 基于GPT-2進行文本生成
基于GPT-2進行文本生成
來自:ChallengeHub
作者:致Great
fromutilsimport* setup_chapter()
Using transformers v4.11.3
Using datasets v1.13.0
Using accelerate v0.5.1
文本生成
文本生成是自然語言處理中一個重要的研究領域,具有廣闊的應用前景。國內外已經有諸如Automated Insights、Narrative Science以及“小南”機器人和“小明”機器人等文本生成系統投入使用。這些系統根據格式化數據或自然語言文本生成新聞、財報或者其他解釋性文本。例如,Automated Insights的WordSmith技術已經被美聯社等機構使用,幫助美聯社報道大學橄欖球賽事、公司財報等新聞。這使得美聯社不僅新聞更新速度更快,而且在人力資源不變的情況下擴大了其在公司財報方面報道的覆蓋面。
任務定義
接受非語言形式的信息作為輸入,生成可讀的文字表述。數據到文本的生成適用于這個定義,后續研究人員將這個概念拓展為包括了文本到文本的生成、數據到文本的生成以及圖像到文本的生成的文本生成技術。
任務分類
按照輸入數據的區別,可以將文本生成任務大致分為以下三類:
-
1)文本到文本的生成;
-
2)數據到文本的生成;
-
3)圖像到文本的生成。
1)文本到文本的生成又可根據不同的任務分為(包括但不限于):文本摘要、 古詩生成、文本復述等。文本摘要又可以分為抽取式摘要和生成式摘要。抽取式摘要通常包含信息抽取和規劃等主要步驟。近期,在這方面有許多有趣的工作:
-
在為論文自動生成相關工作部分文本的任務上使用主題模型PLSA將句子按照主題進行聚類,使用SVR(Support Vector Regression)計算句子的相似度,最后使用線性規劃生成相關工作文本。
-
在基于短語級別為學術論文生成演示文件的研究中采用了四個步驟。首先從論文中抽取名詞短語、動詞短語作為候選短語, 利用人工設計的特征和基于隨機森林的分類器決定短語是否應出現在演示文件中,再訓練一個基于隨機森林的分類器判斷兩個短語是否存在一級、二級標題的關系,最后使用貪心策略選擇句子構成一個演示文件。Zhang[5]在根據體育賽事直播文字生成賽事報道的任務上,主要采用了Learning to Rank的方法結合人工設計的特征模版對句子進行打分,進而采用行列式點過程(DPP, Determinantal Point Process)進行句子選擇。
-
最近ACL 2017上發表了多篇生成式摘要的論文。
-
如See等人提出了解決生成事實性錯誤文本和重復性文本問題的方法[6],Zhou等人加入選擇門網絡(selective gate network)進行摘要生成[7]。
-
古詩生成方面,Zhang等人[8]使用循環神經網絡進行生成,Wang等人[9]將古詩生成劃分為規劃模型和生成模型兩部份。
-
Zhang等人[10]在Seq2Seq模型的基礎上加入記憶模塊。文本復述方面,Quirk等人[11]使用機器翻譯的方法生成復述文本,Max等人
-
[12]采用基于樞軸(pivot)的復述生成方法,以另一種語言作為中間媒介,將源語言翻譯成另一種語言后再翻譯為原來的語言。
2)結構化數據生成文本的任務上,Reiter等人[13]將數據到文本的系統分為了信號處理(視輸入數據類型可選)、數據分析、文檔規劃和文本實現四個步驟。Mei等人[14]基于encoder-decoder模型加入了aligner選擇重要信息,基于深度學習提出了一個端到端的根據數據生成文本的模型。比如 語義解析 (Text-to-SQL)
3)圖像到文本的生成方面也有不同的任務,如image-caption、故事生成、基于圖像的問答等。在為圖像生成解釋性文本(image-caption)的任務上,Vinyals等人[15]使用類似encoder-decoder的模型進行生成。Xu等人[16]則進一步加入Attention機制。Huang等人[17]提出針對圖片序列生成故事的任務,并且提供了單張圖片的描述性文本、單張圖片的故事以及圖片序列的故事三個層級的數據集。在第三個數據集上,他們拓展之前的模型并加入一些技巧提供了該任務的一些baseline。并通過對自動化評價指標以及人工評價相關度的衡量,確定使用METEOR作為自動化評價指標。基于圖像的問答任務上,Shih等人[18]提出了使用基于Attention機制的模型用VGGnet編碼圖片,用詞向量求均值表示問題,最后經過兩層網絡生成答案 、Wu等人[19]提出了整合image-caption模型和外部知識庫等生成答案。
文本生成方法
1 基于語言模型的自然語言生成
基于馬爾可夫的語言模型在數據驅動的自然語言生成中有著重要的應用。它利用數據和文字間的對齊語料,主要采用兩個步驟:內容規劃和內容實現為數據生成對應的文本。Oh等人[21]在搭建面向旅行領域的對話系統時,在內容規劃部分使用bigram作特征根據近期的對話歷史,選取待生成文本中需要出現的屬性,內容實現部分使用n-gram語言模型生成對話。Ratnaparkhi等人[22]經過實驗對比發現在語言模型上加入依存語法關系有助于改善生成效果。Angeli等人[23]則將文本生成的過程分為三種決策(以生成天氣報道為例):1)宏觀的內容選擇,如選擇溫度等方面進行報道。2)微觀內容選擇,如選擇最低溫度或者最高溫度進行報道。3)模版選擇。這三個決策步驟交替進行。每次決策的時候會考慮到歷史決策信息,這有助于處理需要考慮長距離的依賴關系的情況,如語義連貫性。
2 使用深度學習方法的自然語言生成
-
在文本到文本的生成方面,Zhang等人[8]使用RNN進行中文古詩生成,用戶輸入關鍵詞后首先拓展為短語,并用來生成詩的第一行。接下來的每一行結合當時所有已生成的詩句進行生成。Wang[9]則將古詩生成分為規劃模型和生成模型兩部份。規劃模型部分得到用戶的輸入,在使用TextRank進行關鍵詞抽取和使用RNN語言模型和基于知識庫的方法進行拓展后,獲得一個主題詞序列,作為寫作大綱,每一個主題詞在下一個部分生成一行詩。生成模型部分基于encoder-decoder模型,增加一個encoder為主題詞獲得一個向量表示。
-
