") 在近實(shí)時(shí)智能控制器中實(shí)現(xiàn)GPU加速
在近實(shí)時(shí)智能控制器中實(shí)現(xiàn)GPU加速
發(fā)現(xiàn) COVID-19 疫苗所花的時(shí)間證明了醫(yī)療行業(yè)的創(chuàng)新步伐。創(chuàng)新的步伐可以直接聯(lián)系到蓬勃發(fā)展的創(chuàng)新者生態(tài)系統(tǒng)和大量基于人工智能的醫(yī)療保健初創(chuàng)公司。相比之下, 5G 無(wú)線(xiàn)產(chǎn)業(yè)引進(jìn)下一代系統(tǒng)大約需要十年時(shí)間。
O-RAN 聯(lián)盟是解決創(chuàng)新速度和部署后功能增強(qiáng)問(wèn)題的一種先驅(qū)。不透明設(shè)計(jì)的傳統(tǒng)模式正在被具有開(kāi)放和標(biāo)準(zhǔn)化界面的透明范式所打破。忘記使用封閉和專(zhuān)有的接口,以及為生態(tài)系統(tǒng)提供有限的選項(xiàng),以便將新功能引入已部署的設(shè)備。
新的范例包括諸如 RAN 智能控制器( RIC )之類(lèi)的概念, RIC 是一項(xiàng)關(guān)鍵技術(shù),它使第三方能夠向網(wǎng)絡(luò)添加新功能。這不僅為開(kāi)發(fā)者生態(tài)系統(tǒng),也為網(wǎng)絡(luò)運(yùn)營(yíng)商提供了賺錢(qián)的機(jī)會(huì)。
無(wú)線(xiàn)的未來(lái)
軟件化、虛擬化和分散化是 5G 及以上通信網(wǎng)絡(luò)的一些基本概念。 RAN 的軟件化及其使用軟件無(wú)線(xiàn)電( SDR )范式的實(shí)現(xiàn)對(duì)于支持 5G 的三個(gè)關(guān)鍵用例至關(guān)重要:
增強(qiáng)型移動(dòng)寬帶( eMBB )
超可靠低延遲通信( URLLC )
大規(guī)模機(jī)器類(lèi)型通信( mMTC )
4G 和 5G 之間的一個(gè)關(guān)鍵區(qū)別在于,通過(guò)軟件,能夠動(dòng)態(tài)地啟動(dòng)和拆除由 eMBB 、 URLLC 和 mMTC 流組成的網(wǎng)絡(luò)片。事實(shí)上,這是 5G 的核心價(jià)值主張。
虛擬化是在移動(dòng)邊緣計(jì)算( MEC )中高效共享硬件和軟件資產(chǎn)以支持異構(gòu)工作負(fù)載的一個(gè)促成因素。分解代表了無(wú)線(xiàn)產(chǎn)業(yè)新生態(tài)系統(tǒng)的曙光。它為廣大的 spe CTR um 和新一代硬件開(kāi)發(fā)人員打開(kāi)了新的商機(jī)之門(mén)。
傳統(tǒng)的、單片的、不透明的無(wú)線(xiàn)基礎(chǔ)設(shè)施設(shè)備被分解為集中式單元( CU )、分布式單元( DU )和無(wú)線(xiàn)單元( RU )的邏輯實(shí)體。這使得傳統(tǒng)網(wǎng)絡(luò)和新興的專(zhuān)用 5G 網(wǎng)絡(luò)運(yùn)營(yíng)商能夠靈活地定制系統(tǒng)架構(gòu),以滿(mǎn)足其運(yùn)營(yíng)和業(yè)務(wù)需求。
