 利用NVIDIA DALI為加速數據管道提供性能和靈活性
利用NVIDIA DALI為加速數據管道提供性能和靈活性
深度學習模型需要使用大量數據進行培訓,以獲得準確的結果。由于各種原因,例如不同的存儲格式、壓縮、數據格式和大小,以及高質量數據的數量有限,原始數據通常無法直接輸入神經網絡。
解決這些問題需要大量的數據準備和預處理步驟,從加載、解碼、解壓縮到調整大小、格式轉換和各種數據擴充。
深度學習框架,如 TensorFlow 、 PyTorch 、 MXNet 等,為一些預處理步驟提供了本地實現。由于使用特定于框架的數據格式、轉換的可用性以及不同框架之間的實現差異,這通常會帶來可移植性問題。
CPU 瓶頸
直到最近,深度學習工作負載的數據預處理才引起人們的關注,因為訓練復雜模型所需的巨大計算資源使其黯然失色。因此,由于 OpenCV 、 Pillow 或 Librosa 等庫的簡單性、靈活性和可用性,預處理任務通常用于在 CPU 上運行。
NVIDIA 伏特和 NVIDIA 安培體系結構中引入的 GPU 體系結構的最新進展顯著提高了深度學習任務中的 GPU 吞吐量。特別是,半精度算法與張量核加速某些類型的 FP16 矩陣計算,這對培訓DNNs非常有用。密集的多 GPU 系統,如 NVIDIA DGX-2和DGX A100訓練模型的速度遠遠快于輸入管道提供的數據,使 GPU 缺少數據。
今天的 DL 應用程序包括由許多串行操作組成的復雜、多階段的數據處理管道。依賴 CPU 處理這些管道會限制性能和可擴展性。在圖 1 中,可以觀察到數據預處理對 ResNet-50 網絡訓練吞吐量的影響。在左側,我們可以看到在 CPU 上運行的用于數據加載和預處理的框架工具時網絡的吞吐量。在右側,我們可以看到相同網絡的性能,而不受數據加載和預處理的影響,用合成數據替換。當比較不同的數據預處理工具時,這種測量可以用作理論上限。
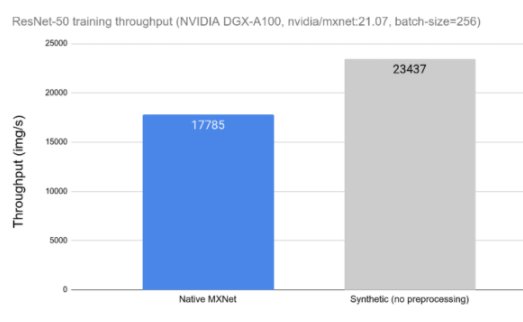
圖 1 : ResNet-50 網絡的數據預處理對總體訓練吞吐量的影響。
大理來營救
NVIDIA 數據加載庫( DALI )是我們致力于為上述數據管道問題找到可擴展和可移植解決方案的結果。 DALI 是一組高度優化的構建塊和執行引擎,用于加速深度學習( DL )應用程序的輸入數據預處理(見圖 2 )。 DALI 為加速不同的數據管道提供了性能和靈活性。
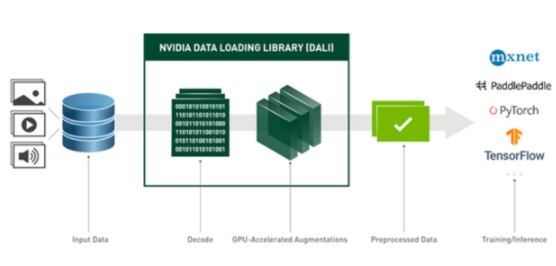
圖 2 : DALI 概述及其在 DL 應用程序中作為加速數據加載和預處理工具的使用。
DALI 為各種深度學習應用程序(如分類或檢測)提供數據處理原語,并支持不同的數據域,包括圖像、視頻、音頻和體積數據。
支持的輸入格式包括最常用的圖像文件格式( JPEG 、 PNG 、 TIFF 、 BMP 、 JPEG2000 、 NETPBM )、 NumPy 陣列、使用多種編解碼器編碼的視頻文件( H 。 264 、 HEVC 、 VP8 、 VP9 、 MJPEG )以及音頻文件( WAV 、 OGG 、 FLAC )。
DALI 的一個重要特性是插件,它可以作為框架本機數據集的插入式替換。目前, DALI 帶有 MxNET PyTorch 、 TensorFlow 和 PaddlePaddle 的插件。只要使用不同的數據迭代器包裝器,就可以一次性定義 DALI 管道,并與任何受支持的框架一起使用。
除此之外, DALI 本機支持特定框架中使用的不同存儲格式(例如, Caffe 和 Caffe2 中的 LMDB 、 MXNet 中的 RecordIO 、 TensorFlow 中的 TFRecord )。這允許我們使用任何受支持的數據格式,而不管使用的是何種 DL 框架。例如,我們可以對模型使用 MXNet ,同時將數據保存在 TFRecord (原生 TensorFlow 數據格式)中。
通過在 Python 中配置外部數據源,或使用自定義運算符進行擴展,可以輕松地為特定項目定制 DALI 。最后,DALI是一個開源項目,因此您可以輕松地對其進行擴展和調整,以滿足您的特定需求。
大理關鍵概念
