 支持動態并行的CUDA擴展功能和最佳應用實踐
支持動態并行的CUDA擴展功能和最佳應用實踐
D.1. Introduction
D.1.1. Overview
Dynamic Parallelism是 CUDA 編程模型的擴展,使 CUDA 內核能夠直接在 GPU 上創建新工作并與新工作同步。在程序中需要的任何位置動態創建并行性提供了令人興奮的新功能。
直接從 GPU 創建工作的能力可以減少在主機和設備之間傳輸執行控制和數據的需要,因為現在可以通過在設備上執行的線程在運行時做出啟動配置決策。此外,可以在運行時在內核內內聯生成依賴于數據的并行工作,動態利用 GPU 的硬件調度程序和負載平衡器,并根據數據驅動的決策或工作負載進行調整。以前需要修改以消除遞歸、不規則循環結構或其他不適合平面、單級并行性的構造的算法和編程模式可以更透明地表達。
本文檔描述了支持動態并行的 CUDA 的擴展功能,包括為利用這些功能而對 CUDA 編程模型進行必要的修改和添加,以及利用此附加功能的指南和最佳實踐。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
只有計算能力為 3.5 或更高的設備支持動態并行。
D.1.2. Glossary
本指南中使用的術語的定義。
Grid:網格是線程的集合。網格中的線程執行內核函數并被劃分為線程。
Thread Block:線程塊是在同一多處理器 (SM) 上執行的一組線程。線程塊中的線程可以訪問共享內存并且可以顯式同步。
Kernel Function:內核函數是一個隱式并行子程序,它在 CUDA 執行和內存模型下為網格中的每個線程執行。
Host:Host 指的是最初調用 CUDA 的執行環境。通常是在系統的 CPU 處理器上運行的線程。
Parent:父線程、線程塊或網格是已啟動新網格、子網格的一種。直到所有啟動的子網格也完成后,父節點才被視為完成。
Child:子線程、塊或網格是由父網格啟動的線程、塊或網格。子網格必須在父線程、線程塊或網格被認為完成之前完成。
Thread Block Scope:具有線程塊作用域的對象具有單個線程塊的生命周期。它們僅在由創建對象的線程塊中的線程操作時具有定義的行為,并在創建它們的線程塊完成時被銷毀。
Device Runtime:設備運行時是指可用于使內核函數使用動態并行的運行時系統和 API。
D.2. Execution Environment and Memory Model
D.2.1. Execution Environment
CUDA 執行模型基于線程、線程塊和網格的原語,內核函數定義了線程塊和網格內的各個線程執行的程序。 當調用內核函數時,網格的屬性由執行配置描述,該配置在 CUDA 中具有特殊的語法。 CUDA 中對動態并行性的支持擴展了在新網格上配置、啟動和同步到設備上運行的線程的能力。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize() 塊)在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
D.2.1.1. Parent and Child Grids
配置并啟動新網格的設備線程屬于父網格,調用創建的網格是子網格。
子網格的調用和完成是正確嵌套的,這意味著在其線程創建的所有子網格都完成之前,父網格不會被認為是完整的。 即使調用線程沒有在啟動的子網格上顯式同步,運行時也會保證父子網格之間的隱式同步。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
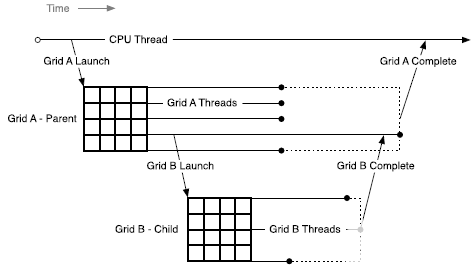
D.2.1.2. Scope of CUDA Primitives
在主機和設備上,CUDA 運行時都提供了一個 API,用于啟動內核、等待啟動的工作完成以及通過流和事件跟蹤啟動之間的依賴關系。 在主機系統上,啟動狀態和引用流和事件的 CUDA 原語由進程內的所有線程共享; 但是進程獨立執行,可能不共享 CUDA 對象。
設備上存在類似的層次結構:啟動的內核和 CUDA 對象對線程塊中的所有線程都是可見的,但在線程塊之間是獨立的。 這意味著例如一個流可以由一個線程創建并由同一線程塊中的任何其他線程使用,但不能與任何其他線程塊中的線程共享。
D.2.1.3. Synchronization
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
來自任何線程的 CUDA 運行時操作,包括內核啟動,在線程塊中都是可見的。 這意味著父網格中的調用線程可以在由該線程啟動的網格、線程塊中的其他線程或在同一線程塊中創建的流上執行同步。 直到塊中所有線程的所有啟動都完成后,才認為線程塊的執行完成。 如果一個塊中的所有線程在所有子啟動完成之前退出,將自動觸發同步操作。
D.2.1.4. Streams and Events
CUDA 流和事件允許控制網格啟動之間的依賴關系:啟動到同一流中的網格按順序執行,事件可用于創建流之間的依賴關系。 在設備上創建的流和事件服務于這個完全相同的目的。
在網格中創建的流和事件存在于線程塊范圍內,但在創建它們的線程塊之外使用時具有未定義的行為。 如上所述,線程塊啟動的所有工作在塊退出時都會隱式同步; 啟動到流中的工作包含在其中,所有依賴關系都得到了適當的解決。 已在線程塊范圍之外修改的流上的操作行為未定義。
