") 采用預(yù)訓(xùn)練的動(dòng)作識(shí)別模型快速跟蹤AI應(yīng)用程序的開(kāi)發(fā)
采用預(yù)訓(xùn)練的動(dòng)作識(shí)別模型快速跟蹤AI應(yīng)用程序的開(kāi)發(fā)
作為人類(lèi),我們每天都在不停地移動(dòng),做一些動(dòng)作,比如走路、跑步和坐著。這些行為是我們?nèi)粘I畹淖匀谎由臁?gòu)建能夠捕獲這些特定動(dòng)作的應(yīng)用程序在體育分析領(lǐng)域、醫(yī)療保健領(lǐng)域、零售領(lǐng)域以及其他領(lǐng)域都非常有價(jià)值。
然而,構(gòu)建和部署能夠理解人類(lèi)行為的時(shí)間信息的人工智能應(yīng)用程序既具有挑戰(zhàn)性又耗時(shí),需要大量培訓(xùn)和深入的人工智能專(zhuān)業(yè)知識(shí)。
在這篇文章中,我們將展示如何快速跟蹤 AI 應(yīng)用程序的開(kāi)發(fā),方法是采用預(yù)訓(xùn)練的動(dòng)作識(shí)別模型,使用 NVIDIA TAO Toolkit 自定義數(shù)據(jù)和類(lèi)對(duì)其進(jìn)行微調(diào),并通過(guò) NVIDIA DeepStream 部署它進(jìn)行推理,而無(wú)需任何 AI 專(zhuān)業(yè)知識(shí)。
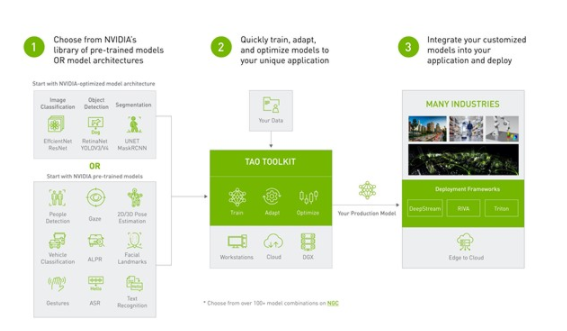
圖 1 端到端工作流從預(yù)訓(xùn)練模型開(kāi)始,使用 TAO 工具包進(jìn)行微調(diào),并使用 DeepStream 進(jìn)行部署
動(dòng)作識(shí)別模型
要識(shí)別一個(gè)動(dòng)作,網(wǎng)絡(luò)不僅要查看單個(gè)靜態(tài)幀,還要查看多個(gè)連續(xù)幀。這提供了理解操作的時(shí)間上下文。這是與分類(lèi)或目標(biāo)檢測(cè)模型相比的額外時(shí)間維度,其中網(wǎng)絡(luò)僅查看單個(gè)靜態(tài)幀。
這些模型是使用二維卷積神經(jīng)網(wǎng)絡(luò)創(chuàng)建的,其中的尺寸是寬度、高度和通道數(shù)。 2D 動(dòng)作識(shí)別模型與其他 2D 計(jì)算機(jī)視覺(jué)模型類(lèi)似,但通道維度現(xiàn)在也包含時(shí)間信息。
在 2D 動(dòng)作識(shí)別模型中,將時(shí)間幀 D 與通道計(jì)數(shù) C 相乘,形成通道維度輸入。
對(duì)于三維模型,添加了表示時(shí)間信息的新維度 D 。
2D 和 3D 卷積網(wǎng)絡(luò)的輸出進(jìn)入一個(gè)完全連接的層,然后是一個(gè) Softmax 層來(lái)預(yù)測(cè)動(dòng)作。
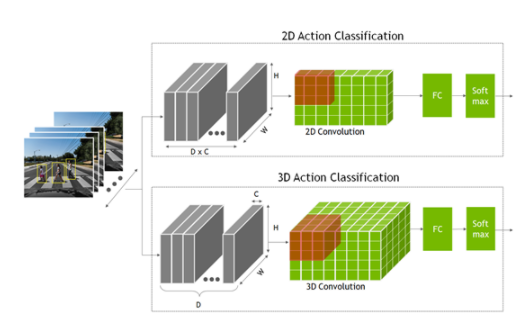
圖 2 動(dòng)作識(shí)別 2D 和 3D 卷積網(wǎng)絡(luò)
pretrained model 是在代表性數(shù)據(jù)集上經(jīng)過(guò)訓(xùn)練并使用權(quán)重和偏差進(jìn)行微調(diào)的數(shù)據(jù)集。 NGC catalog 提供的動(dòng)作識(shí)別模型已在五個(gè)常見(jiàn)類(lèi)別上進(jìn)行了培訓(xùn):
行走
跑步
推
騎自行車(chē)
墜落
這是一個(gè)示例模型。更重要的是,該模型可以很容易地用自定義數(shù)據(jù)重新訓(xùn)練,只需花費(fèi)很少的時(shí)間和從頭開(kāi)始訓(xùn)練所需的數(shù)據(jù)。
預(yù)訓(xùn)練模型是在 HMDB51 數(shù)據(jù)集中的幾百個(gè)短視頻剪輯上訓(xùn)練的。對(duì)于模型培訓(xùn)的五個(gè)類(lèi), 2D 模型的精度達(dá)到 83% , 3D 模型的精度達(dá)到 86% 。此外,如果選擇按原樣部署模型,下表顯示了各種 GPU 上的預(yù)期性能。

在本實(shí)驗(yàn)中,您將使用三個(gè)新類(lèi)對(duì)模型進(jìn)行微調(diào),這些新類(lèi)包含簡(jiǎn)單動(dòng)作,如俯臥撐、仰臥起坐和引體向上。您使用 HMDB51 數(shù)據(jù)集的子集,其中包含 51 個(gè)不同的操作。
先決條件
開(kāi)始之前,您必須擁有以下培訓(xùn)和部署資源:
NVIDIA GPU 驅(qū)動(dòng)程序版本:》 470
NVIDIA Docker:2.5.0-1
云中或本地的 NVIDIA GPU :
英偉達(dá) A100
英偉達(dá) V100
英偉達(dá) T4
英偉達(dá) RTX 30×0