DALI 中的主要實體是數據處理pipeline。管道由operators連接的數據節點的符號圖定義。每個操作符通常獲得一個或多個輸入,應用某種數據處理,并產生一個或多個輸出。有一些特殊類型的運算符不接受任何輸入并產生輸出。這些特殊操作符就像一個數據源——讀卡器、隨機數生成器和外部_源都屬于這一類。管道定義在 Python 中使用命令式語言表示,與當前大多數深度學習框架一樣,但以異步方式運行。
構建完成后,管道實例可以通過調用管道的 run 方法顯式運行,也可以使用特定于目標深度學習框架的數據迭代器包裝。
DALI 為各種處理操作員提供 CPU 和 GPU 實現。 CPU 或 GPU 實現的可用性取決于運營商的性質。確保檢查文檔中是否有支持的操作的最新列表,因為每個版本都會對其進行擴展。
DALI 運營商要求將輸入數據放置在與運營商后端相同的設備上。具有混合后端的運算符是一種特殊類型的運算符,用于接收 CPU 內存中的輸入和 GPU 內存中的輸出數據。出于性能原因,無法訪問 DALI 管道中從 GPU 到 CPU 內存的數據傳輸。
雖然 DALI 的大部分好處是在將處理卸載到 GPU 時實現的,但有時在 CPU 上保持部分操作運行是有益的。特別是在 CPU 與 GPU 比率較高的系統中,或在 GPU 完全被模型占用的情況下。用戶可以嘗試 CPU / GPU 位置,以逐個找到最佳位置。
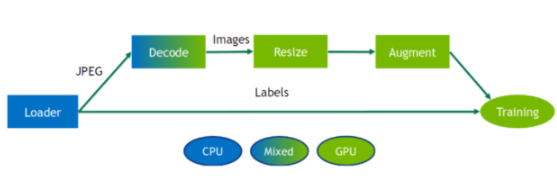
圖 3 : DALI 管道的示例。數據加載到 CPU 上,然后使用混合后端操作符進行解碼,該操作符在 GPU 內存上輸出解碼圖像,然后在 GPU 上對其進行大小調整和擴充。
如前所述, DALI 的執行是異步的,這允許數據預取,也就是說,在請求批數據之前提前準備批數據,以便框架始終為下一次迭代準備好數據。 DALI 使用可配置的預取隊列長度為用戶透明地處理數據預取。數據預取有助于隱藏預處理的延遲,當處理時間在迭代中發生顯著變化時,這一點很重要(見圖 4 )。
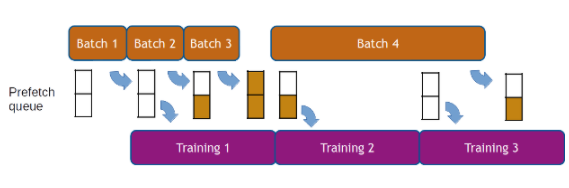
圖 4 :數據預取示例,預取隊列深度為 2 。較長迭代(第 4 批)的延遲因提前計算而被隱藏。
如何使用大理
定義 DALI 管道的最簡單方法是使用pipeline_def Python 裝飾器。為了創建管道,我們定義了一個函數,在該函數中實例化并連接所需的運算符,并返回相關的輸出。然后用pipeline_def來裝飾它。
from nvidia.dali import pipeline_def, fn
@pipeline_def
def simple_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
return images, labels
在這個示例管道中,沒有什么值得注意的事情。第一個操作符是文件讀取器,它發現并加載目錄中包含的文件。讀取器輸出文件的內容(在本例中為編碼的 JPEG )和從目錄結構推斷的標簽。我們還啟用了隨機洗牌并為 reader 實例命名,這在稍后與框架迭代器集成時非常重要。第二個運算符是圖像解碼器。
下一步是實例化simple_pipeline對象并構建它以實際構建圖形。在管道實例化過程中,我們還定義了批大小、用于數據處理的 CPU 線程數以及 GPU 設備序號。
pipe = simple_pipeline(batch_size=32, num_threads=3, device_id=0)
pipe.build()
此時,管道已準備好使用。我們可以通過調用 run 方法獲得一批數據。
images, labels = pipe.run()
現在,讓我們添加一些數據增強,例如,以隨機角度旋轉每個圖像。要生成隨機角度,我們可以使用random.uniform,并旋轉rotation:
@pipeline_def()
def rotate_pipeline():
jpegs, labels = fn.readers.file(file_root=image_dir,
random_shuffle=True,