在主機上創建的流和事件在任何內核中使用時具有未定義的行為,就像在子網格中使用時由父網格創建的流和事件具有未定義的行為一樣。
D.2.1.5. Ordering and Concurrency
從設備運行時啟動內核的順序遵循 CUDA Stream 排序語義。在一個線程塊內,所有內核啟動到同一個流中都是按順序執行的。當同一個線程塊中的多個線程啟動到同一個流中時,流內的順序取決于塊內的線程調度,這可以通過 __syncthreads() 等同步原語進行控制。
請注意,由于流由線程塊內的所有線程共享,因此隱式 NULL 流也被共享。如果線程塊中的多個線程啟動到隱式流中,則這些啟動將按順序執行。如果需要并發,則應使用顯式命名流。
動態并行使并發在程序中更容易表達;但是,設備運行時不會在 CUDA 執行模型中引入新的并發保證。無法保證設備上任意數量的不同線程塊之間的并發執行。
缺乏并發保證延伸到父線程塊及其子網格。當父線程塊啟動子網格時,在父線程塊到達顯式同步點(例如 cudaDeviceSynchronize())之前,不保證子網格開始執行。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
雖然并發通常很容易實現,但它可能會因設備配置、應用程序工作負載和運行時調度而異。因此,依賴不同線程塊之間的任何并發性是不安全的。
D.2.1.6. Device Management
設備運行時不支持多 GPU; 設備運行時只能在其當前執行的設備上運行。 但是,允許查詢系統中任何支持 CUDA 的設備的屬性。
D.2.2. Memory Model
父網格和子網格共享相同的全局和常量內存存儲,但具有不同的本地和共享內存。
D.2.2.1. Coherence and Consistency
D.2.2.1.1. Global Memory
父子網格可以連貫地訪問全局內存,但子網格和父網格之間的一致性保證很弱。當子網格的內存視圖與父線程完全一致時,子網格的執行有兩點:當子網格被父線程調用時,以及當子網格線程完成時(由父線程中的同步 API 調用發出信號)。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
在子網格調用之前,父線程中的所有全局內存操作對子網格都是可見的。在父網格完成同步后,子網格的所有內存操作對父網格都是可見的。
在下面的示例中,執行 child_launch 的子網格只能保證看到在子網格啟動之前對數據所做的修改。由于父線程 0 正在執行啟動,子線程將與父線程 0 看到的內存保持一致。由于第一次 __syncthreads() 調用,孩子將看到 data[0]=0, data[1]=1, 。.., data[255]=255(沒有 __syncthreads() 調用,只有 data[0]將保證被孩子看到)。當子網格返回時,線程 0 保證可以看到其子網格中的線程所做的修改。只有在第二次 __syncthreads() 調用之后,這些修改才可用于父網格的其他線程:
__global__ void child_launch(int *data) {
data[threadIdx.x] = data[threadIdx.x]+1;
}
__global__ void parent_launch(int *data) {
data[threadIdx.x] = threadIdx.x;
__syncthreads();
if (threadIdx.x == 0) {
child_launch<<< 1, 256 >>>(data);
cudaDeviceSynchronize();
}
__syncthreads();
}
void host_launch(int *data) {
parent_launch<<< 1, 256 >>>(data);
}
D.2.2.1.2. Zero Copy Memory
零拷貝系統內存與全局內存具有相同的一致性和一致性保證,并遵循上面詳述的語義。 內核可能不會分配或釋放零拷貝內存,但可能會使用從主機程序傳入的指向零拷貝的指針。
D.2.2.1.3. Constant Memory
常量是不可變的,不能從設備修改,即使在父子啟動之間也是如此。 也就是說,所有 __constant__ 變量的值必須在啟動之前從主機設置。 所有子內核都從各自的父內核自動繼承常量內存。
從內核線程中獲取常量內存對象的地址與所有 CUDA 程序具有相同的語義,并且自然支持將該指針從父級傳遞給子級或從子級傳遞給父級。
D.2.2.1.4. Shared and Local Memory
共享內存和本地內存分別是線程塊或線程私有的,并且在父子之間不可見或不連貫。 當這些位置之一中的對象在其所屬范圍之外被引用時,行為未定義,并且可能導致錯誤。
如果 NVIDIA 編譯器可以檢測到指向本地或共享內存的指針作為參數傳遞給內核啟動,它將嘗試發出警告。 在運行時,程序員可以使用 __isGlobal() 內部函數來確定指針是否引用全局內存,因此可以安全地傳遞給子啟動。
請注意,對 cudaMemcpy*Async() 或 cudaMemset*Async() 的調用可能會調用設備上的新子內核以保留流語義。 因此,將共享或本地內存指針傳遞給這些 API 是非法的,并且會返回錯誤。
