 利用NVIDIA平臺并行編程語言加速計算方法
利用NVIDIA平臺并行編程語言加速計算方法
NVIDIA 平臺是最成熟、最完整的加速計算平臺。在這篇文章中,我將介紹最簡單、最高效、最可移植的加速計算方法。有三種編程方法 GPU (圖 1 )。

圖 1 。NVIDIA 平臺編程的三種方法
CUDA C ++ Fortran 是 NVIDIA 可以展示新硬件和軟件創新的創新平臺,在這里,您可以調整應用程序以在 NVIDIA GPU 上實現最佳性能。許多開發人員認為這就是 NVIDIA 希望每個人為 GPU 編程的方式。
相反,我們預計,開發者首次來到NVIDIA平臺將使用標準的并行編程語言,如 ISO C ++、 ISO Fortran 和 Python 。在這篇文章中,我強調了使用這種方法進行并行編程的一些成功,以證明進入NVIDIA CUDA 生態系統的最有成效的途徑。
NVIDIA 戰略的基礎是提供一套豐富、成熟的 SDK 和庫,在這些數據庫上可以構建應用程序。 NVIDIA 已經提供了高度優化的數學庫,如 cuBLAS 、 cuSolver 和 cuFFT ;核心庫,如 Thrust 和 libcu++ ;和通信庫,如 NCCL 和 NVSHMEM ,以及其他可用于構建應用程序的包和框架。
除此之外, NVIDIA 還將三種不同的編程方法分層:
標準語言并行性,這是本文的主題
用于平臺專業化的語言,如 CUDA C ++和 CUDA FORTRAN ,以獲得NVIDIA 平臺上的最佳性能
編譯器指令,通過啟用增量性能優化來彌合這兩種方法之間的差距
每種方法都在性能、生產率和代碼可移植性方面進行權衡。因為它們都可以互操作,所以您不必使用特定的模型,但可以根據需要混合任何或所有模型。
如果您開始使用標準編程語言中的并行性編寫代碼,那么您可以來到NVIDIA 平臺或任何其他已經具有并行運行能力的基線代碼平臺。這就是為什么我們在標準語言委員會中投入了十多年的時間來合作,采用特性來支持并行編程,而不需要額外的擴展或 API 。標準語言并行性是一股興起的潮流,它讓所有人都感到振奮。
ISO C ++
在編程趨勢的最近研究中, C ++編程語言一直是最高級的編程語言之一。它在科學計算中的應用有了顯著的增長。其標準模板庫的豐富性使其成為新代碼開發的高效語言,自 C ++ 17 發布以來,它支持并行編程的幾個重要特性。
我看到幾個應用程序從傳統的循環中重構,有利于這些 C ++并行算法。下面是其中幾個的結果。
Lulesh
Lulesh 是勞倫斯 LIVEMOR 國家實驗室( LLNL )的流體動力學迷你應用程序,用 C++ 編寫。 mini 應用程序有幾個版本用于評估不同的編程方法,包括代碼質量和性能。我們與開發人員一起工作,以重寫他們現有的基于 OpenMP 的代碼,使用 C ++并行算法。圖 2 顯示了應用程序重要功能之一的示例。
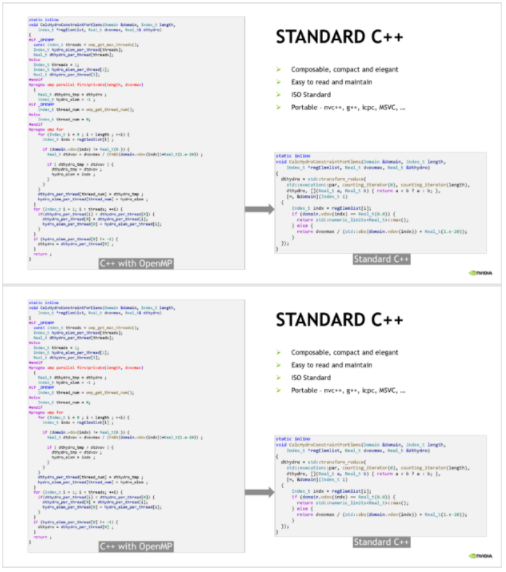
圖 2 。從 OpenMP 到 ISOC ++并行重構 Lulesh 會導致代碼更簡單、更容易閱讀、 ISO 標準,并可移植到支持 ISOC ++的所有編譯器中。
左邊的代碼使用 OpenMP 跨 CPU 線程并行化代碼中的循環。為了維護串行和并行版本的代碼,開發人員使用了#ifdef宏和編譯器雜注。結果是重復代碼,并在源代碼中引入額外的 API OpenMP 。
右邊的代碼是相同的例程,但是使用 C ++ transform_reduce算法重寫。生成的代碼更加緊湊,不易出錯,更易于閱讀,更易于維護。它還移除了 OpenMP 的依賴性,依賴于 C ++標準模板庫,同時為所有平臺維護單個源代碼。此代碼完全符合 ISO C ++,能夠由支持 C ++ 17 的任何 C ++編譯器構建。事實證明,它也更快!
