 RTL級的基本要素和設計步驟
RTL級的基本要素和設計步驟
RTL和綜合的概念
RTL(Register Transfer Level,寄存器傳輸級)指:不關注寄存器和組合邏輯的細節(如使用了多少邏輯門,邏輯門之間的連接拓撲結構等),通過描述寄存器到寄存器之間的邏輯功能描述電路的HDL層次。RTL級是比門級更高的抽象層次,使用RTL級語言描述硬件電路一般比門級描述簡單高效得多。
-
RTL級語言的最重要的特性是:RTL級描述是可綜合的描述層次。
-
綜合(Synthesize)是指將HDL語言、原理圖等設計輸入翻譯成由與、或、非門等基本邏輯單元組成的門級連接(網表),并根據設計目標與要求(約束條件)優化所生成的邏輯連接,輸出門級網表文件。RTL級綜合指將RTL級源碼翻譯并優化為門級網表。
RTL級的基本要素和設計步驟
典型的RTL設計包含一下3個部分
-
時鐘域描述:描述所使用的所有時鐘,時鐘之間的主從與派生關系,時鐘域之間的轉換;
-
時序邏輯描述(寄存器描述):根據時鐘沿的變換,描述寄存器之間的數據傳輸方式;
-
組合邏輯描述:描述電平敏感信號的邏輯組合方式與邏輯功能。
書中推薦的設計步驟:
- 功能定義與模塊劃分:根據系統功能的定義和模塊劃分準則劃分各個功能模塊;
- 定義所有模塊的接口:首先清晰定義每個模塊的接口,完成每個模塊的信號列表,這種思路與Modular Design(模塊化設計方法)一致,利于模塊重用、調試、修改;
- 設計時鐘域:根據設計的時鐘復雜程度定義時鐘之間的派生關系,分析設計中有哪些時鐘域,是否存在異步時鐘域之間的數據交換;對于PLD器件設計,還需要確認全局時鐘是否使用PLL/DLL完成時鐘的分頻、倍頻、移相等功能,哪些時鐘使用全局時鐘資源布線,哪些時鐘使用第二全局時鐘資源布線;全局時鐘的特點是:幾乎沒有Clock Skew(時鐘傾斜),有一定的Clock Delay(時鐘延遲),驅動能力最強;第二全局時鐘的特點是:有較小的Clock Shew,較小的Clock Delay,時鐘驅動能力較強;
補充:時鐘抖動(Clock Jitter):指芯片的某一個給定點上時鐘周期發生暫時性變化,使得時鐘周期在不同的周期上可能加長或縮短。時鐘偏移(Clock Skew):是由于布線長度及負載不同引起的,導致同一個時鐘信號到達相鄰兩個時序單元的時間不一致。區別:Jitter是在時鐘發生器內部產生的,和晶振或者PLL內部電路有關,布線對其沒有影響。Skew是由不同布線長度導致的不同路徑的時鐘上升沿到來的延時不同。
-
考慮設計的關鍵路徑:關鍵路徑是指設計中時序要求最難以滿足的路徑,設計的時序要求主要體現在頻率、建立時間、保持時間等時序指標上,;在設計初期,設計者可以根據系統的頻率要求,粗略的分析出設計的時序難點(如最高頻率路徑、計數器的最低位、包含復雜組合邏輯的時序路徑等),通過一些時序優化手段(如Pipeline、Retiming、邏輯復制等)從代碼上緩解設計的時序壓力,這種方法以但依靠綜合與布線工具的自動優化有效的多;
-
頂層設計:RTL設計推薦使用自頂而下的設計方法,因為這種設計方法與模塊規劃的順序一致,而且更有利于進行Modular Design,可以并行開展設計工作,提高模塊復用率;
-
FSM設計:FSM是邏輯設計最重要的內容之一;
-
時序邏輯設計:首先根據時鐘域規劃好寄存器組,然后描述各個寄存器組之間的數據傳輸方式;
-
組合邏輯設計:一般來說,大段的組合邏輯最好與時序邏輯分開描述,這樣更有利于時序約束和時序分析,使綜合器和布局布線器達到更好的優化效果。
常用RTL級建模
非阻塞賦值、阻塞賦值、連續賦值
- 對于時序邏輯,即always塊的敏感信號列表為邊沿敏感信號,統一使用非阻塞賦值“<=”;
- 對于always塊敏感信號列表為電平敏感的組合邏輯,統一使用阻塞賦值“=”;
- 對于assign關鍵字描述的組合邏輯,統一使用阻塞賦值“=”,變量被定義為wire型信號。
寄存器電路建模
寄存器和組合邏輯是數字邏輯電路的兩大基本要素,寄存器一般和同步時序邏輯關聯,其特點是僅當時鐘的邊沿到達時,才有可能發生輸出的改變。
- 寄存器變量聲明:寄存器定義為reg型,但要注意的是,反之不一定成立;
- 時鐘輸入:在每個時鐘的正沿或負沿對數據從進行處理。
- 異步復位/置位:絕大多數目標器件的寄存器模型都包含異步復位/置位端;
- 同步復位/置位:任何寄存器都可以實現同步復位/置位功能;
- 同時使用時鐘上升沿和下降沿的問題:有時因為數據采樣或者調整數據相位等需求,設計者會在一個always的敏感信號列表中同時使用時鐘的posedge和negedge,或者在兩個always的敏感信號列表中分別使用posedge和nesedge對某個寄存器電路操作;這兩種描述下,時鐘上升沿和下降沿到來時,寄存器電路都會做相應的操作,這個雙邊沿電路等同于使用了原來時鐘的倍頻時鐘的單邊沿操作電路,這種操作是不推薦的;芯片內部的PLL/DLL和一些時鐘電路往往只能對一個邊沿有非常好的指標,而另一個沿的抖動、偏移、斜率等指標不見得非常優化,有時同時使用時鐘的正負邊沿會因為時鐘的抖動、偏斜、占空比、斜率等問題造成一定的性能惡化;一般推薦將原時鐘通過PLL/DLL倍頻,然后使用倍頻時鐘的單邊沿進行操作。
組合邏輯建模
-
always 模塊的敏感信號列表為電平敏感信號的組合邏輯電路always模塊的敏感信號列表為所有判定條件和輸入信號,在使用這種結構描述組合邏輯時一定要將敏感列表列寫完整。在always塊中可以使用高級編程語言,使用阻塞賦值“=”,雖然信號被定義位reg型,但最終綜合實現結果并不是寄存器,而是組合邏輯,定義為reg型是純語法需要。
-
assign 等語句描述的組合邏輯電路