工具包 NVIDIA:3.0-21-11
NVIDIA DeepStream:6.0
有關(guān)更多信息,請(qǐng)參閱 TAO 工具包快速入門(mén)指南 。
使用 TAO 工具包進(jìn)行培訓(xùn)、調(diào)整和優(yōu)化
在本節(jié)中,您將使用 TAO 工具包使用新類(lèi)對(duì)模型進(jìn)行微調(diào)。
TAO 工具包使用 transfer learning ,其中使用從現(xiàn)有神經(jīng)網(wǎng)絡(luò)模型學(xué)習(xí)的特征,并將其應(yīng)用于新的神經(jīng)網(wǎng)絡(luò)模型。 TAO 工具包是 NVIDIA TAO 框架 基于 CLI 和 Jupyter 筆記本的解決方案,它抽象了 AI / DL 框架的復(fù)雜性,使您能夠在沒(méi)有任何 AI 專(zhuān)業(yè)知識(shí)的情況下為您的用例創(chuàng)建定制和生產(chǎn)就緒的模型。
您可以在 CLI 窗口中提供簡(jiǎn)單指令,也可以使用交鑰匙 Jupyter 筆記本進(jìn)行培訓(xùn)和微調(diào)。您可以使用 NGC 中的動(dòng)作識(shí)別筆記本來(lái)訓(xùn)練自定義的三類(lèi)模型。
下載 TAO Toolkit 計(jì)算機(jī)視覺(jué)示例工作流 的 1.3 版并解壓縮包。在/action_recognition_net目錄中,找到用于動(dòng)作識(shí)別培訓(xùn)的 Jupyter 筆記本(actionrecognitionnet.ipynb),以及/specs目錄,其中包含用于培訓(xùn)、評(píng)估和模型導(dǎo)出的所有規(guī)范文件。您可以為培訓(xùn)配置這些等級(jí)庫(kù)文件。
啟動(dòng) Jupyter 筆記本并打開(kāi)action_recognition_net/actionrecognitionnet.ipynb文件:
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
步驟 1 :設(shè)置并安裝 TAO 工具包
所有培訓(xùn)步驟都在 Jupyter 筆記本中運(yùn)行。啟動(dòng)筆記本后,運(yùn)行筆記本中提供的設(shè)置環(huán)境變量和映射驅(qū)動(dòng)器和安裝 TAO 發(fā)射器步驟。
步驟 2 :下載數(shù)據(jù)集和預(yù)訓(xùn)練模型
安裝 TAO 后,下一步是下載并準(zhǔn)備數(shù)據(jù)集進(jìn)行培訓(xùn)。 Jupyter 筆記本提供了下載和預(yù)處理 HMDB51 數(shù)據(jù)集的步驟。如果您有自己的自定義數(shù)據(jù)集,則可以在步驟 2.1 中使用它。
對(duì)于本文,您將使用 HMDB51 數(shù)據(jù)集中的三個(gè)類(lèi)。修改幾行以添加俯臥撐、引體向上和仰臥起坐課程。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/hmdb51_org.rar $ mkdir -p $HOST_DATA_DIR/videos && unrar x $HOST_DATA_DIR/hmdb51_org.rar $HOST_DATA_DIR/videos $ mkdir -p $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pushup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/pullup.rar $HOST_DATA_DIR/raw_data $ unrar x $HOST_DATA_DIR/videos/situp.rar $HOST_DATA_DIR/raw_data
每個(gè)類(lèi)的視頻文件存儲(chǔ)在$HOST_DATA_DIR/raw_data下各自的目錄中。這些是經(jīng)過(guò)編碼的視頻文件,必須解壓縮為幀才能訓(xùn)練模型。已經(jīng)提供了一個(gè)腳本來(lái)幫助您為培訓(xùn)準(zhǔn)備數(shù)據(jù)。
下載幫助程序腳本并安裝依賴(lài)項(xiàng):
$ git clone https://github.com/NVIDIA-AI-IOT/tao_toolkit_recipes.git $ pip3 install xmltodict opencv-python
將視頻文件解壓縮為幀:
$ cd tao_recipes/tao_action_recognition/data_generation/ $ ./preprocess_HMDB_RGB.sh $HOST_DATA_DIR/raw_data \ $HOST_DATA_DIR/processed_data
