 Magnum IO的體系結構、組件和優點
Magnum IO的體系結構、組件和優點
這是 解釋 Magnum IO 系列的第三篇文章,目的是描述現代數據中心的IO子系統Magnum IO的體系結構、組件和優點。
本系列中的 第一個崗位 介紹了 Magnum IO 體系結構;將其定位在更廣泛的 CUDA 、 CUDA -X 和垂直應用程序域中;并列出了體系結構的四個主要組件。 第二崗位 深入研究了 Magnum IO 的網絡 IO 組件。第三篇文章涵蓋了兩個較短的領域:網絡適配器或交換機中的計算和 IO 管理。無論您是對 InfiniBand 還是以太網感興趣, NVIDIA Mellanox 解決方案都涵蓋了您。
HDR 200G InfiniBand 和 NDR 400G ,下一代網絡
InfiniBand 是 AI 超級計算的理想互連選擇。根據 2020 年 11 月的 500 強超級計算機排行榜,全球前 10 強超級計算機中有 8 臺正在使用它,前 100 強中有 60 臺正在使用它。 InfiniBand 還加速了綠色 500 強超級計算機的速度。作為一種基于標準的互連, InfiniBand 享受著不斷開發的新功能,以實現更高的應用程序性能和可擴展性。
InfiniBand 技術基于四個主要基礎:
一種端點,可以在網絡級別執行和管理所有網絡功能,從而增加 CPU 或 GPU 時間,專門用于實際應用程序。 由于端點位于 CPU / GPU 內存附近,因此它還可以有效地管理內存操作,例如使用 RDMA 、 GPUDirect RDMA 和 GPUDirect 存儲。
一種基于純軟件定義網絡( SDN )的、按規模設計的交換網絡。 例如, InfiniBand 交換機不需要每個交換機設備中都有嵌入式服務器來管理交換機和運行其操作系統。這使得 InfiniBand 成為與其他網絡相比性價比領先的網絡結構。簡單的交換機架構為其他技術創新留下了空間,例如在網絡計算中,在數據通過網絡傳輸時對其進行操作。一個重要的例子是可伸縮的層次聚合和歸約協議( SHARP )技術,它已經證明了科學和深度學習應用框架的巨大性能改進。
從一個地方集中管理整個 InfiniBand 網絡。 您可以使用通用的 IB 交換機構建塊設計和構建任何類型的網絡拓撲,并為其目標應用程序定制和優化數據中心網絡。不需要為網絡的不同部分創建不同的交換機配置,也不需要處理多種復雜的網絡算法。 InfiniBand 的創建是為了提高性能和減少運營成本。
前后兼容。 InfiniBand 是帶有開放 API 的開源軟件。
在 SuperComputing 20 上, NVIDIA 宣布了第七代 NVIDIA Mellanox InfiniBand 架構,其特點是 NDR 400Gb / s (每車道 100 Gb / s ) InfiniBand 。這使人工智能開發人員和科研人員能夠以最快的網絡性能應對世界上最具挑戰性的問題。圖 1 顯示 InfiniBand 繼續使用 NDR InfiniBand 設置性能記錄:
每端口帶寬為 400Gb / s ,數據傳輸速率提高 2 倍。
4 倍的消息傳遞接口( MPI )性能,適用于所有對所有操作,新的網絡計算加速引擎適用于所有對所有操作。
更高的交換機基數,支持 64 個 400Gb / s 端口或 128 個 200Gb / s 端口。更高的基數可以在三跳 Dragonfly +網絡拓撲中構建連接超過一百萬個節點的低延遲網絡拓撲。
