 使用PyTorch Lightning構建語音模型和解決方案
使用PyTorch Lightning構建語音模型和解決方案
人工智能正在推動第四次工業革命,其機器可以在超人的水平上聽到、看到、理解、分析,然后做出明智的決定。然而,人工智能的有效性取決于基礎模型的質量。因此,無論您是學術研究人員還是數據科學家,您都希望使用各種參數快速構建模型,并確定最有效的解決方案。
在這篇文章中,我們將引導您在 GPU NVIDIA 供電的 AWS 實例上使用 PyTorch Lightning構建語音模型。
PyTorch Lightning + Grid.ai :以更快的速度按比例構建模型
NGC 目錄 Lightning 是用于高性能 AI 研究的輕量級 PyTorch 包裝。使用 Lightning 組織 PyTorch 代碼可以在多個 GPU 和 TPU CPU 上進行無縫培訓,并使用難以實施的最佳實踐,如檢查點、日志記錄、分片和混合精度。 PyTorch 上提供了 PyTorch Lightning 容器和開發人員環境。
網格使您能夠將培訓從筆記本電腦擴展到云端,而無需修改代碼。 Grid 在 AWS 等云提供商上運行,支持 Lightning 以及 Sci 工具包、 TensorFlow 、 Keras 、 PyTorch 等所有經典機器學習框架。使用 Grid ,可以縮放 NGC 目錄中模型的訓練。
NGC : GPU 優化 AI 軟件的中心
NGC 目錄是 GPU 優化軟件(包括AI / ML 容器、預訓練模型和 SDK )的中心,這些軟件可以輕松部署到內部部署、云、邊緣和混合環境中。 NGC 提供 NVIDIA TAO 工具套件,可使用自定義數據和 NVIDIA Triton 推理服務器對模型進行再培訓,以便在 CPU 和 GPU 供電系統上運行預測。
本文的其余部分將指導您如何利用NGC 目錄中的模型和 NVIDIA NeMo 框架,在 PyTorch 教程的基礎上,使用以下tutorial使用帶 NeMo 的 ASR Lightning 訓練自動語音識別( ASR )模型。
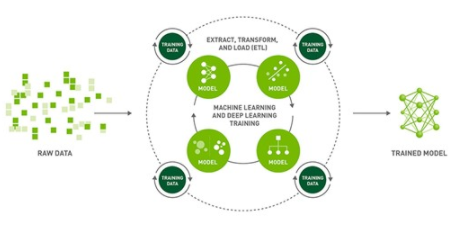
圖 1 。人工智能模型訓練過程
通過網格課程培訓 NGC 模型, PyTorch Lightning 和 NVIDIA NeMo
ASR 是將口語轉錄成文本的任務,是語音 – 文本系統的關鍵組成部分。在訓練 ASR 模型時,您的目標是從給定的音頻輸入中生成文本,以最小化人類轉錄語音的單詞錯誤率( WER )度量。 NGC 目錄包含 ASR 最先進的預訓練模型。
在本文的其余部分中,我們將向您展示如何使用網格會話 NVIDIA NeMo 和 PyTorch Lightning 在AN4 數據集上對這些模型進行微調。
AN4 數據集,也稱為字母數字數據集,由卡內基梅隆大學收集和發布。它包括人們拼寫地址、姓名、電話號碼等的錄音,一次一個字母或號碼,以及相應的成績單。
步驟 1 :創建針對 Lightning 和預訓練 NGC 模型優化的網格會話
網格會話運行在需要擴展的相同硬件上,同時為您提供預配置的環境,以比以前更快地迭代機器學習過程的研究階段。會話鏈接到 GitHub ,使用 JupyterHub 加載,可以通過 SSH 和您選擇的 IDE 進行訪問,而無需自己進行任何設置。
對于會話,您只需支付使基線運行所需的計算費用,然后您就可以通過網格運行將工作擴展到云。網格會話針對托管在 NGC 目錄上的 PyTorch Lightning 和模型進行了優化。他們甚至提供專門的現貨定價。

圖 2 。創建網格會話的工作流
步驟 2 :克隆 ASR 演示報告并打開教程筆記本
現在您有了一個針對 PyTorch Lightning 優化的開發人員環境,下一步是克隆 NGC Lightning Grid Workshop repo 。
您可以使用以下命令直接從網格會話中的終端執行此操作:
git clone https://github.com/aribornstein/NGC-Lightning-Grid-Workshop.git
克隆 repo 后,可以打開筆記本,使用 NeMo 和 PyTorch Lightning 對 NGC 托管模型進行微調。
步驟 3 :安裝 NeMo ASR 依賴項
首先,安裝所有會話依賴項。運行 PyTorch Lightning 和 NeMo 等工具,并處理 AN4 數據集以完成此操作。運行教程筆記本中的第一個單元格,該單元格運行以下 bash 命令來安裝依賴項。