這種無(wú)線(xiàn)網(wǎng)絡(luò)基礎(chǔ)設(shè)施新方法的一個(gè)同樣重要的組成部分是硬件和軟件子系統(tǒng)之間物理和邏輯接口的標(biāo)準(zhǔn)化。隨著開(kāi)放軟件棧的開(kāi)發(fā),這些功能使得能夠通過(guò)軟件快速部署新的網(wǎng)絡(luò)功能。它們還使新一代軟件生態(tài)系統(tǒng)開(kāi)發(fā)人員能夠編寫(xiě)應(yīng)用程序代碼,以便在網(wǎng)絡(luò)中部署。這些應(yīng)用程序通過(guò)這些標(biāo)準(zhǔn)化的接口和 api ,促進(jìn)了對(duì) CU 、 DU 和 RU 中運(yùn)行的實(shí)體的控制和交互。
RAN 智能控制器
O-RAN 聯(lián)盟正在標(biāo)準(zhǔn)化一個(gè)開(kāi)放的、智能的、可分解的 RAN 體系結(jié)構(gòu)。 目標(biāo)是使用 COTS 硬件構(gòu)建運(yùn)營(yíng)商定義的 RAN ,并為 5G 和未來(lái)一代 6G 無(wú)線(xiàn)網(wǎng)絡(luò)提供基于 AI / ML 的智能控制。將使用專(zhuān)有硬件、接口和軟件構(gòu)建的傳統(tǒng) RAN 替換為使用 COTS 硬件和開(kāi)放接口的 VRAN 。新的體系結(jié)構(gòu)可以選擇支持專(zhuān)有軟件和生態(tài)系統(tǒng)開(kāi)發(fā)的應(yīng)用程序。
O-RAN 標(biāo)準(zhǔn)最重要的元素之一是圖 1 所示的 RAN 智能控制器( RIC )。 RIC 由兩個(gè)主要組件組成:
非實(shí)時(shí) RIC ( Non-RT RIC ):支持時(shí)間尺度大于 1 秒的網(wǎng)絡(luò)功能。
近實(shí)時(shí) RIC (近實(shí)時(shí) RIC ):支持以 10 毫秒 -1 秒的時(shí)間尺度運(yùn)行的函數(shù)。
作為 SMO 框架的一部分,非 RT RIC 的一些職責(zé)包括 ML 模型生命周期管理和 ML 模型選擇。它還包括對(duì)從 CU 、 DU 甚至 RU 收集的數(shù)據(jù)進(jìn)行編組、整理和預(yù)處理,為在訓(xùn)練主機(jī)上進(jìn)行模型訓(xùn)練做準(zhǔn)備。
O-RAN 架構(gòu)中引入的近 RT-RIC 為系統(tǒng)帶來(lái)了軟件定義的智能。它包括對(duì) CU 和 DU 數(shù)據(jù)流的高級(jí)近實(shí)時(shí)分析、 AI 模型推理和機(jī)器學(xué)習(xí)( ML )模型的在線(xiàn)再培訓(xùn)。
SMO 、 Non-RT-RIC 和 Near-RT-RIC 共同將 ML 技術(shù)引入到網(wǎng)絡(luò)體系結(jié)構(gòu)的所有層:第 1 層 PHY 、第 2 層,以及通過(guò)基于 AI 的自組織網(wǎng)絡(luò)( SoN )功能在網(wǎng)絡(luò)級(jí)別本身。
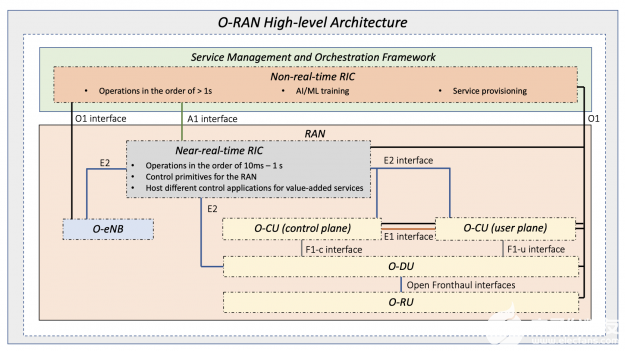
圖 1 。 O-RAN RIC 體系結(jié)構(gòu)由非 RT RIC 、近 RT RIC 和這些軟件實(shí)體之間的各種接口組成。這些接口允許從 CU 、 DU 和 RU 中進(jìn)行控制、配置和數(shù)據(jù)提取。 來(lái)源: 開(kāi)放、可編程和虛擬化 5G 網(wǎng)絡(luò):現(xiàn)狀和未來(lái)之路 。