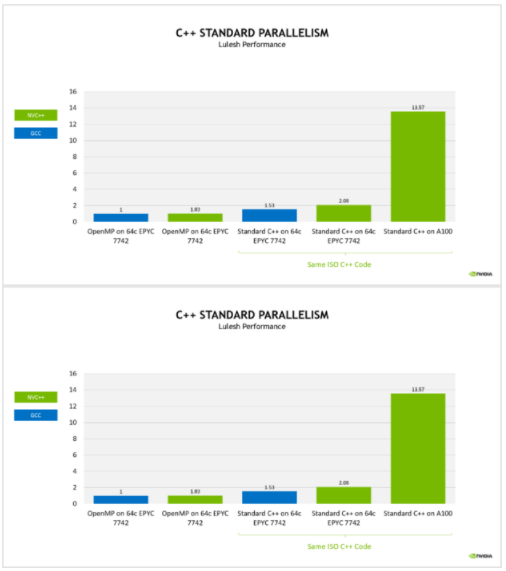
圖 3 。 ISOLC ++版本的 Lulesh 比原始 OpenMP 代碼和便攜式多編譯器和 CPU 和 GPU 之間的速度快。
作為性能基準,我們使用運行在 AMD EPYC 7742 處理器所有核心上的 OpenMP 代碼,并使用 GCC 構建。使用 NVIDIA nvc++編譯器重建此基線代碼在 CPU 上實現了基本相同的性能。
如果您使用同一版本的 GCC 來構建 ISO C ++代碼,并在同一 CPU 上運行,則性能將提高約 50% ,這是由于編譯器的各種改進開銷和機會來更好地優化代碼。
當使用nvc++構建此代碼并在同一 CPU 上運行時,這將使性能提高 2 倍。這已經是一項激動人心的成就,但最重要的是,您可以構建相同的代碼,只需將編譯器選項更改為針對 NVIDIA GPU 而不是多核 CPU 。現在,同樣的代碼在 NvidiaA100 GPU 上運行速度快了 13 倍以上。從原始代碼中得到 13.5x 性能改進,在 CPU 和 GPU 上并行運行,使用嚴格的 ISO C ++代碼。
STLBM
應用 C ++標準并行性的另一個例子是 STLBM ,來自日內瓦大學的格子 Boltzmann 求解器。 Jonas Latt 教授在幾次 GTC 會議上討論了這一應用 顯示了如何在沒有任何外部 SDK 依賴關系的情況下編寫代碼在 ISO C ++中運行,可以使用多個編譯器和多個硬件平臺,包括 NVIDIA GPU 。有關詳細信息,請參閱 基于 C ++并行算法的 GPU 流體力學:一種硬件無關方法的最新進展 和 利用 C++ 標準并行技術在 GPU 中移植科學應用
他的應用程序使用 GPU 實現了超過 12 倍的性能改進。值得注意的是,他的比較基準是默認情況下并行的源代碼,使用 C ++ 17 標準模板庫中的并行算法來表示應用程序中固有的并行性。
他將使用ISO C++作為GPU編程的經驗歸類為“跨平臺CPU/GPU編程的范式轉換”。他的團隊沒有編寫一個默認為串行的應用程序,然后再添加并行性,而是編寫了一個適用于他們希望運行的任何并行平臺的應用程序。
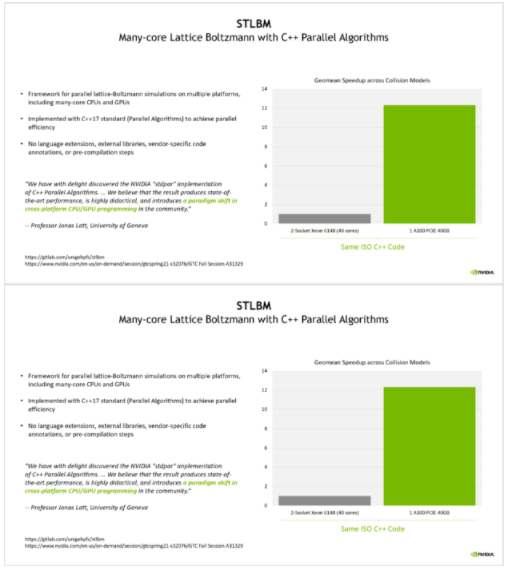
圖 4 。 STLBM 能夠在多核 CPU 節點和 NVIDIA GPU 上運行相同的源代碼
NVIDIA 在 C ++中并行開發和并發性的大量投資,并為即將到來的 C ++ 23 規范編寫了各種建議,以進一步提高您編寫并行的代碼的能力。
ISO Fortran
Fortran 仍然是一種主要關注科學和高性能計算的語言。最初, Fortran 是公式轉換器,它為開發人員和編譯器提供了多種優勢,并且還擁有用于建模和仿真代碼的龐大現有代碼庫。
