 在MLPerf推理2.0上如何獲得人工智能模型所需的性能
在MLPerf推理2.0上如何獲得人工智能模型所需的性能
Megatron 530B 等機型正在擴大人工智能可以解決的問題范圍。然而,隨著模型的復雜性不斷增加,它們對人工智能計算平臺構成了雙重挑戰:
這些模型必須在合理的時間內進行訓練。
他們必須能夠實時進行推理工作。
我們需要的是一個多功能的人工智能平臺,它可以在各種各樣的模型上提供所需的性能,用于訓練和推理。
為了評估這種性能, MLPerf 是唯一一個行業標準人工智能基準,用于測試六個應用程序中的數據中心和邊緣平臺,測量吞吐量、延遲和能效。
在 MLPerf 推理 2.0 , NVIDIA 交付領先的結果在所有工作負載和場景,同時數據中心 GPU 和最新的參賽者,NVIDIA Jetson AGX ORIN SOC 平臺,為邊緣設備和機器人建造。
除了硬件,還需要大量的軟件和優化工作才能充分利用這些平臺。 MLPerf 推理 2.0 的結果展示了如何獲得處理當今日益龐大和復雜的人工智能模型所需的性能。
下面我們來看一下 MLPerf 推理 2.0 的性能,以及其中的一些優化,以及它們是如何構建的。
計算數字
圖 1 顯示了最新的參賽者 NVIDIA Jetson AGX Orin 。
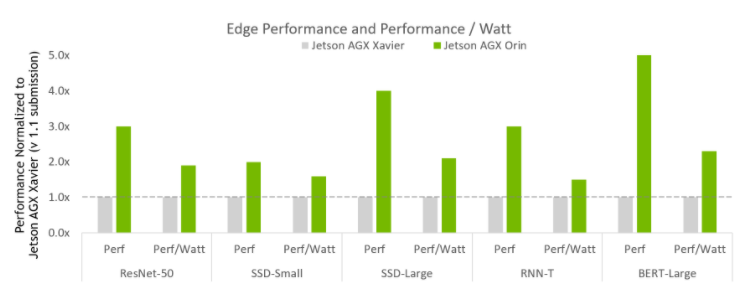
圖 1 NVIDIA Jetson AGX Orin 性能改進
MLPerf v2.0 推斷邊閉合和邊閉合冪;數據中心和邊緣、離線吞吐量和功率的 MLPerf 結果的性能/瓦特。NVIDIA Xavier AGX Xavier:1.1-110 和 1.1-111 | Jetson AGX Orin:2.0-140 和 2.0-141 。 MLPerf 名稱和徽標是商標。資料來源: http://www.mlcommons.org/en 。
圖 1 顯示 Jetson AGX Orin 的性能是上一代的 5 倍。在測試的全部使用范圍內,它平均提高了約 3.4 倍的性能。此外, Jetson AGX Orin 的能效提高了 2.3 倍。
Jetson Orin AGX 是一個 SoC ,為多個并發人工智能推理管道提供多達 275 個人工智能計算頂層,并為多個傳感器提供高速接口支持。NVIDIA Jetson AGX ORIN 開發者工具包使您能夠創建先進的機器人和邊緣 AI 應用程序,用于制造、物流、零售、服務、農業、智能城市、醫療保健和生命科學。
在數據中心領域,NVIDIA 繼續在所有應用領域提供全面的人工智能推理性能領先。
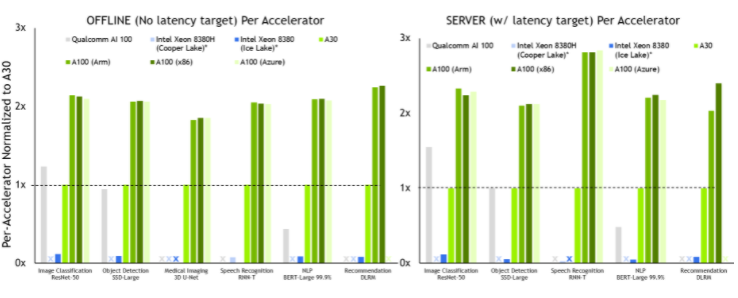
圖 2 NVIDIA A100 每臺加速器性能
MLPerf v2 。 0 推理關閉;使用數據中心脫機和服務器中報告的加速器計數,根據各自提交的最佳 MLPerf 結果得出每加速器性能。高通 AI 100:2.0-130 ,來自 MLPerf v.1.1 的英特爾至強 8380 提交: 1.1-023 和 1.1-024 ,英特爾至強 8380H 1.1-026 ,NVIDIA A30:2.0-090 ,NVIDIA A100 ( Arm ): 2.0-077 ,NVIDIA A100 ( x86 ): 2.0-094 。 MLPerf 名稱和徽標是商標。
NVIDIA A100 在離線和服務器場景下的所有測試中都提供了最佳的每加速器性能。
我們提交了以下配置的 A100 :
A100 SXM 搭配 x86 CPU ( AMD Epyc 7742 )
A100 PCIe 與 x86 CPU ( AMD Epyc 7742 )配對
A100 SXM 配 Arm CPU (NVIDIA 安培架構 Altra Q80-30 )
