圖 2 。與 64 核 EPYC 7742 CPU 上的 Cirq / qsim 相比,在單個 NVIDIA A100 GPU 上使用 cuStateVec 的多個不同分子的變分量子本征解算器加速
多 GPU 狀態向量仿真
狀態向量模擬也非常適合在多個 GPU 上執行。大多數門應用是一種完全并行的操作,通過拆分狀態向量并將其分布在多個 GPU 上來加速。
在大約 30 個量子位之外,多 GPU 模擬是不可避免的。這是因為一個狀態向量無法適應單個 GPU 的內存,因為它的大小隨著附加的量子位呈指數增長。
當多個 GPU 在一個模擬中協同工作時,每個 GPU 可以將一個門并行應用于其狀態向量部分。在大多數情況下,每個 GPU 只需要本地數據來更新狀態向量,每個 GPU 都可以獨立應用門。
然而,根據門作用于哪個模擬量子位, GPU 有時可能需要存儲在不同 GPU 中的部分狀態向量來執行更新。在這種情況下, GPU 必須交換大部分狀態向量。這些部分的大小通常為數百兆字節或幾千兆字節。因此,多 GPU 狀態向量模擬對 GPU 互連的帶寬非常敏感。
DGX A100 完全符合這些要求,八款 NVIDIA A100 GPU 使用 NVLink 提供 600GB / s 的 GPU 到 GPU 直接帶寬。我們選擇了三種 30-32 量子位的常見量子計算算法,在 DGX A100 上用 cuStateVec 對 Cirq / qsim 進行基準測試:
量子傅里葉變換( QFT )
肖爾算法
梧桐至上電路
與單次 GPU 運行相比,在八次 GPU 運行中,所有基準測試都顯示出 4.5 – 7 倍加速之間良好的強縮放行為。
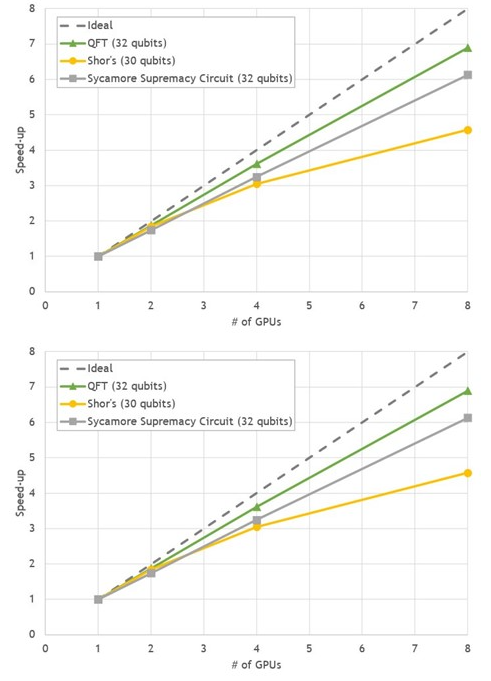
圖 3 。 DGX A100 上流行電路狀態向量模擬的多重 GPU 縮放
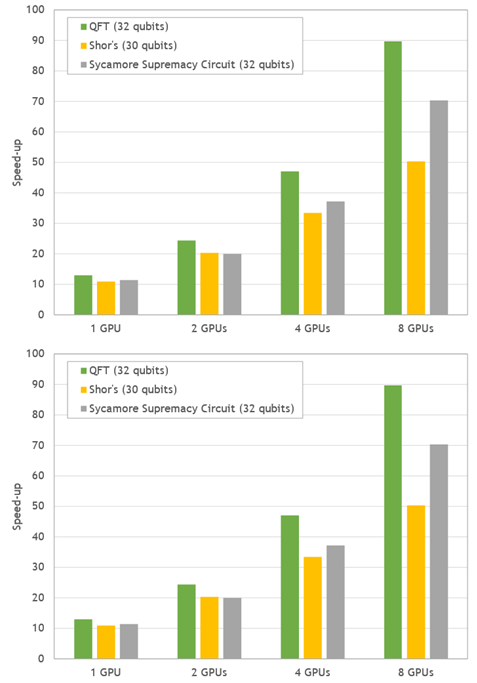
圖 4 。流行量子電路模擬的加速比。在 DGX A100 上測量了 GPU 模擬的性能,并與 EPYC 7742 的兩個插座的性能進行了比較。
與兩個 64 核 CPU 上的模擬時間相比, DGX-A100 在 50-90 倍之間提供了令人印象深刻的整體速度提升。
總結
NVIDIA CuQuin SDK 中的 CuStEVEVEC 庫旨在加速 GPU 上的量子電路的狀態向量模擬器。谷歌針對 Cirq qsim 的模擬器是首批采用該庫的模擬器之一,該庫對現有程序的 GPU 加速使 Cirq 用戶受益。隨后將集成到更多量子電路框架,包括 IBM 的 Qiskit 軟件。
我們也在擴大規模。基于 cuStateVec 的多 GPU 模擬的初步結果顯示,關鍵量子算法的加速比為 50 – 90 倍。我們希望 cuStateVec 成為開創量子計算新領域的寶貴工具。
關于作者
Shinya Morino 是NVIDIA 高級解決方案架構師,隸屬于NVIDIA 人工智能技術中心( NVAITC )。他已經在 NVAITC 中原型化了一個 GPU 加速狀態向量模擬器,并正在利用他的知識推動 cuStateVec 的開發。新亞擁有日本東京大學的工程學博士學位。
Andreas Hehn 是NVIDIA 的開發技術工程師。他幫助客戶使用 GPU 加速他們的科學工作流程,重點關注基因組學、高能物理實驗和量子計算。安德烈亞斯擁有瑞士蘇黎世 ETH 的物理學博士學位,他在那里從事大規模凝聚態物理模擬。
Leo Fang 是NVIDIA 的高級工程師,專注于 HPC 、量子計算和 Python 軟件。 2017 年,他在杜克大學獲得物理學博士學位。在加入 NVIDIA 之前,他是布魯克海文國家實驗室計算科學倡議的助理計算科學家。他也是許多開源項目的定期貢獻者,包括 CuPy 、 mpi4py 、 conda forge 和 Python 數據 API 標準聯盟。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5047瀏覽量
103326 -
gpu
+關注
關注
28文章
4759瀏覽量
129117 -
API
+關注
關注
2文章
1506瀏覽量
62205
發布評論請先 登錄
相關推薦
云數據庫是哪種數據庫類型?
觸發器的無效狀態怎么判斷
什么是IO模擬量模塊?

請問STM8L052R8的USART2中斷向量在哪?
IAP升級,boot和app分別是用標準庫和HAL庫寫的,跳轉不成功是怎么回事?
搭載英偉達GPU,全球領先的向量數據庫公司Zilliz發布Milvus2.4向量數據庫
Zilliz攜手大模型生態企業玩轉GDC 2024,向量數據庫和RAG成行業焦點

與NVIDIA深度參與GTC,向量數據庫大廠Zilliz與全球頂尖開發者共迎AI變革時刻
ocl電路工作在什么狀態
什么是中斷向量偏移,為什么要做中斷向量偏移?
博途用戶自定義庫的使用-庫的編輯及管理





 工商網監
工商網監
評論