 如何使用桌面級計算將訓練策略傳輸到遠程機器人中
如何使用桌面級計算將訓練策略傳輸到遠程機器人中
在設計基于機器學習的解決方案時,需要問的一個關鍵問題是,“開發此解決方案的資源成本是多少?”答案通常有很多因素:時間、開發人員技能和計算資源。很少有研究人員能夠最大化所有這些方面,因此優化解決方案開發過程至關重要。這一問題在機器人技術中進一步加劇,因為每項任務通常都需要一個完全獨特的解決方案,其中涉及到專家的大量手工制作。
典型的機器人解決方案需要數周甚至數月的時間來開發和測試。靈巧的多指物體操縱一直是機器人操縱控制和學習領域的一個長期挑戰。
靈巧手法綜述
放松剛性約束:抓取操作的運動學軌跡優化和碰撞避免
學習局部模型的最優控制:在靈巧操作中的應用
具有深度強化學習的靈巧操作:高效、通用和低成本
雖然在過去 5 年中,運動的高維控制以及基于圖像的物體操作(使用簡化的夾持器)方面的挑戰取得了顯著的進展,但多指靈巧操作仍然是一個影響巨大但難以解決的問題。這一挑戰是由以下問題造成的:
高維協調控制
低效的仿真平臺
實際機器人操作中觀測和控制的不確定性
缺乏強健且經濟高效的硬件平臺
這些挑戰加上缺乏大規模計算機和機器人硬件,限制了試圖解決這些問題的團隊的多樣性。
我們在這項工作中的目標是通過大規模仿真和機器人即服務技術,為機器人學習的民主化提供一條道路和可行的解決方案。以靈巧多指機械手為例,重點研究了六自由度物體操縱。我們展示了在桌面級 GPU 和基于云的機器人技術上進行的大規模模擬如何使機器人專家能夠利用有限的資源進行機器人學習方面的研究。
雖然在手工操作方面的一些努力試圖構建健壯的系統,但最令人印象深刻的演示之一是幾年前來自 OpenAI 的一個團隊,該團隊構建了一個名為Dactyl的系統。這是一個令人印象深刻的工程壯舉,以實現多目標在手休息與陰影的手。
然而,它不僅在最終性能上,而且在構建此演示所需的計算量和工程工作量上都是引人注目的。據公眾估計,它使用了 13000 年的計算機,硬件本身成本高昂,但需要反復干預。巨大的資源需求有效地阻止了其他人復制這一結果,并因此在這一結果的基礎上再接再厲。
在這篇文章中,我們展示了我們的系統努力是解決這種資源不平等的途徑。現在,使用單一的臺式機等級 GPU 和 CPU ,在不到一天的時間內即可獲得類似的結果。
強化學習中標準姿勢表示的復雜性
在最初的實驗中,我們遵循以前的工作,提供了基于三維笛卡爾位置加上四維四元數表示的姿勢的觀察,以指定立方體的當前和目標位置。我們還根據 L2 范數(位置)和立方體的期望姿勢和當前姿勢之間的角度差(方向)固定了獎勵。有關更多信息,請參閱學習靈活性 OpenAI 帖子和 GPU – 分布式強化學習的加速機器人仿真。
我們發現這種方法會產生不穩定的獎勵曲線,即使在調整相對權重后,它也能很好地優化獎勵的位置部分。
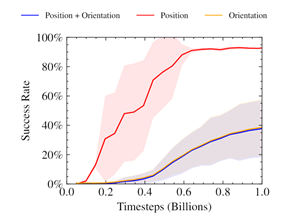
圖 1 。訓練曲線上的三指操縱任務使用獎勵函數類似于以前的作品。獎勵的性質使得政策難以優化,尤其是實現定向目標。
先前的工作已經證明了使用神經網絡時空間旋轉的交替表示的好處。此外,已經證明,這種方式的混合損失會導致只朝著優化單一目標的方向崩潰。該圖表暗示了類似的行為,其中只有職位獎勵被優化。
受此啟發,我們在 SO ( 3 )中為我們的 6 自由度休息問題尋找姿勢表示。這也會自然地通過強化學習以適合優化的方式權衡職位和輪換獎勵。