為了幫助更詳細(xì)地理解 RIC ,請(qǐng)考慮一個(gè) LTE 示例。該方法類(lèi)似于 5G NR 。該示例通過(guò)使用長(zhǎng) – 短期記憶( LSTM )業(yè)務(wù)預(yù)測(cè)模型,使用支持 RIC 的 AI 進(jìn)行小區(qū)容量管理。其目標(biāo)是預(yù)測(cè)網(wǎng)絡(luò)中所有小區(qū)的通信量并緩解未來(lái)的擁塞。有關(guān)更多信息,請(qǐng)參閱 超 5G 和 6G 無(wú)線(xiàn)網(wǎng)絡(luò)的智能 O-RAN 。
兩層 LSTM 網(wǎng)絡(luò)每層使用 12 個(gè) LSTM 單元。它是在一個(gè)真實(shí)的、完全可操作的無(wú)線(xiàn)網(wǎng)絡(luò)中使用來(lái)自 17 個(gè) LTE enb 的 UE 吞吐量測(cè)量和物理資源塊( PRB )利用率來(lái)訓(xùn)練的。推斷操作預(yù)測(cè)未來(lái) 1 小時(shí)內(nèi) UE 吞吐量和 eNB 下行鏈路 PRB 利用率。
圖 2 顯示了一個(gè) eNB 的一個(gè)小區(qū)的吞吐量和 PRB 利用率的基本事實(shí)(實(shí)際)和預(yù)測(cè)( LSTM 推斷)。平均預(yù)測(cè)準(zhǔn)確率為 92 。 64% 。由于能夠預(yù)測(cè)未來(lái) 1 小時(shí)內(nèi)的小區(qū)負(fù)荷, eNB 可以采取措施避免覆蓋中斷,例如小區(qū)分裂。
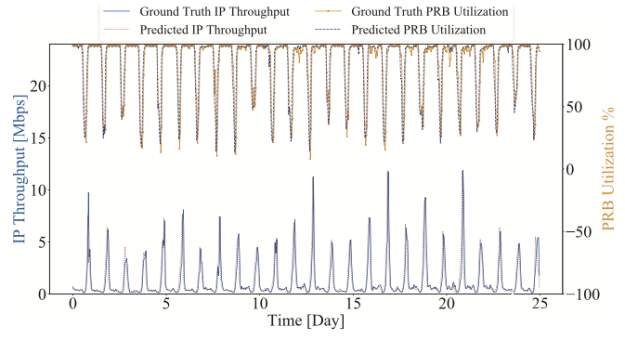
圖 2 。網(wǎng)絡(luò)中所選 eNB 的小區(qū)的用戶(hù)感知 IP 吞吐量和 PRB 利用率預(yù)測(cè)。 來(lái)源: 超 5G 和 6G 無(wú)線(xiàn)網(wǎng)絡(luò)的智能 O-RAN 。
在本例中, SMO 的作用是通過(guò) O1 接口(圖 1 )從 O-CU / DU 收集數(shù)據(jù)并將其傳送到非 RT RIC 。非 RT-RIC rApp 反過(guò)來(lái)查詢(xún)與 SMO 相關(guān)聯(lián)的 AI 服務(wù)器。 AI 服務(wù)器運(yùn)行一個(gè)訓(xùn)練過(guò)程,根據(jù)從操作網(wǎng)絡(luò)收集的新數(shù)據(jù)更新 LSTM 模型參數(shù)。
從編程模型和計(jì)算能力的角度來(lái)看, gpu 是 ML 訓(xùn)練的自然選擇。無(wú)線(xiàn)網(wǎng)絡(luò)規(guī)模龐大,訓(xùn)練工作量大。 我們不感興趣的模型訓(xùn)練為一個(gè)單一的 eNB 與幾個(gè)細(xì)胞。相反,我們感興趣的是培訓(xùn)一個(gè)系統(tǒng),它可以有 100 到 1000 個(gè)基站,有 1000 個(gè)小區(qū)和 1000 到 10000 個(gè)用戶(hù)終端。擁有一個(gè) GPU 支持的人工智能培訓(xùn)服務(wù)器,就可以在許多 SMO 主機(jī)上共享基礎(chǔ)設(shè)施。它比 CPU 人工智能培訓(xùn)主機(jī)更具成本和能效。換言之,網(wǎng)絡(luò)運(yùn)營(yíng)商既有資本支出優(yōu)勢(shì),也有運(yùn)營(yíng)支出優(yōu)勢(shì)。
