

磁共振成像( MRI )是一種有用的軟組織或分子擴散成像技術(shù)。然而,獲取 MR 圖像的掃描時間可能相當長。有幾種方法可以用來減少掃描時間,包括矩形視場( RFOV )、部分傅里葉成像和采樣截斷。這些方法要么導致信噪比( SNR )降低,要么導致分辨率降低。有關(guān)更多信息,請參閱k 空間教程:更好地理解 k 空間的 MRI 教育工具。
當使用采樣截斷技術(shù)以減少掃描和數(shù)據(jù)傳輸時間時,吉布斯現(xiàn)象也稱為振鈴或截斷偽影,會出現(xiàn)在結(jié)果圖像中。通常,通過平滑圖像來消除吉布斯現(xiàn)象,從而降低圖像分辨率。
在這篇文章中,我們探索了一種使用 NVIDIA Clara AGX 開發(fā)者套件的深度學習方法,以消除磁共振圖像中的吉布斯現(xiàn)象和噪聲,同時保持高圖像分辨率。
信號可以表示為頻率和相位變化的正弦波的無限和。 MR 圖像通過使用相對較少的 h ARM 電子近似,從而導致吉布斯現(xiàn)象的存在。圖 1 顯示了一個類似的一維情況,即僅用幾個 h ARM 電子近似方波,右側(cè) MRI 模型中的吉布斯現(xiàn)象。
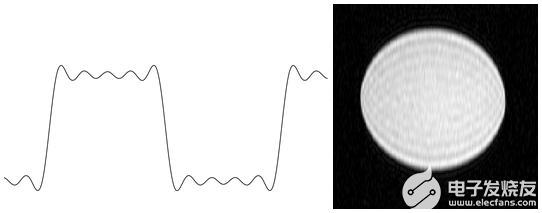
圖 1 。(左)截斷偽影,也稱為吉布斯現(xiàn)象,僅使用五個 h ARM 源近似方波時顯示:Wikipedia. (右)二維 MRI 模型中顯示的吉布斯現(xiàn)象。
數(shù)據(jù)集和模型
我們擴展了現(xiàn)有的用于 Gibbs 和噪聲消除的深度學習方法 dldegibbs 的工作。有關(guān)更多信息,請參閱擴散磁共振成像中 Gibbs 神經(jīng)網(wǎng)絡(luò)的訓練與去噪。該白皮書的代碼在/mmuckley/dldegibbs GitHub repo 中。
在他們的工作中,大約 130 萬張模擬吉布斯現(xiàn)象和高斯噪聲的 ImageNet 圖像被用作訓練數(shù)據(jù)。在我們的項目中,我們測試了 Muckley 等人開發(fā)的一些預訓練 dldegibbs 模型,并使用開放圖像數(shù)據(jù)集訓練了我們自己的模型。我們最后用 MRI 擴散數(shù)據(jù)測試了不同的模型。
為什么要模擬吉布斯現(xiàn)象?
與其他網(wǎng)絡(luò)相比,使用 dldegibbs 的一個好處是它不需要訪問原始 MRI 數(shù)據(jù)和系統(tǒng)參數(shù)。該數(shù)據(jù)很難獲得,因為該數(shù)據(jù)的存儲要求很高,并且在圖像重建后通常不會保留該數(shù)據(jù)。
另一個好處是不需要專有信息或與供應(yīng)商簽署研究協(xié)議。此外,還可以節(jié)省收集和分發(fā)醫(yī)療數(shù)據(jù)的時間,這可能是一項挑戰(zhàn)。使用異構(gòu)數(shù)據(jù)集(如 ImageNet 或 Open Images )對模型進行訓練有可能使該方法應(yīng)用于其他 MRI 序列或成像模式,因為訓練數(shù)據(jù)本質(zhì)上是對象不可知的。
dldegibbs 的數(shù)據(jù)加載程序為每個加載的映像創(chuàng)建兩個映像:一個訓練映像和一個目標映像。在傅里葉域中模擬原始圖像上的吉布斯現(xiàn)象生成訓練圖像。將調(diào)整原始圖像的大小并將其用作目標圖像。數(shù)據(jù)加載程序包括標準數(shù)據(jù)增強方法(隨機翻轉(zhuǎn)、裁剪),然后是隨機相位模擬和橢圓裁剪。接下來,對原始圖像進行 FFT 處理,進行 Gibbs 裁剪,添加復高斯噪聲,并模擬部分傅里葉變換。最后,應(yīng)用逆 FFT 對圖像進行歸一化處理。圖 2 顯示了模擬管道。
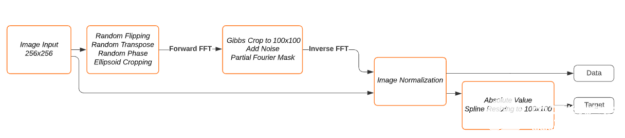
圖 2 。吉布斯現(xiàn)象方框圖與噪聲模擬。
在這個項目中,我們使用了由 170 多萬張訓練圖像組成的開放圖像數(shù)據(jù)集。然后,我們在由 170 名患者( 996424 個軸向切片)[5]組成的磁共振擴散數(shù)據(jù)集上測試訓練模型。圖 3 顯示了一個示例 MRI 擴散切片。
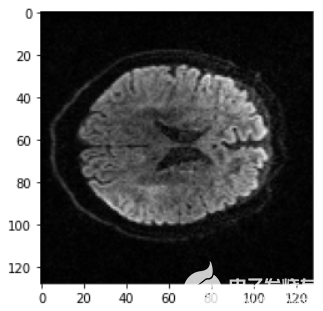
圖 3 。測試集中使用的 MRI 擴散軸向切片示例。
結(jié)果
圖 4 顯示了使用 dldegibbs 模型測試的驗證圖像示例,該模型使用完全開放的圖像訓練數(shù)據(jù)集進行訓練。圖 5 顯示了相應(yīng)的錯誤。訓練圖像在傅里葉空間從 256 × 256 裁剪到 100 × 100 。該模型未模擬部分傅里葉成像。