這種形式描述組合邏輯電路適用于描述那些相對簡單的組合邏輯,信號一般被定義位wire型。
- 雙向端口與三態信號建模
所有的雙向總線應該在頂層模塊定義為三態信號,禁止在頂層以外的其他子層次定義雙向端口。為了避免仿真和綜合實現結果不一致,并便于維護,強烈建議僅在頂層定義雙向總線和例化三態信號,禁止在除頂層以外的其他層次賦值高阻態"Z",在頂層將雙向信號分為輸入和輸出信號兩種類型,然后根據需要分別傳遞到不同的子模塊中,這樣做的另一個好處是便于描述仿真激勵。
modulebibus(clk,rst,sel,data_bus,addr);
inputclk,rst,sel;
input[7:0]addr;
inout[7:0]data_bus;
wire[7:0]data_in,data_out;
assigndata_in=data_bus;
assigndata_bus=(sel)?data_out:8'bZ;
decodedecode_inst(.clock(clk),
.reset(rst),
.data_bus_in(data_in),
.addr_bus(addr),
.data_bus_out(data_out)
);
endmodule
如果三態總線的使能關系比較復雜,不是單一信號,此時可以使用嵌套的問號表達式,或者使用case語句描述。
- 嵌套的問號表達式
modulecomplex_bibus(clk,rst,sel1,sel2,sel3,data_bus,addr);
inputclk,rst;
inputsel1,sel2,sel3;
input[7:0]addr;
inout[7:0]data_bus;
wire[7:0]data_in;
//wire[7:0]data_out;//usewiretype
wire[7:0]decode_out;
wire[7:0]cnt_out;
assigndata_in=data_bus;
assigndata_bus=(sel1)?decode_out:((sel2)?cnt_out:((sel3)?8'b11111111:8'bZZZZZZZZ));
decodedecode_inst(.clock(clk),
.reset(rst),
.data_bus_in(data_in),
.addr_bus(addr),
.data_bus_out(decode_out)
);
countercounter_inst(.clock(clk),
.reset(rst),
.data_bus_in(data_in),
.cnt_out(cnt_out)
);
endmodule
- case語句(如果使能情況比較復雜,通過case進行羅列,更清晰)
inputsel1,sel2,sel3;
input[7:0]addr;
inout[7:0]data_bus;
wire[7:0]data_in;
reg[7:0]data_out;//useregtype,butnotregisters
wire[7:0]decode_out;
wire[7:0]cnt_out;
assigndata_in=data_bus;
decodedecode_inst(.clock(clk),
.reset(rst),
.data_bus_in(data_in),
.addr_bus(addr),
.data_bus_out(decode_out)
);
countercounter_inst(.clock(clk),
.reset(rst),
.data_bus_in(data_in),
.cnt_out(cnt_out)
);
always@(decode_outorcnt_outorsel1orsel2orsel3)
begin
case({sel1,sel2,sel3})
3'b100:data_out=decode_out;
3'b010:data_out=cnt_out;
3'b001:data_out=8'b11111111;
default:data_out=8'bZZZZZZZZ;
endcase
end
assigndata_bus=data_out;
endmodule
- mux 建模
簡單的使用assign和?,相對復雜的使用always和if…else、case等條件判斷語句建模。
- 存儲器建模
邏輯電路設計經常使用一些單口RAM、雙口RAM和ROM等存儲器。Verilog 語法中基本的存儲單元定義格式為:
reg[datawidth]MemoryName[addresswidth]
如定義一個數據位寬為8bit,地址為63為的RAM8x64:
reg[7:0]RAM8x64[0:63];
在使用存儲單元時,不能直接操作存儲器某地址的某位,需要先將存儲單元賦值給某個寄存器,然后再對該存儲器的某位進行相關操作。
moduleram_basic(clk,CS,WR,addr,data_in,data_out,en);
inputclk;
inputCS;//CS=1,RAMenable
inputWR;//WR=1thenWRiteenable;WR=0thenreadenable
inputen;//data_outenable,convertthedatasequency
input[5:0]addr;
input[7:0]data_in;
output[7:0]data_out;
reg[7:0]RAM8x64[0:63];
reg[7:0]mem_data;
always@(posedgeclk)
if(WR&&CS)//WRite
RAM8x64[addr]<=?data_in?[7:0];
????elseif(~WR&&CS)//read
mem_data<=?RAM8x64?[addr];?
