") Magnum IO存儲合作伙伴關(guān)系和最新成果分享
Magnum IO存儲合作伙伴關(guān)系和最新成果分享
我們鼓勵您基于目前通用的產(chǎn)品部署生產(chǎn)解決方案,并考慮將新出現(xiàn)的解決方案納入下一代系統(tǒng)。 GPU Direct Storage 現(xiàn)已在 v1.0 版中全面提供,更多的供應(yīng)商合作伙伴正在將支持 GDS 的產(chǎn)品轉(zhuǎn)移到 GA 狀態(tài)。還有一系列案例研究,涵蓋存儲框架、深度學(xué)習(xí)、地震、數(shù)據(jù)分析和數(shù)據(jù)庫。
隨著 AI 、 ML 和 HPC 應(yīng)用程序的計(jì)算從 CPU 轉(zhuǎn)移到更快的 GPU ,輸入輸出 GPU 的 IO 可能成為整體應(yīng)用程序性能的主要瓶頸。
NVIDIA 創(chuàng)建了 Magnum IO GPU 直接存儲( GDS ),以簡化存儲和 GPU 內(nèi)存之間的數(shù)據(jù)移動,并消除平臺中的性能瓶頸,例如被迫通過 CPU 內(nèi)存中的緩沖區(qū)存儲和轉(zhuǎn)發(fā)數(shù)據(jù)。
GDS 通過在本地 NVMe 存儲或 NIC 后面的遠(yuǎn)程存儲和 GPU 內(nèi)存之間啟用直接內(nèi)存訪問( DMA ),提高了帶寬,減少了延遲,減輕了 CPU 利用率的負(fù)擔(dān)。從 DGX 平臺上的 GDS 本身的深度學(xué)習(xí)推理、數(shù)據(jù)分析可視化和視頻分析中分別觀察到 2 。 5x 、 8x 和 9x 的性能優(yōu)勢。
要在部署的平臺范圍內(nèi)加速各種各樣的客戶應(yīng)用程序和框架,需要一系列合作關(guān)系。我們的目標(biāo)是實(shí)現(xiàn)整個(gè)豐富的數(shù)據(jù)存儲生態(tài)系統(tǒng),該生態(tài)系統(tǒng)由近 180 家軟件和硬件供應(yīng)商以及 2500 多個(gè)貢獻(xiàn)者組成。有關(guān)更多信息,請參閱SNIA網(wǎng)站。
本文概述了 GDS 合作生態(tài)系統(tǒng),并分享了我們合作伙伴的最新成果。
GDS 生態(tài)系統(tǒng)
NVIDIA 尋求一個(gè)開放的生態(tài)系統(tǒng),與供應(yīng)商、框架開發(fā)人員和最終客戶建立越來越多的合作伙伴關(guān)系。自 GPU Direct Storage 的 1 。 0 產(chǎn)品發(fā)布以來,合作伙伴供應(yīng)商的生態(tài)系統(tǒng)已經(jīng)發(fā)展,如表 1 所示。
每個(gè)類別中的項(xiàng)目按時(shí)間順序排列。尚未發(fā)布的項(xiàng)目和正在開發(fā)的項(xiàng)目均為斜體。以黃色突出顯示的項(xiàng)目具有自本系列最后一篇 GDS 文章發(fā)布以來的新數(shù)據(jù)。
Vendor partnersFrameworks and applicationsSystems software
File systems
– DDN EXAScaler
– Weka FS
– VAST NFSoRDMA
– EXT4 via NVMe or NVMoF drivers from MLNX_OFED
– IBM Spectrum Scale (GPFS)
– DELL Technologies PowerScale