Microsoft Azure 也使用其 A100 實例提交,我們也在這一數據中顯示了這一點。
所有配置都提供了大致相同的推理性能,這證明了我們 Arm 軟件堆棧的就緒性,以及 A100 本地和云中的總體性能。
A100 還提供了高達 105 倍的性能,比僅 CPU 提交( RNN-T ,服務器方案)。 A30 在除一項工作外的所有工作上都表現出領導水平。與 A100 一樣,它運行了所有數據中心類別測試。
關鍵優化
提供出色的推理性能需要一種全堆棧方法,在這種方法中,優秀的硬件與優化且通用的軟件相結合。 NVIDIA TensorRT 和 NVIDIA Triton 推理服務器都在不同工作負載下提供出色的推理性能方面發揮著關鍵作用。
Jetson AGX-Orin 優化
NVIDIA Orin 新 NVIDIA 安培架構 I GPU 由 NVIDIA TensorRT 8.4 支持。對于 MLPerf 性能而言,它是 SoC 中最重要的組件。擴展了大量優化 GPU 內核的 TensorRT 庫,以支持新的體系結構。 TensorRT 生成器會自動拾取這些內核。
此外, MLPerf 網絡中使用的插件都已移植到 NVIDIA Orin 并添加到 TensorRT 8.4 中,包括 res2 插件( resnet50 )和 qkv 到上下文插件( BERT )。與帶有離散 GPU 加速器的系統不同,輸入不會從主機內存復制到設備內存,因為 SoC DRAM 由 CPU 和 iGPU 共享。
除了 iGPU , NVIDIA 還使用了兩個深度學習加速器( DLA ),以在離線情況下在 CV 網絡( resnet50 、 ssd mobilenet 、 ssd-resnet34 )上實現最高的系統性能。
NVIDIA Orin 采用了新一代 DLA 硬件。為了利用這些硬件改進, DLA 編譯器添加了以下 NVIDIA Orin 功能,這些功能在升級到 TensorRT 的未來版本時自動可用,無需修改任何應用程序源代碼。
SRAM chaining: 在本地 SRAM 中保留中間張量,以避免對 DRAM 的讀寫,從而減少延遲和平臺 DRAM 的使用。它還減少了對 GPU 推理的干擾。
卷積+池融合: INT8 卷積+偏差+縮放+重新調整可以與后續池節點融合。
卷積+元素融合: INT8 卷積+元素和可以與后續的 ReLU 節點融合。
對兩個 DLA 加速器的批量大小進行了微調,以獲得 GPU + DLA 聚合性能的適當平衡。該調整平衡了將 DLA 引擎 GPU 后備內核的調度沖突降至最低的需求,同時減少了 SoC 共享 DRAM 帶寬的整體潛在不足。
3D UNet 醫學成像
雖然大多數工作負載與 MLPerf 推斷 v1 相比基本保持不變。 1 、使用 KITS19 數據集增強了 3D UNet 醫學成像工作量。這個新的腎腫瘤圖像數據集有更大的不同大小的圖像,每個樣本需要更多的處理。
KiTS19 數據集為實現高效節能推理帶來了新的挑戰。更具體地說:
KiTS19 中使用的輸入張量的形狀從 128x192x320 到 320x448x448 不等;最大輸入張量比最小輸入張量大 8.17 倍。
推理過程中需要大于 2GB 的張量。
在特定感興趣區域( ROI )形狀( 128x128x128 )上有一個滑動窗口,具有較大的重疊系數( 50% )。
為了解決這個問題,我們開發了一種滑動窗口方法來處理這些圖像:
根據重疊因子,將每個輸入張量切成 ROI 形狀。
使用循環處理給定輸入張量的所有滑動窗口切片。
加權并規范化每個滑動窗口的推理結果。
通過滑動窗口推斷的聚合結果的 ArgMax 獲得最終分割輸出。
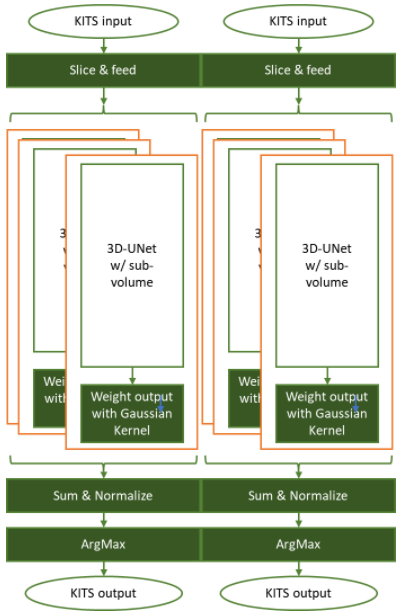