?????????
assign?data_out?=?(en)??mem_data[7:0]?:?{~mem_data[7],?mem_data[6:0]};
endmodule
- FPGA中內嵌的RAM資源分為兩類:塊RAM(Block RAM)資源和分布式RAM(DistributedRAM)資源,BRAM作為FPGA內部硬件資源,使用時不會占用其他邏輯資源,分布式RAM是通過查找表和觸發器實現的RAM結構。
- 使用RAM等資源時通常不使用這種Verilog語言進行建模,一般使用廠商提供IP核通過GUI完成相關參數配置,并生成相關IP。
簡單的時鐘分頻電路
偶數分頻十分簡單,只需要用高速時鐘驅動一個同步計數器;
moduleclk_div_phase(rst,clk_200K,clk_100K,clk_50K,clk_25K);
inputclk_200K;
inputrst;
outputclk_100K,clk_50K,clk_25K;
wireclk_100K,clk_50K,clk_25K;
reg[2:0]cnt;
always@(posedgeclk_200Kornegedgerst)
if(!rst)
cnt<=?3'b000;
else
cnt<=?cnt?+?1;
assign?clk_100K?=?~cnt?[0];//2分頻
assign?clk_50K??=?~cnt?[1];//4分頻
assign?clk_25K??=?~cnt?[2];//8分頻
endmodule
上例通過對計數器每個bit的反向,完成了所有分頻后的時鐘調整,保證了3個分頻后時鐘的相位嚴格同相,也與源時鐘同相,有共同的上升沿。
奇數分頻
moduleclk_3div(clk,reset,clk_out);
inputclk,reset;
outputclk_out;
reg[1:0]state;
regclk1;
always@(posedgeclkornegedgereset)
if(!reset)
state<=2'b00;
else
case(state)
2'b00:state<=2'b01;
2'b01:state<=2'b11;
2'b11:state<=2'b00;
default:state<=2'b00;
endcase
always@(negedgeclkornegedgereset)
if(!reset)
clk1<=1'b0;
else
clk1<=state[0];
assign?clk_out=state[0]&clk1;
endmodule?
串/并轉換建模
根據數據的排序和數量的要求,可以選用移位寄存器、RAM等實現;對于數量比較小的設計可以采用移位寄存器完成串/并轉換(串轉并:先移位,再并行輸出;并轉串:先加載并行數據,再移位輸出);對于排列順序有規律的串/并轉換,可以使用case語句進行判斷實現;對于復雜的串/并轉換,還可以用狀態機實現。
同步復位與異步復位
同步復位建模
modulesyn_rst(clk,rst_,cnt1,cnt2);
inputclk;
inputrst_;
output[4:0]cnt1,cnt2;
reg[4:0]cnt1,cnt2;
always@(posedgeclk)
if(!rst_)
begin
cnt1<=?4'b0;
cnt2<=?4'b0;
end
else
begin
if(cnt1'b11)
cnt1<=?cnt1?+?1;
????????else
????????????cnt1?<=?cnt1;????????????????
????????cnt2?<=?cnt1?-?1;??????
??????end
endmodule
很多目標器件的觸發器本身本身并不包含同步復位端口,則同步復位可以通過下圖結構實現:
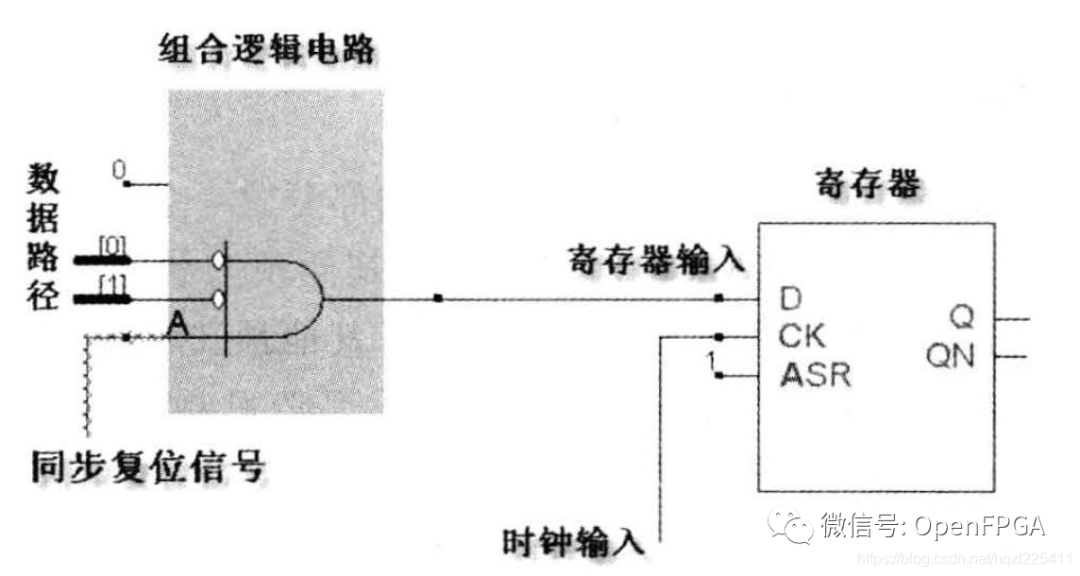
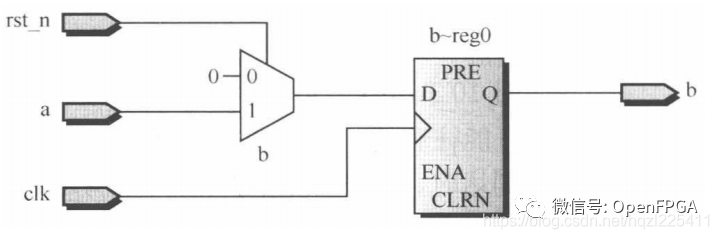
優點
- 同步復位利于基于周期機制的仿真器仿真;
- 使用同步復位可以設計100%的同步時序電路,利于時序分析,其綜合結果的頻率往往更高;
- 同步復位僅在時鐘的上升沿生效,可以有效的避免因復位電路毛刺造成的亞穩態和錯誤;在進行復位和釋放復位信號時,都是僅當時鐘沿采到復位電平變化時才進行相關操作,如果復位信號樹的組合邏輯出現了某些毛刺,此時時鐘邊沿采集到毛刺的概率非常低,通過時鐘沿采樣,可以十分有效地過濾復位電路的組合邏輯毛刺,增強電路的穩定性。
缺點
-
很多目標器件的觸發器本身不包含同步復位端口,使用同步復位會增加很多邏輯資源;
-
同步復位的最大問題在于必須保證復位信號的有效時間足夠長,才能保證所有觸發器都有效復位,所以同步復位信號的持續時間必須大于設計的最長時鐘周期,以保證所有時鐘的有效沿都能采樣到同步復位信號。
-
其實僅僅保證同步復位信號的持續時間大于最慢的時鐘周期還是不夠的,設計中還要考慮到同步復位信號樹通過所有組合邏輯路徑的延時以及由于時鐘布線產生的偏斜(skew),只有同步復位大于時鐘最大周期加上同步信號穿過的組合邏輯路徑延時加上時鐘偏斜時,才能保證同步復位可靠、徹底。
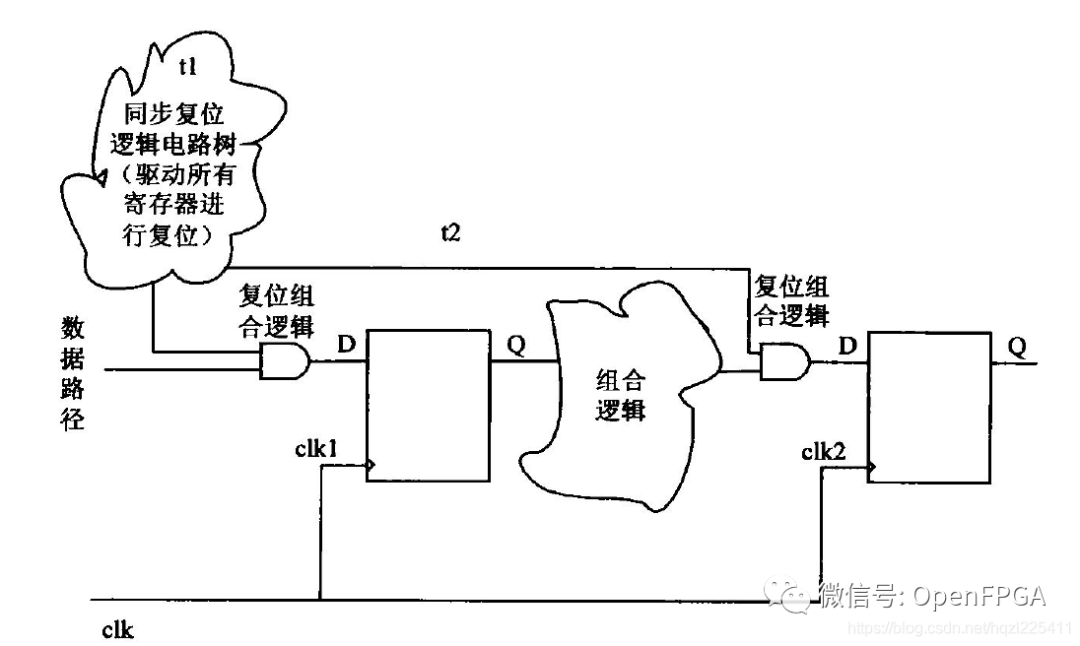
