") 使用CUDA流順序內(nèi)存分配器助于提高現(xiàn)有應(yīng)用程序的性能
使用CUDA流順序內(nèi)存分配器助于提高現(xiàn)有應(yīng)用程序的性能
在 本系列的第 1 部分 中,我們引入了新的 API 函數(shù) cudaMallocAsync 和 cudaFreeAsync ,它們使內(nèi)存分配和釋放成為流順序操作。在這篇文章中,我們通過分享一些大數(shù)據(jù)基準測試結(jié)果來強調(diào)這一新功能的好處,并為修改現(xiàn)有應(yīng)用程序提供代碼 MIG 定量指南。我們還介紹了在多 GPU 訪問和 IPC 使用環(huán)境中利用流順序內(nèi)存分配的高級主題。這一切都有助于提高現(xiàn)有應(yīng)用程序的性能。
GPU 大數(shù)據(jù)基準
為了衡量新的流式有序分配器在實際應(yīng)用程序中的性能影響,以下是來自 RAPIDS GPU 大數(shù)據(jù)基準 ( GPU -bdb]的結(jié)果。 GPU -bdb 是 30 個查詢的基準,這些查詢以各種比例因子表示現(xiàn)實世界的數(shù)據(jù)科學(xué)和機器學(xué)習(xí)工作流: SF1000 是 1 TB 的數(shù)據(jù), SF10000 是 10 TB 的數(shù)據(jù)。事實上,每個查詢都是一個模型工作流,可以包括 SQL 、用戶定義函數(shù)、仔細的子集和聚合以及機器學(xué)習(xí)。
圖 1 顯示了在 SF1000 上在 NVIDIA DGX-2 上跨 16 個 V100 GPU 執(zhí)行的 gpu-bdb 查詢子集的 cudaMallocAsync 與 cudaMalloc 的性能比較。如您所見,由于內(nèi)存重用和消除無關(guān)同步,使用 cudaMallocAsync 時端到端性能提高了 2-5 倍。
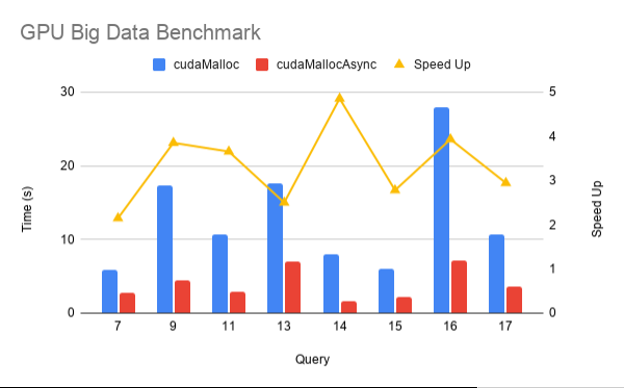
圖 1 加速 cudaMallocAsync 結(jié)束 cudaMalloc 對于 RAPIDS GPU 大數(shù)據(jù)基準的各種查詢 。
與 CUDA Malloc 和 CUDA Free 的互操作性
應(yīng)用程序可以使用 cudaFreeAsync 釋放 cudaMalloc 分配的指針。在下一次同步傳遞到 cudaFreeAsync 的流之前,不會釋放基礎(chǔ)內(nèi)存。
cudaMalloc(&ptr, size); kernel<<<..., stream>>>(ptr); cudaFreeAsync(ptr, stream); cudaStreamSynchronize(stream); // The memory for ptr is freed at this point
類似地,應(yīng)用程序可以使用 cudaFree 釋放使用 cudaMallocAsync 分配的內(nèi)存。但是,在這種情況下, cudaFree 不會隱式同步,因此應(yīng)用程序必須插入適當?shù)耐剑源_保對要釋放的內(nèi)存的所有訪問都已完成。任何有意或無意依賴 cudaFree 的隱式同步行為的應(yīng)用程序代碼都必須更新。
cudaMallocAsync(&ptr, size, stream); kernel<<<..., stream>>>(ptr); cudaStreamSynchronize(stream); // Must synchronize first cudaFree(ptr);
多 – GPU 訪問
默認情況下,可以從與指定流關(guān)聯(lián)的設(shè)備訪問使用 cudaMallocAsync 分配的內(nèi)存。從任何其他設(shè)備訪問內(nèi)存需要啟用從該其他設(shè)備訪問整個池。正如 cudaDeviceCanAccessPeer 所報告的,它還要求這兩個設(shè)備具有對等功能。與 cudaMalloc 分配不同, cudaDeviceEnablePeerAccess 和 cudaDeviceDisablePeerAccess 對從內(nèi)存池分配的內(nèi)存沒有影響。
例如,考慮啟用設(shè)備 4Access 到設(shè)備 3 的內(nèi)存池:
cudaMemPool_t mempool; cudaDeviceGetDefaultMemPool(&mempool, 3); cudaMemAccessDesc desc = {}; desc.location.type = cudaMemLocationTypeDevice; desc.location.id = 4; desc.flags = cudaMemAccessFlagsProtReadWrite; cudaMemPoolSetAccess(mempool, &desc, 1 /* numDescs */);
調(diào)用 cudaMemPoolSetAccess 時,可以使用 cudaMemAccessFlagsProtNone 撤銷對內(nèi)存池所在設(shè)備以外的設(shè)備的訪問。無法撤消對內(nèi)存池自身設(shè)備的訪問。