圖 3 3D UNet 使用滑動窗口方法執行 KiTS19 腎臟腫瘤分割推斷任務
在圖 3 中,每個輸入張量被切片成具有重疊因子( 50% )的 ROI 形狀( 128x128x128 ),并輸入預訓練網絡。然后對每個滑動窗口輸出進行最佳加權,以獲取歸一化 sigma = 0.125 的高斯核特征。
推理結果根據原始輸入張量形狀進行聚合,并對這些權重因子進行歸一化。然后, ArgMax 操作會切割分割信息,標記背景、正常腎細胞和腫瘤。
該實現將分割與基本事實進行比較,并計算骰子分數以確定基準測試的準確性。您還可以直觀地檢查結果。
我們的數據中心 GPU 已經支持 INT8 精度超過 5 年,與 FP16 和 FP32 精度級別相比,這種精度在許多型號上帶來了顯著的加速,精度損失接近于零。
對于 3D UNet ,我們通過使用 TensorRT IInt8MinMaxCalibrator 校準校準集中的圖像來使用 INT8 。該實現在 FP32 參考模型中實現了 100% 的精度,從而實現了基準的高精度和低精度模式。
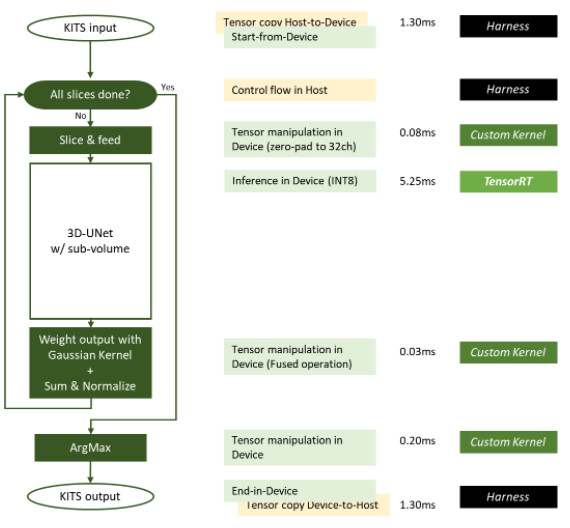
圖 5 MLPerf 推理 v2 中使用的 NVIDIA 3D UNet KiTS19 實現。 0 提交
在圖 5 中,綠色框在設備( GPU )上執行,黃色框在主機( CPU )上執行。滑動窗口推理所需的一些操作被優化為融合操作。
利用 GPUDirect RDMA 和存儲,可以最小化或消除主機到設備或設備到主機的數據移動。從 DGX-A100 系統中測量一個輸入樣本(其大小接近平均輸入大小)的每項工作的延遲。切片內核和 ArgMax 內核的延遲隨輸入圖像大小成比例變化。
以下是一些具體的優化措施:
用于加權的高斯核補丁現在已預先計算并存儲在磁盤上,并在基準測試的定時部分開始之前加載到 GPU 內存中。
加權和歸一化作為融合操作進行優化,使用 27 個預計算的面片,用于 3D 輸入張量上 50% 重疊的滑動窗口。
編寫處理切片、加權和 ArgMax 的自定義 CUDA 內核,以便所有這些操作都在 GPU 中完成,無需 H2D / D2H 數據傳輸。
INT8 線性內存布局中的輸入張量使 H2D 傳輸中的數據量最小,因為 KiTS19 輸入集是單通道。
TensorRT 需要 NC / 32DHW32 格式的 INT8 輸入。我們使用一個定制的 CUDA 內核,該內核在 GPU 全局內存中的一個連續內存區域中執行對零填充的切片,并將 INT8 線性輸入張量切片重新格式化為 INT8 NC / 32DHW32 格式。
GPU 中的零填充和重新格式化張量要比其他昂貴的 H2D 傳輸速度快得多, H2D 傳輸的數據要多 32 倍。這種優化顯著提高了整體性能,并釋放了寶貴的系統資源。
TensorRT 引擎用于在每個滑動窗口切片上運行推理。因為 3D UNet 是密集的,我們發現增加批量大小會成比例地增加引擎的運行時間。
NVIDIA Triton 優化
NVIDIA 提交繼續顯示 Triton 推理服務器的多功能性。這一輪, Triton 推理服務器還支持在 AWS 推理機上運行 NVIDIA Triton 。NVIDIA Triton 使用 Python 后端運行推理優化 PyTorch 和 TensorFlow 模型。
使用NVIDIA Triton 和火炬神經元, NVIDIA 提交獲得 85% 至 100% 的推斷推理的自然推斷性能。
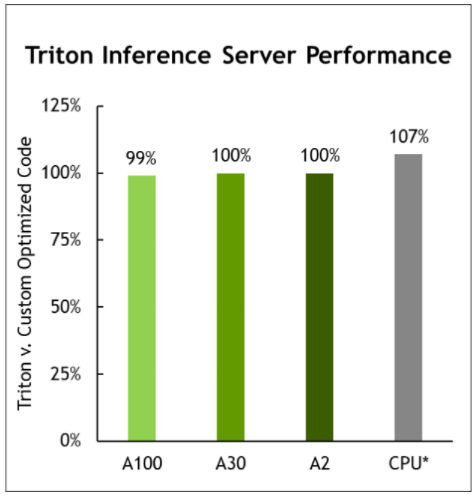
圖 6 。 Triton 推理服務器性能
