 分享一份面試真題(附答案)
分享一份面試真題(附答案)
前言
分享了一份面試真題,整理了一下答案給大家。如果有不正確的,歡迎指出哈,一起進步。
- Redis的key和value可以存儲的最大值分別是多少?
- 怎么利用Redis實現數據的去重?
- Redis什么時候需要序列化?Redis序列化的方式有哪些?
- MySQL的B+樹的高度怎么計算?
- 線程池的狀態有哪些?獲取多線程并發執行結果的方式有哪些?
- 線程池原理?各個參數的作用。
- ThreadLocal的使用場景有哪些?原理?內存泄漏?
- kafka是如何保證消息的有序性?
- Nacos的選舉機制了解嘛?說下Raft算法?
- 聊一聊TCC補償機制
1、Redis的key和value可以存儲的最大值分別是多少?
-
雖然Key的大小上限為
512M,但是一般建議key的大小不要超過1KB,這樣既可以節約存儲空間,又有利于Redis進行檢索。 -
value的最大值也是
512M。對于String類型的value值上限為512M,而集合、鏈表、哈希等key類型,單個元素的value上限也為512M。
2. 怎么利用Redis實現數據的去重?
-
Redis的
set:它可以去除重復元素,也可以快速判斷某一個元素是否存在于集合中,如果元素很多(比如上億的計數),占用內存很大。 -
Redis的
bit:它可以用來實現比set內存高度壓縮的計數,它通過一個bit設置為1或者0,表示存儲某個元素是否存在信息。例如網站唯一訪客計數,可以把user_id作為 bit 的偏移量 offset,如設置為1表示有訪問,使用1 MB的空間就可以存放800多萬用戶的一天訪問計數情況。 -
HyperLogLog:實現超大數據量精確的唯一計數都是比較困難的,HyperLogLog可以僅僅使用 12 k左右的內存,實現上億的唯一計數,而且誤差控制在百分之一左右。 -
bloomfilter布隆過濾器:布隆過濾器是一種占用空間很小的數據結構,它由一個很長的二進制向量和一組Hash映射函數組成,它用于檢索一個元素是否在一個集合中
關于布隆過濾器,關注數據分析與開發公號,回復布隆過濾器即可獲取。
3. Redis什么時候需要序列化?Redis序列化的方式有哪些?
大家先回憶下Java序列化,什么時候需要序列化?
- 序列化:將 Java 對象轉換成字節流的過程。
- 反序列化:將字節流轉換成 Java 對象的過程。
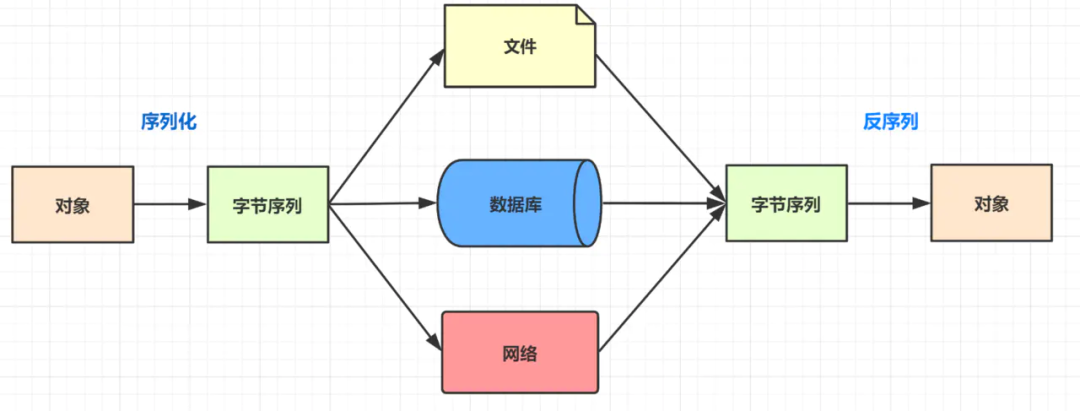
為什么需要序列化呢?