下面的代碼示例中顯示了每個(gè)類(lèi)的輸出。f cnt: 82表示此視頻剪輯已解壓縮到 82 幀。對(duì)目錄中的所有視頻執(zhí)行此操作。根據(jù)類(lèi)的數(shù)量以及數(shù)據(jù)集和視頻剪輯的大小,此過(guò)程可能需要一些時(shí)間。
Preprocess pullup f cnt: 82.0 f cnt: 82.0 f cnt: 82.0 f cnt: 71.0 ...
處理后的數(shù)據(jù)的格式類(lèi)似于下面的代碼示例。如果您正在對(duì)自己的數(shù)據(jù)進(jìn)行培訓(xùn),請(qǐng)確保數(shù)據(jù)集也遵循此目錄格式。
$HOST_DATA_DIR/processed_data/ |-->|-->
下一步是將數(shù)據(jù)拆分為培訓(xùn)和驗(yàn)證集。 HMDB51 數(shù)據(jù)集為每個(gè)類(lèi)提供了一個(gè)拆分文件,因此只需下載該文件,并將數(shù)據(jù)集劃分為 70% 的培訓(xùn)和 30% 的驗(yàn)證。
$ wget -P $HOST_DATA_DIR http://serre-lab.clps.brown.edu/wp-content/uploads/2013/10/test_train_splits.rar $ mkdir -p $HOST_DATA_DIR/splits && unrar x \ $HOST_DATA_DIR/test_train_splits.rar $HOST_DATA_DIR/splits
使用助手腳本split_dataset.py拆分?jǐn)?shù)據(jù)。這僅適用于 HMDB 數(shù)據(jù)集提供的拆分文件。如果您正在使用自己的數(shù)據(jù)集,那么這將不適用。
$ cd tao_recipes/tao_action_recognition/data_generation/ $ python3 ./split_dataset.py $HOST_DATA_DIR/processed_data \ $HOST_DATA_DIR/splits/testTrainMulti_7030_splits $HOST_DATA_DIR/train \ $HOST_DATA_DIR/test
用于培訓(xùn)的數(shù)據(jù)在$HOST_DATA_DIR/train下,用于測(cè)試和驗(yàn)證的數(shù)據(jù)在$HOST_DATA_DIR/test下。
準(zhǔn)備好數(shù)據(jù)集后,從 NGC 下載預(yù)訓(xùn)練模型。按照 Jupyter 筆記本 2.1 中的步驟操作。
$ ngc registry model download-version "nvidia/tao/actionrecognitionnet:trainable_v1.0" --dest $HOST_RESULTS_DIR/pretrained
步驟 3 :配置培訓(xùn)參數(shù)
spec YAML 文件中提供了培訓(xùn)參數(shù)。在/ specs 目錄中,查找所有用于培訓(xùn)、微調(diào)、評(píng)估、推斷和導(dǎo)出的 spec 文件。對(duì)于培訓(xùn),您可以使用train_rgb_3d_finetune.yaml。
對(duì)于本實(shí)驗(yàn),我們將向您展示一些可以修改的超參數(shù)。有關(guān)所有不同參數(shù)的更多信息,請(qǐng)參閱ActionRecognitionNet。
您還可以在運(yùn)行時(shí)覆蓋任何參數(shù)。大多數(shù)參數(shù)保留為默認(rèn)值。下面的代碼塊中突出顯示了正在更改的少數(shù)代碼。
## Model Configuration model_config: model_type: rgb input_type: "3d" backbone: resnet18 rgb_seq_length: 32 ## Change from 3 to 32 frame sequence rgb_pretrained_num_classes: 5 sample_strategy: consecutive sample_rate: 1 # Training Hyperparameter configuration train_config: optim: lr: 0.001 momentum: 0.9 weight_decay: 0.0001 lr_scheduler: MultiStep lr_steps: [5, 15, 25] lr_decay: 0.1 epochs: 20 ## Number of Epochs to train checkpoint_interval: 1 ## Saves model checkpoint interval ## Dataset configuration dataset_config: train_dataset_dir: /data/train ## Modify to use your train dataset val_dataset_dir: /data/test ## Modify to use your test dataset
第四步:訓(xùn)練你的人工智能模型