另一 個encoder編碼已經生成的句子。使用attention-based的模型,decoder綜合主題詞和已經生成的句子,生成下一句的內容。通過這兩個模型,在更好的控制每一行詩的主題的同時保持詩詞的流暢性。最近,在ACL 2017上發表了多篇生成式摘要的論文。如See等人[6]為了解決生成一些與事實不符的內容,在標準的基于attention的Seq2Seq模型上結合Pointer Network,使其既可以生成詞,也可以從原文中直接把一些詞放入生成的文本中。為了解決重復的問題,加入coverage模型。Zhou等人[7]則通過在encoder和decoder之間加入一個選擇門網絡(selective gate network)作為輸入句子的第二層表示,提高編碼的有效性,降低decoder的負擔。
-
在數據到文本的生成方面,Mei[14]提出了encoder-aligner-decoder的端到端模型。主要特點是在標準的encoder和進行了改進的decoder之間加入用于選擇將要描述的重要信息的aligner。它對每條記錄生成的權重分為兩個部分。第一部分是針對每條記錄的向量表示單獨計算一個權重。第二部分是在decoder的第t步時,根據decoder已經生成的內容及對應記錄的向量表示計算權重。在兩個數據集上取得比較好的效果提升。它的優勢在于同步訓練內容選擇和生成部分且不需要針對任務人工設置特征,普適性較好。
-
在圖像到文本的生成方面,Vinyals[15]使用Seq2Seq的模型,首先利用深層卷積神經網絡DCNN 對圖像建模,然后由一個LSTM網絡進行解碼生成最終的文本。與傳統的機器學習方法相比,無需進行圖像和文本中詞的對齊、調整順序等步驟。Xu[16]則進一步提出利用Attention機制來加強詞語和圖像塊之間的對齊,在生成文字的時候,模擬人看東西時關注點逐漸轉移的過程,以生成更符合人習慣的文本。
seq2seq結構:nmt_with_attention
【深度學習和自然語言處理】Seq2seq 中文文本生成
模型評價
No evaluation, no research。如何對生成的文本進行評價也是文本生成研究中重要的一環。Gkatzia[24]總結2005年到2014年間的常用的針對文本生成的評價方法,將其分為內在評價和外在評價方法。其中內在評價關注文本的正確性、流暢度和易理解性。常見的內在評價方法又可分為兩類:
- 1)采用BLEU、NIST和ROUGE等進行自動化評價,評估生成文本和參考文本間相似度來衡量生成質量。
- 2)通過人工評價,從有用性等對文本進行打分。外在評價則關注生成文本在實際應用中的可用性。
根據他們的分析,內在評價方法是最為流行的評價方法。2012-2015年間發表的論文超半數使用自動化評價指標進行評價,但由于它需要有大量的對齊語料,且對于對齊語料的質量很敏感,所以在使用自動化評價指標的同時,研究者常常還會同時使用其它的評價方法,如直觀且易于操作(與外在評價方法相比)的人工評價生成文本的正確性、流暢性方法。
基于Seq2Seq的文本生成評價指標解析
基于GPT-2進行文本生成
基于Transformers的語言模型最不可思議的特點之一是它們能夠生成與人類所寫的文本幾乎沒有區別的文本。一個著名的例子是OpenAI的GPT-2,它在給出以下提示時:
Inashockingfinding,scientistdiscoveredaherdofunicornslivinginaremote,previouslyunexploredvalley,intheAndesMountains.EvenmoresurprisingtotheresearcherswasthefactthattheunicornsspokeperfectEnglish.
能夠生成一篇關于獨角獸的新聞:
Thescientistnamedthepopulation,aftertheirdistinctivehorn,Ovid’sUnicorn.Thesefour-horned,silver-whiteunicornswerepreviouslyunknowntoscience.Now,afteralmosttwocenturies,themysteryofwhatsparkedthisoddphenomenonisfinallysolved.Dr.JorgePérez,anevolutionarybiologistfromtheUniversityofLaPaz,andseveralcompanions,wereexploringtheAndesMountainswhentheyfoundasmallvalley,withnootheranimalsorhumans.Péreznoticedthatthevalleyhadwhatappearedtobeanaturalfountain,surroundedbytwopeaksofrockandsilversnow.Pérezandtheothersthenventuredfurtherintothevalley.“Bythetimewereachedthetopofonepeak,thewaterlookedblue,withsomecrystalsontop,”saidPérez.Pérezandhisfriendswereastonishedtoseetheunicornherd.Thesecreaturescouldbeseenfromtheairwithouthavingtomovetoomuchtoseethem—theyweresoclosetheycouldtouchtheirhorns.WhileexaminingthesebizarrecreaturesthescientistsdiscoveredthatthecreaturesalsospokesomefairlyregularEnglish...
這個例子之前是非常有名的,是因為它是在沒有任何明確監督的情況下產生的! 通過簡單地學習預測數以百萬計的網頁文本中的下一個詞,GPT-2和它更強大的改進版,如GPT-3,能夠獲得文本學習和模式識別能力,以及能被不同類型的輸入提示獲得比較不錯效果。語言模型在預訓練期間有時會接觸到一些任務序列,在這些任務中,它們需要僅僅根據上下文來預測下面的標記,如加法、解詞和翻譯。這使得它們在微調期間或(如果模型足夠大)在推理時間有效地轉移這些知識。這些任務不是提前選擇的,而是在用于訓練十億參數語言模型的巨大語料庫中自然出現的。
Transformers生成現實文本的能力導致了多樣化的應用,如InferKit、Write With Transformer、AI Dungeon,以及像谷歌的Meena這樣的對話代理,它甚至可以講出老套的笑話,如圖5-2所示!