打個比喻:作為大城市漂泊的碼農,搬家是常態。當我們搬書桌時,桌子太大了就通不過比較小的門,因此我們需要把它拆開再搬過去,這個拆桌子的過程就是序列化。而我們把書桌復原回來(安裝)的過程就是反序列化啦。
- 比如想把內存中的對象狀態保存到一個文件中或者數據庫中的時候(最常用,如保存到redis);
- 再比喻想用套接字在網絡上傳送對象的時候,都需要序列化。
RedisSerializer接口 是 Redis 序列化接口,用于 Redis KEY 和 VALUE 的序列化
- JDK 序列化方式 (默認)
- String 序列化方式
- JSON 序列化方式
- XML 序列化方式
4. MySQL的B+樹的高度怎么計算?(比如有100w的數據,字段為int類型)
InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。
B+樹葉子存的是數據,內部節點存的是鍵值+指針。索引組織表通過非葉子節點的二分查找法以及指針確定數據在哪個頁中,進而再去數據頁中找到需要的數據;
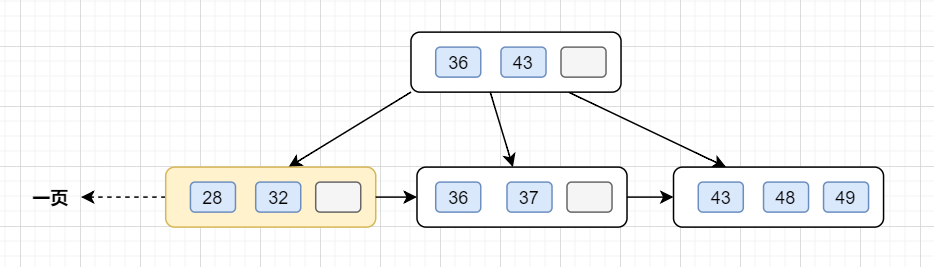
假設B+樹的高度為2的話,即有一個根結點和若干個葉子結點。這棵B+樹的存放總記錄數為=根結點指針數*單個葉子節點記錄行數。
- 如果一行記錄的數據大小為1k,那么單個葉子節點可以存的記錄數 =16k/1k =16.
- 非葉子節點內存放多少指針呢?我們假設主鍵ID為bigint類型,長度為8字節(面試官問你int類型,一個int就是32位,4字節),而指針大小在InnoDB源碼中設置為6字節,所以就是8+6=14字節,16k/14B =16*1024B/14B = 1170
因此,一棵高度為2的B+樹,能存放1170 * 16=18720條這樣的數據記錄。同理一棵高度為3的B+樹,能存放1170 *1170 *16 =21902400,也就是說,可以存放兩千萬左右的記錄。B+樹高度一般為1-3層,已經滿足千萬級別的數據存儲。
5、線程池的狀態有哪些?獲取多線程并發執行結果的方式有哪些?