– NetApp/SFW/BeeGFS
– NetApp/NFS
– HPE Cray ClusterStor Lustre
Block systems
– Excelero
– ScaleFlux smart storageStorage
-HDF5
– ADIOS
– OMPIO
Deep learning
– PyTorch
– MXNet
Data analytics
– cuDF
– DALI
– Spark
– cuSIM/Clara
– NVTabular
Databases
– HeteroDB for PostgreSQL acceleration
Visualization
– IndeX– Ubuntu 18.04
– Ubuntu 20.04
– RHEL 8.3
– RHEL 8.4
– DGX BaseOS
Compatibility mode only:
– Debian 10
– RHEL7.9
– CentOS 7.9
– Ubuntu 18.04 (desktop)
– Ubuntu 20.04 (desktop)
– SLES 15.2
– OpenSUSE 15.2
Contributions to a repoSystems vendorsMedia vendors
Readers
– Serial HDF5
– IOR Containers
– PyTorch/DALI Samples
– Transparent threading
– Buffer agnostic– Dell
– Hitachi
– HPE
– IBM
– Liqid
– Pavilion– Kioxia
– Micron
– Samsung
– Western Digital
表 1 。 GPU 直接存儲生態(tài)系統(tǒng)中的產(chǎn)品
供應(yīng)商合作伙伴
我們有幾種不同類型的供應(yīng)商合作伙伴,他們的產(chǎn)品具有不同的成熟度。供應(yīng)商合作伙伴分為兩類:直接參與 GDS 軟件支持的合作伙伴和提供系統(tǒng)和組件解決方案的合作伙伴。
GDS 支持合作伙伴全面提供
本節(jié)涵蓋了那些積極地使英偉達(dá) GPU 直接存儲到他們擁有的軟件棧中的合作伙伴,滿足 NVIDIA 基本功能和性能標(biāo)準(zhǔn),并將其集成到一般可用性的生產(chǎn)解決方案中。
DDN 將 GDS 集成到基于 Lustre 的 EXAScaler 并行文件系統(tǒng)中。他們正在與社區(qū)合作,將 GDS 支持上游到開源發(fā)行版。
Dell Power Scale 是 NFS 的優(yōu)化實(shí)現(xiàn)。
IBM Spectrum Scale ,以前稱為 GPFS ,是 HPC 、數(shù)據(jù)和 AI 中廣泛使用的分布式并行文件系統(tǒng)。
龐大的并行分布式文件系統(tǒng)開創(chuàng)了通過 RDMA ( NFSoRDMA )提供多路徑 NFS 的先河。 VAST 還使 nconnect 中 NFSoRDMA 中的 GDS 在將來的上游版本中可用。
Weka 將 GDS 集成到自己的 Weka FS 并行分布式文件系統(tǒng)中。
解決方案和組件提供商全面提供
一些供應(yīng)商對 GDS 的支持處于通用可用性級別。一些供應(yīng)商提供軟件解決方案,對代碼進(jìn)行更改以啟用 GDS ,而其他供應(yīng)商則是已經(jīng)或?qū)⒁褂?GDS 的組件或系統(tǒng)供應(yīng)商。