在之前教程里,我們一直專注于通過預訓練和監督微調的組合來處理NLP任務。正如我們所看到的,對于像序列或標記分類這樣的特定任務,產生預測是相當直接的,比如預測一個文本的情感類別;模型產生一些分數(可以理解為logits),然后我們取最大值來獲得預測的類別,或者應用softmax函數來獲得每個類別的預測概率。相比之下,將模型的概率輸出轉換為文本需要一種解碼方法,這就引入了一些文本生成所特有的挑戰:
- 解碼是反復進行的,因此比簡單地將輸入通過模型的前向傳遞一次涉及到更多的計算。
- 生成文本的質量和多樣性取決于解碼方法和相關超參數的選擇。
為了理解這個解碼過程是如何進行的,讓我們先來看看GPT-2是如何進行預訓練并隨后應用于生成文本的。
像其他自回歸或因果語言模型一樣,給定一些初始提示或語境序列x = x1, x2, ... xk,GPT-2被預訓練來估計文本中出現的文本序列y = y1, y2, ... yt的概率P(y|x)。由于訓練數據比較大,來直接估計P(y|x)是不切實際的,所以通常使用概率鏈規則來將其分解為條件概率的乘積。
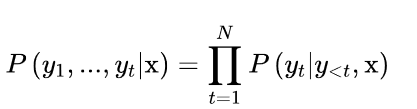
其中y是序列y1,>
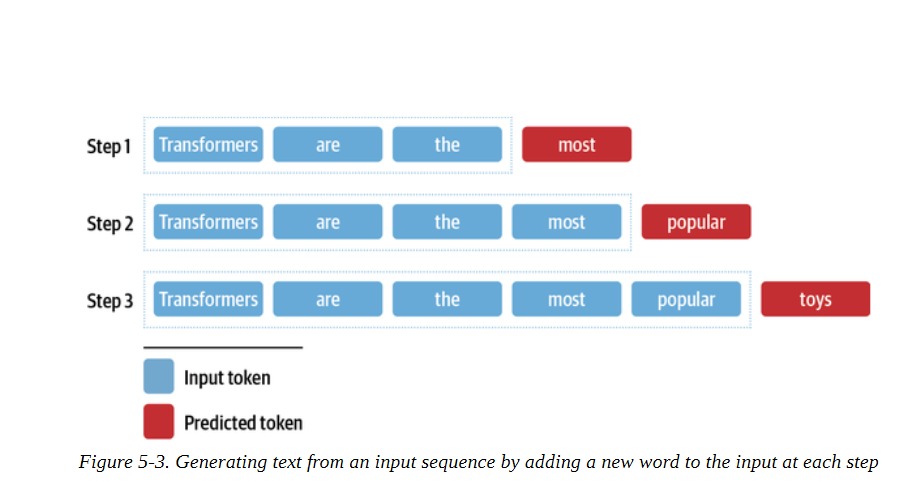
現在你可能已經猜到我們如何調整這個下一個標記的預測任務,以生成任意長度的文本序列。如圖5-3所示,我們從 "transformers "這樣的流程開始,用模型來預測下一個標記。一旦我們確定了下一個標記,我們就把它附加到提示上,然后用新的輸入序列來生成另一個標記。重復這個過程,直到我們達到一個特殊的序列結束符號或預先定義的最大長度。
文本生成挑戰
解碼方式1:貪婪搜索(Greedy Search)
從模型的連續輸出中獲得離散標記的最簡單的解碼方法是貪婪地選擇每個時間點上概率最大的標記:
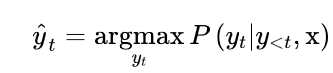
為了了解貪婪搜索是如何工作的,讓我們先用語言建模頭加載15億參數版本的GPT-2:
#導入包
importtorch
fromtransformersimportAutoTokenizer,AutoModelForCausalLM
device="cuda"iftorch.cuda.is_available()else"cpu"
model_name="gpt2-xl"
tokenizer=AutoTokenizer.from_pretrained(model_name)
model=AutoModelForCausalLM.from_pretrained(model_name).to(device)
Downloading: 0%| | 0.00/689 [00:00
現在讓我們來生成一些文本! 盡管Transformers為GPT-2這樣的自回歸模型提供了一個generate()函數,加載預訓練模型就可以直接進行解碼
但我們將自己實現這個解碼方法,看看內部具體流程是什么操作。為了方便理解,我們采取圖5-3所示的相同的迭代方法:我們將使用 "transformers "作為輸入提示,并進行8步的解碼。在每個時間步驟中,我們為提示中的最后一個字符計算出模型的對數,并用softmax計算一下,得到一個概率分布。然后,我們挑選出概率最高的下一個符號,將其添加到輸入序列中,并再次運行該過程。
下面的代碼完成了這項工作,并且還在每個時間段存儲了五個最有可能的標記,這樣我們就可以直觀地看到備選方案:
importpandasaspd
input_txt="Transformersarethe"
input_ids=tokenizer(input_txt,return_tensors="pt")["input_ids"].to(device)
iterations=[]
n_steps=8#進行8步解碼
choices_per_step=5#每一步候選數量
withtorch.no_grad():#eval模式
for_inrange(n_steps):#每步解碼
iteration=dict()
iteration["Input"]=tokenizer.decode(input_ids[0])#提示文本
output=model(input_ids=input_ids)#將提示文本輸入到模型進行解碼
#Selectlogitsofthefirstbatchandthelasttokenandapplysoftmax
next_token_logits=output.logits[0,-1,:]
next_token_probs=torch.softmax(next_token_logits,dim=-1)
sorted_ids=torch.argsort(next_token_probs,dim=-1,descending=True)
#Storetokenswithhighestprobabilities
forchoice_idxinrange(choices_per_step):#概率最大的五個token
token_id=sorted_ids[choice_idx]
token_prob=next_token_probs[token_id].cpu().numpy()
token_choice=(
f"{tokenizer.decode(token_id)}({100*token_prob:.2f}%)"#取百分號兩位數
)
iteration[f"Choice{choice_idx+1}"]=token_choice
#Appendpredictednexttokentoinput
input_ids=torch.cat([input_ids,sorted_ids[None,0,None]],dim=-1)#將概率最大的字符拼接到提示文本
iterations.append(iteration)
pd.DataFrame(iterations)
|
Input |
Choice 1 |
Choice 2 |
Choice 3 |
Choice 4 |
Choice 5 |
|---|---|---|---|---|---|---|
0 |
Transformers are the |
most (8.54%) |
only (4.96%) |
best (4.65%) |
Transformers (4.37%) |
ultimate (2.16%) |
1 |
Transformers are the most |
popular (16.77%) |
powerful (5.37%) |
common (4.96%) |
famous (3.72%) |
successful (3.19%) |
2 |
Transformers are the most popular |
toy (10.62%) |
toys (7.23%) |
Transformers (6.60%) |
of (5.46%) |
and (3.76%) |
3 |
Transformers are the most popular toy |
line (34.37%) |
in (18.21%) |
of (11.71%) |
brand (6.09%) |
line (2.69%) |
4 |
Transformers are the most popular toy line |
in (46.26%) |
of (15.09%) |
, (4.94%) |
on (4.39%) |
ever (2.72%) |
5 |
Transformers are the most popular toy line in |
the (66.00%) |
history (12.40%) |
America (6.91%) |
Japan (2.44%) |
North (1.40%) |
6 |
Transformers are the most popular toy line in the |
world (69.24%) |
United (4.55%) |
history (4.29%) |
US (4.23%) |
U (2.30%) |
7 |
Transformers are the most popular toy line in ... |
, (39.73%) |
. (30.64%) |
and (9.88%) |
with (2.32%) |
today (1.74%) |
實現貪婪搜索并不難,但我們要使用Transformers內置的generate()函數來探索更復雜的解碼方法。為了重現我們的簡單例子,讓我們 確保采樣被關閉(默認情況下是關閉的,除非你加載檢查點的模型的具體配置另有規定),并為新生成的標記數量指定max_new_tokens:
input_ids=tokenizer(input_txt,return_tensors="pt")["input_ids"].to(device)
output=model.generate(input_ids,max_new_tokens=n_steps,do_sample=False)
print(tokenizer.decode(output[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Transformers are the most popular toy line in the world,
現在讓我們嘗試一些更有趣的東西:我們能重現OpenAI的獨角獸故事嗎?正如我們之前所做的,我們將用標記器對提示進行編碼,并且我們將為max_length指定一個較大的值,以生成一個較長的文本序列:
max_length=128
input_txt="""Inashockingfinding,scientistdiscovered
aherdofunicornslivinginaremote,previouslyunexplored
valley,intheAndesMountains.Evenmoresurprisingtothe
researcherswasthefactthattheunicornsspokeperfectEnglish.