進程間通信支持
使用與設(shè)備關(guān)聯(lián)的默認內(nèi)存池分配的內(nèi)存不能與其他進程共享。應(yīng)用程序必須顯式創(chuàng)建自己的內(nèi)存池,以便與其他進程共享使用 cudaMallocAsync 分配的內(nèi)存。以下代碼示例顯示如何創(chuàng)建具有進程間通信( IPC )功能的顯式內(nèi)存池:
cudaMemPool_t exportPool;
cudaMemPoolProps poolProps = {};
poolProps.allocType = cudaMemAllocationTypePinned;
poolProps.handleTypes = cudaMemHandleTypePosixFileDescriptor;
poolProps.location.type = cudaMemLocationTypeDevice;
poolProps.location.id = deviceId;
cudaMemPoolCreate(&exportPool, &poolProps);
位置類型設(shè)備和位置 ID deviceId 指示必須在特定 GPU 上分配池內(nèi)存。分配類型 pinted 表示內(nèi)存應(yīng)該是 non-migratable ,也稱為不可分頁。句柄類型 PosixFileDescriptor 表示用戶打算查詢池的文件描述符,以便與其他進程共享。
通過 IPC 共享此池中的內(nèi)存的第一步是查詢表示該池的文件描述符:
int fd; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolExportToShareableHandle(&fd, exportPool, handleType, 0);
然后,應(yīng)用程序可以與另一個進程共享文件描述符,例如通過 UNIX 域套接字。然后,另一個進程可以導(dǎo)入文件描述符并獲得進程本地池句柄:
cudaMemPool_t importPool; cudaMemAllocationHandleType handleType = cudaMemHandleTypePosixFileDescriptor; cudaMemPoolImportFromShareableHandle(&importPool, &fd, handleType, 0);
下一步是導(dǎo)出過程從池中分配內(nèi)存:
cudaMallocFromPoolAsync(&ptr, size, exportPool, stream);
cudaMallocAsync還有一個重載版本,它采用與cudaMallocFromPoolAsync相同的參數(shù):
cudaMallocAsync(&ptr, size, exportPool, stream);
通過這兩個 API 中的任何一個從該池分配內(nèi)存后,指針就可以與導(dǎo)入進程共享。首先,導(dǎo)出過程獲得一個表示內(nèi)存分配的不透明句柄:
cudaMemPoolPtrExportData data; cudaMemPoolExportPointer(&data, ptr);
然后,可以通過任何標準 IPC 機制(例如通過共享內(nèi)存、管道等)與導(dǎo)入進程共享此不透明數(shù)據(jù)。導(dǎo)入進程然后將不透明數(shù)據(jù)轉(zhuǎn)換為進程本地指針:
cudaMemPoolImportPointer(&ptr, importPool, &data);
現(xiàn)在,兩個進程共享對相同內(nèi)存分配的訪問。在導(dǎo)出過程中釋放內(nèi)存之前,必須先在導(dǎo)入過程中釋放內(nèi)存。這是為了確保在導(dǎo)出過程中,當導(dǎo)入過程仍在訪問以前的共享內(nèi)存分配時,內(nèi)存不會重新用于另一個 cudaMallocAsync 請求,從而可能導(dǎo)致未定義的行為。
現(xiàn)有函數(shù) cudaIpcGetMemHandle 僅適用于通過 cudaMalloc 分配的內(nèi)存,不能用于通過 cudaMallocAsync 分配的任何內(nèi)存,無論該內(nèi)存是否從顯式池分配。
更改設(shè)備池
如果應(yīng)用程序期望大部分時間使用顯式內(nèi)存池,則可以考慮通過 cudaDeviceSetMemPool 將其設(shè)置為設(shè)備的當前池。這使應(yīng)用程序可以避免每次必須從池中分配內(nèi)存時都必須指定池參數(shù)。
cudaDeviceSetMemPool(device, pool); cudaMallocAsync(&ptr, size, stream); // This now allocates from the earlier pool set instead of the device’s default pool.