D.2.2.1.5. Local Memory
本地內存是執行線程的私有存儲,在該線程之外不可見。 啟動子內核時將指向本地內存的指針作為啟動參數傳遞是非法的。 從子級取消引用此類本地內存指針的結果將是未定義的。
例如,如果 child_launch 訪問 x_array,則以下內容是非法的,具有未定義的行為:
int x_array[10]; // Creates x_array in parent's local memory child_launch<<< 1, 1 >>>(x_array);
程序員有時很難知道編譯器何時將變量放入本地內存。 作為一般規則,傳遞給子內核的所有存儲都應該從全局內存堆中顯式分配,或者使用cudaMalloc()、new()或通過在全局范圍內聲明__device__存儲。 例如:
// Correct - "value" is global storage
__device__ int value;
__device__ void x() {
value = 5;
child<<< 1, 1 >>>(&value);
}
// Invalid - "value" is local storage
__device__ void y() {
int value = 5;
child<<< 1, 1 >>>(&value);
}
D.2.2.1.6. Texture Memory
對紋理映射的全局內存區域的寫入相對于紋理訪問是不連貫的。 紋理內存的一致性在子網格的調用和子網格完成時強制執行。 這意味著在子內核啟動之前寫入內存會反映在子內核的紋理內存訪問中。 類似地,子進程對內存的寫入將反映在父進程對紋理內存的訪問中,但只有在父進程同步子進程完成之后。 父子并發訪問可能會導致數據不一致。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
D.3. Programming Interface
D.3.1. CUDA C++ Reference
內核可以使用標準 CUDA 《《《 》》》 語法從設備啟動:
kernel_name<<< Dg, Db, Ns, S >>>([kernel arguments]);
Dg 是 dim3 類型,并指定網格(grid)的尺寸和大小
Db 是 dim3 類型,指定每個線程塊(block)的維度和大小
Ns 是 size_t 類型,并指定為每個線程塊動態分配的共享內存字節數,用于此調用并添加到靜態分配的內存中。 Ns 是一個可選參數,默認為 0。
S 是 cudaStream_t 類型,并指定與此調用關聯的流。 流必須已在進行調用的同一線程塊中分配。 S 是一個可選參數,默認為 0。
D.3.1.1.1. Launches are Asynchronous
與主機端啟動相同,所有設備端內核啟動相對于啟動線程都是異步的。 也就是說,《《《》》》 啟動命令將立即返回,啟動線程將繼續執行,直到它命中一個明確的啟動同步點,例如 cudaDeviceSynchronize()。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
網格啟動會發布到設備,并將獨立于父線程執行。 子網格可以在啟動后的任何時間開始執行,但不能保證在啟動線程到達顯式啟動同步點之前開始執行。
D.3.1.1.2. Launch Environment Configuration
所有全局設備配置設置(例如,從 cudaDeviceGetCacheConfig() 返回的共享內存和 L1 緩存大小,以及從 cudaDeviceGetLimit() 返回的設備限制)都將從父級繼承。 同樣,堆棧大小等設備限制將保持配置不變。
對于主機啟動的內核,從主機設置的每個內核配置將優先于全局設置。 這些配置也將在從設備啟動內核時使用。 無法從設備重新配置內核環境。
D.3.1.2. Streams
設備運行時提供命名和未命名 (NULL) 流。線程塊中的任何線程都可以使用命名流,但流句柄不能傳遞給其他塊或子/父內核。換句話說,流應該被視為創建它的塊的私有。流句柄不能保證在塊之間是唯一的,因此在未分配它的塊中使用流句柄將導致未定義的行為。
與主機端啟動類似,啟動到單獨流中的工作可能會同時運行,但不能保證實際的并發性。 CUDA 編程模型不支持依賴子內核之間的并發性的程序,并且將具有未定義的行為。
設備不支持主機端 NULL 流的跨流屏障語義(詳見下文)。為了保持與主機運行時的語義兼容性,必須使用 cudaStreamCreateWithFlags() API 創建所有設備流,并傳遞 cudaStreamNonBlocking 標志。 cudaStreamCreate() 調用是僅限主機運行時的 API,將無法為設備編譯。
由于設備運行時不支持 cudaStreamSynchronize() 和 cudaStreamQuery(),因此當應用程序需要知道流啟動的子內核已完成時,應使用 cudaDeviceSynchronize()。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
D.3.1.2.1. The Implicit (NULL) Stream