最大的高性能交換機系統,基于無阻塞、兩層胖樹拓撲設計,提供 2048 個 400Gb / s 端口或 4096 個 200Gb / s 端口,共 1 。 6petabit 的雙向數據吞吐量。
通過夏普技術提高了人工智能網絡加速,使網絡中的大型消息縮減操作的容量提高了 32 倍。

圖 1 。 NDR 400Gb / s InfiniBand 生成中的網絡改進。
高速以太網: 200G 和 400G 以太網
以太網和 InfiniBand 各有其獨特的優勢。 NVIDIA Mellanox 用這對溶液覆蓋堿基。有幾種情況下,客戶首選基于以太網的解決方案。有些存儲系統只能使用以太網。人們對安全性越來越感興趣,現有的協議是 IPSec ,這在 InfiniBand 上是不可用的。精確時間協議( PTP )用于以亞微秒的粒度在整個網絡中同步時鐘,例如用于高頻交易。在許多情況下,基于以太網的編排和資源調配工具、監控安全性、性能調優、法規遵從性或技術支持的分析工具方面的長期專業知識是推動客戶選擇的原因,而不是其他成本或性能問題。
以太網和 InfiniBand 解決方案都與廣泛關注的最佳實踐工具(如 sFlow 和 NetFlow 網絡監控和分析解決方案)以及自動化工具(如 Ansible 、 Puppet 和 SaltStack )進行互操作。
以太網已經變得無處不在,部分原因是它被認為易于配置和管理。但是, GPUDirect RDMA 和 GPUDirect Storage over Ethernet 要求將網絡結構配置為支持 RDMA over Converged Ethernet ( RoCE )。在大多數網絡供應商的設備上, RoCE 的配置和管理非常復雜。 NVIDIA Mellanox 以太網交換機通過使用單個命令啟用 RoCE 以及提供 RoCE 特定的可見性和故障排除功能,消除了這種復雜性。
NVIDIA Mellanox 以太網交換機現在的運行速度高達 400 Gb / s ,提供了最高級別的性能,因為它們提供了市場上所有以太網交換機中最低的延遲數據包轉發。 NVIDIA Mellanox 以太網交換機還提供獨特的擁塞避免創新,為基于 RoCE 的工作負載提供應用程序級性能優勢:

圖 2 。 NVIDIA 配置了 RoCE 的 Mellanox 交換機在應用程序被交換機阻塞期間的暫停時間可以忽略不計,而其他供應商的解決方案可能會有隨時間變化的顯著延遲。
以太網交換機已被證明具有可擴展性,世界上所有最大的數據中心都使用簡單且易于理解的葉和脊拓撲結構運行純以太網結構。來自 NVIDIA 的以太網結構易于自動化, NVIDIA 提供的交鑰匙 產品就緒自動化工具 免費提供并發布在 GitHub 上。
NVIDIA 的高速以太網交換機目前提供 100GbE 、 200GbE 甚至 400GbE 的速度,以實現基于以太網的存儲和 GPU 連接的最高性能。
網絡計算中的 InfiniBand
在網絡計算引擎中,指位于網絡適配器或交換機的數據路徑上的預先配置的計算引擎。這些引擎可以在網絡內傳輸數據時處理數據或對數據執行預定義的算法任務。這類引擎的兩個例子是硬件 MPI 標記匹配和 InfiniBand SHARP 。
硬件標簽匹配引擎
MPI 標準允許基于嵌入在消息中的標記來接收匹配的消息。處理每條消息以評估其標記是否符合感興趣的條件既耗時又浪費時間。
MPI 發送/接收操作需要匹配的源和目標消息參數才能將數據傳遞到正確的目標。匹配的順序必須遵循發送和接收的發布順序。提供高效標記匹配支持的關鍵挑戰包括:
管理標記匹配所需的元數據。
制作數據的臨時副本以最小化標記匹配和數據傳遞之間的延遲。
跟蹤未匹配的已過帳接收。
處理意外消息到達。
重疊標簽匹配和相關的數據傳遞與正在進行的計算。
支持異步、基于硬件的標記匹配和數據傳遞是 ConnectX-6 (或更高版本)網絡適配器的一部分。基于網絡硬件的標記匹配減少了多個 MPI 操作的延遲,同時也增加了 MPI 計算和通信之間的重疊(圖 3 和圖 4 )。
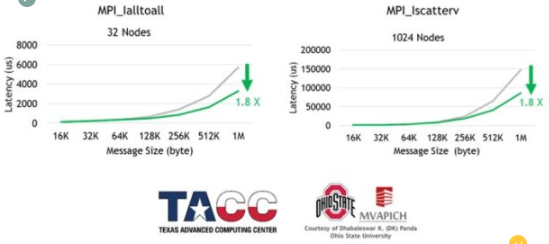
圖 3 。俄亥俄大學 MVAPICH 團隊在德克薩斯州高級計算中心 Frontera 超級計算機上演示了網絡計算標記匹配的加速。
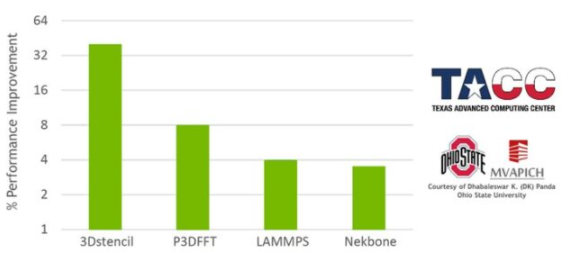
圖 4 。 InfiniBand 在網絡計算標記匹配引擎中的應用程序性能結果,在德克薩斯高級計算中心 Frontera 超級計算機上進行了測試。測試由 OSU MVAPICH 團隊完成。
SHARP :可擴展的分層聚合和歸約協議
NVIDIA Mellanox InfiniBand SHARP 通過在穿越網絡時處理數據聚合和還原操作,提高了集合操作的性能,消除了在端點之間多次發送數據的需要。這種創新的方法不僅減少了通過網絡的數據量,而且提供了額外的好處,包括釋放寶貴的 CPU 資源用于計算,而不是用它們來處理通信開銷。它還以異步方式進行此類通信,與主機處理狀態無關。
如果沒有 SHARP ,數據必須從每個端點發送到交換機,返回到計算集合的端點,返回到交換機,然后返回到端點。這是四個遍歷步驟。使用 SHARP 時,集合操作發生在交換機中,因此遍歷步驟的數量減少了一半:從端點到交換機,再返回。這使得這種集體操作的帶寬提高了 2 倍, MPI allreduce 延遲降低了 7 倍(圖 5 )。當然,吞吐量需求開銷也會從 CPU 或 GPU 中除去,否則這些開銷將用于計算。
支持的操作:
浮點數據: barrier 、 reduce 、 allreduce 、 broadcast 、 gather 和 allgather
有符號和無符號整數數據:大小為 64 、 32 和 16 位的操作數
支持的縮減操作: sum 、 min 、 max 、 minloc 、 maxloc 和按位 and 、 OR 和 XOR 。
SHARP 技術集成在大多數開源和商業 MPI 軟件包以及 OpenSHMEM 、 NCCL 和其他 IO 框架中。
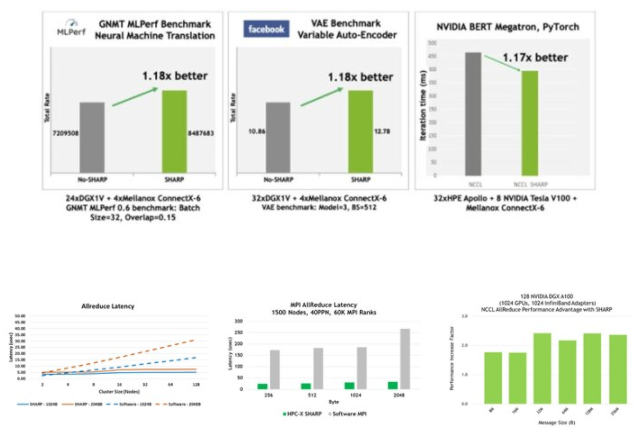
圖 5 。加速網絡計算夏普技術:提高 NCCL 所有吞吐量和減少 MPI 延遲。
InfiniBand 和以太網 IO 管理
雖然提高性能是最終用戶的興趣所在,而清晰的體系結構有助于開發人員,但 IO 管理對于您作為管理員和所服務的最終用戶來說至關重要。 NVIDIA Mellanox NetQ 和 UFM 管理平臺使 IT 經理能夠輕松配置、管理和優化其以太網連接數據中心( NetQ )或 InfiniBand 連接數據中心( UFM )操作。
以太網 NetQ
圖 6 。 NetQ 在以太網中增加了監控平面。
NVIDIA Mellanox 網絡電話 是一個高度可擴展的現代網絡操作工具集,可實時提供開放以太網的可見性、故障排除和生命周期管理。 NetQ 提供了關于數據中心和校園以太網健康狀況的可操作的見解和操作智能,從容器或主機一直到交換機和端口,支持 NetDevOps 方法。 NetQ 是領先的以太網網絡操作工具,它使用遙測技術從單個 GUI 界面進行深層次的故障排除、可見性和自動化工作流,減少維護和網絡停機時間。
