") 使用NVIDIA DALI加速醫(yī)學圖像處理
使用NVIDIA DALI加速醫(yī)學圖像處理
深度學習模型需要大量數(shù)據(jù)才能產生準確的預測,隨著模型規(guī)模和復雜性的增加,這種需求日益迫切。即使是大型數(shù)據(jù)集,例如擁有 100 多萬張圖像的著名 ImageNet ,也不足以在現(xiàn)代計算機視覺任務中實現(xiàn)最先進的結果。
為此,需要使用數(shù)據(jù)增強技術,通過對數(shù)據(jù)引入隨機干擾(如幾何變形、顏色變換、噪聲添加等),人為地增加數(shù)據(jù)集的大小。這些干擾有助于生成預測更穩(wěn)健的模型,避免過度擬合,并提供更好的精度。
在醫(yī)學成像任務中,數(shù)據(jù)擴充至關重要,因為數(shù)據(jù)集最多只包含數(shù)百或數(shù)千個樣本。另一方面,模型往往會產生需要大量 GPU 內存的大激活,特別是在處理 CT 和 MRI 掃描等體積數(shù)據(jù)時。這通常會導致在小數(shù)據(jù)集上進行小批量的培訓。為了避免過度擬合,需要更精細的數(shù)據(jù)預處理和擴充技術。
然而,預處理通常對系統(tǒng)的整體性能有重大影響。這在處理大輸入的應用程序中尤其如此,例如體積圖像。由于 NumPy 等庫的簡單性、靈活性和可用性,這些預處理任務通常在 CPU 上運行。
在某些應用中,例如醫(yī)學圖像的分割或檢測,由于數(shù)據(jù)預處理通常在 CPU 中執(zhí)行,因此訓練期間的 GPU 利用率通常不理想。解決方案之一是嘗試完全重疊數(shù)據(jù)處理和訓練,但并不總是那么簡單。
這樣的性能瓶頸導致了雞和蛋的問題。由于性能原因,研究人員避免在他們的模型中引入更高級的增強,并且由于采用率較低,庫不會將精力放在優(yōu)化預處理原語上。
GPU 加速解決方案
通過將數(shù)據(jù)預處理卸載到 GPU ,可以顯著提高具有大量數(shù)據(jù)預處理管道的應用程序的性能。 GPU 在此類場景中通常未得到充分利用,但可用于完成 CPU 無法及時完成的工作。其結果是更好的硬件利用率,最終更快的培訓。
就在最近, NVIDIA 在 MICCAI 2021 腦腫瘤分割挑戰(zhàn)中獲得 10 個頂級排名中的 3 個 ,包括獲勝的解決方案。獲勝的解決方案通過加快系統(tǒng)的 preprocessing pipeline 速度,使 GPU 利用率高達 98% ,并將總訓練時間減少了約 5% ( 30 分鐘)(圖 1 )。
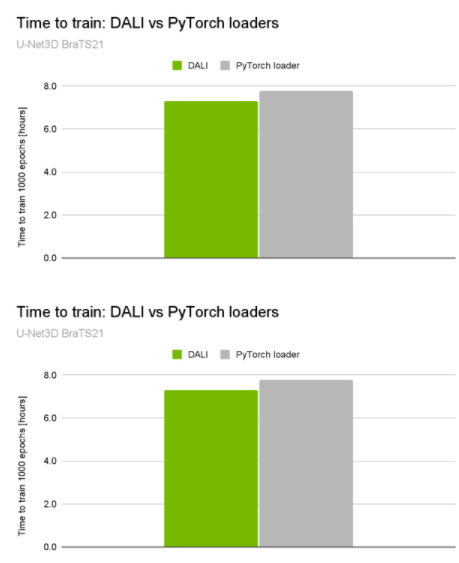
圖 1 。 U-Net3D BraTS21 訓練性能比較
當你查看NVIDIA 提交的[VZX333 ]時,這種差異變得更加顯著。它使用了與BraTS21獲獎解決方案相同的網絡體系結構,但具有更復雜的數(shù)據(jù)加載管道和更大的輸入量(KITS19數(shù)據(jù)集)。與本機管道相比,性能提升是令人印象深刻的2倍端到端培訓加速(圖2)。