在訓(xùn)練服務(wù)器更新 LSTM 模型之后,更新的模型參數(shù)被返回到非 RT-RIC rApp ,并且吞吐量/ PRB 預(yù)測(cè)過(guò)程繼續(xù)使用更新的模型。圖 3 顯示了吞吐量增益。縱軸顯示每個(gè)頻段的用戶(hù)吞吐量在橫軸上表示的工作小時(shí)數(shù)的分?jǐn)?shù)。
例如,您可以看到,在沒(méi)有小區(qū)分裂的情況下,吞吐量在 5-7 。 5 Mbps 的范圍內(nèi)大約有 1% 的時(shí)間。通過(guò)預(yù)測(cè)細(xì)胞分裂,吞吐量在相同的范圍內(nèi)大約為 10% ,相差 10 倍。
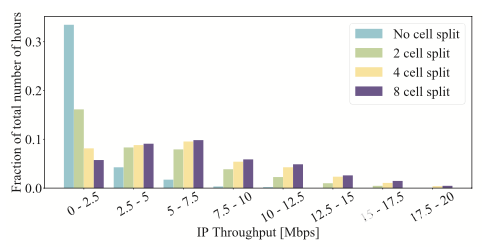
圖 3 。不同小區(qū)分裂配置的用戶(hù)吞吐量。 來(lái)源: 超 5G 和 6G 無(wú)線(xiàn)網(wǎng)絡(luò)的智能 O-RAN 。
NVIDIA 正在研究的 xApp 是實(shí)現(xiàn)智能和預(yù)測(cè)的多小區(qū)聯(lián)合資源管理。這有可能顯著提高網(wǎng)絡(luò)的能源效率。
在非 RT-RIC 上運(yùn)行的 AI 算法可以在一個(gè)預(yù)測(cè)窗口內(nèi)(以秒到分鐘的時(shí)間尺度)預(yù)測(cè)每個(gè)小區(qū)的用戶(hù)密度和流量負(fù)載。預(yù)測(cè)基于 CUs 和 DUs 提供的交通歷史。每個(gè) DU 調(diào)度器都會(huì)做出關(guān)閉某些具有低預(yù)測(cè)流量負(fù)載的小區(qū)的決定,以降低能耗。它們還觸發(fā)來(lái)自相鄰活動(dòng)小區(qū)的協(xié)調(diào)多點(diǎn)傳輸/接收( CoMP ),以確保有效覆蓋。
近 RT-RIC 有助于在同一頻段上實(shí)現(xiàn) eMBB 和 URLLC 數(shù)據(jù)業(yè)務(wù)的高效復(fù)用。由于服務(wù)需求的顯著差異, eMBB 和 URLLC 傳輸被安排在兩個(gè)不同的時(shí)間尺度上: eMBB 和 URLLC 的時(shí)隙和小時(shí)隙級(jí)別。
位于近 RT RIC 的基于 AI 的 xApp 可以根據(jù)從 DU 通過(guò) E2 接口傳輸?shù)牧髁拷y(tǒng)計(jì)信息來(lái)學(xué)習(xí)和預(yù)測(cè) URLLC 數(shù)據(jù)包到達(dá)模式(圖 1 )。在 DU 調(diào)度器中使用這種預(yù)測(cè)知識(shí)來(lái)優(yōu)化 eMBB 數(shù)據(jù)流之上的 URLLC 小時(shí)隙的資源預(yù)留。它還用于最小化這種多路復(fù)用造成的 eMBB 吞吐量損失。
您還可以設(shè)想一個(gè) xApp 用于大規(guī)模 MIMO 波束形成優(yōu)化,以最大限度地提高 spe CTR al 效率。在這種情況下,非 RT-RIC 承載 rApp 以執(zhí)行長(zhǎng)期數(shù)據(jù)分析。 rApp 的任務(wù)是收集和分析天線(xiàn)陣列參數(shù),并不斷更新 ML 模型。近 RT-ricxapp 正在實(shí)現(xiàn) ML 推斷以配置例如波束水平和垂直孔徑以及單元形狀。
為什么是 GPU ?