使用遠程機器人縮小 Sim2Real 差距
獲得物理機器人資源的問題因新冠病毒 -19 大流行而加劇。那些之前有幸在他們的研究小組中接觸到機器人的人發現,能夠接觸到機器人的人數大大減少了。那些依賴其他機構提供硬件的機構往往由于物理距離限制而完全疏遠。
我們的工作證明了機器人即服務( RaaS )方法與機器人學習相結合的可行性。一小隊接受過維護機器人培訓的人員和另一隊研究人員可以上傳一份經過培訓的政策,并遠程收集數據進行后處理。
雖然我們的研究團隊主要在北美,但物理機器人在歐洲。在整個項目期間,我們的開發團隊從來沒有和我們工作的機器人呆在同一個房間里。遠程訪問意味著我們無法改變手頭的任務以使其更容易。它還限制了我們可以進行的迭代和實驗的種類。例如,合理的系統識別是不可能的,因為我們的策略在整個 f ARM 中隨機選擇的機器人上運行。
盡管缺乏物理訪問,但我們發現,我們能夠通過多種技術的組合,制定出一個穩健且有效的策略來解決 6 自由度休息任務:
真實 GPU – 加速仿真
無模型 RL
域隨機化
任務適當的姿勢表示
方法概述
我們的系統使用 NVIDIA V100 或 NVIDIA NVIDIA 3090 RTX 在 16384 個環境中并行使用 GPU 健身房模擬器進行訓練。然后,利用上傳的演員權重,在位于德國大西洋彼岸的三指機器人上遠程進行推理。我們執行 Sim2Real 傳輸的基礎設施由真正的機器人挑戰的組織者提供。
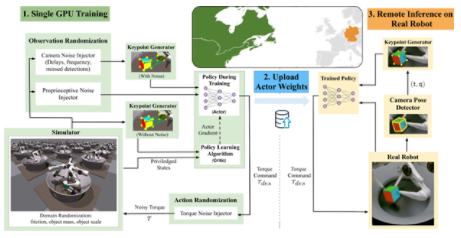
圖 2 。培訓系統流程圖
收集并處理培訓示例
使用 ISAAC 健身房模擬器,我們收集了高通量體驗( NVIDIA RTX 3090 上每秒約 10 萬個樣本)。樣例的對象姿勢和目標姿勢與對象形狀的八個關鍵點對應。將領域隨機化應用于觀測和環境參數,以模擬真實機器人和攝像機本體感受傳感器的變化。這些觀察結果,以及來自模擬器的一些特權狀態信息,然后被用來訓練我們的政策。
培訓政策
我們的策略是使用近端策略優化( PPO )算法來最大化定制獎勵。我們的獎勵激勵政策平衡機器人手指與物體的距離、移動速度以及從物體到指定目標位置的距離。它有效地解決了這項任務,盡管它是一種廣泛適用于手部操作應用的通用公式。該策略輸出每個機器人電機的扭矩,然后將其傳回模擬環境。
將策略轉移到真正的機器人并運行推理
在我們訓練了策略之后,我們將其上傳到真實機器人的控制器。這個立方體是用三個攝像頭在系統上跟蹤的。我們將系統提供的本體感知信息與轉換的關鍵點表示結合起來,為策略提供輸入。我們重復了基于攝像頭的立方體姿勢觀察,以進行后續的策略評估,從而使策略能夠利用機器人可用的更高頻率本體感受數據。然后,從系統收集的數據用于確定策略的成功率。
機器人上的跟蹤系統目前只支持立方體。然而,這在將來可以擴展到任意對象。
Results
姿勢的關鍵點表示大大提高了成功率和收斂性。
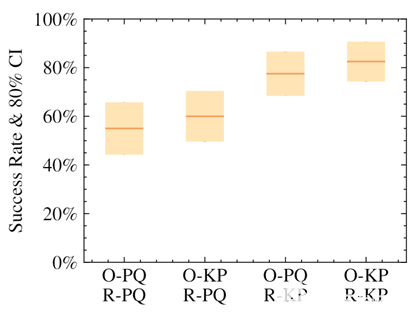
圖 3 。為不同的訓練代理繪制真實機器人的成功率。 O-PQ 和 O-KP 分別表示位置+四元數和關鍵點觀測, R-PQ 和 R-KP 分別表示線性+角度和基于關鍵點的位移。每個平均數 由 N = 40 個試驗和基于 80% 置信區間計算的誤差條組成。