"""
input_ids=tokenizer(input_txt,return_tensors="pt")["input_ids"].to(device)
output_greedy=model.generate(input_ids,max_length=max_length,
do_sample=False)
print(tokenizer.decode(output_greedy[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The researchers, from the University of California, Davis, and the University of Colorado, Boulder, were conducting a study on the Andean cloud forest, which is home to the rare species of cloud forest trees.
The researchers were surprised to find that the unicorns were able to communicate with each other, and even with humans.
The researchers were surprised to find that the unicorns were able
我們還可以看到貪婪搜索解碼的一個主要缺點:它傾向于產生重復的輸出序列,這在新聞文章場景中當然是不合適的,新聞講究言簡意賅。這是貪婪搜索算法的一個常見問題,它可能無法給你提供最佳解決方案;在解碼的背景下,它們可能會錯過整體概率較高的單詞序列,只是因為高概率的單詞剛好在低概率的單詞之前。
幸運的是,我們可以做得更好--讓我們研究一種被稱為集束搜索(eam search decoding)的解碼方法。
解碼方式2:集束搜索(beam search decoding)
集束搜索不是在每一步解碼概率最高的標記,而是記錄前b個最有可能的下一個標記,其中b被稱為波束或路徑個數。下一組集束的選擇是考慮現有集束的所有可能的下一個標記的擴展,并選擇b個最可能的擴展。這個過程重復進行,直到我們達到最大長度或EOS標記,然后根據對數概率對b個波束進行排序,選擇最可能的序列。圖5-4中顯示了一個束搜索的例子。
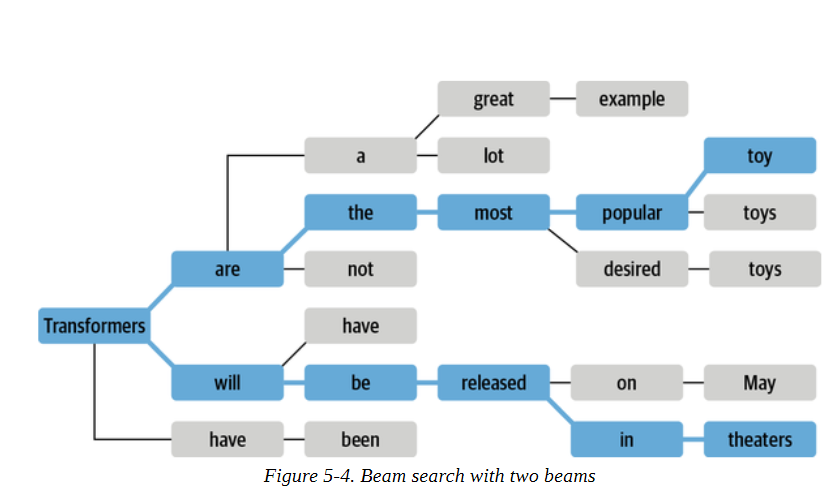
為什么我們要用對數概率而不是概率本身對序列進行評分?計算一個序列的總體概率P(y1,y2,...,yt|x)涉及計算條件概率P(yt|y,x)的乘積是一個原因。由于每個條件概率通常是[0,1]范圍內的一個小數字,取它們的乘積會導致總的概率很容易出現下溢。這意味著計算機不能再精確地表示計算的結果。例如,假設我們有一個由t>
0.5**1024
5.562684646268003e-309
導致數值不穩定,因為我們遇到了下溢。我們可以通過計算一個相關項,即對數概率來避免這種情況。如果我們將對數應用于聯合概率和條件概率,那么在對數的乘積規則的幫助下,我們可以得到:
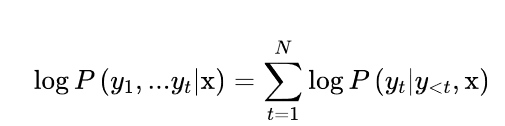
importnumpyasnp
sum([np.log(0.5)]*1024)
-709.7827128933695
這是一個我們可以輕松處理的數字,而且這種方法對更小的數字仍然有效。由于我們只想比較相對概率,我們可以直接用對數概率來做。
讓我們計算并比較貪婪和束搜索產生的文本的對數概率,看看束搜索是否能提高整體概率。由于變形金剛模型返回的是給定輸入標記的下一個標記的未歸一化對數,我們首先需要將對數歸一化,以便為序列中的每個標記創建整個詞匯的概率分布。然后,我們需要只選擇序列中存在的標記概率。下面的函數實現了這些步驟。
importtorch.nn.functionalasF
deflog_probs_from_logits(logits,labels):
logp=F.log_softmax(logits,dim=-1)
logp_label=torch.gather(logp,2,labels.unsqueeze(2)).squeeze(-1)
returnlogp_label
這給我們提供了單個標記的對數概率,所以要得到一個序列的總對數概率,我們只需要將每個標記的對數概率相加:
defsequence_logprob(model,labels,input_len=0):
withtorch.no_grad():
output=model(labels)
log_probs=log_probs_from_logits(
output.logits[:,:-1,:],labels[:,1:])
seq_log_prob=torch.sum(log_probs[:,input_len:])
returnseq_log_prob.cpu().numpy()
注意,我們忽略了輸入序列的對數概率,因為它們不是由模型生成的。我們還可以看到,將對數和標簽對齊是很重要的;因為模型預測了下一個標記,所以我們沒有得到第一個標簽的對數,我們也不需要最后一個對數,因為我們沒有它的地面真相標記。
讓我們用這些函數來首先計算OpenAI提示上的貪婪解碼器的序列對數概率。
logp=sequence_logprob(model,output_greedy,input_len=len(input_ids[0]))
print(tokenizer.decode(output_greedy[0]))
print(f"
log-prob:{logp:.2f}")
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The researchers, from the University of California, Davis, and the University of Colorado, Boulder, were conducting a study on the Andean cloud forest, which is home to the rare species of cloud forest trees.
The researchers were surprised to find that the unicorns were able to communicate with each other, and even with humans.