NetQ 還可以作為一種安全的云服務提供,這使得安裝、部署和擴展網絡更加容易。基于云的 NetQ 部署提供了即時升級、零維護和最小化設備管理工作。
通過添加完整的生命周期管理功能, NetQ 將輕松升級、配置和部署網絡元素的能力與一整套操作功能結合起來,如可見性、故障排除、驗證、跟蹤和比較回溯功能。
NetQ 包括 Mellanox What Just ochapped ( WJH )先進的流式遙測技術,它通過提供異常網絡行為的可操作細節,超越了傳統的遙測解決方案。傳統的解決方案試圖通過分析網絡計數器和統計數據包采樣來推斷網絡問題的根本原因。 WJH 消除了網絡故障排除中的猜測。
WJH 解決方案利用 NVIDIA Mellanox Spe CTR um 系列以太網交換機 ASIC 內置的獨特硬件功能,以比基于軟件或固件的解決方案更快的多 TB 速度檢查數據包。 WJH 可以幫助診斷和修復數據中心網絡,包括軟件問題。 WJH 以線速率檢查所有端口上的數據包,其速度超過了傳統的深度數據包檢查( DPI )解決方案。 WJH 為您節省了數小時的計算機軟件故障排除、維護和維修現場技術支持服務。
InfiniBand 統一結構管理器

圖 7 。 InfiniBand Unified Fabric Manager 的主要功能。
NVIDIA Mellanox InfiniBand Unified Fabric Manager UFM 平臺徹底改變了數據中心網絡管理。通過將增強的實時網絡遙測與 AI 支持的網絡智能和分析相結合, UFM 平臺使 IT 經理能夠發現運行異常并預測網絡故障,以進行預防性維護。
UFM 平臺包括多個級別的解決方案和功能,以滿足數據中心的需求和要求。在基礎層面, UFM 遙測平臺提供網絡驗證工具,并監控網絡性能和狀況。例如,它捕獲豐富的實時網絡遙測信息、工作負載使用數據和系統配置,然后將其流式傳輸到已定義的內部部署或基于云的數據庫以供進一步分析。
中端 UFM 企業平臺增加了增強的網絡監視、管理、工作負載優化和定期配置檢查。除了包括所有 UFM 遙測服務外,它還提供網絡設置、連接驗證和安全電纜管理功能、自動網絡發現和網絡供應、流量監控和擁塞發現。 UFM Enterprise 還支持作業調度器配置和與 Slurm 或 Platform LSF 的集成,以及與 OpenStack 、 Azure 云和 VMware 的網絡配置和集成。
增強型 UFM 網絡人工智能平臺包括所有 UFM 遙測和 UFM 企業服務。網絡人工智能平臺的獨特優勢在于,隨著時間的推移,它能夠捕獲豐富的遙測信息,并使用深度學習算法。平臺學習數據中心的“心跳”、操作模式、條件、使用情況和工作負載網絡特征。它建立了一個增強的遙測信息數據庫,并發現事件之間的相關性。它檢測性能下降、使用情況和配置文件隨時間的變化,并提供異常系統和應用程序行為以及潛在系統故障的警報。它還可以執行糾正措施。
網絡人工智能平臺可以轉換和關聯數據中心心跳的變化,以指示未來性能下降或數據中心計算資源的異常使用。這種變化和相關性觸發預測分析,并啟動警報,指示異常的系統和應用程序行為,以及潛在的系統故障。系統管理員可以快速檢測和響應此類潛在的安全威脅,并以有效的方式解決即將發生的故障,從而節省運營成本并維護最終用戶 SLA 。隨著時間的推移,通過收集額外的系統數據,可預測性得到了優化。
