 并行計算平臺和NVIDIA編程模型CUDA的更簡單介紹
并行計算平臺和NVIDIA編程模型CUDA的更簡單介紹
這篇文章是對 CUDA 的一個超級簡單的介紹,這是一個流行的并行計算平臺和 NVIDIA 的編程模型。我在 2013 年給 CUDA 寫了一篇前一篇 “簡單介紹” ,這幾年來非常流行。但是 CUDA 編程變得越來越簡單, GPUs 也變得更快了,所以是時候更新(甚至更容易)介紹了。
CUDA C ++只是使用 CUDA 創建大規模并行應用程序的一種方式。它讓您使用強大的 C ++編程語言來開發由數千個并行線程加速的高性能算法 GPUs 。許多開發人員已經用這種方式加速了他們對計算和帶寬需求巨大的應用程序,包括支持人工智能正在進行的革命的庫和框架 深度學習 。
所以,您已經聽說了 CUDA ,您有興趣學習如何在自己的應用程序中使用它。如果你是 C 或 C ++程序員,這個博客應該給你一個好的開始。接下來,您需要一臺具有 CUDA – 功能的 GPU 計算機( Windows 、 Mac 或 Linux ,以及任何 NVIDIA GPU 都可以),或者需要一個具有 GPUs 的云實例( AWS 、 Azure 、 IBM 軟層和其他云服務提供商都有)。您還需要安裝免費的 CUDA 工具箱 。
我們開始吧!
從簡單開始
我們將從一個簡單的 C ++程序開始,它添加兩個數組的元素,每個元素有一百萬個元素。
#include#include // function to add the elements of two arrays void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; // 1M elements float *x = new float[N]; float *y = new float[N]; // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the CPU add(N, x, y); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory delete [] x; delete [] y; return 0; }
首先,編譯并運行這個 C ++程序。將代碼放在一個文件中,并將其保存為add.cpp,然后用 C ++編譯器編譯它。我在 Mac 電腦上,所以我用的是clang++,但你可以在 Linux 上使用g++,或者在 Windows 上使用 MSVC 。
> clang++ add.cpp -o add
然后運行它:
> ./add Max error: 0.000000
(在 Windows 上,您可能需要命名可執行文件添加. exe 并使用.dd運行它。)
正如預期的那樣,它打印出求和中沒有錯誤,然后退出。現在我想讓這個計算在 GPU 的多個核心上運行(并行)。其實邁出第一步很容易。
首先,我只需要將我們的add函數轉換成 GPU 可以運行的函數,在 CUDA 中稱為內核。要做到這一點,我所要做的就是把說明符__global__添加到函數中,它告訴 CUDA C ++編譯器,這是一個在 GPU 上運行的函數,可以從 CPU 代碼調用。
// CUDA Kernel function to add the elements of two arrays on the GPU __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; }
這些__global__函數被稱為果仁,在 GPU 上運行的代碼通常稱為設備代碼,而在 CPU 上運行的代碼是主機代碼。
CUDA 中的內存分配
為了在 GPU 上計算,我需要分配 GPU 可訪問的內存, CUDA 中的統一存儲器通過提供一個系統中所有 GPUs 和 CPU 都可以訪問的內存空間,這使得這一點變得簡單。要在統一內存中分配數據,請調用cudaMallocManaged(),它返回一個指針,您可以從主機( CPU )代碼或設備( GPU )代碼訪問該指針。要釋放數據,只需將指針傳遞到cudaFree()。
我只需要將上面代碼中對new的調用替換為對cudaMallocManaged()的調用,并將對delete []的調用替換為對cudaFree.的調用
// Allocate Unified Memory -- accessible from CPU or GPU float *x, *y; cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); ... // Free memory cudaFree(x); cudaFree(y);
最后,我需要發射內核,它在add()上調用它。 CUDA 內核啟動是使用三角括號語法指定的。我只需要在參數列表之前將它添加到對 CUDA 的調用中。
add<<<1, 1>>>(N, x, y);
容易的!我很快將詳細介紹尖括號內的內容;現在您只需要知道這行代碼啟動了一個 GPU 線程來運行add()。
還有一件事:我需要 CPU 等到內核完成后再訪問結果(因為 CUDA 內核啟動不會阻塞調用的 CPU 線程)。為此,我只需在對 CPU 進行最后的錯誤檢查之前調用cudaDeviceSynchronize()。