在宿主程序中,未命名(NULL)流與其他流具有額外的屏障同步語義(有關詳細信息,請參閱默認流)。 設備運行時提供在塊中的所有線程之間共享的單個隱式、未命名流,但由于必須使用 cudaStreamNonBlocking 標志創建所有命名流,啟動到 NULL 流中的工作不會插入對任何其他流中未決工作的隱式依賴 (包括其他線程塊的 NULL 流)。
D.3.1.3. Events
僅支持 CUDA 事件的流間同步功能。 這意味著支持 cudaStreamWaitEvent(),但不支持 cudaEventSynchronize()、cudaEventElapsedTime() 和 cudaEventQuery()。 由于不支持 cudaEventElapsedTime(),cudaEvents 必須通過 cudaEventCreateWithFlags() 創建,并傳遞 cudaEventDisableTiming 標志。
對于所有設備運行時對象,事件對象可以在創建它們的線程塊內的所有線程之間共享,但對于該塊是本地的,并且可能不會傳遞給其他內核,或者在同一內核內的塊之間。 不保證事件句柄在塊之間是唯一的,因此在未創建它的塊中使用事件句柄將導致未定義的行為。
D.3.1.4. Synchronization
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
cudaDeviceSynchronize() 函數將同步線程塊中任何線程啟動的所有工作,直到調用 cudaDeviceSynchronize() 為止。 請注意,可以從不同的代碼中調用 cudaDeviceSynchronize()(請參閱塊范圍同步)。
如果調用線程旨在與從其他線程調用的子網格同步,則由程序執行足夠的額外線程間同步,例如通過調用 __syncthreads()。
D.3.1.4.1. Block Wide Synchronization
cudaDeviceSynchronize() 函數并不意味著塊內同步。 特別是,如果沒有通過 __syncthreads() 指令進行顯式同步,則調用線程無法對除自身之外的任何線程啟動的工作做出任何假設。 例如,如果一個塊中的多個線程都在啟動工作,并且所有這些工作都需要一次同步(可能是因為基于事件的依賴關系),則由程序來保證在調用之前由所有線程提交這項工作 cudaDeviceSynchronize()。
因為允許實現在從塊中的任何線程啟動時同步,所以很可能多個線程同時調用 cudaDeviceSynchronize() 將耗盡第一次調用中的所有工作,然后對后面的調用沒有影響。
D.3.1.5. Device Management
只有運行內核的設備才能從該內核控制。 這意味著設備運行時不支持諸如 cudaSetDevice() 之類的設備 API。 從 GPU 看到的活動設備(從 cudaGetDevice() 返回)將具有與從主機系統看到的相同的設備編號。 cudaDeviceGetAttribute() 調用可能會請求有關另一個設備的信息,因為此 API 允許將設備 ID 指定為調用的參數。 請注意,設備運行時不提供包羅萬象的 cudaGetDeviceProperties() API – 必須單獨查詢屬性。
D.3.1.6. Memory Declarations
D.3.1.6.1. Device and Constant Memory
使用 __device__ 或 __constant__ 內存空間說明符在文件范圍內聲明的內存在使用設備運行時行為相同。 所有內核都可以讀取或寫入設備變量,無論內核最初是由主機還是設備運行時啟動的。 等效地,所有內核都將具有與在模塊范圍內聲明的 __constant__ 相同的視圖。
D.3.1.6.2. Textures & Surfaces
CUDA 支持動態創建的紋理和表面對象,其中紋理引用可以在主機上創建,傳遞給內核,由該內核使用,然后從主機銷毀。 設備運行時不允許從設備代碼中創建或銷毀紋理或表面對象,但從主機創建的紋理和表面對象可以在設備上自由使用和傳遞。 不管它們是在哪里創建的,動態創建的紋理對象總是有效的,并且可以從父內核傳遞給子內核。
注意:設備運行時不支持從設備啟動的內核中的遺留模塊范圍(即費米風格)紋理和表面。 模塊范圍(遺留)紋理可以從主機創建并在設備代碼中用于任何內核,但只能由頂級內核(即從主機啟動的內核)使用。
D.3.1.6.3. Shared Memory Variable Declarations
在 CUDA C++ 中,共享內存可以聲明為靜態大小的文件范圍或函數范圍的變量,也可以聲明為外部變量,其大小由內核調用者在運行時通過啟動配置參數確定。 這兩種類型的聲明在設備運行時都有效。
__global__ void permute(int n, int *data) {
extern __shared__ int smem[];
if (n <= 1)
return;
smem[threadIdx.x] = data[threadIdx.x];
__syncthreads();
permute_data(smem, n);
__syncthreads();
// Write back to GMEM since we can't pass SMEM to children.