這樣做的好處是,使用 cudaMallocAsync 分配的任何其他函數(shù)現(xiàn)在都會自動使用新池作為默認池。可以使用 cudaDeviceGetMemPool 查詢與設(shè)備關(guān)聯(lián)的當前池。
庫可組合性
通常,庫不應(yīng)該更改設(shè)備的池,因為這樣做會影響整個頂級應(yīng)用程序。如果庫必須分配具有不同于默認設(shè)備池屬性的內(nèi)存,它可以創(chuàng)建自己的池,然后使用 cudaMallocFromPoolAsync 從該池進行分配。該庫還可以使用 cudaMallocAsync 的重載版本,該版本將池作為參數(shù)。
為了使應(yīng)用程序的互操作更容易,庫應(yīng)該考慮為頂級應(yīng)用程序提供 API 以協(xié)調(diào)所使用的池。例如,庫可以提供 set 或 get API ,使應(yīng)用程序能夠以更明確的方式控制池。庫還可以將池作為單個 API 的參數(shù)。
代碼遷移指南
當將使用 cudaMalloc 或 cudaFree 的現(xiàn)有應(yīng)用程序移植到新的 cudaMallocAsync 或 cudaFreeAsync API 時,考慮以下準則。
確定適當人才庫的指南:
初始默認池適用于許多應(yīng)用程序。
今天,顯式構(gòu)造的池只需要在與 CUDA IPC 的進程之間共享池內(nèi)存。這可能會隨著將來的功能而改變。
為了方便起見,考慮將顯式創(chuàng)建池設(shè)置為設(shè)備的當前池,以確保進程內(nèi)的所有 cudaMallocAsync 調(diào)用都使用該池。這必須由頂級應(yīng)用程序而不是庫來完成,以避免與頂級應(yīng)用程序的目標沖突。
為所有內(nèi)存池設(shè)置釋放閾值的準則:
設(shè)備的共享和釋放方式取決于:
對單個進程是獨占的 :使用最大釋放閾值。
在合作進程之間共享 :通過 IPC 協(xié)調(diào)使用相同的池,或?qū)⒚總€進程池設(shè)置為適當?shù)闹担员苊馊魏我粋€進程獨占所有設(shè)備內(nèi)存。
在未知進程之間共享: 如果已知,請將閾值設(shè)置為應(yīng)用程序的工作集大小。否則,在使用非零值之前,請將其保留為零,并使用探查器確定分配性能是否是瓶頸。
用 cudaMallocAsync 替換 cudaMalloc 的指南:
確保所有內(nèi)存訪問都是在流順序分配之后排序的。
如果需要對等訪問,請使用 cudaMemPoolSetAccess ,因為 cudaEnablePeerAccess 和 cudaDisablePeerAccesss 對池內(nèi)存沒有影響。
與 cudaMalloc 分配不同, cudaDeviceReset 不會隱式釋放池內(nèi)存,因此必須顯式釋放。
如果使用 cudaFree 釋放,請確保在釋放之前通過適當?shù)耐酵瓿伤性L問,因為在這種情況下沒有隱式同步。依賴隱式同步的任何后續(xù)代碼也可能需要更新。
如果內(nèi)存通過 IPC 與另一個進程共享,請從顯式創(chuàng)建的支持 IPC 的池中進行分配,并刪除該指針對 cudaIpcGetMemHandle 、 cudaIpcOpenMemHandle 和 cudaIpcCloseMemHandle 的所有引用。
如果該內(nèi)存必須與 GPU 直接 RDMA 一起使用,請暫時繼續(xù)使用 cudaMalloc ,因為通過 cudaMallocAsync 分配的內(nèi)存目前不支持它。 CUDA 打算在將來支持它。
與使用 cudaMalloc 分配的內(nèi)存不同,使用 cudaMallocAsync 分配的內(nèi)存與 CUDA 上下文不關(guān)聯(lián)。這有以下影響:
使用屬性 CU_POINTER_ATTRIBUTE_CONTEXT 調(diào)用 cuPointerGetAttribute 會為上下文返回 null 。