The researchers were surprised to find that the unicorns were able
log-prob: -87.43
現在讓我們把它與用束搜索生成的序列進行比較。要用generate()函數激活束搜索,我們只需要用num_beams參數指定波束的數量。我們選擇的波束越多,可能得到的結果就越好;然而,生成過程會變得更慢,因為我們為每個波束生成平行序列:
output_beam=model.generate(input_ids,max_length=max_length,num_beams=5,
do_sample=False)
logp=sequence_logprob(model,output_beam,input_len=len(input_ids[0]))
print(tokenizer.decode(output_beam[0]))
print(f"
log-prob:{logp:.2f}")
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The discovery of the unicorns was made by a team of scientists from the University of California, Santa Cruz, and the National Geographic Society.
The scientists were conducting a study of the Andes Mountains when they discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English
log-prob: -55.22
我們可以看到,我們用束搜索得到的對數概率(越高越好)比用簡單的貪婪解碼得到的要好。然而,我們可以看到,束搜索也受到重復文本的影響。解決這個問題的一個方法是用no_repeat_ngram_size參數施加一個n-gram懲罰,跟蹤哪些n-gram已經被看到,并將下一個token的概率設置為零,如果它將產生一個以前看到的n-gram:
output_beam = model.generate(input_ids, max_length=max_length, num_beams=5,do_sample=False, no_repeat_ngram_size=2)logp = sequence_logprob(model, output_beam, input_len=len(input_ids[0]))print(tokenizer.decode(output_beam[0]))print(f" log-prob: {logp:.2f}")
這還不算太糟!我們已經設法停止了重復,而且我們可以看到,盡管產生了較低的分數,但文本仍然是連貫的。帶n-gram懲罰的束搜索是一種很好的方法,可以在關注高概率的標記(用束搜索)和減少重復(用n-gram懲罰)之間找到一個平衡點,它通常用于總結或機器翻譯等事實正確性很重要的應用中。當事實的正確性不如生成的輸出的多樣性重要時,例如在開放領域的閑聊或故事生成中,另一種減少重復同時提高多樣性的方法是使用抽樣。讓我們通過研究幾種最常見的抽樣方法來完成我們對文本生成的探索。
解碼方式3:溫度采樣方法(Temperature Sampling Methods)
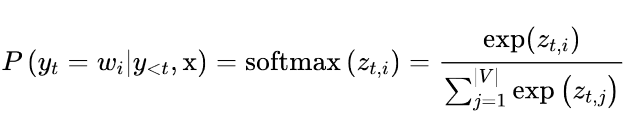
其中|V|表示詞匯的cardinality。我們可以通過添加一個溫度參數T來輕松控制輸出的多樣性,該參數在采取softmax之前重新調整對數:
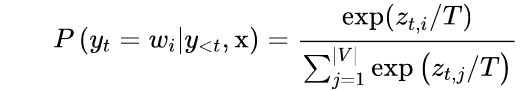
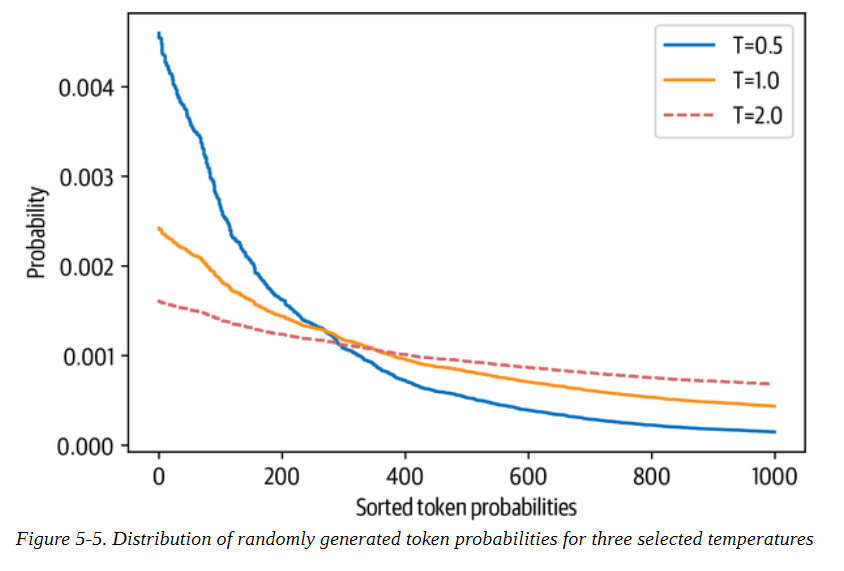
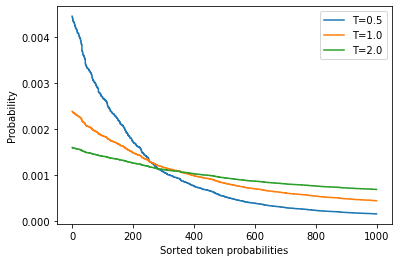
通過調整T,我們可以控制概率分布的形狀。當T?1時,分布在原點周圍變得尖銳,罕見的標記被壓制。另一方面,當T?1時,分布變得平緩,每個令牌的可能性相同。溫度對標記概率的影響見圖5-5。
當temperature→0,就變成greedy search;當temperature→∞,就變成均勻采樣(uniform sampling)。詳見論文:The Curious Case of Neural Text Degeneration
為了看看我們如何利用溫度來影響生成的文本,讓我們通過在generate()函數中設置溫度參數,以T=2為例進行采樣(我們將在下一節解釋top_k參數的含義):
#hide_input
#idtemperature
#altTokenprobabilitiesasafunctionoftemperature
#captionDistributionofrandomlygeneratedtokenprobabilitiesforthreeselectedtemperatures
importmatplotlib.pyplotasplt
importnumpyasnp
defsoftmax(logits,T=1):
e_x=np.exp(logits/T)
returne_x/e_x.sum()
logits=np.exp(np.random.random(1000))
sorted_logits=np.sort(logits)[::-1]
x=np.arange(1000)
forTin[0.5,1.0,2.0]:
plt.step(x,softmax(sorted_logits,T),label=f"T={T}")
plt.legend(loc="best")
plt.xlabel("Sortedtokenprobabilities")
plt.ylabel("Probability")
plt.show()
#hide
torch.manual_seed(42);
為了看看我們如何利用溫度來影響生成的文本,讓我們通過在generate()函數中設置溫度參數,以T=2為例進行采樣(我們將在下一節解釋top_k參數的含義):
output_temp=model.generate(input_ids,max_length=max_length,do_sample=True,
temperature=2.0,top_k=0)
print(tokenizer.decode(output_temp[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
While the station aren protagonist receive Pengala nostalgiates tidbitRegarding Jenny loclonju AgreementCON irrational ?rite Continent seaf A jer Turner Dorbecue WILL Pumpkin mere Thatvernuildagain YoAniamond disse * Runewitingkusstemprop});b zo coachinginventorymodules deflation press Vaticanpres Wrestling chargesThingsctureddong Ty physician PET KimBi66 graz Oz at aff da temporou MD6 radi iter
我們可以清楚地看到,高溫產生了大部分的胡言亂語;通過調大罕見詞匯出現的概率,我們使模型產生了奇怪的語法和相當多的生造詞!讓我們看看如果我們把溫度降下來會發生什么:
#hide
torch.manual_seed(42);
output_temp=model.generate(input_ids,max_length=max_length,do_sample=True,
temperature=0.5,top_k=0)
print(tokenizer.decode(output_temp[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The scientists were searching for the source of the mysterious sound, which was making the animals laugh and cry.