5G NR 物理層的信號(hào)處理需求( MACs /秒)是巨大的。 GPU 的大規(guī)模并行性帶來(lái)了能夠支持這類(lèi)工作負(fù)載的硬件資源。事實(shí)上,一個(gè) GPU 可以支持許多 10s 載波的基帶處理需求。上一代系統(tǒng)通常采用專(zhuān)用硬件加速器。然而, GPU 的并行性通過(guò)提供高級(jí)編程信號(hào)處理算法的 C ++抽象來(lái)實(shí)現(xiàn) RAN 的軟件化。
然而, GPU 的價(jià)值超出了 vRAN 信號(hào)處理。在大數(shù)據(jù)與無(wú)線(xiàn)結(jié)合的 5G 和 6G 系統(tǒng)中, AI / ML 用于提高網(wǎng)絡(luò)性能, GPU 是模型訓(xùn)練和推理的默認(rèn)標(biāo)準(zhǔn)。
一個(gè)通用的基于 GPU 的硬件平臺(tái)可以支持訓(xùn)練、推理和信號(hào)處理等任務(wù)。然而,這不僅僅是關(guān)于 GPU 硬件。一個(gè)同樣重要的考慮因素是用于編程 gpu 和 sdk 的軟件以及用于應(yīng)用程序開(kāi)發(fā)的庫(kù)。
gpu 是使用 CUDA 編程的, ZCK0 是世界上唯一商業(yè)上成功的基于 C / C ++的并行編程框架。還有一組豐富的 GPU 庫(kù),用于開(kāi)發(fā)使用 NVIDIA RAPIDS 軟件套件的數(shù)據(jù)分析管道。數(shù)據(jù)分析管道可以是 SMO /非 RT RIC 用于更新和微調(diào)在近 RT RIC 下運(yùn)行的推理模型的服務(wù)之一。
VMware 和 NVIDIA 合作伙伴關(guān)系
在 2021 年初, VMware 發(fā)布了世界上第一個(gè)符合 O-RAN 標(biāo)準(zhǔn)的近 RT RIC ,用于與選定的 RAN 和 xApp 供應(yīng)商合作伙伴進(jìn)行集成和測(cè)試。為了便于在其近 RT-RIC 上開(kāi)發(fā) xApp , VMware 向其 xApp 合作伙伴提供了一組打包為 SDK 的開(kāi)發(fā)人員資源。
今天, VMware 和 NVIDIA 興奮地宣布,近乎 RT 的 RIC SDK 現(xiàn)在使 xApp 開(kāi)發(fā)人員能夠在其應(yīng)用程序中利用 GPU 加速。這是業(yè)界一個(gè)激動(dòng)人心的里程碑。它為更大的行業(yè)打開(kāi)了大門(mén),為現(xiàn)代 RAN 構(gòu)建 AI / ML 動(dòng)力能力,包括那些基于 NVIDIA 空中 gNB 堆棧的能力。最終, VMware RIC 和 NVIDIA 空中堆棧的組合將支持新的和創(chuàng)新的 XAPP 的開(kāi)發(fā)和貨幣化,以增強(qiáng)或擴(kuò)展已部署網(wǎng)絡(luò)的能力。
結(jié)論
開(kāi)放性和智能性是 O-RAN 計(jì)劃的兩大核心支柱。隨著 5G 的推出和 6G 研究的不斷深入,無(wú)線(xiàn)網(wǎng)絡(luò)的部署、優(yōu)化和運(yùn)行的智能將是無(wú)所不包的。
從蜂窩網(wǎng)絡(luò)歷史上采用的不透明方法轉(zhuǎn)變?yōu)榭焖賱?chuàng)新和新 RAN 功能上市的新時(shí)代打開(kāi)了大門(mén)。 NVIDIA vRAN ( NVIDIA AIR )和 AI 技術(shù),結(jié)合 VMware RIC ,將培育新一代無(wú)線(xiàn)技術(shù),開(kāi)辟新的盈利和創(chuàng)新機(jī)會(huì)。
關(guān)于作者
Rakesh Misra 博士是 VMware 服務(wù)提供商和邊緣業(yè)務(wù)部門(mén)的研發(fā)總監(jiān)。在加入 VMware 之前,他與人共同創(chuàng)建了 Uhana 公司,該公司為移動(dòng)無(wú)線(xiàn)接入網(wǎng)( RAN )商業(yè)化了一個(gè) AI / ML 供電的可觀(guān)察性和優(yōu)化平臺(tái)。 Uhana 于 2019 年被 VMware 收購(gòu)。在 VMware ,他領(lǐng)導(dǎo) VMware 開(kāi)放 RAN 平臺(tái)的體系結(jié)構(gòu)和開(kāi)發(fā),以及 RAN 應(yīng)用程序生態(tài)系統(tǒng)的創(chuàng)建。他有博士學(xué)位。來(lái)自斯坦福大學(xué)和 B 。 Tea 。和 M 。 Tech 。來(lái)自印度技術(shù)學(xué)院( IIT )馬德拉斯,全是電子工程專(zhuān)業(yè)。