當使用至少一個使用 cudaMallocAsync 分配的源或目標指針調(diào)用 cudaMemcpy 時,必須可以從調(diào)用線程的當前上下文/設(shè)備訪問該內(nèi)存。如果無法從該上下文或設(shè)備訪問,請改用 cudaMemcpyPeer 。
將 cudaFree 替換為 cudaFree 的指南
確保所有內(nèi)存訪問都是在按流排序的釋放之前排序的。
在下一次同步操作之前,可能無法將內(nèi)存釋放回系統(tǒng)。如果釋放閾值設(shè)置為非零值,則在顯式修剪相應(yīng)的池之前,可能無法將內(nèi)存釋放回系統(tǒng)。
與 cudaFree 不同, cudaFreeAsync 不會隱式同步設(shè)備。任何依賴此隱式同步的代碼都必須更新為顯式同步。
結(jié)論
CUDA 11 。 2 中添加的流式有序分配器以及 cudaMallocAsync 和 cudaFreeAsync API 函數(shù)通過將內(nèi)存分配和釋放作為流式有序操作引入 CUDA 流編程模型,擴展了 CUDA 流編程模型。這使得分配的范圍能夠限定到內(nèi)核,內(nèi)核使用它們,同時避免了傳統(tǒng) cudaMalloc/cudaFree 可能發(fā)生的昂貴的設(shè)備范圍同步。
此外,這些 API 函數(shù)在 CUDA 中添加了內(nèi)存池的概念,從而實現(xiàn)了內(nèi)存的重用,從而避免了代價高昂的系統(tǒng)調(diào)用并提高了性能。使用指南 MIG 評估您現(xiàn)有的代碼,并查看您的應(yīng)用程序性能有多大改進!
關(guān)于作者
Vivek Kini 是 NVIDIA 的高級系統(tǒng)軟件工程師。他致力于 CUDA 驅(qū)動程序,特別關(guān)注內(nèi)存管理功能。他旨在簡化 CUDA 應(yīng)用程序的內(nèi)存管理,而不犧牲它們所需的性能。
Jake Hemstad 是一個高級開發(fā)工程師 NVIDIA ,他在開發(fā)高性能 CUDA C ++軟件加速數(shù)據(jù)分析。他同樣關(guān)心開發(fā)高質(zhì)量的軟件,正如他實現(xiàn)最佳的 GPU 性能一樣,也是現(xiàn)代 C ++設(shè)計的倡導(dǎo)者。在 NVIDIA 之前,他參加了明尼蘇達大學(xué)的研究生院,在那里他與桑迪亞國家實驗室在任務(wù)并行 HPC 運行時間和稀疏線性求解器上工作。
審核編輯:郭婷
-
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129131 -
API
+關(guān)注
關(guān)注
2文章
1507瀏覽量
62215 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13644
發(fā)布評論請先 登錄
相關(guān)推薦
PS2-185/NF帶狀線2路電源分配器
英邁質(zhì)譜流路分配器:精準控制,引領(lǐng)質(zhì)譜分析新高度
CDCL1810A 1.8V、10 輸出高性能時鐘分配器數(shù)據(jù)表

CDCL1810 1.8V 10路輸出高性能時鐘分配器數(shù)據(jù)表
CDCE18005高性能時鐘分配器數(shù)據(jù)表
CDCE62005高性能時鐘發(fā)生器和分配器數(shù)據(jù)表
LMK01000高性能時鐘緩沖器、分頻器和分配器數(shù)據(jù)表
液壓分配器起什么作用的
液壓分配器工作原理是什么
液壓分配器壓力調(diào)整方法有哪些
單線分配器與雙線分配器的區(qū)別是什么
四路數(shù)據(jù)分配器的基本概念、工作原理、應(yīng)用場景及設(shè)計方法
八路數(shù)據(jù)分配器的基本概念及工作原理
Linux內(nèi)核內(nèi)存管理之slab分配器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論