The unicorns were living in a remote valley in the Andes mountains
'When we first heard the noise of the animals, we thought it was a lion or a tiger,' said Luis Guzman, a researcher from the University of Buenos Aires, Argentina.
'But when
這明顯更有連貫性,甚至還包括了另一所大學因這一發現而被引用的一段話 我們可以從溫度中得出的主要經驗是,它允許我們控制樣本的質量,但在一致性(低溫)和多樣性(高溫)之間總有一個權衡,我們需要根據根據手頭的使用情況進行調整。
調整一致性和多樣性之間權衡的另一種方法是截斷詞匯的分布。這使我們能夠隨著溫度自由地調整多樣性,但在一個更有限的范圍內,排除那些在語境中過于奇怪的詞(即低概率詞)。有兩種主要的方法:top-k和nucleus(或top-p)采樣。我們來看看
在大多數研究中, tempreature的選擇,往往呈現如下規律:
-
當 temperature 設置為較小或者0的值時, Temperature Sampling 等同于 每次選擇最大概率的 Greedy Search。 -
小的temperature 會引發極大的 repetitive 和predictable文本,但是文本內容往往更貼合語料(highly realistic),基本所有的詞都來自與語料庫。 -
當temperatures較大時, 生成的文本更具有隨機性( random)、趣味性( interesting),甚至創造性( creative); 甚至有些時候能發現一些新詞(misspelled words) 。 -
當 設置高 temperature時,文本局部結構往往會被破壞,大多數詞可能會時semi-random strings 的形式。 -
實際應用中,往往experiment with multiple temperature values! 當保持了一定的隨機性又能不破壞結構時,往往會得到有意思的生成文本。
Top-k和核采樣(Top-k and Nucleus Sampling)
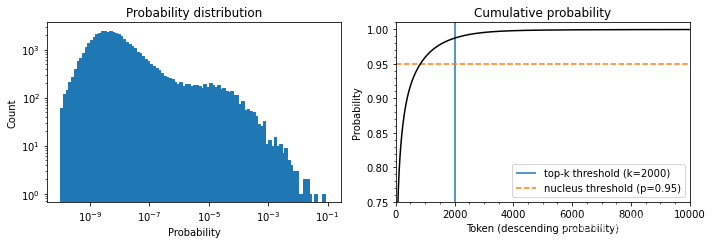
Top-k和nucleus(top-p)抽樣是兩種流行的替代方法或使用溫度的擴展。在這兩種情況下,其基本思想是限制我們在每個時間步長中可以取樣的可能標記的數量。為了了解這一點,首先讓我們把模型在T=1時的累積概率分布可視化,如圖5-6所示。
讓我們把這些圖分開,因為它們包含了大量的信息。在上面的圖中,我們可以看到令牌概率的柱狀圖。它在10-8左右有一個峰值,在10-4左右有一個較小的峰值,然后是急劇下降,只有少數幾個概率在10-2和10-1之間的標記出現。看這張圖,我們可以看到,挑選概率最高的字符(10-1處的孤立條)的概率是1/10。
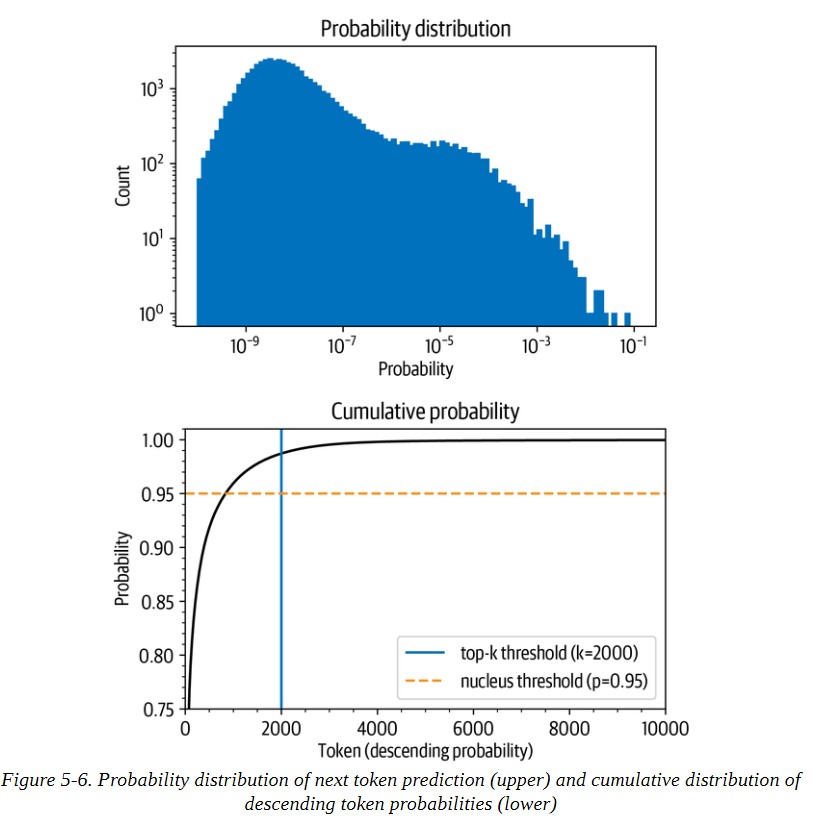
在下圖中,我們按概率降序排列標記,并計算前10,000個標記的累積總和(GPT-2的詞匯中總共有50,257個標記)。弧線代表挑選前面任何一個標記的概率。例如,在概率最高的1,000個標記中,大約有96%的機會挑選任何一個標記。我們看到,該概率迅速上升到90%以上,但在幾千個標記之后才飽和,接近100%。該圖 顯示,有1/100的概率沒有選到任何甚至不在前2000名的標記。
雖然這些數字乍看之下可能很小,但它們變得很重要,因為在生成文本時,我們對每個標記取樣一次。因此,即使只有1/100或1/1000的機會,如果我們取樣數百次,就有很大的機會在某一時刻選到一個不可能的標記,而且在取樣時選到這樣的標記會嚴重影響生成文本的質量。出于這個原因,我們通常希望避免這些非常不可能的標記。這就是top-k和top-p采樣發揮作用的地方。
#hide
torch.manual_seed(42);
#hide
input_txt="""Inashockingfinding,scientistdiscovered
aherdofunicornslivinginaremote,previouslyunexplored
valley,intheAndesMountains.Evenmoresurprisingtothe
researcherswasthefactthattheunicornsspokeperfectEnglish.