提供硬件或 GDS 特性數(shù)據(jù)的供應(yīng)商
NVIDIA 與我們的 NPN 和 GPU 直接存儲合作伙伴密切合作,以鑒定 GDS 的全部功能。他們還使用硬件和軟件解決方案,結(jié)合 NVIDIA 帶來的最佳 GPU 加速技術(shù),量化測量的性能增益。這些措施包括:。
使用其他支持 GDS 的解決方案(如 MLNX _ OFED 中提供的解決方案)提供完整端到端解決方案的系統(tǒng)供應(yīng)商合作伙伴包括:
數(shù)字?jǐn)?shù)據(jù)網(wǎng)
戴爾科技
惠普企業(yè)
國際商用機(jī)器公司
亭閣
巨大的
與我們合作最密切的組件供應(yīng)商包括:
基奧西亞
微米
桑孫
標(biāo)度通量
表達(dá)興趣的供應(yīng)商
對 GDS 表示強(qiáng)烈興趣的其他供應(yīng)商包括:
日立
輕盈
西部數(shù)字
開發(fā)中的 GDS 支持合作伙伴
有些合作伙伴的產(chǎn)品可供您評估,但尚未達(dá)到全面可用的成熟期:
BeeGFS 并行分布式文件系統(tǒng)是 HPC 中常用的文件系統(tǒng)。 System Fabric Works 一直在與 NetApp 合作為 BeeGFS 啟用 GDS 。
Excelero NVMesh 將任何網(wǎng)絡(luò)上的 NVMe 驅(qū)動器轉(zhuǎn)換為支持任何本地或分布式文件系統(tǒng)的企業(yè)級受保護(hù)共享存儲。
HPE 促成了 Cray ClusterStor E1000 Storage System中使用的支持 GDS 的 Lustre 并行分布式文件系統(tǒng)代碼的升級。
NetApp 目前正在致力于啟用服務(wù)器端 NFSoRDMA ,因此他們可以利用其他人在客戶端啟用 NFS 的 GDS 。
具有 GDS 的供應(yīng)商證明點(diǎn)
自 NVIDIA 發(fā)布last GDS post以來,已有幾項(xiàng)新數(shù)據(jù)的開發(fā)。我們在這篇文章中分享了其中的一個(gè)示例,作為證明 GPU 直接存儲的好處和通用性的證據(jù)。
配置
GDS 可以通過跳過各種平臺上的 CPU 跳出緩沖區(qū)來增加價(jià)值,無論是 NVIDIA 的 DGX 系統(tǒng)還是第三方 OEM 平臺。如前一篇文章Accelerating IO in the Modern Data Center: Magnum IO Storage所述,當(dāng) NIC PCIe 交換機(jī) – GPU 數(shù)據(jù)路徑不經(jīng)過 CPU 就可用時(shí), GDS 可用的理論峰值帶寬有 2 倍的差異,盡管實(shí)際增益可能要大得多。
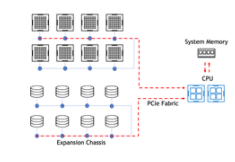
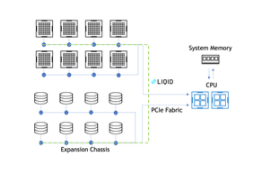
在 DGX 中,某些 NIC 插槽的數(shù)據(jù)路徑必須經(jīng)過 CPU ,而對于其他插槽,直接 NIC PCIe 交換機(jī) GPU 路徑可繞過 CPU 。圖 2 顯示了 DGX A100 背面的標(biāo)記圖片。
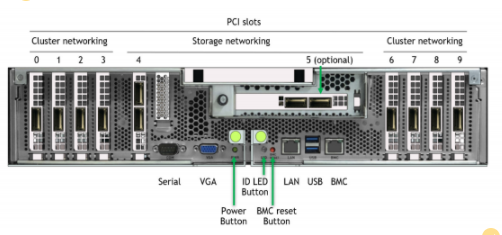
圖 2 。帶有標(biāo)記 NIC 插槽的 DGX A100 背面圖片。插槽 4 和 5 (傳統(tǒng)上連接到存儲網(wǎng)絡(luò))分別連接到 CPU 。插槽 0-3 和 6-9 分別連接到 PCIe 交換機(jī),與 GPU s 0-7 一樣。