對(duì)于培訓(xùn),請(qǐng)遵循 Jupyter 筆記本中的步驟 4 。設(shè)置環(huán)境變量。
訓(xùn)練動(dòng)作識(shí)別的 TAO 工具包任務(wù)稱(chēng)為action_recognition。要進(jìn)行培訓(xùn),請(qǐng)使用tao action_recognition train命令。指定培訓(xùn)規(guī)范文件,并提供輸出目錄和預(yù)培訓(xùn)模型。或者,也可以在model_config規(guī)范中設(shè)置預(yù)訓(xùn)練模型。
$ tao action_recognition train \ -e $SPECS_DIR/train_rgb_3d_finetune.yaml \ -r $RESULTS_DIR/rgb_3d_ptm \ -k $KEY \ model_config.rgb_pretrained_model_path=$RESULTS_DIR/pretrained/actionrecognitionnet_vtrainable_v1.0/resnet18_3d_rgb_hmdb5_32.tlt ognition train \
根據(jù)您的 GPU 、序列長(zhǎng)度或年代,這可能需要幾分鐘到幾小時(shí)的時(shí)間。因?yàn)橐4婷總€(gè)歷元,所以可以看到與歷元數(shù)量相同的模型檢查點(diǎn)。
模型檢查點(diǎn)另存為ar_model_epoch=。選擇模型評(píng)估和導(dǎo)出的最后一個(gè)歷元,但可以使用驗(yàn)證損失最小的歷元。
步驟 5 :評(píng)估經(jīng)過(guò)培訓(xùn)的模型
有兩種不同的抽樣策略來(lái)評(píng)估視頻剪輯上的訓(xùn)練模型:
- Center mode:拾取序列的中間幀進(jìn)行推斷。例如,如果模型需要 32 幀作為輸入,而視頻剪輯有 128 幀,則可以從索引 48 到索引 79 中選擇幀進(jìn)行推斷。
- Conv mode:對(duì)單個(gè)視頻中的 10 個(gè)序列進(jìn)行卷積采樣并進(jìn)行推斷。結(jié)果取平均值。
對(duì)于評(píng)估,請(qǐng)使用/specs目錄中提供的評(píng)估規(guī)范文件(evaluate_rgb.yaml)。這就像訓(xùn)練配置。修改dataset_config參數(shù)以使用您正在培訓(xùn)的三個(gè)類(lèi)。
dataset_config: ## Label maps for new classes. Modify this for your custom classes label_map: pushup: 0 pullup: 1 situp: 2
使用tao action_recognition evaluate命令進(jìn)行計(jì)算。如前所述,對(duì)于video_eval_mode,您可以在中心模式或 conv 模式之間進(jìn)行選擇。使用訓(xùn)練運(yùn)行中最后保存的模型檢查點(diǎn)。
$ tao action_recognition evaluate \ -e $SPECS_DIR/evaluate_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss= .tlt \ batch_size=1 \ test_dataset_dir=$DATA_DIR/test \ video_eval_mode=center
評(píng)價(jià)產(chǎn)出:
100%|███████████████████████████████████████████| 90/90 [00:03<00:00, 29.82it/s] ******************************* pushup 56.67 pullup 100.0 situp 90.0 ******************************* Total accuracy: 82.222 Average class accuracy: 82.222 2021-11-17 17:46:52,590 [INFO] tlt.components.docker_handler.docker_handler: Stopping container.