## Install dependencies !pip install wget !sudo apt-get install sox libsndfile1 ffmpeg -y !pip install unidecode !pip install matplotlib>=3.3.2 ## Install NeMo BRANCH = 'main' !python -m pip install --user git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all] ## Grab the config we'll use in this example !mkdir configs !wget -P configs/ https://raw.githubusercontent.com/NVIDIA/NeMo/$BRANCH/examples/asr/conf/config.yaml
步驟 4 :轉換并可視化 AN4 數據集
AN4 數據集以原始 Sof 音頻文件的形式提供,但大多數模型在mel p 頻譜圖上處理。請將 Sof 文件轉換為 Wav 格式,以便使用 NeMo 音頻處理。
import librosa import IPython.display as ipd import glob import os import subprocess import tarfile import wget # Download the dataset. This will take a few moments... print("******") if not os.path.exists(data_dir + '/an4_sphere.tar.gz'): an4_url = 'http://www.speech.cs.cmu.edu/databases/an4/an4_sphere.tar.gz' an4_path = wget.download(an4_url, data_dir) print(f"Dataset downloaded at: {an4_path}") else: print("Tarfile already exists.") an4_path = data_dir + '/an4_sphere.tar.gz' if not os.path.exists(data_dir + '/an4/'): # Untar and convert .sph to .wav (using sox) tar = tarfile.open(an4_path) tar.extractall(path=data_dir) print("Converting .sph to .wav...") sph_list = glob.glob(data_dir + '/an4/**/*.sph', recursive=True) for sph_path in sph_list: wav_path = sph_path[:-4] + '.wav' cmd = ["sox", sph_path, wav_path] subprocess.run(cmd) print("Finished conversion. ******") # Load and listen to the audio file example_file = data_dir + '/an4/wav/an4_clstk/mgah/cen2-mgah-b.wav' audio, sample_rate = librosa.load(example_file) ipd.Audio(example_file, rate=sample_rate)
然后,您可以將音頻示例可視化為音頻波形的圖像。圖 3 顯示了與音頻中每個字母對應的波形中的活動,正如您的揚聲器在這里非常清楚地闡明的那樣!
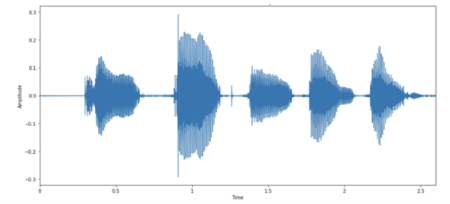
圖 3 示例的音頻波形
每個口語字母都有不同的“形狀”。有趣的是,最后兩個字母看起來相對相似,這是因為它們都是字母 N 。
頻譜圖
在聲音頻率隨時間變化的情況下,音頻建模更容易。您可以得到比 57330 個值的原始序列更好的表示。 頻譜圖是一種很好的可視化音頻中各種頻率強度隨時間變化的方式。它是通過將信號分成更小的、通常重疊的塊,并對每個塊執行短時傅立葉變換( STFT )來獲得的。
圖 4 顯示了樣本的頻譜圖 的外觀。
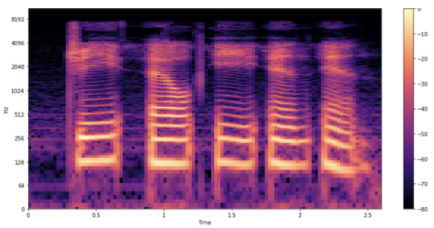
圖 4 示例的音頻譜圖
與前面的波形一樣,您可以看到每個字母的發音。你如何解釋這些形狀和顏色?與前面的波形圖一樣,您可以看到時間在 x 軸上流逝(所有 2 。 6 秒的音頻)。但是,現在 y 軸表示不同的頻率(對數刻度),并且圖上的顏色顯示特定時間點的頻率強度。
Mel 頻譜圖
您仍然沒有完成,因為您可以通過使用 mel 頻譜圖可視化數據來進行一個更可能有用的調整。將頻率比例從線性(或對數)更改為 mel 比例,這樣可以更好地表示人耳可感知的音調。 Mel 頻譜圖直觀上對 ASR 有用。因為您正在處理和轉錄人類語音,所以 mel 頻譜圖可以減少可能影響模型的背景噪聲。