有兩種配置可以在 DGX A100 上評估存儲性能。經(jīng)批準(zhǔn)的標(biāo)準(zhǔn)配置在插槽 4 和 5 中專用于連接到用戶管理平面和外部存儲平面的兩個(gè)“南北”(朝向數(shù)據(jù)中心邊緣) NIC ,以及在插槽 0-3 和 6-9 中專用于連接到節(jié)點(diǎn)間計(jì)算平面的八個(gè)“東西”(集群內(nèi)) NIC 。
我們正朝著使用八個(gè)東西方 NIC 訪問高帶寬存儲的方向發(fā)展,從而在完成 QoS 評估之前創(chuàng)建一個(gè)聚合計(jì)算存儲平面。現(xiàn)在,我們稱之為實(shí)驗(yàn)的配置
以前提供的合作伙伴數(shù)據(jù)
自從第一次發(fā)布 GDS 后, NVIDIA 已經(jīng)公開了其他供應(yīng)商的數(shù)據(jù)。其中包括來自 DDN EXAScaler 、 Pavilion NFSoRDMA 、 VAST NFSoRDMA 和 Weka FS 的數(shù)字。使用 DGX A100 上的實(shí)驗(yàn)性 8-NIC 配置,我們已經(jīng)看到供應(yīng)商提供的帶寬范圍為 152 到 178 GiB ( 186 GB / s )的 GDS 。如果沒有 GDS ,他們報(bào)告的帶寬范圍為 40-103 GiB / s 。
今后, NVIDIA 要求任何合作伙伴的 DGX 系統(tǒng)性能報(bào)告(包括 8-NIC 數(shù)據(jù))也應(yīng)包括兩個(gè)南北 NIC 的特性描述。這些數(shù)據(jù)還沒有全部出來,所以這里沒有介紹。我們的政策是不在供應(yīng)商合作伙伴之間進(jìn)行直接性能比較。
以太網(wǎng)上的海量數(shù)據(jù)
以前在 InfiniBand 上報(bào)告了海量數(shù)據(jù)通用存儲。他們提供了一個(gè)單一(插槽 4 ) NIC 和 DGX A100 中的 1 GPU 的新結(jié)果,該 DGX A100 具有龐大的入門級 1 × 1 配置,使用以太網(wǎng)而不是 InfiniBand 。以太網(wǎng)顯示了完整的功能和相當(dāng)?shù)男阅堋膯蝹€(gè)鏈路實(shí)現(xiàn)超過 22 GiB / s 的速度接近最高性能。這表明,除了 InfiniBand 之外, GDS 同樣適用于以太網(wǎng)。
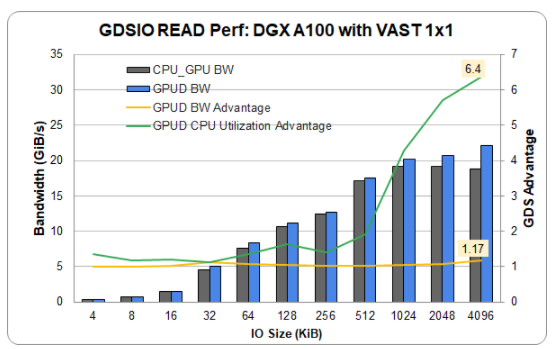
圖 3 。在 GDS v 上,插槽 4 中有 1 個(gè) NIC ,插槽 1 GPU 中有 1 個(gè) NIC ,以太網(wǎng)具有極高的讀取性能。 1 。 0 。 0 。 61 , 96 個(gè)螺紋,預(yù)取開啟。帶寬優(yōu)勢高達(dá) 1 。 17 倍, CPU 利用率優(yōu)勢高達(dá) 6 。 4 倍。
IBM 頻譜規(guī)模
IBM Spectrum Scale (前身為 GPFS )的 GA 產(chǎn)品最近有了一個(gè)條目。在他們的配置中,一個(gè)運(yùn)行 IBM Spectrum Scale 5 。 1 。 1 的 ESS 3200 存儲文件服務(wù)器提供了 71 GiB / s ( 77 GB / s )。它通過 4 個(gè) HDR NIC 的 NIC 插槽 4 和 5 連接到兩個(gè)采用傳統(tǒng)存儲網(wǎng)絡(luò)配置的 DGX A100 。 IO 大小為 1MB 。通常情況下,絕對性能隨著使用的線程數(shù)的增加而提高(圖 4 )。與沒有 GDS 的情況相比, GDS 的相對改進(jìn)在線程數(shù)量方面仍然相當(dāng)穩(wěn)定,但在線程數(shù)量較少的情況下顯然是最好的。