上圖中,假設同步復位邏輯樹組合邏輯的延時為t1,復位信號傳播路徑的最大延遲為t2,最慢時鐘的周期為Period max,時鐘的skew為clk2-clk1,則同步復位的周期Tsys_rst應滿足:Tsys_rst > Period max + (clk2-clk1) + t1 + t2;
異步復位建模
moduleasyn_rst(clk,rst_,cnt1,cnt2);
inputclk;
inputrst_;
output[4:0]cnt1,cnt2;
reg[4:0]cnt1,cnt2;
always@(posedgeclkornegedgerst_)
if(!rst_)
begin
cnt1<=?4'b0;
cnt2<=?4'b0;
end
else
begin
if(cnt1'b11)
cnt1<=?cnt1?+?1;
????????else
????????????cnt1?<=?cnt1;????????????????
????????cnt2?<=?cnt1?-?1;??????
??????end
endmodule
優點
- 多數器件包含異步復位端口,異步復位會節約邏輯資源;
- 異步復位設計簡單;
- 大多數FPGA,都有專用的全局復位/置位資源(GSR,Globe Set Reset),使用GSR資源,異步復位達到所有寄存器的偏斜(skew)最小。
缺點
- 異步復位的作用和釋放與時鐘沿沒有直接關系,在異步復位神效時問題并不明顯,但當異步復位釋放時,如果異步復位釋放時間和時鐘的有效沿到達時間幾乎一致,則容易造成觸發器輸出亞穩態,造成邏輯錯誤;
- 如果異步復位邏輯樹的組合邏輯產生了毛刺,則毛刺的有效沿會使觸發器誤復位,造成邏輯錯誤。
推薦的復位電路設計方式——異步復位,同步釋放
- 推薦的復位電路設計方式是異步復位,同步釋放,這種方式可以有效的繼承異步復位設計簡單的優勢,并克服異步復位的風險與缺陷;相較于純粹的異步復位,降低了異步復位信號釋放導致的亞穩態的可能性,相較于同步復位,能夠識別到同步復位中檢測不到的復位信號。
- 在FPGA中使用異步復位,同步釋放可以節約器件資源,并獲得穩定可靠的復位效果。
- 異步復位同步釋放,既能很快的檢測到復位信號,不需要復位保持超過一個時鐘周期,又能解決釋放時的亞穩態問題(降低亞穩態發生的概率)。
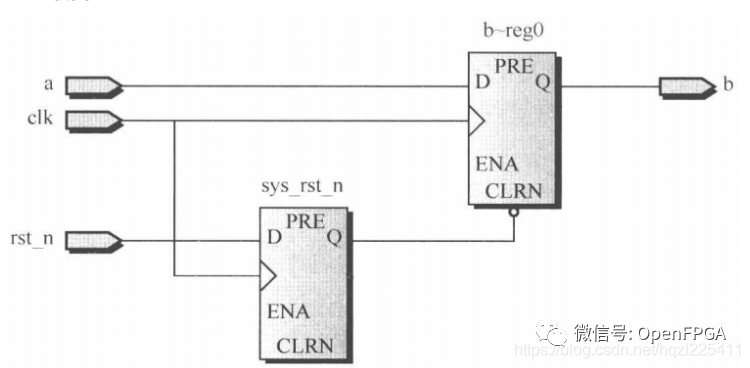
- 異步復位,同步釋放的具體設計方法很多,關鍵是如何保證同步地釋放復位信號,本例舉例的方法是在復位信號釋放時,用系統時鐘采樣后再將復位信號送到寄存器的異步復位端。
- 所謂“異步復位”是針對D觸發器的復位端口,它是異步的,但是設計中已經同步了異步復位信號,所以筆者(Crazybingo)認為這只是某種意義上的“異步復位”。
- 所謂“同步釋放”,實際上是由于我們設計了同步邏輯電路,外部復位信號不會在出現釋放時與clk信號競爭,整個系統將與全局時鐘clk信號同步。
- 使用時鐘將外部輸入的異步復位信號寄存一個節拍后,再送到觸發器異步復位端口的設計方法的另一個好處在于:做STA(靜態時序分析)分析時,時序工具會自動檢查同步后的異步復位信號和時鐘的到達(Recovery)/撤銷(Removal)時間關系,如果因布線造成的skew導致該到達/撤銷時間不能滿足,STA工具會上報該路徑,幫助設計者進一步分析問題。
modulesystem_ctrl//異步復位,同步釋放——by特權同學
//==================<端口>==================================================
(
//globelclock----------------------------------
inputwireclk,//時鐘,50Mhz
inputwirerst_n,//復位,低電平有效
//userinterface--------------------------------
inputwirea,//輸入信號
outputregb//輸出信號
);
//==========================================================================
//==異步復位的同步化設計
//==========================================================================
regsys_rst_n_r;
regsys_rst_n;
always@(posedgeclkornegedgerst_n)
begin
if(!rst_n)begin
sys_rst_n_r<=?1'b0;
sys_rst_n<=?1'b0;
end
elsebegin
sys_rst_n_r<=?1'b1;
sys_rst_n<=?sys_rst_n_r;?//注意這里的rst_sync_n才是我們真正對系統輸出的復位信號
????end
end
always?@(posedge?clk?or?negedge?sys_rst_n)???//注意這里將同步后的信號仍作為異步復位信號進行處理,Altera推薦
begin
????if(!sys_rst_n)
????????b?<=?0;
????else
????????b?<=?a;
end