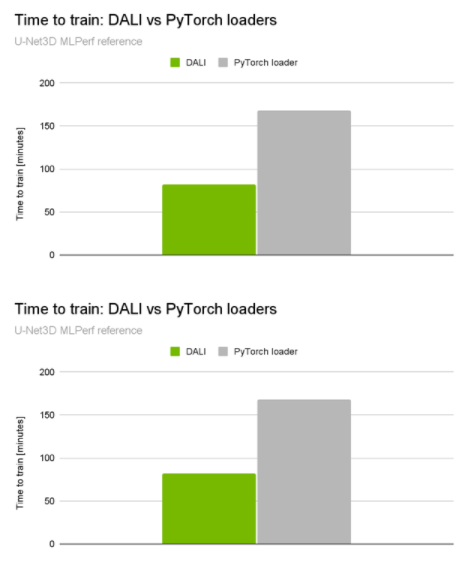
圖 2 。 U-Net3D MLPerf 訓練 1.1 訓練性能比較
這是由 NVIDIA 數(shù)據(jù)加載庫( DALI ) 實現(xiàn)的。 DALI 提供了一組 GPU 加速構建塊,使您能夠構建完整的數(shù)據(jù)處理管道,包括數(shù)據(jù)加載、解碼和擴充,并將其與所選的深度學習框架集成(圖 3 )。
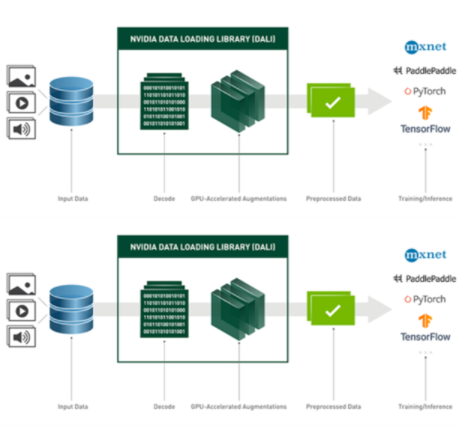
圖 3 。 DALI 概述及其應用 在 DL 應用程序中用作加速數(shù)據(jù)加載和預處理的工具
體積圖像操作
最初, DALI 是作為圖像分類和檢測工作流的解決方案開發(fā)的。后來,它被擴展到其他數(shù)據(jù)域,如音頻、視頻或體積圖像。有關體積數(shù)據(jù)處理的更多信息,請參閱 3D Transforms 或 NumPy 讀卡器 .
DALI 支持多種圖像處理操作員。有些還可以應用于體積圖像。以下是一些值得一提的例子:
Resize
Warp affine
Rotate
隨機對象邊界框
為了展示上述的一些操作,我們使用了來自 BraTS19 數(shù)據(jù)集的一個樣本,該樣本由標記為腦腫瘤分割的 MRI 掃描組成。圖 4 顯示了從腦 MRI 掃描體積中提取的二維切片,其中較暗的區(qū)域表示標記為異常的區(qū)域。
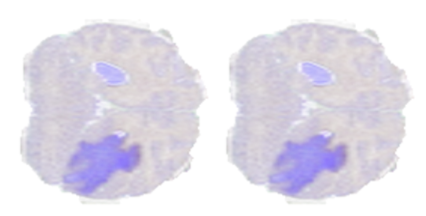
圖 4 。來自 BraTS19 數(shù)據(jù)集樣本的切片
調整大小運算符
Resize通過插值輸入像素將圖像放大或縮小到所需形狀。可以分別為每個維度配置“高比例”或“低比例”,包括選擇插值方法。
Warp affine通過線性變換將像素坐標從源映射到目標,應用幾何變換。
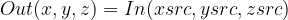
Warp affine可用于一次性執(zhí)行多個變換(旋轉、翻轉、剪切、縮放)。
旋轉運算符
Rotate允許您繞任意軸旋轉體積,該軸作為矢量和角度提供。它還可以選擇性地擴展畫布,使整個旋轉圖像包含在其中。
隨機對象邊界框操作符
隨機對象邊界框是一種適合于檢測和分段任務的運算符。如前所述,醫(yī)療數(shù)據(jù)集往往相當小,目標類別(如異常)占據(jù)的區(qū)域相對較小。此外,在許多情況下,輸入容量遠大于網絡預期的容量。如果要使用隨機裁剪窗口進行訓練,則大多數(shù)窗口不會包含目標。這可能導致訓練收斂速度減慢或使網絡偏向假陰性結果。
此運算符選擇可能偏向于對特定標簽采樣的偽隨機作物。連接組件分析是在標簽圖上執(zhí)行的一個預步驟。然后,以相同的概率隨機選擇一個連接的 blob 。通過這樣做,操作符可以避免過度呈現(xiàn)較大的斑點。
您還可以選擇將選擇限制為最大的 K 個 blob 或指定最小 blob 大小。選擇特定 blob 時,將在包含給定 blob 的范圍內生成隨機裁剪窗口。圖 8 顯示了這個裁剪窗口選擇過程。