線程池和線程的狀態是不一樣的哈,線程池有這幾個狀態:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//線程池狀態
privatestaticfinalintRUNNING=-1<
線程池各個狀態切換狀態圖如下:
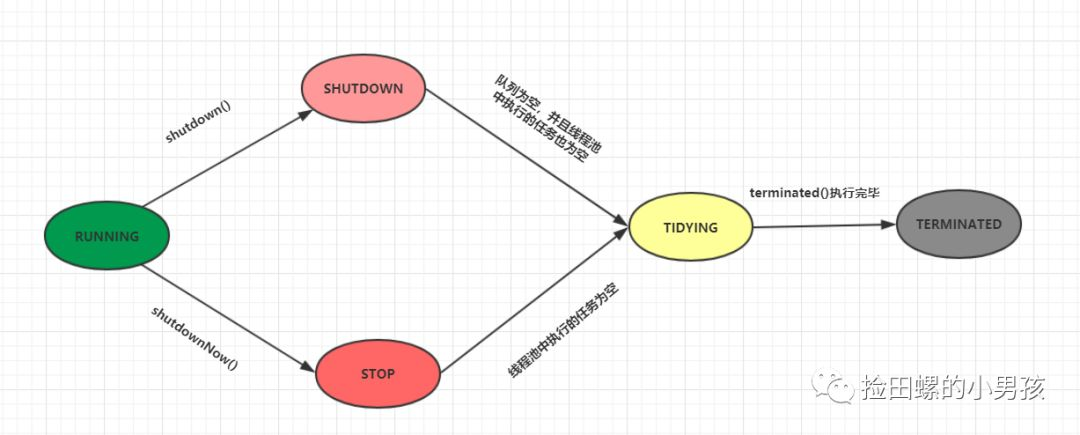
RUNNING
- 該狀態的線程池會接收新任務,并處理阻塞隊列中的任務;
-
調用線程池的
shutdown()方法,可以切換到SHUTDOWN狀態; -
調用線程池的
shutdownNow()方法,可以切換到STOP狀態;
SHUTDOWN
- 該狀態的線程池不會接收新任務,但會處理阻塞隊列中的任務;
- 隊列為空,并且線程池中執行的任務也為空,進入TIDYING狀態;
STOP
- 該狀態的線程不會接收新任務,也不會處理阻塞隊列中的任務,而且會中斷正在運行的任務;
- 線程池中執行的任務為空,進入TIDYING狀態;
TIDYING
- 該狀態表明所有的任務已經運行終止,記錄的任務數量為0。
-
terminated()執行完畢,進入TERMINATED狀態
TERMINATED
- 該狀態表示線程池徹底終止
6. 線程池原理?各個參數的作用。
ThreadPoolExecutor的構造函數:
publicThreadPoolExecutor(intcorePoolSize,intmaximumPoolSize,longkeepAliveTime,TimeUnitunit,
BlockingQueueworkQueue,
ThreadFactorythreadFactory,
RejectedExecutionHandlerhandler)
幾個核心參數的作用:
- corePoolSize:線程池核心線程數最大值
- maximumPoolSize:線程池最大線程數大小
- keepAliveTime:線程池中非核心線程空閑的存活時間大小
- unit:線程空閑存活時間單位
- workQueue:存放任務的阻塞隊列
- threadFactory:用于設置創建線程的工廠,可以給創建的線程設置有意義的名字,可方便排查問題。
- handler:線城池的飽和策略事件,主要有四種類型。
四種飽和拒絕策略