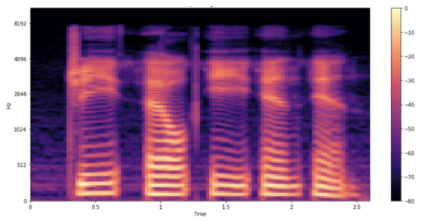
圖 5 示例的 Mel spe CTR 圖
步驟 5 :從 NGC 加載并推斷預訓練的 QuartzNet 模型
既然您已經加載并正確理解了 AN4 數據集,那么看看如何使用 NGC 加載一個 ASR 模型,以便使用 PyTorch Lightning 進行微調。 NeMo 的 ASR 集合包含許多構建塊,甚至完整的模型,您可以使用它們進行培訓和評估。此外,有幾種型號帶有預訓練重量。
要為這篇文章建模數據,可以使用名為來自 NGC 模型中心的 QuartzNet的 Jasper 體系結構。 Jasper 體系結構由重復的塊結構組成,這些塊結構使用 1D 卷積對 spe CTR 圖形數據建模(圖 6 )。
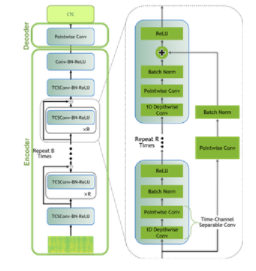
圖 6 Jasper / QuartzNet 模型
QuartzNet 是 Jasper 的一個更好的變體,關鍵區別在于它使用時間通道可分離的一維卷積。這使得它能夠在保持類似精度的同時大幅減少權重的數量。
下面的命令從 NGC 目錄下載預訓練的 QuartzNet15x5 模型,并為您實例化它.
tgmuartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="QuartzNet15x5Base-En")
步驟 6 :使用 Lightning 微調模型
當您擁有一個模型時,您可以使用 PyTorch Lightning 對其進行微調,如下所示。
import pytorch_lightning as pl from omegaconf import DictConfig trainer = pl.Trainer(gpus=1, max_epochs=10) params['model']['train_ds']['manifest_filepath'] = train_manifest params['model']['validation_ds']['manifest_filepath'] = test_manifest first_asr_model = nemo_asr.models.EncDecCTCModel(cfg=DictConfig(params['model']), trainer=trainer) # Start training!!! trainer.fit(first_asr_model)
因為您使用的是 Lightning Trainer ,所以您獲得了一些關鍵優勢,例如默認情況下的模型檢查點和日志記錄。您還可以使用 50 +種最佳實踐策略,而無需修改模型代碼,包括多 GPU 訓練、模型切分、深度速度、量化感知訓練、提前停止、混合精度、漸變剪裁和分析。

圖 7 微調策略
步驟 7 :推斷和部署
既然您有了一個基線模型,那么就推斷它。
圖 9 運行推斷
步驟 8 :暫停會話
現在您已經訓練了模型,您可以暫停會話,并保存您需要的所有文件。
圖 9 監視網格會話
暫停的會話是免費的,可以根據需要恢復。
結論
現在,您應該對 PyTorch Lightning 、 NGC 和 Grid 有了更好的了解。您已經對第一個 NGC NeMo 模型進行了微調,并通過網格運行對其進行了優化。我們很高興看到您下一步如何使用 Grid 和 NGC。
關于作者
Ari Bornstein 是一名人工智能研究人員,他熱愛歷史、新技術和計算醫學。作為 Grid 。 ai 的開發人員宣傳負責人,他與機器學習社區合作,利用改變游戲規則的技術解決現實世界中的問題,這些技術隨后被記錄在案、開源并與世界其他地方共享。
Chintan Patel是NVIDIA的高級產品經理,致力于將GPU加速的解決方案引入HPC社區。 他負責NVIDIA GPU Cloud注冊表中HPC應用程序容器的管理和提供。 在加入NVIDIA之前,他曾在Micrel,Inc.擔任產品管理,市場營銷和工程職位。他擁有圣塔克拉拉大學的MBA學位以及UC Berkeley的電氣工程和計算機科學學士學位。
Shokoufeh Monejzi Kouchak 是 NVIDIA 的技術營銷工程師,專注于深度學習模型。肖庫菲從亞利桑那州國家大學獲得了計算機工程學博士學位,她把重點放在駕駛行為分析和駕駛員注意力檢測上,并用深度學習模型。
審核編輯:郭婷
-
人工智能
+關注
關注
1792文章
47497瀏覽量
239214 -
數據集
+關注
關注
4文章
1208瀏覽量
24749 -
pytorch
+關注
關注
2文章
808瀏覽量
13283
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論