endmodule
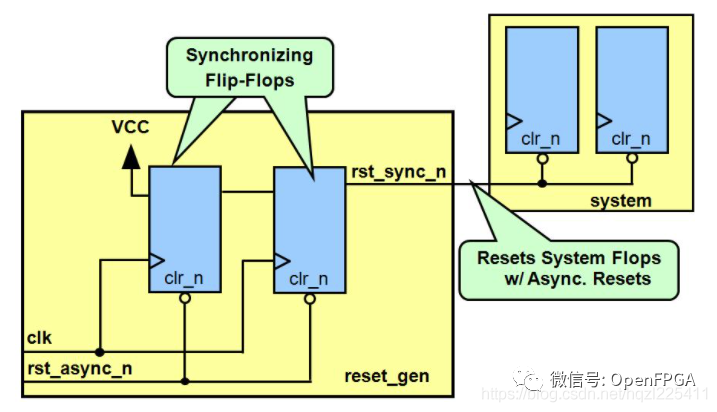
上圖是Altera推薦的異步復位,同步釋放示意圖
modulereset_gen(outputrst_sync_n,inputclk,rst_async_n);//此模塊對應前一個黃框中的邏輯,輸出信號在后級電路中仍作為異步復位信號進行處理
regrst_s1,rst_s2;
wirerst_sync_n;
always@(posedgeclk,posedgerst_async_n)
if(rst_async_n)
begin
rst_s1<=?1'b0;
rst_s2<=?1'b0;
end
else
begin
rst_s1<=?1'b1;//針對AlteraFPGA
rst_s2<=?rst_s1;
????????end
assign?rst_sync_n?=?rst_s2;?//注意這里的rst_sync_n才是我們真正對系統輸出的復位信號
endmodule
Xilinx的FPGA,高電平復位其Filp-Flop同時支持同步/異步復位,復位準則:
- 盡量少使用復位,特別是少用全局復位,能不用復位就不用,一定要用復位的使用局部復位;
- 如果必須要復位,在同步和異步復位上,則盡量使用同步復位(BRAM DSP48不支持異步復位),一定要用異步復位的地方,采用“異步復位、同步釋放”;
- 復位電平選擇高電平復位;
只要存在復位都會增加布局布線的負擔,因為復位會像時鐘一樣連接到每一個寄存器上,是相當復雜的工程,會增加時序收斂的難度。
對于同一個觸發器邏輯,因為同時支持異步和同步復位,所以異步復位并不會節省資源;對于其他的資源,比如 DSP48 等,同步復位更加節省資源。
首先,對于 DSP48,其內部還帶有一些寄存器(只支持同步復位),如果使用異步復位,則會額外使用外部 Slice 中帶異步復位的寄存器,而使用同步復位時,可以利用 DSP48 內部的寄存器;Xilinx 的 FPGA,對于 DSP48、BRAM 資源,使用同步復位比異步復位更節省資源。
對于高電平復位,使用異步復位同步釋放,則第一個寄存器的 D 輸入是 0,這里使用了 4 個觸發器打拍同步。
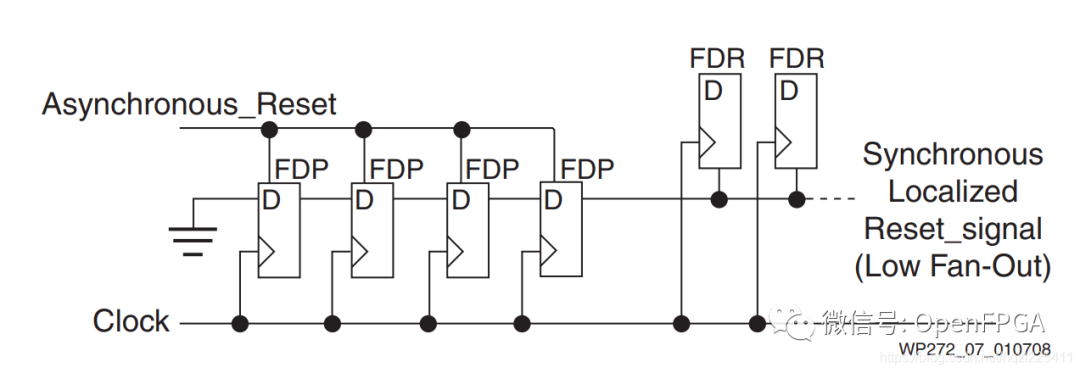
always@(posedgeclkorposedgerst_async)
begin
if(rst_async==1'b1)begin
rst_sync_reg1<=?1'b1;//Xilinx的FPGA高電平復位
rst_sync_reg2<=?1'b1;
rst_sync_reg3<=?1'b1;
rst_sync_reg4<=?1'b1;
end
elsebegin
rst_sync_reg1<=?1'b0;
rst_sync_reg2<=?rst_sync_reg1;
????????rst_sync_reg3?<=?rst_sync_reg2;
????????rst_sync_reg4?<=?rst_sync_reg3;
????end
end??
wire?sys_rst;
assign?sys_rst?=?rst_sync_reg4;
always?@(posedge?clk)????//同步后的信號當作同步復位信號處理
begin
????if(sys_rst==1'b1)begin
data_out_rst_async<=?1'b0;
end
elsebegin
data_out_rst_async<=?a?&?b?&?c?&?d;
????end
end
同步后的信號如果作為同步復位信號進行處理:
rst_async異步復位一旦給出,用于同步的4個寄存器rst_sync_reg1~4立刻輸出高電平“1”,在下一個時鐘上升沿檢測到同步復位并將輸出data_out_rst_async復位;
異步復位信號釋放后,經過同步的sys_rst經過一定周期后在時鐘邊沿同步釋放;
同步后的信號如果作為異步復位信號進行處理:
區別在于異步復位信號rst_async一旦產生,輸出立刻復位,且同樣是同步釋放,好像這種處理才更符合異步復位、同步釋放。
那么為什么Xilinx白皮書還是將sys_rst按照同步復位去做的呢?綜合考慮可能有這樣的因素:
-
當作同步復位的差別只在于復位時間會稍晚一些,要在時鐘的下一個邊沿檢測到,但是還是能夠識別到輸入的rst_async異步復位信號,所以從復位角度來說,都能夠后實現復位效果;
-
根據Xilinx復位準則,我們知道同步復位相比異步復位有很多好處,具體參見:Xilinx FPGA 復位策略白皮書(WP272) 公眾號-FPGA探索者做了翻譯可以參考,既然兩者對后級復位沒有功能上的差別,那么優先選擇同步復位;
Xilinx 推薦的復位準則:
-
盡量少使用復位,特別是少用全局復位,能不用復位就不用,一定要用復位的使用局部復位;
-
如果必須要復位,在同步和異步復位上,則盡量使用同步復位,一定要用異步復位的地方,采用“異步復位、同步釋放”;
-
復位電平選擇高電平復位;
Altera
Altera的FPGA,低電平復位,其觸發器只有異步復位端口,所以如果想要用同步復位,需要額外的資源來實現,這也是“異步復位節省資源”這一說法的原因。
具體電路及代碼見上文
可綜合的Verilog語法子集