data[threadIdx.x] = smem[threadIdx.x];
__syncthreads();
if (threadIdx.x == 0) {
permute<<< 1, 256, n/2*sizeof(int) >>>(n/2, data);
permute<<< 1, 256, n/2*sizeof(int) >>>(n/2, data+n/2);
}
}
void host_launch(int *data) {
permute<<< 1, 256, 256*sizeof(int) >>>(256, data);
}
D.3.1.6.4. Symbol Addresses
設備端符號(即標記為 __device__ 的符號)可以簡單地通過 & 運算符從內核中引用,因為所有全局范圍的設備變量都在內核的可見地址空間中。 這也適用于 __constant__ 符號,盡管在這種情況下指針將引用只讀數據。
鑒于可以直接引用設備端符號,那些引用符號的 CUDA 運行時 API(例如 cudaMemcpyToSymbol() 或 cudaGetSymbolAddress())是多余的,因此設備運行時不支持。 請注意,這意味著常量數據不能在正在運行的內核中更改,即使在子內核啟動之前也是如此,因為對 __constant__ 空間的引用是只讀的。
D.3.1.7. API Errors and Launch Failures
與 CUDA 運行時一樣,任何函數都可能返回錯誤代碼。 最后返回的錯誤代碼被記錄下來,并且可以通過 cudaGetLastError() 調用來檢索。 每個線程都會記錄錯誤,以便每個線程都可以識別它最近生成的錯誤。 錯誤代碼的類型為 cudaError_t。
與主機端啟動類似,設備端啟動可能由于多種原因(無效參數等)而失敗。 用戶必須調用 cudaGetLastError() 來確定啟動是否產生錯誤,但是啟動后沒有錯誤并不意味著子內核成功完成。
對于設備端異常,例如,訪問無效地址,子網格中的錯誤將返回給主機,而不是由父調用 cudaDeviceSynchronize() 返回。
D.3.1.7.1. Launch Setup APIs
內核啟動是通過設備運行時庫公開的系統級機制,因此可通過底層 cudaGetParameterBuffer() 和 cudaLaunchDevice() API 直接從 PTX 獲得。 允許 CUDA 應用程序自己調用這些 API,其要求與 PTX 相同。 在這兩種情況下,用戶都負責根據規范以正確的格式正確填充所有必要的數據結構。 這些數據結構保證了向后兼容性。
與主機端啟動一樣,設備端操作符 《《《》》》 映射到底層內核啟動 API。 這樣一來,以 PTX 為目標的用戶將能夠啟動加載,并且編譯器前端可以將 《《《》》》 轉換為這些調用。
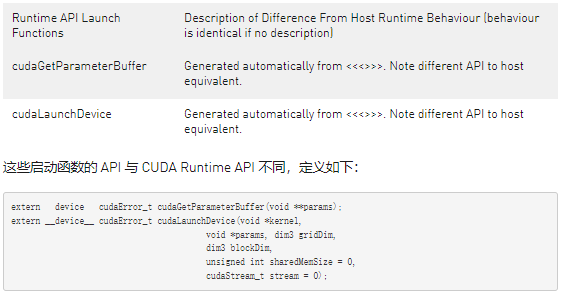
D.3.1.8. API Reference
此處詳細介紹了設備運行時支持的 CUDA 運行時 API 部分。 主機和設備運行時 API 具有相同的語法; 語義是相同的,除非另有說明。 下表提供了與主機可用版本相關的 API 概覽。


D.3.2. Device-side Launch from PTX
本部分適用于以并行線程執行 (PTX) 為目標并計劃在其語言中支持動態并行的編程語言和編譯器實現者。 它提供了與在 PTX 級別支持內核啟動相關的底層詳細信息。
D.3.2.1. Kernel Launch APIs
可以使用可從 PTX 訪問的以下兩個 API 來實現設備端內核啟動:cudaLaunchDevice() 和 cudaGetParameterBuffer()。 cudaLaunchDevice() 使用通過調用 cudaGetParameterBuffer() 獲得的參數緩沖區啟動指定的內核,并將參數填充到啟動的內核。 參數緩沖區可以為 NULL,即,如果啟動的內核不帶任何參數,則無需調用 cudaGetParameterBuffer()。
D.3.2.1.1. cudaLaunchDevice
在 PTX 級別,cudaLaunchDevice() 需要在使用前以如下所示的兩種形式之一聲明。
// PTX-level Declaration of cudaLaunchDevice() when .address_size is 64 .extern .func(.param .b32 func_retval0) cudaLaunchDevice ( .param .b64 func, .param .b64 parameterBuffer, .param .align 4 .b8 gridDimension[12], .param .align 4 .b8 blockDimension[12], .param .b32 sharedMemSize, .param .b64 stream ) ;