MLPerf v1 。 1 。關閉推理;每個加速器的性能源自使用數據中心脫機中報告的加速器計數的各個提交的最佳 MLPerf 結果。顯示所有提交工作負載的幾何平均值。 CPU 基于 MLPerf 推理 1.1 中的英特爾提交數據進行比較,以比較相同 CPU 的配置,提交 1.0-16 、 1.0-17 、 1.0-19 。 NVIDIA Triton 在 CPU 上: 2.0-100 和 2.0-101 。 A2:2.0-060 和 2.0-061 。 A30:2.0-091 和 2.0-092 。 A100:2.0-094 和 2.0-096 。 MLPerf 名稱和徽標是商標。
NVIDIA Triton 現在支持 AWS 推理處理器,并提供與僅在 AWS Neuron SDK 上運行幾乎相同的性能。
它需要一個平臺
NVIDIA 推理領導力來自于打造最優秀的人工智能加速器,用于培訓和推理。但優秀的硬件只是開始。
NVIDIA TensorRT 和 Triton 推理服務器軟件在跨這一組不同的工作負載提供出色的推理性能方面發揮著關鍵作用。他們可以在 NGC ,NVIDIA 中心,以及其他 GPU 優化的軟件,用于深度學習,機器學習,和 HPC 。
NGC 容器化軟件使加速平臺的建立和運行變得更加容易,因此您可以專注于構建真正的應用程序,并加快實現價值的時間。 NGC 可以通過您首選的云提供商的市場免費獲得。
關于作者
Dave Salvator 是 NVIDIA 旗下 Tesla 集團的高級產品營銷經理,專注于超規模、深度學習和推理。
Ashwin Nanjappa 是 NVIDIA TensorRT 團隊的工程經理。他領導 MLPerf 推理計劃,展示 NVIDIA 加速器的性能和能效。他還參與改進 TensorRT DL 推理庫的性能。在加入NVIDIA 之前,他曾參與培訓和部署 CV 的 DL 模型、深度相機的 GPU 加速 ML / CV 算法,以及手機和 DVD 播放器中的多媒體庫。他擁有來自新加坡國立大學( NUS )的計算機科學博士學位,重點是 GPU 算法用于三維計算幾何。
Jinho 是NVIDIA DLSIM 團隊的高級深度學習架構師。他正在研究 NVIDIA 加速器上的深度學習工作負載的性能建模和分析,并有助于NVIDIA MLPIFF 推理實現。在加入NVIDIA 之前,他曾在英特爾和 Arm 從事服務器 CPU 和 SoC 體系結構及微體系結構方面的工作。他擁有南加州大學計算機工程博士學位,專注于計算機體系結構。
Ian 是 NVIDIA TensorRT 團隊的高級系統軟件工程師,他專注于 MLPerf 推理。在加入 TensorRT 團隊之前,他曾為 NVIDIA 自動駕駛軟件開發實時調度系統。伊恩畢業于多倫多大學工程科學專業,主修電氣和計算機工程。
Madhumitha Sridhara 是 TensorRT 團隊的高級軟件工程師,專注于使用 Triton 推理服務器的 NVIDIA MLPerf推理提交。她擁有卡內基梅隆大學計算機工程碩士學位和印度卡納塔克邦蘇拉特卡爾國家理工學院電子和通信工程學士學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5047瀏覽量
103326 -
gpu
+關注
關注
28文章
4759瀏覽量
129117 -
服務器
+關注
關注
12文章
9248瀏覽量
85732 -
MLPerf
+關注
關注
0文章
35瀏覽量
647
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
澎峰科技高性能大模型推理引擎PerfXLM解析

risc-v在人工智能圖像處理應用前景分析
人工智能ai4s試讀申請
FPGA在人工智能中的應用有哪些?
人工智能大模型在工業網絡安全領域的應用
人工智能模型有哪些
人工智能與大模型的關系與區別
大模型應用之路:從提示詞到通用人工智能(AGI)





 工商網監
工商網監
評論