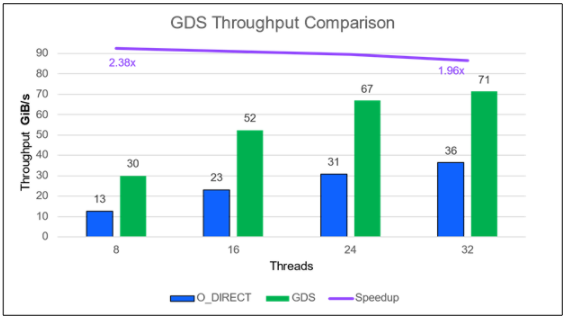
圖 4 。 IBM Spectrum Scale 5 。 1 。 1 讀取性能,具有足夠( 2 )個(gè) DGX A100 盒,可使單個(gè) IBM ESS 3200 飽和。 GDS 收益超過 2 倍。
展館數(shù)據(jù)結(jié)果
Pavilion 為分布式并行文件系統(tǒng)、塊和對象接口提供存儲解決方案。它使用 NFSoRDMA 啟用 GDS 。 Pavilion Data 提供占用四個(gè)機(jī)架單元( RU )的存儲節(jié)點(diǎn),提供足夠的帶寬,其中兩個(gè)節(jié)點(diǎn)可以使四個(gè) DGX A100 上的兩個(gè) NIC 或單個(gè) DGX A100 上的八個(gè) NIC 達(dá)到飽和。圖 5 中的結(jié)果僅來自實(shí)驗(yàn)配置, Pavilion 軟件版本 2 執(zhí)行文件訪問。
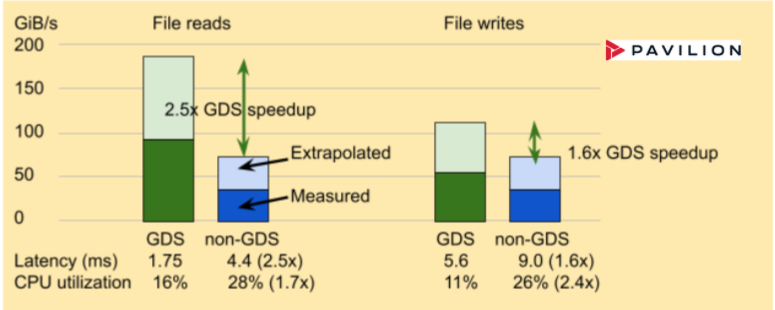
圖 5 。 4RU Pavilion 存儲產(chǎn)品為 DGX A100 的一半提供高達(dá) 89 GiB / s 的 NFSoRDMA 讀取性能。 GDS 提供了 2 。 5 倍的帶寬和延遲優(yōu)勢,同時(shí)將 CPU 利用率(如下所示的延遲)降低了 1 。 7 倍用于讀取,更多用于寫入。在 8RU 中加倍到兩個(gè) Pavilion 節(jié)點(diǎn)應(yīng)線性縮放。
Liqid 結(jié)果
最近在 Liqid 系統(tǒng)上測量的性能表明,基于 PCIe 的 P2P 路徑比基于以太網(wǎng)/ InfiniBand 的 NVMe 更快。 GPU 和與 GDS 集成的 SSD 之間的 P2P 通信達(dá)到 2900K IOPS ,吞吐量提高了 16 倍。與非 GDS 路徑相比,延遲從 712 us 提高了 1 。 86 倍至 112 us (圖 6 )。
GPU 到 SSD 且禁用 P2P
吞吐量: 179K
IOPS 潛伏期: 712 us
GPU 到 SSD ,帶啟用 GDS 的 P2P
吞吐量: 2900K
IOPS 潛伏期: 112 us
收集了三種不同配置的數(shù)據(jù):
配置 1 : GPU – 到 NVMe 。使用 Liqid 結(jié)構(gòu)連接同一 PCIe 結(jié)構(gòu)上的所有設(shè)備。
配置# 2 : GPU – 到 – CPU – 到 NVMe 。將 GPU 和 NVMe 驅(qū)動器直接連接到 CPU 主板。
配置# 3 : GPU – 到的 NIC NVMe 。使用 GPU 到( CX-5 )的 NVMe 通過網(wǎng)絡(luò)訪問遠(yuǎn)程 NVMe 。
以下是配置的詳細(xì)信息:
主板: AsROCK 機(jī)架 ROME8D-2T ,配備 AMD Epyc 7702p 、 512GB DDR4 2933
系統(tǒng)軟件: Ubuntu 服務(wù)器 20 。 04 。 2 , NVIDIA 驅(qū)動程序版本 470 。 63 。 01 , CUDA 11 。 4