這是在 90 個(gè)視頻數(shù)據(jù)集上評(píng)估的,該數(shù)據(jù)集包含所有三個(gè)動(dòng)作的剪輯。總體準(zhǔn)確率約為 82% ,這對(duì)于數(shù)據(jù)集的大小來(lái)說(shuō)是合適的。數(shù)據(jù)集越大,模型的通用性越好。您可以嘗試使用自己的剪輯測(cè)試準(zhǔn)確性。
步驟 6 :導(dǎo)出以進(jìn)行 DeepStream 部署
最后一步是導(dǎo)出用于部署的模型。要導(dǎo)出,請(qǐng)運(yùn)行tao action_recognition export命令。您必須提供導(dǎo)出規(guī)范文件,該文件作為export_rgb.yaml包含在/specs目錄中。修改export_rgb.yaml中的dataset_config值,以使用您培訓(xùn)的三個(gè)類(lèi)。這類(lèi)似于evaluate_rgb.yaml中的dataset_config。
$ tao action_recognition export \ -e $SPECS_DIR/export_rgb.yaml \ -k $KEY \ model=$RESULTS_DIR/rgb_3d_ptm/ar_model_epoch=-val_loss= .tlt \ /export/rgb_resnet18_3.etlt
祝賀您,您已成功培訓(xùn)了自定義 3D 動(dòng)作識(shí)別模型。現(xiàn)在,使用 DeepStream 部署此模型。
使用 DeepStream 部署
在本節(jié)中,我們將展示如何使用 NVIDIA DeepStream 部署經(jīng)過(guò)微調(diào)的模型。
DeepStream SDK幫助您快速構(gòu)建高效、高性能的視頻 AI 應(yīng)用程序。 DeepStream 應(yīng)用程序可以在由 NVIDIA Jetson 提供動(dòng)力的邊緣設(shè)備、本地服務(wù)器或云中運(yùn)行。
為了支持動(dòng)作識(shí)別模型, DeepStream 6.0 添加了Gst-nvdspreprocess插件。該插件加載一個(gè)自定義庫(kù)( custom _ sequence _ preprocess.so ),以執(zhí)行時(shí)間序列捕獲和感興趣區(qū)域( ROI )部分批處理,然后將批處理的張量緩沖區(qū)轉(zhuǎn)發(fā)給下游推理插件。
您可以修改 DeepStream SDK 中包含的deepstream-3d-action-recognition應(yīng)用程序,以測(cè)試使用 TAO 微調(diào)的模型。
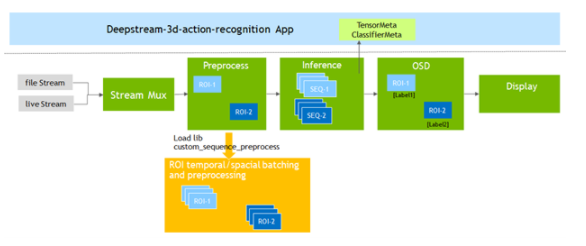 圖 4 。三維動(dòng)作識(shí)別應(yīng)用程序管道
圖 4 。三維動(dòng)作識(shí)別應(yīng)用程序管道示例應(yīng)用程序同時(shí)對(duì)四個(gè)視頻文件運(yùn)行推斷,并以 2 × 2 平鋪顯示結(jié)果。
在進(jìn)行修改之前,先運(yùn)行標(biāo)準(zhǔn)應(yīng)用程序。首先,啟動(dòng) DeepStream 6.0 開(kāi)發(fā)容器:
$ xhost + $ docker run --gpus '"'device=0'"' -it -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -w /opt/nvidia/deepstream/deepstream-6.0 nvcr.io/nvidia/deepstream:6.0-devel
有關(guān) NVIDIA 提供的 DeepStream 集裝箱的更多信息,請(qǐng)參閱NGC catalog。