關于作者
CJ Newburn 是 NVIDIA 計算軟件組的首席架構師,他領導 HPC 戰略和軟件產品路線圖,特別關注系統和規模編程模型。 CJ 是 Magnum IO 的架構師和 GPU Direct Storage 的聯合架構師,與能源部領導 Summit Dev 系列產品,并領導 HPC 容器咨詢委員會。在過去的 20 年里, CJ 為硬件和軟件技術做出了貢獻,擁有 100 多項專利。他是一個社區建設者,熱衷于將硬件和軟件平臺的核心功能從 HPC 擴展到 AI 、數據科學和可視化。在卡內基梅隆大學獲得博士學位之前, CJ 曾在幾家初創公司工作過,致力于語音識別器和 VLIW 超級計算機。他很高興能為他媽媽使用的批量產品工作。
Kushal Datta 是 Magnum IO 的產品負責人,專注于加速多 GPU 系統上的 AI 、數據分析和 HPC 應用程序。他的興趣包括創建新的工具和方法,以提高復雜人工智能和大規模系統上的科學應用的總掛鐘時間。他發表了 20 多篇學術論文、多篇白皮書和博客文章。他擁有五項美國專利。他在北卡羅來納大學夏洛特分校獲得歐洲經委會博士學位,并在印度賈達夫普爾大學獲得計算機科學學士學位。
Gilad Shainer 擔任 NVIDIA Mellanox networking 的營銷高級副總裁,專注于高性能計算、人工智能和 InfiniBand 技術。吉拉德于 2001 年加入梅蘭諾克斯公司,擔任設計工程師,之后自 2005 年起擔任高級營銷管理職務。他是 HPC-AI 咨詢委員會組織的主席、 UCF 和 CCIX 聯合會的主席、 IBTA 的成員以及 PCISIG PCI-X 和 PCIe 規范的貢獻者。他在高速網絡領域擁有多項專利。他因對網絡計算技術的核心直接貢獻獲得了 2015 年 R & D100 獎,并因對統一通信 X ( UCX )技術的貢獻獲得了 2019 年 R & D100 獎。吉拉德擁有以色列理工學院電氣工程碩士學位和理學學士學位。
David Iles 是 NVIDIA 的以太網交換高級主管。 Iles 先生曾在 3COM 、 Cisco Systems 、 Nortel Networks 和 IBM 擔任領導職務,在那里他推廣先進的網絡技術,包括高速以太網、 4-7 層交換、支持虛擬機的網絡和軟件定義的網絡。作為一名終身技術專家, David 發明了新的方法來測試 4-7 層交換機的性能,并在數據中心網絡方面貢獻了多項專利。
審核編輯:郭婷
-
以太網
+關注
關注
40文章
5443瀏覽量
172104 -
NVIDIA
+關注
關注
14文章
5026瀏覽量
103298 -
人工智能
+關注
關注
1792文章
47446瀏覽量
239072
發布評論請先 登錄
相關推薦
【「RISC-V體系結構編程與實踐」閱讀體驗】-- SBI及NEMU環境
【「RISC-V體系結構編程與實踐」閱讀體驗】-- 前言與開篇

名單公布!【書籍評測活動NO.45】RISC-V體系結構編程與實踐(第二版)
嵌入式系統的體系結構包括哪些
工業控制計算機的體系結構是什么
dcs的體系結構體現在哪幾個方面
嵌入式微處理器體系結構 嵌入式微處理器原理與應用
嵌入式微處理器體系結構有幾種
WiMAX MAC層基礎知識:WiMAX網絡體系結構

智能化的計算機體系結構設計方案
《RVfpga:理解計算機體系結構》3.0 版本更新上線






 工商網監
工商網監
評論