// PTX-level Declaration of cudaLaunchDevice() when .address_size is 32 .extern .func(.param .b32 func_retval0) cudaLaunchDevice ( .param .b32 func, .param .b32 parameterBuffer, .param .align 4 .b8 gridDimension[12], .param .align 4 .b8 blockDimension[12], .param .b32 sharedMemSize, .param .b32 stream ) ;
下面的 CUDA 級聲明映射到上述 PTX 級聲明之一,可在系統頭文件cuda_device_runtime_api.h中找到。 該函數在cudadevrt系統庫中定義,必須與程序鏈接才能使用設備端內核啟動功能。
// CUDA-level declaration of cudaLaunchDevice()
extern "C" __device__
cudaError_t cudaLaunchDevice(void *func, void *parameterBuffer,
dim3 gridDimension, dim3 blockDimension,
unsigned int sharedMemSize,
cudaStream_t stream);
第一個參數是指向要啟動的內核的指針,第二個參數是保存已啟動內核的實際參數的參數緩沖區。 參數緩沖區的布局在下面的參數緩沖區布局中進行了說明。 其他參數指定啟動配置,即網格維度、塊維度、共享內存大小以及啟動關聯的流(啟動配置的詳細說明請參見執行配置)。
D.3.2.1.2. cudaGetParameterBuffer
cudaGetParameterBuffer()需要在使用前在 PTX 級別聲明。 PTX 級聲明必須采用以下兩種形式之一,具體取決于地址大小:
// PTX-level Declaration of cudaGetParameterBuffer() when .address_size is 64 // When .address_size is 64 .extern .func(.param .b64 func_retval0) cudaGetParameterBuffer ( .param .b64 alignment, .param .b64 size ) ;
// PTX-level Declaration of cudaGetParameterBuffer() when .address_size is 32 .extern .func(.param .b32 func_retval0) cudaGetParameterBuffer ( .param .b32 alignment, .param .b32 size ) ;
cudaGetParameterBuffer()的以下 CUDA 級聲明映射到上述 PTX 級聲明:
// CUDA-level Declaration of cudaGetParameterBuffer() extern "C" __device__ void *cudaGetParameterBuffer(size_t alignment, size_t size);
第一個參數指定參數緩沖區的對齊要求,第二個參數以字節為單位的大小要求。 在當前實現中,cudaGetParameterBuffer() 返回的參數緩沖區始終保證為 64 字節對齊,忽略對齊要求參數。 但是,建議將正確的對齊要求值(即要放置在參數緩沖區中的任何參數的最大對齊)傳遞給 cudaGetParameterBuffer() 以確保將來的可移植性。
D.3.2.2. Parameter Buffer Layout
禁止參數緩沖區中的參數重新排序,并且要求放置在參數緩沖區中的每個單獨的參數對齊。 也就是說,每個參數必須放在參數緩沖區中的第 n 個字節,其中 n 是參數大小的最小倍數,它大于前一個參數占用的最后一個字節的偏移量。 參數緩沖區的最大大小為 4KB。
有關 CUDA 編譯器生成的 PTX 代碼的更詳細說明,請參閱 PTX-3.5 規范。
D.3.3. Toolkit Support for Dynamic Parallelism
D.3.3.1. Including Device Runtime API in CUDA Code
與主機端運行時 API 類似,CUDA 設備運行時 API 的原型會在程序編譯期間自動包含在內。 無需明確包含 cuda_device_runtime_api.h。
D.3.3.2. Compiling and Linking
當使用帶有 nvcc 的動態并行編譯和鏈接 CUDA 程序時,程序將自動鏈接到靜態設備運行時庫 libcudadevrt。
設備運行時作為靜態庫(Windows 上的 cudadevrt.lib,Linux 下的 libcudadevrt.a)提供,必須鏈接使用設備運行時的 GPU 應用程序。設備庫的鏈接可以通過 nvcc 或 nvlink 完成。下面顯示了兩個簡單的示例。