name="Reader")
images = fn.decoders.image(jpegs)
angle = fn.random.uniform(range=(-10.0, 10.0))
rotated_images = fn.rotate(images, angle=angle, fill_value=0)
return rotated_images, labels
將計算卸載到 GPU
我們現在可以修改我們的簡單_管道,以便它使用.gpu()執行擴充。 DALI 使這種轉變非常容易。唯一改變的是rotate運算符的定義。我們只需要將device參數設置為“gpu”,并確保通過調用 GPU 將其輸入傳輸到 GPU 。
self.rotate = fn.rotate(images.gpu(), angle=angle, device="gpu")
為了使事情更簡單,我們甚至可以省略device參數,讓 DALI 直接從輸入位置推斷出運算符。
self.rotate = fn.rotate(images.gpu(), angle=angle)
也就是說,simple_pipeline現在在 GPU 上執行旋轉。請記住,生成的圖像也會分配到 GPU 內存中,這通常是我們想要的,因為模型需要 GPU 內存中的數據。在任何情況下,運行管道后將數據復制回 CPU 內存都可以通過調用Pipeline.run返回的對象as_cpu輕松實現。
images, labels = pipe.run()
images_host = images.as_cpu()
框架集成
與不同深度學習框架的無縫互操作性代表了 DALI 的最佳功能之一。例如,要將您的管道與 PyTorch 模型一起使用,我們可以通過使用DALIClassificationIterator包裝它來輕松實現。對于更一般的情況,例如任意數量的管道輸出,請使用DALIGenericIterator。
from nvidia.dali.plugin.pytorch import DALIGenericIterator
train_loader = DALIClassificationIterator([pipe], reader_name='Reader')
注意參數reader_name,該值與reader實例的 name 參數匹配。迭代器將使用該讀取器作為一個歷元中樣本數的信息源。
我們現在可以枚舉train_loader實例并將數據批提供給模型。
for i, data in enumerate(train_loader):
images = data[0]["data"]
target = data[0]["label"].squeeze(-1).long()
# model training
關于框架集成的更多信息可以在文檔的框架插件部分中找到。
推理中的達利
為訓練和推理提供數據處理步驟的等效定義對于獲得良好的精度結果至關重要。多虧了 NVIDIA Triton 推理服務器及其專用的大理后端,我們現在可以輕松地將 DALI 管道部署到推理應用程序,使數據管道完全可移植。在圖 6 所示的體系結構中, DALI 管道作為 Triton 集成模型的一部分進行部署。這種配置有兩個主要優點。首先,數據處理是在服務器中執行的,通常是一臺比客戶機功能更強大的機器。第二個好處是數據可以被壓縮后發送到服務器,這節省了網絡帶寬。
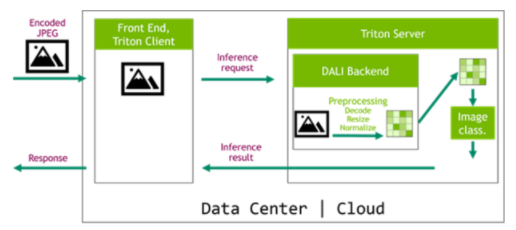
圖 6 : DALI 在推理配置中,帶有 NVIDIA Triton 推理服務器和用于服務器端預處理的 DALI 后端。
請務必查看我們的專用文章使用 NVIDIA Triton 推理服務器和 NVIDIA DALI 加速推理,詳細介紹此主題。
達利對績效的影響
NVIDIA 展示了 DALI 對 SSD 、 ResNet-50 和 RNN-T 的實現,這是我們的MLPerf基準成功中的一個促成因素。
讓我們比較一下使用 DALI 和使用框架的本機解決方案時 ResNet-50 網絡的訓練吞吐量。在圖 7 中,我們可以看到與圖 1 中所示類似的比較,這一次顯示了將 DALI 作為選項之一用于數據加載和預處理的結果。我們可以看到 DALI 的訓練吞吐量如何更接近理論上限(合成示例)。
