 使用NVIDIA UFM Cyber AI實現數據中心的安全性和可管理性
使用NVIDIA UFM Cyber AI實現數據中心的安全性和可管理性
今天的數據中心承載著許多用戶和各種各樣的應用程序。它們甚至已經成為研究、技術和全球產業競爭優勢的關鍵要素。隨著科學計算復雜性的增加,數據中心的運營成本也在不斷上升。除了安全威脅造成的運營中斷之外,保持數據中心完好無損并平穩運行也至關重要。
如今的數據中心承載著許多用戶和各種應用,它們甚至已經成為科研、技術和全球產業競爭優勢的關鍵因素。隨著科學計算復雜性的增加,數據中心的運營成本也在不斷上升。除了要防止運營安全隱患的干擾外,保持數據中心的完整和平滑運行也至關重要。
更重要的是,惡意用戶可能會利用數據中心的訪問權限,運行被禁止的應用,濫用計算資源,進而導致意外停機以及更高的運營成本。對于今天的IT經理和支持開發者而言,能夠快速識別問題并提高效率的數據中心管理工具比以往任何時候都更加重要。
NVIDIA以驚人圖形處理能力和出色GPU計算性能而聞名,廣泛應用于各個研究領域。同時,多年來NVIDIA也一直是安全和可擴展數據中心技術的領導者,提供了各種靈活的庫和工具,來最大程度地優化業界一流的基礎設施。
NVIDIA認識到,要為當今研究和商業領域最關鍵的組成部分提供全棧式解決方案,其中不僅包括提供一流的服務器平臺、GPU以及部署在整個數據中心的豐富軟件組合,而且還需要關注到安全和可管理性是建立數據中心基礎設施的關鍵支柱。
此外,惡意用戶可能會利用數據中心訪問權限,通過運行被禁止的應用程序來濫用計算資源,從而導致意外的停機時間和更高的操作成本。 數據中心管理工具比以往任何時候都更能快速發現問題,同時提高效率,是當今 IT 經理和支持它們的開發人員的首要任務。
NVIDIA 最著名的可能是驚人的圖形功能和無與倫比的 GPU 計算性能,幾乎應用于所有研究領域。然而,多年來,它還是安全和可擴展數據中心技術的領導者,包括靈活的庫和工具,以最大限度地利用世界一流的基礎設施。
NVIDIA 認識到,為 MIG 這一當今研究和業務中最關鍵的組成部分提供全套解決方案,不僅包括世界一流的服務器平臺,而部署在整個數據中心的最廣泛的軟件組合。 NVIDIA 也知道,安全性和可管理性是構建數據中心基礎設施的關鍵支柱。
NVIDIA UFM 網絡 AI 徹底改變了 InfiniBand 數據中心
NVIDIA Unified Fabric Manager ( UFM )網絡 AI 平臺提供增強的實時網絡遙測,結合 AI 提供的智能和高級分析。它使 It 經理能夠發現操作異常,甚至預測網絡故障。這提高了安全性和數據中心正常運行時間,同時降低了總體運營開支。
UFM 網絡人工智能的獨特優勢在于它能夠捕獲豐富的遙測信息,并利用人工智能技術來識別事件之間隱藏的相關性。這使它能夠檢測異常的系統和應用程序行為,甚至在性能下降導致組件或系統故障之前識別它們。 UFM 網絡 AI 甚至可以實時采取糾正措施。該平臺學習數據中心的典型操作模式,并基于網絡遙測數據檢測異常使用,包括流量模式、溫度等。
UFM 網絡人工智能基礎
UFM 網絡 AI 包含三個不同的層,如圖 1 所示。
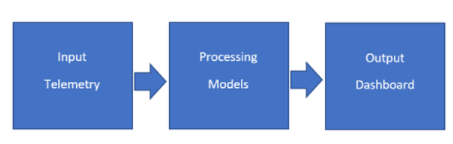
圖 1 。 UFM 網絡 AI 層
輸入遙測: 通過各種方式收集信息并從網絡中學習:
網絡中所有元件的遙測
網絡拓撲(租戶或應用程序的連接和資源分配)
網絡設備的特點和能力
處理模型: 包含幾個模型,例如用于數據準備的提取、轉換和加載( ETL )處理引擎。它還包含聚合、數據存儲和用于比較的分析模型。 UFM 網絡人工智能使用機器學習( ML )技術和人工智能模型進行異常檢測和預測,以學習數據中心網絡組件(電纜、交換機、端口、 InfiniBand 適配器)的生命周期模式。
輸出儀表板: 一個可視化層,它為網絡管理員和云編排器提供一個中央儀表板,以查看有關提高網絡利用率和效率以及解決網絡健康問題的警報和建議。儀表板提供了兩個主要類別: 可疑行為 和 鏈接分析 ,每個類別都包括警報和預測部分(圖 2 )。
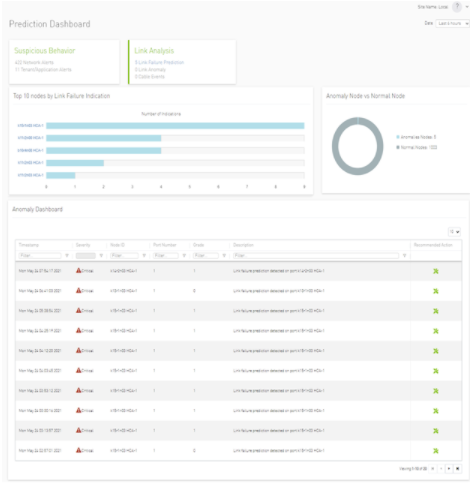
圖 2 。 UFM 網絡人工智能預測儀表盤
功能豐富、直觀且可定制的 fabric manager
UFM 網絡人工智能還支持定制的網絡警報或查看觸發的異常隨著時間的推移和在不同的時間維度。通過使用基于小時或星期幾參數的聚合網絡統計信息,您可以根據 MIG ht 偏離典型操作用途的測量值設置閾值和配置通知。例如,可以使用預定義的閾值來識別有問題的電纜。