Chris Dick 博士是 NVIDIA 的無(wú)線(xiàn)架構(gòu)師,也是將人工智能和機(jī)器學(xué)習(xí)應(yīng)用于 5G 和 6G 無(wú)線(xiàn)的技術(shù)負(fù)責(zé)人。在從事信號(hào)處理和通信的 24 年中,他為 3G 、 4G 和 5G 基帶 DSP 和 Docsis 3 。 1 電纜接入提供了硅和軟件產(chǎn)品。他為蜂窩系統(tǒng)的數(shù)字前端( DFE )技術(shù)進(jìn)行了研究并交付了產(chǎn)品,特別強(qiáng)調(diào)用于功率放大器線(xiàn)性化的數(shù)字預(yù)失真。 Chris 還廣泛研究了計(jì)算機(jī)視覺(jué)中機(jī)器學(xué)習(xí)的體系結(jié)構(gòu)和編譯器。在 1998 年搬到硅谷之前,他在澳大利亞墨爾本做了 13 年的終身學(xué)者。他擁有超過(guò) 150 份出版物和 70 項(xiàng)專(zhuān)利,是 Santa Clara 大學(xué)的兼職教授,他在那里教了 18 年的實(shí)時(shí)信號(hào)處理和機(jī)器學(xué)習(xí)課程。 2018 年,他因全雙工無(wú)線(xiàn)通信研究獲得 IEEE 通信學(xué)會(huì)通信進(jìn)步獎(jiǎng)。
Soma Velayutham 是 NVIDIA 電信業(yè)的全球行業(yè)業(yè)務(wù)開(kāi)發(fā)負(fù)責(zé)人,他向電信和 5G 無(wú)線(xiàn)通信宣傳人工智能的采用和加速計(jì)算。他是一位成功的內(nèi)部企業(yè)家和產(chǎn)品領(lǐng)導(dǎo)者,在軟件和高科技行業(yè)擁有 20 多年的經(jīng)驗(yàn)。他在全球?yàn)榇蠊痉趸屯瞥隽硕喾N軟件產(chǎn)品。他還是早期創(chuàng)業(yè)公司和斯坦福孵化計(jì)劃 iFarm 的導(dǎo)師。 Soma 擁有從產(chǎn)品戰(zhàn)略到研發(fā)的完整產(chǎn)品生命周期經(jīng)驗(yàn)。
Yan Huang 目前是 NVIDIA 的系統(tǒng)軟件工程師。他獲得了博士學(xué)位。 2020 年獲得弗吉尼亞理工大學(xué)電子工程學(xué)位,從事 NVIDIA 空中 5G vRAN 系統(tǒng)的研究,并研究機(jī)器學(xué)習(xí)和 GPU 在下一代通信系統(tǒng)中的應(yīng)用。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5039瀏覽量
103309 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8428瀏覽量
132821 -
5G
+關(guān)注
關(guān)注
1355文章
48480瀏覽量
564953
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU加速云服務(wù)器怎么用的
自動(dòng)控制系統(tǒng)在智能制造中的應(yīng)用
《CST Studio Suite 2024 GPU加速計(jì)算指南》
德州儀器推出兩個(gè)全新系列實(shí)時(shí)微控制器
GPU加速計(jì)算平臺(tái)是什么
FPGA在人工智能中的應(yīng)用有哪些?
ARMxy系列控制器:在智能網(wǎng)關(guān)中實(shí)現(xiàn)數(shù)據(jù)采集
組合邏輯控制器是用什么實(shí)現(xiàn)的
PID控制器在工業(yè)自動(dòng)化中的應(yīng)用
開(kāi)關(guān)控制器在智能設(shè)備中的應(yīng)用
IGBT在電機(jī)控制器中的應(yīng)用
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
開(kāi)放式高實(shí)時(shí)高性能PLC控制器解決方案-基于米爾電子STM32MP135
在TC387微控制器上實(shí)現(xiàn)內(nèi)存映射,負(fù)載增加的原因是什么?
集中電源控制器在智能家居中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論