以下是完整的代碼:
#include#include // Kernel function to add the elements of two arrays __global__ void add(int n, float *x, float *y) { for (int i = 0; i < n; i++) y[i] = x[i] + y[i]; } int main(void) { int N = 1<<20; float *x, *y; // Allocate Unified Memory – accessible from CPU or GPU cudaMallocManaged(&x, N*sizeof(float)); cudaMallocManaged(&y, N*sizeof(float)); // initialize x and y arrays on the host for (int i = 0; i < N; i++) { x[i] = 1.0f; y[i] = 2.0f; } // Run kernel on 1M elements on the GPU add<<<1, 1>>>(N, x, y); // Wait for GPU to finish before accessing on host cudaDeviceSynchronize(); // Check for errors (all values should be 3.0f) float maxError = 0.0f; for (int i = 0; i < N; i++) maxError = fmax(maxError, fabs(y[i]-3.0f)); std::cout << "Max error: " << maxError << std::endl; // Free memory cudaFree(x); cudaFree(y); return 0; }
CUDA 文件具有文件擴展名;.cu。所以把代碼保存在一個名為
> nvcc add.cu -o add_cuda > ./add_cuda Max error: 0.000000
這只是第一步,因為正如所寫的,這個內核只適用于一個線程,因為運行它的每個線程都將在整個數組上執行 add 。此外,還有一個競爭條件,因為多個并行線程讀寫相同的位置。
注意:在 Windows 上,您需要確保在 Microsoft Visual Studio 中項目的配置屬性中將“平臺”設置為 x64 。
介紹一下!
我認為找出運行內核需要多長時間的最簡單的方法是用nvprof運行它,這是一個帶有 CUDA 工具箱的命令行 GPU 分析器。只需在命令行中鍵入nvprof ./add_cuda:
$ nvprof ./add_cuda ==3355== NVPROF is profiling process 3355, command: ./add_cuda Max error: 0 ==3355== Profiling application: ./add_cuda ==3355== Profiling result: Time(%) Time Calls Avg Min Max Name 100.00% 463.25ms 1 463.25ms 463.25ms 463.25ms add(int, float*, float*) ...
上面是來自nvprof的截斷輸出,顯示了對add的單個調用。在 NVIDIA Tesla K80 加速器上需要大約半秒鐘的時間,而在我 3 歲的 Macbook Pro 上使用 NVIDIA GeForce GT 740M 大約需要半秒鐘的時間。
讓我們用并行來加快速度。
把線撿起來
既然你已經用一個線程運行了一個內核,那么如何使它并行?鍵是在 CUDA 的<<<1, 1>>>語法中。這稱為執行配置,它告訴 CUDA 運行時要使用多少并行線程來啟動 GPU 。這里有兩個參數,但是讓我們從更改第二個參數開始:線程塊中的線程數。 CUDA GPUs 運行內核時使用的線程塊大小是 32 的倍數,因此 256 個線程是一個合理的選擇。
add<<<1, 256>>>(N, x, y);
如果我只在這個修改下運行代碼,它將為每個線程執行一次計算,而不是將計算分散到并行線程上。為了正確地執行它,我需要修改內核。 CUDA C ++提供了關鍵字,這些內核可以讓內核獲得運行線程的索引。具體來說,threadIdx.x包含其塊中當前線程的索引,blockDim.x包含塊中的線程數。我只需修改循環以使用并行線程跨過數組。
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
add函數沒有太大變化。事實上,將index設置為 0 ,stride設置為 1 會使其在語義上與第一個版本相同。
將文件另存為add_block.cu,然后再次在nvprof中編譯并運行。在后面的文章中,我將只顯示輸出中的相關行。
Time(%) Time Calls Avg Min Max Name 100.00% 2.7107ms 1 2.7107ms 2.7107ms 2.7107ms add(int, float*, float*)