"""
input_ids=tokenizer(input_txt,return_tensors="pt")["input_ids"].to(device)
#hide
importtorch.nn.functionalasF
withtorch.no_grad():
output=model(input_ids=input_ids)
next_token_logits=output.logits[:,-1,:]
probs=F.softmax(next_token_logits,dim=-1).detach().cpu().numpy()
#hide_input
#iddistribution
#altProbabilitydistributionofnexttokenprediction.
#captionProbabilitydistributionofnexttokenprediction(left)andcumulativedistributionofdescendingtokenprobabilities
importmatplotlib.pyplotasplt
importnumpyasnp
fig,axes=plt.subplots(1,2,figsize=(10,3.5))
axes[0].hist(probs[0],bins=np.logspace(-10,-1,100),color="C0",edgecolor="C0")
axes[0].set_xscale("log")
axes[0].set_yscale("log")
axes[0].set_title("Probabilitydistribution")
axes[0].set_xlabel("Probability")
axes[0].set_ylabel("Count")
#axes[0].grid(which="major")
axes[1].plot(np.cumsum(np.sort(probs[0])[::-1]),color="black")
axes[1].set_xlim([0,10000])
axes[1].set_ylim([0.75,1.01])
axes[1].set_title("Cumulativeprobability")
axes[1].set_ylabel("Probability")
axes[1].set_xlabel("Token(descendingprobability)")
#axes[1].grid(which="major")
axes[1].minorticks_on()
#axes[1].grid(which='minor',linewidth='0.5')
top_k_label='top-kthreshold(k=2000)'
top_p_label='nucleusthreshold(p=0.95)'
axes[1].vlines(x=2000,ymin=0,ymax=2,color='C0',label=top_k_label)
axes[1].hlines(y=0.95,xmin=0,xmax=10000,color='C1',label=top_p_label,linestyle='--')
axes[1].legend(loc='lowerright')
plt.tight_layout()
#hide
torch.manual_seed(42);
-
top-k抽樣
在Top-K Sampling中,將挑選出K個最有可能的下一個單詞,并且僅在這K個下一個單詞之間重新為它們分配概率。GPT2就是采用了這種采樣方案,這也是其生成故事效果不錯的原因之一。
我們將上面示例中兩個采樣步中使用的單詞范圍從3個擴展到10個,以更好地說明Top-K采樣。
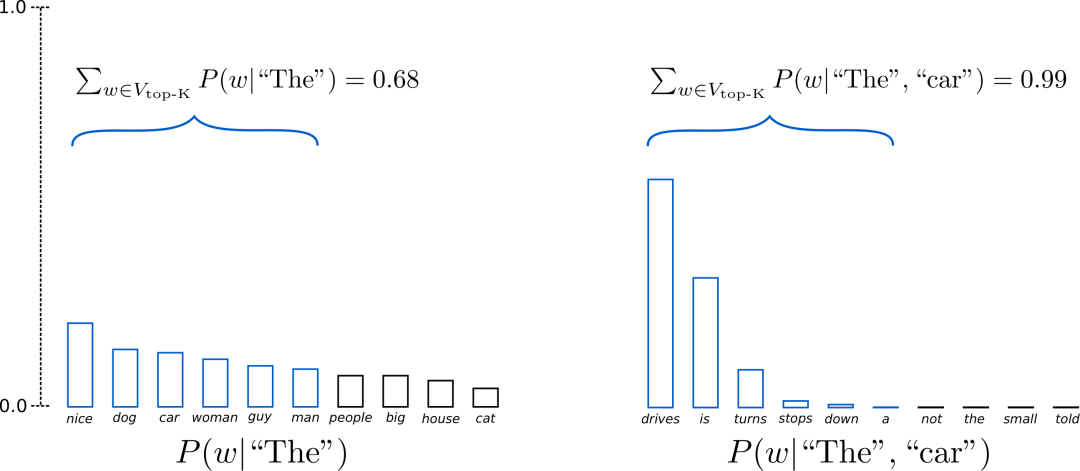
上述設置K = 6 K=6K=6,將采樣最有可能的6個單詞,記為V top-K .在第一步采樣中,V top-K top-K 包含了整體的2/3,第二步采樣則包含了幾乎全部,但是有效地去除了一些奇奇怪怪的單詞。
top-k抽樣背后的想法是通過只從概率最高的k個標記中抽樣來避免低概率的選擇。這就在分布的長尾上設置了一個固定的切口,確保我們只從可能的選擇中取樣。回到圖5-6,top-k抽樣相當于定義一條垂直線并從左邊的標記中抽樣。同樣,generate()函數通過top_k參數提供了一個簡單的方法來實現這一點:
output_topk=model.generate(input_ids,max_length=max_length,do_sample=True,
top_k=50)
print(tokenizer.decode(output_topk[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The wild unicorns roam the Andes Mountains in the region of Cajamarca, on the border with Argentina (Picture: Alamy/Ecole Nationale Supérieure d'Histoire Naturelle)
The researchers came across about 50 of the animals in the valley. They had lived in such a remote and isolated area at that location for nearly a thousand years that
這可以說是我們迄今為止生成的最像人類的文本。但是我們如何選擇k呢?k的值是手動選擇的,對序列中的每個選擇都是一樣的,與實際的輸出分布無關。序列中的每個選擇都是一樣的,與實際的輸出分布無關。我們可以通過查看一些文本質量指標來找到一個好的k值,我們將在下一章探討這個問題--但這個固定的截止值可能并不十分令人滿意。