Liqid QD4500 配備 Phison E16 800GB 、 Gen4 PCIe 、運(yùn)行 Liqid v3 。 0 的 24 端口 Gen4 數(shù)據(jù)交換機(jī)( Astek )的 24 端口管理交換機(jī)( TOR )
NVIDIA A100 40GB , PCIe Gen4 與 LQS4500 位于同一 PCIe 交換機(jī)上
BIOS 設(shè)置 ACS = Off ,在 Liqid 中啟用 P2P 。
圖 6 。 GPU 和 SSD (或 NVMe 驅(qū)動器)之間的點(diǎn)對點(diǎn)( P2P )通信通過 GPU 直接存儲實(shí)現(xiàn)了幾個(gè)數(shù)量級的 IOPS 改進(jìn).GPU Liqid Matrix 擴(kuò)展機(jī)箱中的直接存儲支持 GPU 和 SSD 之間的直接 P2P 通信,實(shí)現(xiàn)了高達(dá) 1620% 的 IOPS 加速和 86% 的延遲改善。
InfiniBand 和以太網(wǎng)
雖然 Infiniband 在傳統(tǒng) HPC 系統(tǒng)中很受歡迎,但以太網(wǎng)在企業(yè)數(shù)據(jù)中心中有著廣泛的應(yīng)用。 GDS 在以太網(wǎng)和 IB 上無處不在。關(guān)鍵要求是底層系統(tǒng)和遠(yuǎn)程文件管理器支持 RDMA 。這在 RoCE 中是可能的。
那么,兩者之間的比較如何呢?以下是初步調(diào)查的一些結(jié)果。對通過擴(kuò)展網(wǎng)絡(luò)訪問存儲的全面分析不在本文討論范圍之內(nèi),但對于那些希望就其網(wǎng)絡(luò)設(shè)計(jì)做出數(shù)據(jù)驅(qū)動決策的人來說,這是值得鼓勵的。
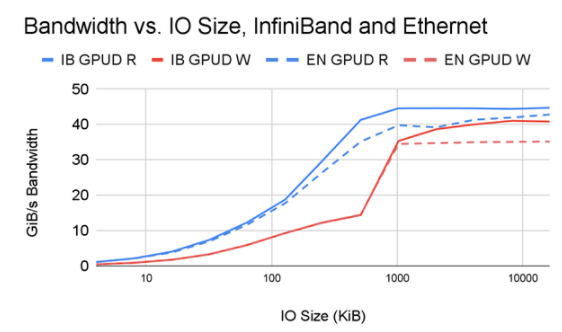
圖 7 。對于 HDR 200 上的 InfiniBand ( IB )和 Ethernet ( EN ),在兩個(gè) NIC 上實(shí)現(xiàn)了對 DDN AI400x 文件服務(wù)器的讀寫帶寬,該帶寬是 IO 大小的函數(shù),并帶有單個(gè)中間交換機(jī)。
圖 7 顯示了在以下條件下帶寬隨 IO 大小變化的并排比較:
單個(gè) PCIe 樹中的兩個(gè) NIC 使用 InfiniBand 連接到一個(gè) DDN AI400x 文件服務(wù)器
單個(gè) PCIe 樹中的兩個(gè) NIC 使用以太網(wǎng)連接到同一 DDN AI400x 文件服務(wù)器
如您所見, IB 和帶有 GDS 的以太網(wǎng)的性能相當(dāng), GDS 顯然是建立在 GPU 直接 RDMA 之上的。 IB 比以太網(wǎng)具有高達(dá) 1 。 17 倍的性能優(yōu)勢,尤其是在性能最高且網(wǎng)絡(luò)速度差異最大的更大 IO 尺寸下。
社區(qū)光澤
不同的供應(yīng)商為 Lustre 的社區(qū)版本增加了自己的價(jià)值。但我們的一些客戶僅限于使用 OSS 社區(qū) Lustre 。他們還能在非專有解決方案中享受 GDS 的好處嗎?答案是肯定的!
與不使用 GDS 相比, GDS 的帶寬、延遲和 CPU 利用率增益都與其他啟用 GDS 的實(shí)現(xiàn)類似。可下載版本 2 。 15 的每個(gè)發(fā)行版本。今天就試試吧!