如果可以從命令行指定所有必需的源文件,則可以在一個步驟中編譯和鏈接設備運行時程序:
$ nvcc -arch=sm_35 -rdc=true hello_world.cu -o hello -lcudadevrt
也可以先將 CUDA .cu 源文件編譯為目標文件,然后在兩個階段的過程中將它們鏈接在一起:
$ nvcc -arch=sm_35 -dc hello_world.cu -o hello_world.o
$ nvcc -arch=sm_35 -rdc=true hello_world.o -o hello -lcudadevrt
有關詳細信息,請參閱 The CUDA Driver Compiler NVCC的使用單獨編譯部分。
D.4. Programming Guidelines
D.4.1. Basics
設備運行時是主機運行時的功能子集。 API 級別的設備管理、內核啟動、設備 memcpy、流管理和事件管理從設備運行時公開。
已經有 CUDA 經驗的人應該熟悉設備運行時的編程。 設備運行時語法和語義與主機 API 基本相同,但本文檔前面詳細介紹了任何例外情況。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
以下示例顯示了一個包含動態并行性的簡單 Hello World 程序:
#include__global__ void childKernel() { printf("Hello "); } __global__ void parentKernel() { // launch child childKernel<<<1,1>>>(); if (cudaSuccess != cudaGetLastError()) { return; } // wait for child to complete if (cudaSuccess != cudaDeviceSynchronize()) { return; } printf("World!\n"); } int main(int argc, char *argv[]) { // launch parent parentKernel<<<1,1>>>(); if (cudaSuccess != cudaGetLastError()) { return 1; } // wait for parent to complete if (cudaSuccess != cudaDeviceSynchronize()) { return 2; } return 0; }
該程序可以從命令行一步構建,如下所示:
$ nvcc -arch=sm_35 -rdc=true hello_world.cu -o hello -lcudadevrt
D.4.2. Performance
D.4.2.1. Synchronization
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
一個線程的同步可能會影響同一線程塊中其他線程的性能,即使這些其他線程自己不調用 cudaDeviceSynchronize() 也是如此。 這種影響將取決于底層實現。 通常,與顯式調用 cudaDeviceSynchronize() 相比,在線程塊結束時完成子內核的隱式同步更有效。 因此,如果需要在線程塊結束之前與子內核同步,建議僅調用 cudaDeviceSynchronize()。
D.4.2.2. Dynamic-parallelism-enabled Kernel Overhead
在控制動態啟動時處于活動狀態的系統軟件可能會對當時正在運行的任何內核施加開銷,無論它是否調用自己的內核啟動。 這種開銷來自設備運行時的執行跟蹤和管理軟件,并且可能導致性能下降,例如,與從主機端相比,從設備進行庫調用時。 通常,鏈接到設備運行時庫的應用程序會產生這種開銷。
D.4.3. Implementation Restrictions and Limitations
動態并行保證本文檔中描述的所有語義,但是,某些硬件和軟件資源依賴于實現,并限制了使用設備運行時的程序的規模、性能和其他屬性。
D.4.3.1. Runtime
D.4.3.1.1. Memory Footprint
設備運行時系統軟件為各種管理目的預留內存,特別是用于在同步期間保存父網格狀態的一個預留,以及用于跟蹤未決網格啟動的第二個預留。 配置控制可用于減少這些預留的大小,以換取某些啟動限制。 有關詳細信息,請參閱下面的配置選項。
大多數保留內存被分配為父內核狀態的后備存儲,用于在子啟動時進行同步。 保守地說,該內存必須支持為設備上可能的最大活動線程數存儲狀態。 這意味著可調用 cudaDeviceSynchronize() 的每個父代可能需要多達 860MB 的設備內存,具體取決于設備配置,即使它沒有全部消耗,也將無法供程序使用。
D.4.3.1.2. Nesting and Synchronization Depth