在RTL建模時,使用可綜合的Verilog語法是整個Verilog語法中的非常小的一個子集。其實可綜合的Verilog常用關鍵字非常有限,這恰恰體現了Verilog語言是硬件描述語言的本質,Verilog作為HDL,其本質在于把電路流暢、合理的轉換為語言形式,而使用較少的一些關鍵字就可以有效的將電路轉換到可綜合的RTL語言結構。常用的RTL語法結構列舉:
- 模塊聲明:module…endmodule;
- 端口聲明:input、outpu、inout;
- 信號類型:wire、reg、tri等,integer通常用于for語句中索引;
- 參數定義:parameter
- 運算操作符:邏輯操作、移位操作、算術操作;
- 比較判斷:case…endcase(casex/casez)、if…else;
- 連續賦值:assign、問號表達式
- always模塊:建模時序和組合邏輯
- 語法分割符:begin…end
- 任務定義:task…endtask
- 循環語句:for
CPU讀/寫PLD寄存器接口設計實例
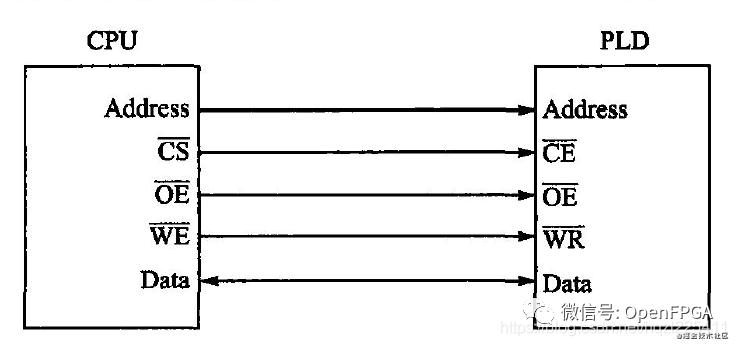
- CS:片選(低有效、input)
- OE:輸出使能信號(低有效、input)
- WR:讀/寫指示,低-讀數據,高-寫數據(input)
- Address:地址總線(input)
- Data:雙向數據總線(inout)
地址譯碼器電路
moduledecode(CS_,OE_,WR_,Addr,my_wr,my_rd,CS_reg1,CS_reg2,CS_reg3);
inputCS_,OE_,WR_;
input[7:0]Addr;
outputmy_wr,my_rd;
outputCS_reg1,CS_reg2,CS_reg3;
regCS_reg1,CS_reg2,CS_reg3;
assignmy_wr=(!WR_)&&(!CS_)&&(!OE_);
assignmy_rd=(WR_)&&(!CS_)&&(!OE_);
always@(AddrorCS_)
if(!CS_)
begin
case(Addr)
8'b11110000:CS_reg1<=?1'b1;
8'b00001111:CS_reg2<=?1'b1;
8'b10100010:CS_reg3<=?1'b1;
default:begin
CS_reg1<=?1'b0;
CS_reg2<=?1'b0;
CS_reg3<=?1'b0;
end
endcase
end
endmodule
讀寄存器
moduleread_reg(clk,rst,data_out,my_rd,CS_reg1,CS_reg2,CS_reg3,reg1,reg2,reg3);
inputclk,rst,my_rd,CS_reg1,CS_reg2,CS_reg3;
input[7:0]reg1,reg2,reg3;
output[7:0]data_out;
reg[7:0]data_out;
always@(posedgeclkornegedgerst)
if(!rst)
data_out<=?8'b0;
else
begin
if(my_rd)
begin
if(CS_reg1)
data_out<=?reg1;
?????????????????????else?if?(CS_reg2)
?????????????????????????data_out?<=?reg2;
?????????????????????else?if?(CS_reg3)
?????????????????????????data_out?<=?reg3;
????????????????end
????????????else
????????????????data_out?<=?8'b0;
end
endmodule
寫寄存器
modulewrite_reg(clk,rst,data_in,my_wr,CS_reg1,CS_reg2,CS_reg3,reg1,reg2,reg3);
inputclk,rst,my_wr,CS_reg1,CS_reg2,CS_reg3;
input[7:0]data_in;
output[7:0]reg1,reg2,reg3;
reg[7:0]reg1,reg2,reg3;
always@(posedgeclkornegedgerst)
if(!rst)
begin
reg1<=?8'b0;
reg2<=?8'b0;
reg3<=?8'b0;
end
else
begin
if(my_wr)
begin
if(CS_reg1)
reg1<=?data_in;
?????????????????????else?if?(CS_reg2)
?????????????????????????reg2?<=?data_in;
?????????????????????else?if?(CS_reg3)
?????????????????????????reg3?<=?data_in;
????????????????end
????????????else
????????????????begin
?????????????????????reg1?<=?reg1;
?????????????????????reg2?<=?reg2;