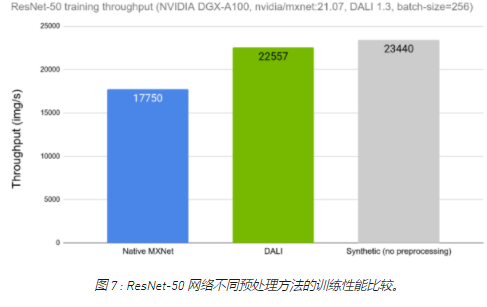
圖 7 : ResNet-50 網絡不同預處理方法的訓練性能比較。
現在讓我們看看 DALI 如何影響 Triton 服務器中 Resnet50 推理的性能。圖 8 顯示了脫機預處理的平均推斷請求延遲,這意味著在啟動請求之前數據已經過預處理,以及聯機服務器端預處理。所花費的時間細分為通信開銷、數據預處理和模型推理。由于解碼數據的大小較大,預處理請求的延遲會受到通信開銷的嚴重影響。因此,服務器端預處理比離線預處理快,即使前者在度量中包含數據預處理時間。
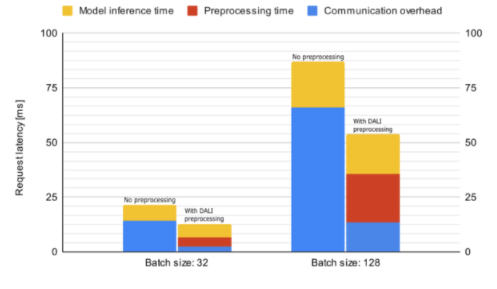
圖 8 : Resnet50 模型推斷的平均請求延遲(越低越好)比較。這些數字是使用 NVIDIA / Triton 服務器在 DGX A100 機器上使用單個 GPU 收集的: 21 。 07-py3 容器。
今天就從 DALI 開始吧
您可以下載預構建和測試的 DALI pip 包的最新版本。]:、MXNetMXNet的 NVIDIA GPU 云( NGC )容器已集成 DALI 。您可以查看許多examples并閱讀最新的發行說明,以獲取新功能和增強功能的詳細列表。
關于作者
Joaquin Anton Guirao 是 NVIDIA 深度學習框架團隊的高級軟件工程師,專注于 NVIDIA DALI
Rafal Banas 是 NVIDIA 的軟件開發工程師。他致力于 DALI 項目,專注于推理用例。拉法在華沙大學獲得計算機科學學士學位。
Krzysztof ??cki 是 NVIDIA 的高級軟件開發工程師,在 DALI 工作。他以前的工作包括為 GPU 和 SIMD 體系結構編寫高度優化的數據處理代碼,重點關注計算機視覺和圖像處理應用。
Janusz Lisiecki 是 NVIDIA 的深度學習經理,致力于快速數據管道。他過去的經驗涵蓋從面向大眾消費市場的嵌入式系統到高性能硬件軟件數據處理解決方案。
Albert Wolant 是軟件開發工程師,在 NVIDIA 的 DALI 團隊工作。他在深度學習和 GP GPU 軟件開發方面都有經驗。他在并行算法和數據結構方面做了一些研究工作。
Micha? Zientkiewicz 是 NVIDIA 的高級軟件工程師,目前正在開發 DALI 。他的專業背景包括 GPU 編程、圖像處理和編譯器開發。米莎先生在華沙工業大學獲得計算機科學碩士學位。
Kamil Tokarski 是 NVIDIA 的軟件工程師,在 DALI 團隊工作,熱衷于深度學習和密碼學。
Micha? Szo?ucha 是 NVIDIA 的軟件工程師,從事圖像處理和深度學習項目。曾與移動 3D 技術合作。熱衷于使波蘭民間傳說適應現代接受者的認知。
審核編輯:郭婷
-
gpu
+關注
關注
28文章
4762瀏覽量
129149 -
python
+關注
關注
56文章
4802瀏覽量
84889 -
深度學習
+關注
關注
73文章
5511瀏覽量
121350
發布評論請先 登錄
相關推薦
Dali通信如何提高能源效率
NVIDIA DOCA-OFED的主要特性
NVIDIA JetPack 6.0版本的關鍵功能

利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
NVIDIA助力提供多樣、靈活的模型選擇

OPSL 優勢1:波長靈活性
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業軟件支持
8芯M16公頭如何提升靈活性

NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

英特爾銳炫A系列顯卡為客戶提供了強大的性能和靈活性

意法半導體推出一款兼備智能功能和設計靈活性的八路高邊開關
利用 IO-Link 提高工業 4.0 工廠的靈活性、利用率和效率





 工商網監
工商網監
評論