內置分析將當前遙測信息與基于時間的聚合信息進行比較,以檢測使用或流量模式中的任何可疑增加或減少,并立即通知系統管理員。 UFM-cyberai 還通過鏈路或端口遙測信息提供數據中心租戶或應用程序警報,以識別與低級別分區密鑰( PKEY )相關的統計信息及其相關節點。
只有 UFM 網絡人工智能提供了鏈接故障預測等功能,支持預測性維護。通過在早期階段檢測性能下降情況, UFM 網絡人工智能可以預測潛在的鏈路或端口故障。這使管理員能夠執行維護并消除數據中心停機時間。
NVIDIA Morpheus 的未來增強功能
為 InfiniBand 帶來最強大的結構管理解決方案需要不斷創新,以跟上管理當今復雜數據中心的復雜性。我們計劃將 NVIDIA Morpheus 與 UFM Cyber AI 集成(圖 3 ),從其他數據中心元素(如服務器或基于機架的組件遙測或 DPU 、 GPU 和應用程序計數器)帶來更多遙測信息。
我們甚至可以提供一個額外的層,它可以直接與其他 api 接口,比如 Kafka ,一個用于高性能數據管道、流分析和數據集成的開源分布式事件流平臺。您可以使用該集成對開發人員定義的操作系統異常進行特定的檢測,例如對生命科學研究專用系統的加密挖掘檢測。
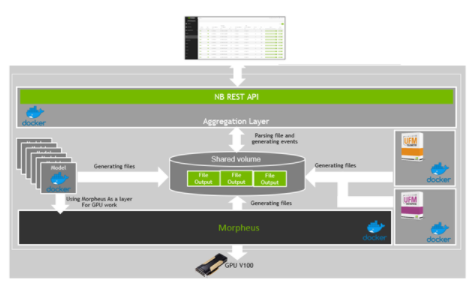
圖 3 。 UFM 網絡人工智能與 Morpheus 框架的集成示例
Morpheus 是一個開放的人工智能應用框架,為網絡安全開發者提供高度優化的人工智能管道和預訓練的人工智能能力。這些功能使您能夠通過數據中心結構即時檢查所有網絡流量。 Morpheus 通過提供以下功能為數據中心帶來了新的安全級別:
動態保護
實時遙測
適應性策略
用于檢測和修復網絡安全威脅的網絡防御
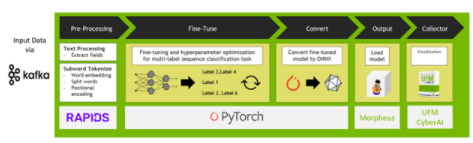
圖 4 。 UFM 網絡人工智能作為靈活和可擴展平臺的示例
隨著 Morpheus 集成到 UFM Cyber AI 設備中,我們可以為關鍵任務數據中心和支持開發人員提供最佳和最完整的解決方案,該解決方案也具有靈活性和可擴展性。通過可定制的異常檢測和與其他標準化 API 的接口, UFM Cyber AI 是任何支持多租戶的數據中心或云本地基礎設施的靈活資產。
關于作者
David Slama 擔任 NVIDIA 網絡營銷高級總監,專注于高性能計算、人工智能、云解決方案和 InfiniBand 技術。 Slama 于 2005 年加入 Mellanox ,擔任軟件工程師,并在 Mellanox 擔任多個軟件管理職位,直到 2020 年。他領導云解決方案、以太網和 InfiniBand 軟件管理、存儲、自動化解決方案以及上游活動,如 Ansible 、 Kubernetes 、 OpenStack 、 puppet 、 chef 等。 Slama 擁有 ML 和 AI 領域的網絡專利。他擁有政府學碩士學位和管理學和計算機科學學士學位。
Scot Schultz 是 HPC 技術專家,專注于人工智能和機器學習系統。 Scot 在分布式計算、操作系統、人工智能框架、高速互連和處理器技術方面擁有廣泛的知識。在他的整個職業生涯中,擁有超過 25 年的高性能計算系統經驗,他的職責包括各種工程和領導角色,包括戰略 HPC 技術生態系統支持。 Scot 在眾多行業標準組織的成長和發展中發揮了重要作用。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5013瀏覽量
103244 -
數據中心
+關注
關注
16文章
4806瀏覽量
72208 -
人工智能
+關注
關注
1792文章
47409瀏覽量
238923
發布評論請先 登錄
相關推薦
如何實現 HTTP 協議的安全性
NVIDIA DOCA 2.9版本的亮點解析

如何選擇數據中心服務

NVIDIA 在 Hot Chips 大會展示提升數據中心性能和能效的創新技術

半導體存儲器在數據中心中的應用
AI時代,我們需要怎樣的數據中心?AI重新定義數據中心

NVIDIA為新工業革命打造 AI 工廠和數據中心
訊維分布式KVM坐席管理系統在數據中心管理中的應用與案例分析
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片

基于NVIDIA DOCA 2.6實現高性能和安全的AI云設計
KVM矩陣的智能化管理:提升運維效率與安全性
KVM矩陣:打造無縫的數據中心管理體驗






 工商網監
工商網監
評論