我們證明了使用我們的關鍵點表示法的策略,無論是在提供給策略的觀察中還是在獎勵計算中,都比使用位置+四元數表示法獲得了更高的成功率。最高性能來自于對這兩個元素使用替代表示的策略。
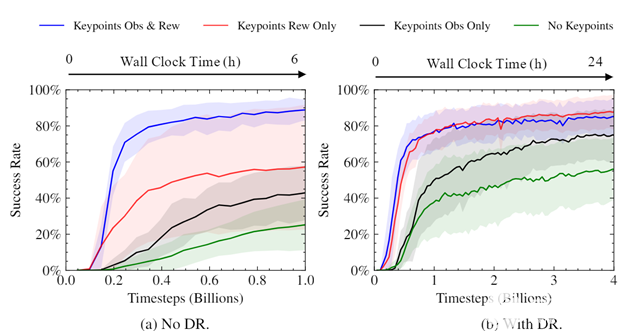
圖 4 。無領域隨機和有領域隨機的訓練過程中的成功率。每條曲線是五個種子的平均值;陰影區域顯示標準偏差。不帶 DR 的培訓將顯示為 1B 步驟,以驗證績效;初始訓練后, DR 的使用對模擬成功率沒有太大影響。
我們進行了實驗,以了解關鍵點的使用如何影響我們經過訓練的策略的速度和收斂水平。可以看出,使用關鍵點作為獎勵的一部分大大加快了培訓,提高了最終成功率,并減少了培訓策略之間的差異。考慮到使用關鍵點作為獎勵的一部分的簡單性和普遍性,差異的大小令人驚訝。
經過培訓的策略可以直接從模擬器部署到遠程真實機器人。
圖 6 顯示了一種我們稱之為“掉落和重新抓取”的緊急行為。在這個動作中,機器人學會在立方體接近正確位置時掉落立方體,重新抓取立方體,然后將其撿起來。這使得機器人能夠在正確的位置穩定地抓住立方體,從而獲得更成功的嘗試。值得注意的是,這段視頻是實時的,不會以任何方式加速。
機器人還學習利用立方體在競技場中正確位置的運動,作為在地面上同時旋轉立方體的機會。這有助于在遠離手指工作區中心的挑戰性目標位置實現正確抓取。
我們的政策也很穩健,有助于降低成本。機器人可以從一個從手上掉下來的立方體中恢復,并從地面上取回它。
對物理和物體變化的魯棒性
我們發現,我們的策略對模擬中環境參數的變化具有魯棒性。例如,它優雅地處理了立方體的上下縮放,其范圍遠遠超過了隨機化。
令人驚訝的是,我們發現我們的策略能夠將 0-shot 推廣到其他對象,例如長方體或球,
由于策略自身的健壯性,在規模和對象上進行了泛化。我們不給它任何形狀信息。關鍵點保持在立方體上的相同位置。
結論
我們的方法通過基于 GPU 的大規模仿真展示了一條可行的機器人學習路徑。在本文中,我們向您展示了如何使用中等水平的計算資源(桌面級計算)來訓練策略,并將其傳輸到遠程機器人。我們還表明,這些策略對環境和被操縱對象中的各種變化具有魯棒性。我們希望我們的工作能夠成為研究人員向前邁進的平臺。
NVIDIA 還宣布廣泛支持具有開放機器人技術的機器人操作系統( ROS )。這一重要的 ISAAC ROS 公告強調了 NVIDIA 人工智能感知技術如何加速人工智能在 ROS 社區的應用,以幫助機器人專家、研究人員和機器人用戶開發、測試和管理下一代基于人工智能的機器人。
關于作者
Varun Lodaya 是多倫多大學計算機科學與統計專業的本科生。他是 PAIR 研究實驗室和病媒研究所的成員。
Animesh Garg 是多倫多大學計算機科學助理教授 CVK3 NVIDIA 的資深研究科學家,也是向量研究所的一名教員。他在加州大學伯克利分校獲得博士學位,是斯坦福人工智能實驗室的博士后。他致力于廣義自治的算法基礎,使基于人工智能的機器人能夠與人類一起工作。他的工作在機器人學和機器學習領域獲得了多項研究獎。
審核編輯:郭婷
-
機器人
+關注
關注
211文章
28524瀏覽量
207558 -
NVIDIA
+關注
關注
14文章
5025瀏覽量
103268 -
gpu
+關注
關注
28文章
4754瀏覽量
129074
發布評論請先 登錄
相關推薦
物理仿真人形機器人的統一全身控制策略







 工商網監
工商網監
評論