在容器中,導(dǎo)航到 3D 動(dòng)作識(shí)別應(yīng)用程序目錄,從 NGC 下載并安裝標(biāo)準(zhǔn) 3D 和 2D 模型。
$ cd sources/apps/sample_apps/deepstream-3d-action-recognition/ $ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/actionrecognitionnet/versions/deployable_v1.0/zip -O actionrecognitionnet_deployable_v1.0.zip $ unzip actionrecognitionnet_deployable_v1.0.zip
現(xiàn)在,您可以使用 3D 推理模型執(zhí)行應(yīng)用程序并查看結(jié)果。
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt
預(yù)處理器插件配置
在修改應(yīng)用程序之前,請(qǐng)熟悉運(yùn)行應(yīng)用程序所需的預(yù)處理器插件的關(guān)鍵配置參數(shù)。
從/app/sample_apps/deepstream-3d-action-recognition文件夾中,打開(kāi)config_preprocess_3d_custom.txt文件并查看三維模型的預(yù)處理器配置。
第 13 行定義了三維模型所需的 5 維輸入形狀:
network-input-shape = 4;3;32;224;224
對(duì)于此應(yīng)用程序,您將使用四個(gè)輸入,每個(gè)輸入有一個(gè) ROI :
- 您的批次號(hào)為 4 (#輸入*每個(gè)輸入的 ROI )。
- 您的輸入是 RGB ,因此通道數(shù)為 3 。
- 序列長(zhǎng)度為 32 ,輸入分辨率為 224 × 224 ( HxW )。
第 18 行告訴預(yù)處理器庫(kù)您正在使用自定義序列:
network-input-order = 2
第 51 行和第 52 行定義了如何將幀傳遞給推理機(jī):
stride=1 subsample=0
-
subsample值為 0 意味著您按順序?qū)ǖ?1 幀、第 2 幀……)傳遞到推斷步驟。 -
stride值為 1 表示序列之間存在單個(gè)幀的差異。例如:- 序列 A :幀 1 , 2 , 3 , 4 …
- 序列 B :幀 2 , 3 , 4 , 5 …
最后,第 55-60 行定義了輸入和 ROI 的數(shù)量:
src-ids=0;1;2;3 process-on-roi=1 roi-params-src-0=0;0;1280;720 roi-params-src-1=0;0;1280;720 roi-params-src-2=0;0;1280;720 roi-params-src-3=0;0;1280;720
有關(guān)所有應(yīng)用程序和預(yù)處理器參數(shù)的更多信息,請(qǐng)參閱 DeepStream 文檔的Action Recognition部分。
運(yùn)行新模型
現(xiàn)在,您可以修改應(yīng)用程序配置并測(cè)試練習(xí)動(dòng)作識(shí)別模型。
因?yàn)槟褂玫氖?Docker 映像,所以在主機(jī)文件系統(tǒng)和容器之間傳輸文件的最佳方法是在啟動(dòng)容器以設(shè)置可共享位置時(shí)使用-v mount標(biāo)志。例如,使用-v /home:/home將主機(jī)的/home目錄裝載到容器的/home目錄。
將新模型、標(biāo)簽文件和文本視頻復(fù)制到/app/sample_apps/deepstream-3d-action-recognitionfolder.