圖 4 。示例 dldegibbs 輸入(數(shù)據(jù))、輸出(估計)和來自 Open Images 驗證數(shù)據(jù)集的目標圖像。

圖 5 。數(shù)據(jù)輸入和目標之間的誤差(左)和估計輸出和目標之間的誤差(右)。
數(shù)據(jù)與目標之間的平均 MSE 為 13 。 2 ± 9 。 2% 。估計值與目標值之間的平均誤差為 2 。 9 ± 2 。 7% 。對于此圖像, dldegibbs 模型可使圖像質(zhì)量提高 10% 以上。
概括
在這篇文章中,我們提供了一個可以與 Clara AGX 開發(fā)工具包一起使用的解決方案,使用以下資源從 MR 圖像中去除噪聲和吉布斯現(xiàn)象:
一種商用數(shù)據(jù)集,稱為 Open Images
一個開源的 ML 模型,稱為 dldegibbs
關(guān)于作者
Emily Anaya 是 NVIDIA Clara AGX團隊的實習生,致力于消除磁共振成像(MRI)中的吉布斯現(xiàn)象和噪音。她也是一名博士。斯坦福大學電子工程專業(yè)的候選人,她的顧問是克雷格·萊文博士。她的研究重點是解決正電子發(fā)射斷層成像和磁共振成像(PET/MRI)組合中的光子衰減問題。
Emmett McQuinn 是 NVIDIA Clara AGX 團隊的高級工程師。埃米特之前是一家助聽器初創(chuàng)公司的創(chuàng)始工程師,領(lǐng)導機器學習和 DSP 團隊,具有自主機器人、科學可視化和超低功耗神經(jīng)網(wǎng)絡(luò)芯片的工作經(jīng)驗。
審核編輯:郭婷
-
芯片
+關(guān)注
關(guān)注
459文章
51876瀏覽量
433042 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4795瀏覽量
102144 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5181瀏覽量
105357
發(fā)布評論請先 登錄
相關(guān)推薦
交通運輸領(lǐng)先企業(yè)率先采用NVIDIA Cosmos平臺
NPU在深度學習中的應(yīng)用

GPU深度學習應(yīng)用案例
AI大模型與深度學習的關(guān)系
GPU計算主板學習資料第735篇:基于3U VPX的AGX Xavier GPU計算主板 信號計算主板 視頻處理 相機信號
FPGA做深度學習能走多遠?
NVIDIA推出全新深度學習框架fVDB
深度學習模型量化方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論