另一種方法是使用動態截斷。在核抽樣或頂抽樣中,我們不是選擇一個固定的截斷值,而是設定一個截斷的時間條件。這個條件就是在選擇中達到一定的概率質量時。比方說,我們把這個值設定為95%。然后我們按概率降序排列所有標記,并從列表的頂部開始一個接一個地添加標記,直到所選標記的概率之和達到95%。回到圖5-6,p的值在概率累積總和圖上定義了一條水平線,我們只從該線以下的標記中取樣。根據輸出分布,這可能只是一個(非常可能的)標記,也可能是一百個(同樣可能的)標記。在這一點上,你可能對generate()函數也提供了一個激活top-p抽樣的參數而不感到驚訝。讓我們來試試吧:
-
top-p采樣
在Top-p采樣中,不是從僅最可能的K個單詞中采樣,而是從其累積概率超過一個閾值p的最小可能單詞集合中進行選擇,然后將這組單詞重新分配概率。這樣,單詞集合的大小(也就是集合中單詞的數量)可以根據下一個單詞的概率分布動態地增加或減少。
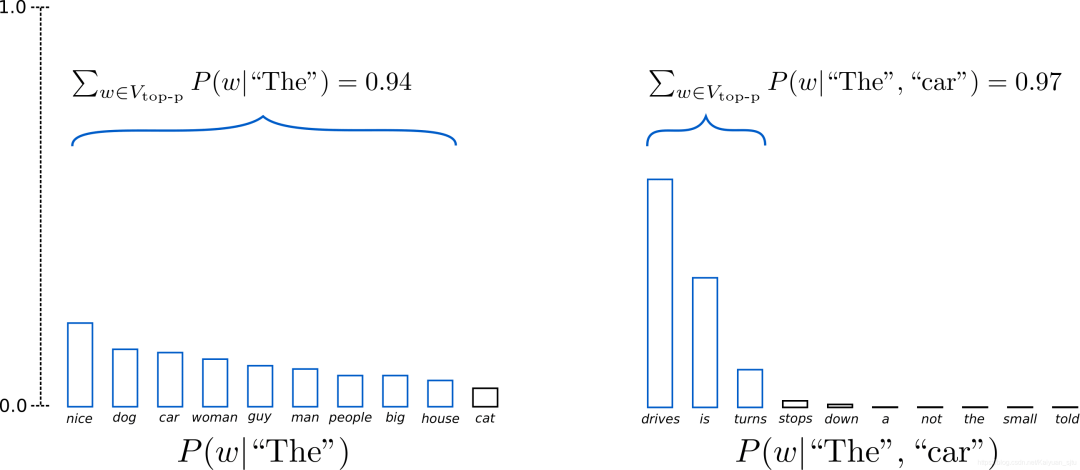
上圖示例設置p = 0.92 p = 0.92p=0.92,定義為V top-p ,所有單詞累計概率超過0.92的最小單詞子集。在第一步采樣中,包括了9個最有可能的單詞,而在第二步采樣中,只需選擇前3個單詞即可超過92%。其實很簡單!上述過程可以看成,當下一個單詞的可預測性不確定時,保留了較多的單詞,例如 P ( w ∣ ′ ′ The ′ ′ ) );而當下一個單詞看起來比較可預測時,只保留幾個單詞,例如P,P(w∣" The ", “car”)。
#hide
torch.manual_seed(42);
output_topp=model.generate(input_ids,max_length=max_length,do_sample=True,
top_p=0.90)
print(tokenizer.decode(output_topp[0]))
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The scientists studied the DNA of the animals and came to the conclusion that the herd are descendants of a prehistoric herd that lived in Argentina about 50,000 years ago.
According to the scientific analysis, the first humans who migrated to South America migrated into the Andes Mountains from South Africa and Australia, after the last ice age had ended.
Since their migration, the animals have been adapting to
Top-p采樣也產生了一個連貫的故事,而且這次有一個新的轉折點,關于從澳大利亞到南美洲的移民。你甚至可以把這兩種抽樣方法結合起來,以獲得兩個世界的最佳效果。設置top_k=50和top_p=0.9,相當于從最多50個標記的池子里選擇概率質量為90%的標記的規則。
注意事項
當我們使用抽樣時,我們也可以應用束搜索。與其貪婪地選擇下一批候選標記,我們可以對它們進行抽樣,并以同樣的方式建立起波束。
哪種解碼方法是最好的?
不幸的是,沒有一個普遍的 "最佳 "解碼方法。哪種方法最好,取決于你生成文本的任務的性質。如果你想讓你的模型執行一個精確的任務,如進行算術運算或提供一個特定問題的答案,那么你應該降低溫度或使用確定性的方法,如貪婪搜索與束搜索相結合,以保證得到最可能的答案。如果你想讓模型生成更長的文本,甚至有點創造性,那么你應該改用抽樣方法,并提高溫度,或者使用top-k和核抽樣的混合方法。
結論
在這一章中,我們研究了文本生成,這是一項與我們之前遇到的NLU任務截然不同的任務。生成文本需要對每個生成的標記進行至少一次前向傳遞,如果我們使用束搜索,則需要更多。這使得文本生成對計算的要求很高,人們需要合適的基礎設施來大規模地運行文本生成模型。此外,一個好的解碼策略,將模型的輸出概率轉化為離散的標記,可以提高文本質量。找到 最好的解碼策略需要進行一些實驗和對生成的文本進行主觀評價。然而,在實踐中,我們不希望僅憑直覺來做這些決定。和其他NLP任務一樣,我們應該選擇一個能反映我們想要解決的問題的模型性能指標。不出所料,選擇的范圍很廣,我們將在下一章中遇到最常見的選擇,在這一章中我們將看看如何訓練和評估文本總結的模型。或者,如果你迫不及待地想學習如何從頭開始訓練一個GPT類型的模型,你可以直接跳到第10章,在那里我們收集一個大型的代碼數據集,然后在上面訓練一個自回歸語言模型。
原文標題:Transformers實戰系列 之 文本生成
文章出處:【微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅 -
生成
+關注
關注
0文章
6瀏覽量
13614 -
語言模型
+關注
關注
0文章
532瀏覽量
10300 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13599
原文標題:Transformers實戰系列 之 文本生成
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何構建文本生成器?如何實現馬爾可夫鏈以實現更快的預測模型
OpenAI發布一款令人印象深刻的語言模型GPT-2
人工智能在文本創作上的發展分析
OpenAI宣布,發布了7.74億參數GPT-2語言模型
基于生成對抗網絡GAN模型的陸空通話文本生成系統設計
文本生成任務中引入編輯方法的文本生成

受控文本生成模型的一般架構及故事生成任務等方面的具體應用
使用NVIDIA TensorRT優化T5和GPT-2

基于OpenAI的GPT-2的語言模型ProtGPT2可生成新的蛋白質序列
基于VQVAE的長文本生成 利用離散code來建模文本篇章結構的方法
ELMER: 高效強大的非自回歸預訓練文本生成模型
ETH提出RecurrentGPT實現交互式超長文本生成

微軟提出Control-GPT:用GPT-4實現可控文本到圖像生成!

面向結構化數據的文本生成技術研究






 工商網監
工商網監
評論