混搭
我們在 NVIDIA 有一個(gè)實(shí)驗(yàn)集群,我們稱之為 ForMIO (用于 Magnum IO ),因?yàn)樗糜谠u估和審查與 Magnum IO ( MIO )相關(guān)的各種技術(shù)。 DDN 和 Pavilion 慷慨地讓我們使用他們的設(shè)備進(jìn)行文件管理。媒體供應(yīng)商 Kioxia 、 Micron 和 Samsung 慷慨捐贈了驅(qū)動器來填充其中一些文件服務(wù)器。我們很興奮,因?yàn)檫@加快了對 DL 框架和使用 GDS 的客戶應(yīng)用程序的評估。
我們做了一些瘋狂的嘗試,結(jié)果成功了!我們使用兩個(gè) HDR 200 NIC 將一個(gè) DDN AI400x 與 InfiniBand 連接起來,一個(gè) DDN AI400s 與兩個(gè) HDR 200 NIC 的以太網(wǎng)連接起來,八個(gè)本地 NVME 與一個(gè) DGX A100 連接起來。我們使用 GDSIO 性能評估工具對所有客戶進(jìn)行了測試。
圖 8 中的早期和未調(diào)整的結(jié)果顯示,存儲帶寬可以跨這些應(yīng)用程序組合,以向應(yīng)用程序提供帶寬。雖然我們在實(shí)踐中不一定推薦這一點(diǎn),但知道這是可能的還是很酷的。感謝 DDN 支持實(shí)現(xiàn)這一點(diǎn)。
在單個(gè) DGX A100 上分別(紅色、藍(lán)色、黃色)和同時(shí)(綠色)測量帶有 InfiniBand 的一個(gè) DDN AI400x (使用兩個(gè) HDR 200 NIC )、帶有以太網(wǎng)的一個(gè) DDN AI400s (使用兩個(gè) HDR 200 NIC )和八個(gè)本地 NVME 的性能。單個(gè)組件堆疊在每對的左側(cè)。當(dāng)它們都同時(shí)運(yùn)行時(shí),綠色條顯示性能。
在 GDS 的情況下,性能完全匹配,因?yàn)?GPU 目標(biāo)被仔細(xì)選擇為無干擾。在 CPU 中使用跳出緩沖區(qū)的非 GDS 情況下,進(jìn)出 CPU 的擁塞會抑制并發(fā)性能。這是一個(gè)巨大的不同。
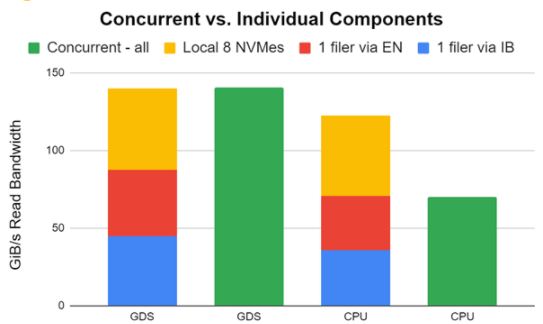
圖 8 。通過 IB 在 2 個(gè) NIC 上實(shí)現(xiàn)了對 DDN AI400x 的讀取帶寬,通過以太網(wǎng)在 2 個(gè) NIC 上實(shí)現(xiàn)了對不同 DDN AI400x 的讀取帶寬,以及 8 個(gè)本地 NVME 的讀取帶寬。分別和同時(shí)測量。
關(guān)于作者
CJ Newburn 是 NVIDIA 計(jì)算軟件組的首席架構(gòu)師,他領(lǐng)導(dǎo) HPC 戰(zhàn)略和軟件產(chǎn)品路線圖,特別關(guān)注系統(tǒng)和規(guī)模編程模型。 CJ 是 Magnum IO 的架構(gòu)師和 GPU Direct Storage 的聯(lián)合架構(gòu)師,與能源部領(lǐng)導(dǎo) Summit Dev 系列產(chǎn)品,并領(lǐng)導(dǎo) HPC 容器咨詢委員會。在過去的 20 年里, CJ 為硬件和軟件技術(shù)做出了貢獻(xiàn),擁有 100 多項(xiàng)專利。他是一個(gè)社區(qū)建設(shè)者,熱衷于將硬件和軟件平臺的核心功能從 HPC 擴(kuò)展到 AI 、數(shù)據(jù)科學(xué)和可視化。在卡內(nèi)基梅隆大學(xué)獲得博士學(xué)位之前, CJ 曾在幾家初創(chuàng)公司工作過,致力于語音識別器和 VLIW 超級計(jì)算機(jī)。他很高興能為他媽媽使用的批量產(chǎn)品工作。
Kiran K. Modukuri 是 NVIDIA 的首席軟件工程師,負(fù)責(zé)加速 IO 管道。他是 GPU 直接存儲產(chǎn)品的聯(lián)合架構(gòu)師。在加入 NVIDIA 之前,他曾在 NetApp 擔(dān)任高級軟件工程師。他在亞利桑那大學(xué)獲得了計(jì)算機(jī)科學(xué)碩士學(xué)位。他在分布式文件系統(tǒng)和存儲技術(shù)方面擁有超過 15 年的經(jīng)驗(yàn)。
審核編輯:郭婷
-
cpu
+關(guān)注
關(guān)注
68文章
10882瀏覽量
212293 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5026瀏覽量
103296
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論