?????????????????????reg3?<=?reg3;
????????????????end????????????????
?????????
?????????end
endmodule
頂層
moduletop(clk_cpu,rst,CS_,OE_,WR_,Addr,data_bus);
inputclk_cpu,rst;
inputCS_,OE_,WR_;
input[7:0]Addr;
inout[7:0]data_bus;
wire[7:0]data_in;
wire[7:0]data_out;
wiremy_wr,my_rd;
wireCS_reg1,CS_reg2,CS_reg3;//theregisterselection
wire[7:0]reg1,reg2,reg3;//theregistertobereadandwritten
assigndata_in=data_bus;
assigndata_bus=((!CS_)&&(!OE_))?data_out:8'bZZZZZZZZ;
decodedecode_u1(.CS_(CS_),
.OE_(OE_),
.WR_(WR_),
.Addr(Addr),
.my_wr(my_wr),
.my_rd(my_rd),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3)
);
write_regwrite_reg_u1(.clk(clk_cpu),
.rst(rst),
.data_in(data_in),
.my_wr(my_wr),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3),
.reg1(reg1),
.reg2(reg2),
.reg3(reg3)
);
read_regread_reg_u1(.clk(clk_cpu),
.rst(rst),
.data_out(data_out),
.my_rd(my_rd),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3),
.reg1(reg1),
.reg2(reg2),
.reg3(reg3)
);
endmodule
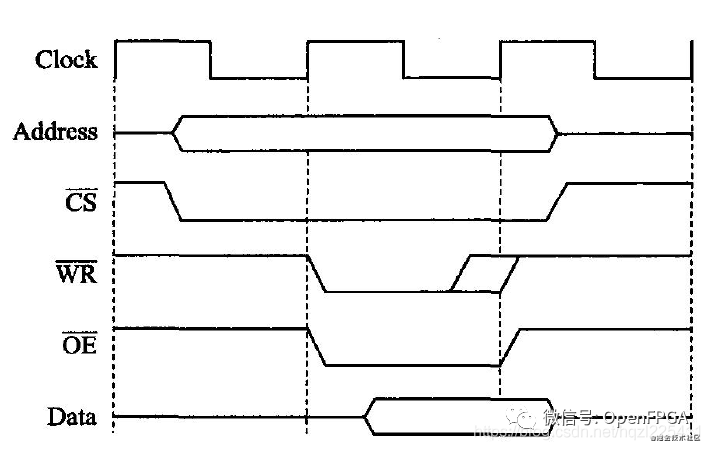
使用OE/WR邊沿讀寫
使用OE或WR的沿讀寫寄存器的描述看起來比前面介紹的使用CPU時鐘同步讀寫寄存器的描述簡單,但是讀者必須明確這種方式正常工作有兩個前提條件:
- OE的上升沿可以有效地采樣數據總線,即OE的上升沿采樣數據總線時Setup和Hold都能保證滿足;
- WR和CS信號都比OE信號寬,即OE上升沿讀寫寄存器時,CS和WR信號始終保持有效。
只有這兩個條件同時滿足的前提下,才能保證使用OE的沿讀寫PLD寄存器電路是可靠的。
/******************************************/
moduledecode(CS_,WR_,Addr,my_wr,my_rd,CS_reg1,CS_reg2,CS_reg3);
inputCS_,WR_;
input[7:0]Addr;
outputmy_wr,my_rd;
outputCS_reg1,CS_reg2,CS_reg3;
regCS_reg1,CS_reg2,CS_reg3;
assignmy_wr=(!WR_)&&(!CS_);
assignmy_rd=(WR_)&&(!CS_);
always@(AddrorCS_)
if(!CS_)
begin
case(Addr)
8'b11110000:CS_reg1<=?1'b1;
8'b00001111:CS_reg2<=?1'b1;
8'b10100010:CS_reg3<=?1'b1;
default:begin
CS_reg1<=?1'b0;
CS_reg2<=?1'b0;
CS_reg3<=?1'b0;
end
endcase
end
endmodule
/******************************************/
moduleread_reg(OE_,rst,data_out,my_rd,CS_reg1,CS_reg2,CS_reg3,reg1,reg2,reg3);
inputOE_,rst,my_rd,CS_reg1,CS_reg2,CS_reg3;
input[7:0]reg1,reg2,reg3;
output[7:0]data_out;
reg[7:0]data_out;
always@(posedgeOE_ornegedgerst)
if(!rst)
data_out<=?8'b0;
else
begin
if(my_rd)
begin
if(CS_reg1)
data_out<=?reg1;
?????????????????????elseif(CS_reg2)
data_out<=?reg2;
?????????????????????elseif(CS_reg3)
data_out<=?reg3;
????????????????end
????????????else
data_out<=?8'b0;
end
endmodule