使用設備運行時,一個內核可能會啟動另一個內核,而該內核可能會啟動另一個內核,以此類推。每個從屬啟動都被認為是一個新的嵌套層級,層級總數就是程序的嵌套深度。同步深度定義為程序在子啟動時顯式同步的最深級別。通常這比程序的嵌套深度小一,但如果程序不需要在所有級別調用 cudaDeviceSynchronize() ,則同步深度可能與嵌套深度有很大不同。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
總體最大嵌套深度限制為 24,但實際上,真正的限制將是系統為每個新級別所需的內存量(請參閱上面的內存占用量)。任何會導致內核處于比最大值更深的級別的啟動都將失敗。請注意,這也可能適用于 cudaMemcpyAsync(),它本身可能會生成內核啟動。有關詳細信息,請參閱配置選項。
默認情況下,為兩級同步保留足夠的存儲空間。這個最大同步深度(以及因此保留的存儲)可以通過調用 cudaDeviceSetLimit() 并指定 cudaLimitDevRuntimeSyncDepth 來控制。必須在主機啟動頂層內核之前配置要支持的層數,以保證嵌套程序的成功執行。在大于指定最大同步深度的深度調用 cudaDeviceSynchronize() 將返回錯誤。
在父內核從不調用 cudaDeviceSynchronize() 的情況下,如果系統檢測到不需要為父狀態保留空間,則允許進行優化。在這種情況下,由于永遠不會發生顯式父/子同步,因此程序所需的內存占用量將遠小于保守的最大值。這樣的程序可以指定較淺的最大同步深度,以避免過度分配后備存儲。
D.4.3.1.3. Pending Kernel Launches
啟動內核時,會跟蹤所有關聯的配置和參數數據,直到內核完成。 此數據存儲在系統管理的啟動池中。
啟動池分為固定大小的池和性能較低的虛擬化池。 設備運行時系統軟件將首先嘗試跟蹤固定大小池中的啟動數據。 當固定大小的池已滿時,虛擬化池將用于跟蹤新的啟動。
固定大小啟動池的大小可通過從主機調用 cudaDeviceSetLimit() 并指定 cudaLimitDevRuntimePendingLaunchCount 來配置。
D.4.3.1.4. Configuration Options
設備運行時系統軟件的資源分配通過主機程序的 cudaDeviceSetLimit() API 進行控制。 限制必須在任何內核啟動之前設置,并且在 GPU 正在運行程序時不得更改。
警告:與父塊的子內核顯式同步(即在設備代碼中使用 cudaDeviceSynchronize())在 CUDA 11.6 中已棄用,并計劃在未來的 CUDA 版本中刪除。
可以設置以下命名限制:

D.4.3.1.5. Memory Allocation and Lifetime
cudaMalloc() 和 cudaFree() 在主機和設備環境之間具有不同的語義。 當從主機調用時,cudaMalloc() 從未使用的設備內存中分配一個新區域。 當從設備運行時調用時,這些函數映射到設備端的 malloc() 和 free()。 這意味著在設備環境中,總可分配內存限制為設備 malloc() 堆大小,它可能小于可用的未使用設備內存。 此外,在設備上由 cudaMalloc() 分配的指針上從主機程序調用 cudaFree() 是錯誤的,反之亦然。
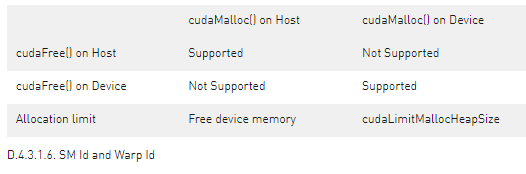
請注意,在 PTX 中,%smid 和 %warpid 被定義為 volatile 值。 設備運行時可以將線程塊重新調度到不同的 SM 上,以便更有效地管理資源。 因此,依賴 %smid 或 %warpid 在線程或線程塊的生命周期內保持不變是不安全的。
D.4.3.1.7. ECC Errors
CUDA 內核中的代碼沒有可用的 ECC 錯誤通知。 整個啟動樹完成后,主機端會報告 ECC 錯誤。 在嵌套程序執行期間出現的任何 ECC 錯誤都將生成異常或繼續執行(取決于錯誤和配置)。
關于作者
Ken He 是 NVIDIA 企業級開發者社區經理 & 高級講師,擁有多年的 GPU 和人工智能開發經驗。自 2017 年加入 NVIDIA 開發者社區以來,完成過上百場培訓,幫助上萬個開發者了解人工智能和 GPU 編程開發。在計算機視覺,高性能計算領域完成過多個獨立項目。并且,在機器人和無人機領域,有過豐富的研發經驗。對于圖像識別,目標的檢測與跟蹤完成過多種解決方案。曾經參與 GPU 版氣象模式GRAPES,是其主要研發者。
審核編輯:郭婷
-
API
+關注
關注
2文章
1501瀏覽量
62018 -
CUDA
+關注
關注
0文章
121瀏覽量
13626
發布評論請先 登錄
相關推薦
立訊精密入選2024可持續發展最佳實踐案例

MES系統的最佳實踐案例
愛芯元速榮膺最佳技術實踐應用獎
邊緣計算架構設計最佳實踐
云計算平臺的最佳實踐

RTOS開發最佳實踐
熱烈恭賀|開盛暉騰入圍APEC?ESCI最佳實踐獎候選






 工商網監
工商網監
評論