Fortran 在 2008 年開始添加支持并行編程的功能,在 2018 年增強了這些功能,并在即將發布的版本(目前稱為 Fortran 202X )中繼續完善這些功能。與 ISOC ++一樣, NVIDIA 也一直在與應用程序開發人員一起使用 FORTRAN 中的標準語言并行化來實現它們的應用程序的現代化,并使它們并行。
計算化學
我的同事杰夫·哈蒙德在他的 FortranCon2021:GPU 上的標準 Fortran 及其在量子化學代碼中的應用 session 在 NWChem 應用程序和另一個計算化學應用程序 GAMESS 的內核中使用 Fortran do concurrent循環,給出了一些有希望的結果。
對于 NWChem ,他分離了幾個執行張量收縮的性能關鍵循環,并使用幾個編程模型編寫了它們。在多核 CPU 上,這些張量收縮使用 OpenMP 跨 CPU 核進行線程。對于 GPU ,有使用 OpenACC 、 OpenMP 目標卸載和現在的 Fortran do concurrent循環的版本可用。
圖 5 顯示了do concurrent循環的性能與 NVIDIA GPU 上的 OpenACC 和 OpenMP 目標卸載相同,但不需要在應用程序中包含這些附加 API 。這都是標準的 Fortran 。
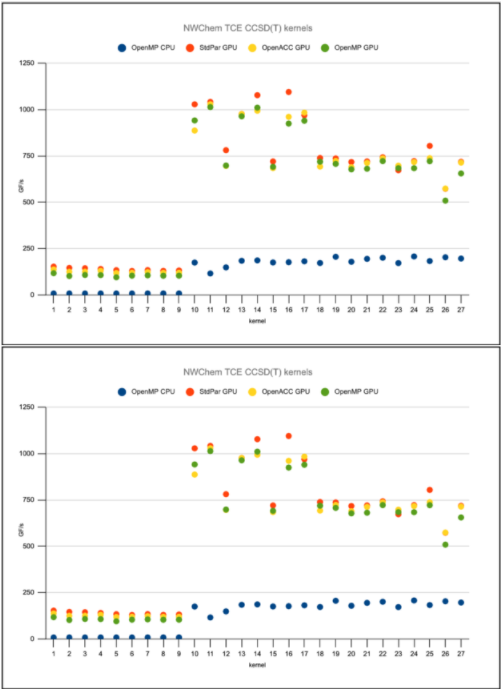
圖 5 使用幾種編程模型的一系列 NWChem 應用程序內核的性能
高性能通量傳輸
在 SC21 會議的最近一次加速器編程使用指令研討會( WACCPD )上, 預測科學公司。 的一組開發人員展示了他們重構其中一個生產代碼的結果,該代碼以前使用 OpenACC 在 NVIDIA GPU 上運行,使用do concurrent循環。
他們比較了使用 NVIDIA nvfortran、gfortran和ifort構建這個純 ISO Fortran 應用程序的結果。他們得出結論,在使用nvfortran編譯器的應用程序中,純 Fortran 提供了他們所需的性能,而不需要任何指令。此外,此代碼可以在 GPU 和多核 CPU 上并行運行,無需修改。

圖 6 。使用 nvfortran compiler
這篇論文在研討會上獲得了最佳論文獎,盡管它根本不需要加速器編程的指導。當被問及他們是否會在其他應用程序中繼續采用標準語言并行方法時,演示者回答說,他們已經計劃在公司的其他重要應用程序中采用這種方法。
Python 帶有連字符和楔形文字
Python 語言在過去十年中迅速流行起來。它現在通常用于機器學習、數據科學,甚至是傳統的建模和仿真應用。雖然 Python 不是 ISO 編程語言,像 C ++和 FORTRAN ,但是我們也在 Python 語言中實現標準語言并行性的精神。