/******************************************/
modulewrite_reg(OE_,rst,data_in,my_wr,CS_reg1,CS_reg2,CS_reg3,reg1,reg2,reg3);
inputOE_,rst,my_wr,CS_reg1,CS_reg2,CS_reg3;
input[7:0]data_in;
output[7:0]reg1,reg2,reg3;
reg[7:0]reg1,reg2,reg3;
always@(posedgeOE_ornegedgerst)
if(!rst)
begin
reg1<=?8'b0;
reg2<=?8'b0;
reg3<=?8'b0;
end
else
begin
if(my_wr)
begin
if(CS_reg1)
reg1<=?data_in;
?????????????????????elseif(CS_reg2)
reg2<=?data_in;
?????????????????????elseif(CS_reg3)
reg3<=?data_in;
????????????????end
????????????else
begin
reg1<=?reg1;
?????????????????????reg2?<=?reg2;
?????????????????????reg3?<=?reg3;
????????????????end????????????????
?????????
?????????end
?????????
endmodule
/******************************************/
module?top?(rst,?CS_,?OE_,?WR_,?Addr,?data_bus);
input???????rst;
input????????CS_,?OE_,?WR_;
input?[7:0]?Addr;
inout?[7:0]?data_bus;
wire?[7:0]?data_in;
wire?[7:0]?data_out;
wire???????my_wr,?my_rd;
wire???????CS_reg1,?CS_reg2,?CS_reg3;?//?the?register?selection
wire?[7:0]?reg1,?reg2,?reg3;??????????//?the?register?to?be?readandwritten
assigndata_in=data_bus;
assigndata_bus=((!CS_)&&(!OE_))?data_out:8'bZZZZZZZZ;
decodedecode_u1(.CS_(CS_),
//.OE_(OE_),
.WR_(WR_),
.Addr(Addr),
.my_wr(my_wr),
.my_rd(my_rd),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3)
);
write_regwrite_reg_u1(.OE_(OE_),
.rst(rst),
.data_in(data_in),
.my_wr(my_wr),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3),
.reg1(reg1),
.reg2(reg2),
.reg3(reg3)
);
read_regread_reg_u1(.OE_(OE_),
.rst(rst),
.data_out(data_out),
.my_rd(my_rd),
.CS_reg1(CS_reg1),
.CS_reg2(CS_reg2),
.CS_reg3(CS_reg3),
.reg1(reg1),
.reg2(reg2),
.reg3(reg3)
);
endmodule
/******************************************/
如果譯碼電路是組合邏輯,則其譯碼結果就有可能帶有毛刺,另外由于CPU總線的時序在電壓、溫度、環境變化的情況下時序可能遭到破壞,造成OE,WR,CS等信號的時序余量惡化,如果此時使用譯碼結果的電平做電平敏感的always模塊,進行讀寫寄存器操作(如Example-4-21 asyn_bad目錄下的read_reg.v和write_reg.v),則會因為毛刺和錯誤電平造成讀寫錯誤。所以不同將OE或WR的電平作為敏感信號來進行讀寫。
-
寄存器
+關注
關注
31文章
5343瀏覽量
120366 -
建模
+關注
關注
1文章
305瀏覽量
60774 -
RTL
+關注
關注
1文章
385瀏覽量
59785
原文標題:RTL概念與常用RTL建模
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機械振動的三個基本要素
正弦量的三要素是什么
所有的labview應用程序的三要素是什么
RTL8187L和802.11n
Realtek RTL8211F系列以太網收發器:高集成度與工業級穩定性的完美結合
建設智慧城市的要素

變頻器選型的基本要素有哪些?

基于樹莓派5的RTL仿真體驗
如何通過優化RTL減少功耗

Aigtek功率放大器的構成要素包括哪些






 工商網監
工商網監
評論