圖 8 。想象 the隨機對象邊界框對具有一組屬于三個不同類別(每個類別用不同顏色高亮顯示)的對象的人造 2D 圖像的操作
學習速度的提高是非常顯著的。在 KITS19 數(shù)據(jù)集上, nnU Net 在使用隨機對象邊界框運算符的測試運行時段中, 2134 達到與 3222 個隨機裁剪時段相同的精度。
通常,查找連接組件的過程很慢,但數(shù)據(jù)集中的樣本數(shù)可能很小。操作員可以配置為緩存連接的組件信息,以便僅在培訓的第一個歷元中計算。
關于作者
Janusz Lisiecki 是 NVIDIA 的深度學習經理,致力于快速數(shù)據(jù)管道。他過去的經驗涵蓋從面向大眾消費市場的嵌入式系統(tǒng)到高性能硬件軟件數(shù)據(jù)處理解決方案。
Joaquin Anton Guirao 是 NVIDIA 深度學習框架團隊的高級軟件工程師,專注于 NVIDIA DALI
Pablo Ribalta 是 NVIDIA 的深度學習算法經理,致力于 2D 和體積數(shù)據(jù)的基于圖像的模型。他的研究經驗包括啟發(fā)式、元啟發(fā)式、優(yōu)化以及深度學習的不同應用,如醫(yī)學和衛(wèi)星圖像。
Michal Futrega 是 NVIDIA 的軟件工程師,致力于醫(yī)學圖像分割的神經網絡和藥物發(fā)現(xiàn)的圖形神經網絡。他獲得了華沙大學理學碩士學位和計算機科學理學士學位。
Micha? Marcinkiewicz 是 NVIDIA 深度學習軟件組的高級 CUDA 算法工程師,專注于醫(yī)學圖像分析的計算機視覺。米莎從法國蒙彼利埃大學獲得博士學位,從事拓撲相變研究。獲得博士學位后,他完全轉向機器學習。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5026瀏覽量
103296 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24744 -
深度學習
+關注
關注
73文章
5508瀏覽量
121312
發(fā)布評論請先 登錄
相關推薦
Dali通信模塊的選擇與配置
Dali通信的優(yōu)勢和劣勢
Dali通信網絡的最佳配置
Dali通信在智能照明中的應用
NVIDIA加速計算如何推動醫(yī)療健康
NVIDIA加速AI在日本各行各業(yè)的應用
日本企業(yè)借助NVIDIA產品加速AI創(chuàng)新
dali協(xié)議的詳細解釋和含義 帶你深度了解DALI DALI驅動器選型要注意什么

圖像處理器是什么意思
卷積神經網絡在圖像和醫(yī)學診斷中的優(yōu)勢
利用NVIDIA的nvJPEG2000庫分析DICOM醫(yī)學影像的解碼功能
基于FPGA的實時邊緣檢測系統(tǒng)設計,Sobel圖像邊緣檢測,F(xiàn)PGA圖像處理
常見的醫(yī)學圖像讀取方式和預處理方法
基于門控線性網絡(GLN)的高壓縮比無損醫(yī)學圖像壓縮算法





 工商網監(jiān)
工商網監(jiān)
評論