在 GTC ‘ 21 秋季的基調演講中, NVIDIA 首席執行官 Jensen Huang 介紹了 cuNumeric 的 alpha 版本,該庫是在 NumPy 之后建模的,它能夠實現與我所討論的關于 ISO C ++和 FORTRAN 的特性。 NumPy 包在 Python 開發中非常普遍,幾乎可以肯定,任何用 Python 編寫的 HPC 應用程序都會使用它。
在名為 Legate 的包之上編寫的cuNumeric包使 NumPy 應用程序不僅能夠在 GPU 上,而且能夠在大型集群中跨 GPU 自動擴展其工作。我已經看到了幾個例子,簡單地替換代碼中的NumPy引用,而不是引用cuNumeric,我可以將該應用程序弱地縮放到 NVIDIA 內部集群的完整大小, Selene,這是世界上10個最快的超級計算機之一。
結論
我希望這篇文章能讓你看到 GPU 編程并不像你可能聽說的那么困難。如果使用標準語言并行性,甚至可能不需要任何代碼更改。
NVIDIA 鼓勵您先編寫并行應用程序,這樣就不需要將應用程序“移植”到新平臺,而標準語言并行是實現這一點的最佳方法,因為它只需要 ISO 標準語言。這就是為什么我們繼續投資于 ISO 編程語言,并為這些語言帶來更多并行和并發特性。
總之,使用標準語言并行性有以下好處:
完全符合 ISO 語言,從而產生更可移植的代碼
更緊湊、更易于閱讀、不易出錯的代碼
默認情況下是并行的代碼,因此它可以在更多平臺上運行而無需修改
關于作者
Jeff Larkin 是 NVIDIA HPC 軟件團隊的首席 HPC 應用程序架構師。他熱衷于高性能計算并行編程模型的發展和采用。他曾是 NVIDIA 開發人員技術小組的成員,專門從事高性能計算應用程序的性能分析和優化。 Jeff 還是 OpenACC 技術委員會主席,曾在 OpenACC 和 OpenMP 標準機構工作。在加入NVIDIA 之前,杰夫在位于橡樹嶺國家實驗室的克雷超級計算卓越中心工作。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5026瀏覽量
103292 -
gpu
+關注
關注
28文章
4754瀏覽量
129093 -
應用程序
+關注
關注
37文章
3283瀏覽量
57766
發布評論請先 登錄
相關推薦
《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA加速計算如何推動醫療健康
NVIDIA向開放計算項目捐贈Blackwell平臺設計
電流計算方法與配線法的區別
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能


儲能容量的計算方法
NVIDIA通過CUDA-Q平臺為全球各地的量子計算中心提供加速
NVIDIA 通過 CUDA-Q 平臺為全球各地的量子計算中心提供加速

NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
電壓探頭延遲計算方法及應用






 工商網監
工商網監
評論