這是一個很大的加速( 463 毫秒下降到 2 . 7 毫秒),但并不奇怪,因為我從 1 線程到 256 線程。 K80 比我的小 MacBookProGPU 快( 3 . 2 毫秒)。讓我們繼續取得更高的表現。
走出街區
CUDA GPUs 有許多并行處理器組合成流式多處理器或 SMs 。每個 SM 可以運行多個并發線程塊。例如,基于 Tesla 的 Tesla P100帕斯卡 GPU 體系結構有 56 個短消息,每個短消息能夠支持多達 2048 個活動線程。為了充分利用所有這些線程,我應該用多個線程塊啟動內核。
現在您可能已經猜到執行配置的第一個參數指定了線程塊的數量。這些平行線程塊一起構成了所謂的網格。因為我有N元素要處理,每個塊有 256 個線程,所以我只需要計算塊的數量就可以得到至少 N 個線程。我只需將N除以塊大小(注意在N不是blockSize的倍數的情況下向上取整)。
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, x, y);
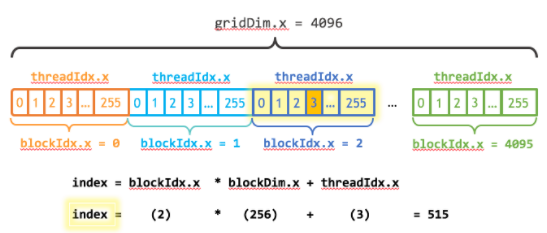
我還需要更新內核代碼來考慮線程塊的整個網格。threadIdx.x提供了包含網格中塊數的gridDim.x和包含網格中當前線程塊索引的blockIdx.x。圖 1 說明了使用 CUDA 、gridDim.x和threadIdx.x在 CUDA 中索引數組(一維)的方法。其思想是,每個線程通過計算到其塊開頭的偏移量(塊索引乘以塊大小:blockIdx.x * blockDim.x),并將線程的索引添加到塊內(threadIdx.x)。代碼blockIdx.x * blockDim.x + threadIdx.x是慣用的 CUDA 。
__global__ void add(int n, float *x, float *y) { int index = blockIdx.x * blockDim.x + threadIdx.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
更新的內核還將stride設置為網格中的線程總數(blockDim.x * gridDim.x)。 CUDA 內核中的這種類型的循環通常稱為柵格步幅循環。
將文件另存為&[EZX63 ;&[編譯并在&[EZX37 ;&]中運行它]
Time(%) Time Calls Avg Min Max Name 100.00% 94.015us 1 94.015us 94.015us 94.015us add(int, float*, float*)
這是另一個 28 倍的加速,從運行多個街區的所有短信 K80 !我們在 K80 上只使用了 2 個 GPUs 中的一個,但是每個 GPU 都有 13 條短信。注意,我筆記本電腦中的 GeForce 有 2 條(較弱的)短信,運行內核需要 680us 。
總結
下面是三個版本的add()內核在 Tesla K80 和 GeForce GT 750M 上的性能分析。
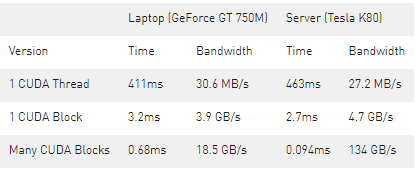
如您所見,我們可以在 GPUs 上實現非常高的帶寬。這篇文章中的計算是非常有帶寬限制的,但是 GPUs 也擅長于密集矩陣線性代數深度學習、圖像和信號處理、物理模擬等大量計算限制的計算。
關于作者
Mark Harris 是 NVIDIA 杰出的工程師,致力于 RAPIDS 。 Mark 擁有超過 20 年的 GPUs 軟件開發經驗,從圖形和游戲到基于物理的模擬,到并行算法和高性能計算。當他還是北卡羅來納大學的博士生時,他意識到了一種新生的趨勢,并為此創造了一個名字: GPGPU (圖形處理單元上的通用計算)。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4989瀏覽量
103093 -
gpu
+關注
關注
28文章
4741瀏覽量
128963 -
計算機
+關注
關注
19文章
7496瀏覽量
88002
發布評論請先 登錄
相關推薦
《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA與谷歌量子AI部門達成合作
NVIDIA向開放計算項目捐贈Blackwell平臺設計
NVIDIA 助力谷歌量子 AI 通過量子器件物理學模擬加快處理器設計

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
GPU加速計算平臺是什么
【「大模型時代的基礎架構」閱讀體驗】+ 第一、二章學習感受
簡單認識NVIDIA網絡平臺
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
NVIDIA提供一套服務、模型以及計算平臺 加速人形機器人發展
畢昇大模型應用開發平臺+浪潮信息AIStation,讓大模型定制更簡單

英偉達CUDA-Q平臺推動全球量子計算研究
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

基于NVIDIA開源CUDA-Q量子計算平臺發布
NVIDIA 推出云量子計算機模擬微服務






 工商網監
工商網監
評論