# back up the original labels file $ cp ./labels.txt ./labels_bk.txt $ cp /home/labels.txt ./ $ cp /home/Exercise_demo.mp4 ./ $ cp /home/rgb_resnet18_3d_exercises.etlt ./
打開(kāi)deepstream_action_recognition_config.txt并將第 30 行更改為指向運(yùn)動(dòng)測(cè)試視頻。
uri-list=file:////opt/nvidia/deepstream/deepstream-6.0/sources/apps/sample_apps/deepstream-3d-action-recognition/Exercise_demo.mp4
打開(kāi)config_infer_primary_3d_action.txt并將第 63 行用于推斷的模型和第 68 行的批次大小從 4 更改為 1 ,因?yàn)槟鷮乃膫€(gè)輸入更改為一個(gè)輸入:
tlt-encoded-model=./rgb_resnet18_3d_exercises.etlt .. batch-size=1
最后,打開(kāi)config_preprocess_3d_custom.txt。更改network-input-shape值以反映第 35 行上運(yùn)動(dòng)識(shí)別模型的單個(gè)輸入和配置:
network-input-shape= 1;3;3;224;224
修改第 77 – 82 行中單個(gè)輸入和 ROI 的源設(shè)置:
src-ids=0 process-on-roi=1 roi-params-src-0=0;0;1280;720 #roi-params-src-1=0;0;1280;720 #roi-params-src-2=0;0;1280;720 #roi-params-src-3=0;0;1280;720
現(xiàn)在可以使用以下命令測(cè)試新模型:
$ deepstream-3d-action-recognition -c deepstream_action_recognition_config.txt
應(yīng)用程序源代碼
動(dòng)作識(shí)別示例應(yīng)用程序使您能夠靈活地更改輸入源、輸入數(shù)量和使用的模型,而無(wú)需修改應(yīng)用程序源代碼。
要查看應(yīng)用程序是如何實(shí)現(xiàn)的,請(qǐng)參閱/sources/apps/sample_apps/deepstream-3d-action-recognition文件夾中的應(yīng)用程序源代碼以及預(yù)處理器插件使用的自定義序列庫(kù)。
總結(jié)
在這篇文章中,我們分別使用TAO Toolkit和DeepStream向您展示了一個(gè)端到端的工作流程,用于微調(diào)和部署動(dòng)作識(shí)別模型。 TAO 工具包和 DeepStream 都是抽象出 AI 框架復(fù)雜性的解決方案,使您能夠在生產(chǎn)中構(gòu)建和部署 AI 應(yīng)用程序,而無(wú)需任何 AI 專(zhuān)業(yè)知識(shí)。
通過(guò)從NGC catalog下載模型,開(kāi)始使用動(dòng)作識(shí)別模型。
關(guān)于作者
Chintan Shah 是 NVIDIA 的產(chǎn)品經(jīng)理,專(zhuān)注于智能視頻分析解決方案的 AI 產(chǎn)品。他管理工具箱,用于有效的深度學(xué)習(xí)培訓(xùn)和實(shí)時(shí)推理。在他之前的工作中,他正在為 NVIDIA GPU 開(kāi)發(fā)硬件 IP 。他擁有北卡羅來(lái)納州立大學(xué)電氣工程碩士學(xué)位。
Alvin Clark 是 DeepStream 的產(chǎn)品營(yíng)銷(xiāo)經(jīng)理。阿爾文的職業(yè)生涯始于設(shè)計(jì)工程師,然后轉(zhuǎn)向技術(shù)銷(xiāo)售和市場(chǎng)營(yíng)銷(xiāo)。他曾與多個(gè)行業(yè)的客戶(hù)合作,應(yīng)用范圍從衛(wèi)星系統(tǒng)、外科機(jī)器人到深海潛水器。阿爾文持有圣地亞哥加利福尼亞大學(xué)的工程學(xué)學(xué)位,目前正在喬治亞理工大學(xué)攻讀碩士學(xué)位。
Akhil Docca 是 NVIDIA NGC 的高級(jí)產(chǎn)品營(yíng)銷(xiāo)經(jīng)理,專(zhuān)注于 HPC 和 DL 容器。 Akhil 擁有加州大學(xué)洛杉磯分校安德森商學(xué)院工商管理碩士學(xué)位,圣何塞州立大學(xué)機(jī)械工程學(xué)士學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4994瀏覽量
103166 -
gpu
+關(guān)注
關(guān)注
28文章
4743瀏覽量
128996
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU是如何訓(xùn)練AI大模型的
AI模型部署邊緣設(shè)備的奇妙之旅:如何實(shí)現(xiàn)手寫(xiě)數(shù)字識(shí)別
AI大模型的訓(xùn)練數(shù)據(jù)來(lái)源分析
如何訓(xùn)練自己的AI大模型
直播預(yù)約 |數(shù)據(jù)智能系列講座第4期:預(yù)訓(xùn)練的基礎(chǔ)模型下的持續(xù)學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論