- AbortPolicy(拋出一個異常,默認的)
- DiscardPolicy(直接丟棄任務)
- DiscardOldestPolicy(丟棄隊列里最老的任務,將當前這個任務繼續提交給線程池)
- CallerRunsPolicy(交給線程池調用所在的線程進行處理)
線程池原理:
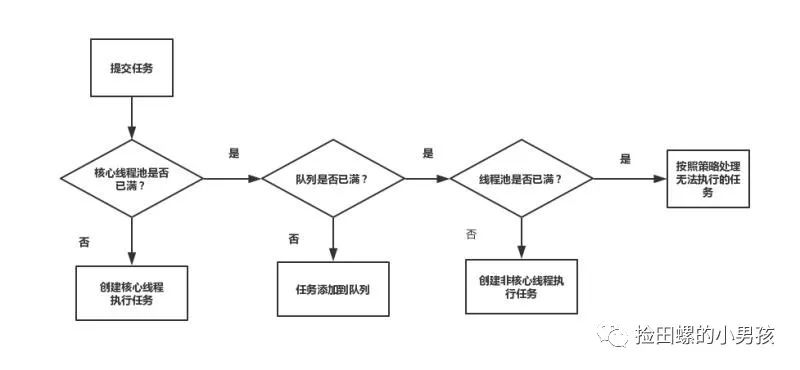
- 提交一個任務,線程池里存活的核心線程數小于線程數corePoolSize時,線程池會創建一個核心線程去處理提交的任務。
- 如果線程池核心線程數已滿,即線程數已經等于corePoolSize,一個新提交的任務,會被放進任務隊列workQueue排隊等待執行。
- 當線程池里面存活的線程數已經等于corePoolSize了,并且任務隊列workQueue也滿,判斷線程數是否達到maximumPoolSize,即最大線程數是否已滿,如果沒到達,創建一個非核心線程執行提交的任務。
- 如果當前的線程數達到了maximumPoolSize,還有新的任務過來的話,直接采用拒絕策略處理。
為了形象描述線程池執行,我打個比喻:
- 核心線程比作公司正式員工
- 非核心線程比作外包員工
- 阻塞隊列比作需求池
- 提交任務比作提需求
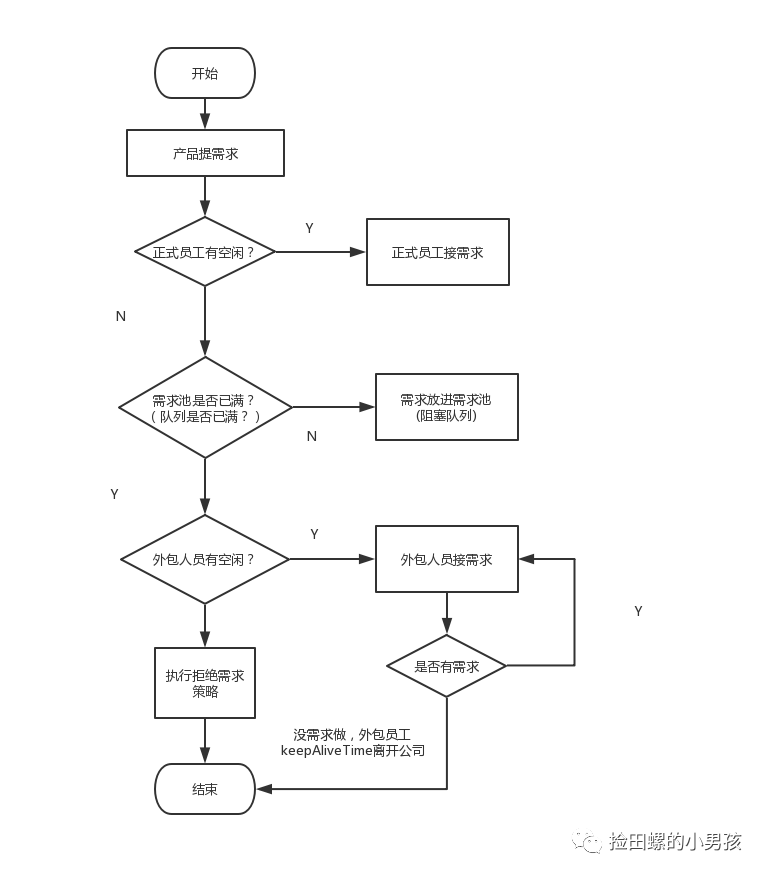
- 當產品提個需求,正式員工(核心線程)先接需求(執行任務)
- 如果正式員工都有需求在做,即核心線程數已滿),產品就把需求先放需求池(阻塞隊列)。
- 如果需求池(阻塞隊列)也滿了,但是這時候產品繼續提需求,怎么辦呢?那就請外包(非核心線程)來做。
- 如果所有員工(最大線程數也滿了)都有需求在做了,那就執行拒絕策略。
- 如果外包員工把需求做完了,它經過一段(keepAliveTime)空閑時間,就離開公司了。
7. ThreadLocal的使用場景有哪些?原理?內存泄漏?
ThreadLocal,即線程本地變量。如果你創建了一個ThreadLocal變量,那么訪問這個變量的每個線程都會有這個變量的一個本地拷貝,多個線程操作這個變量的時候,實際是操作自己本地內存里面的變量,從而起到線程隔離的作用,避免了線程安全問題。
ThreadLocal的應用場景
- 數據庫連接池
- 會話管理中使用
ThreadLocal內存結構圖:
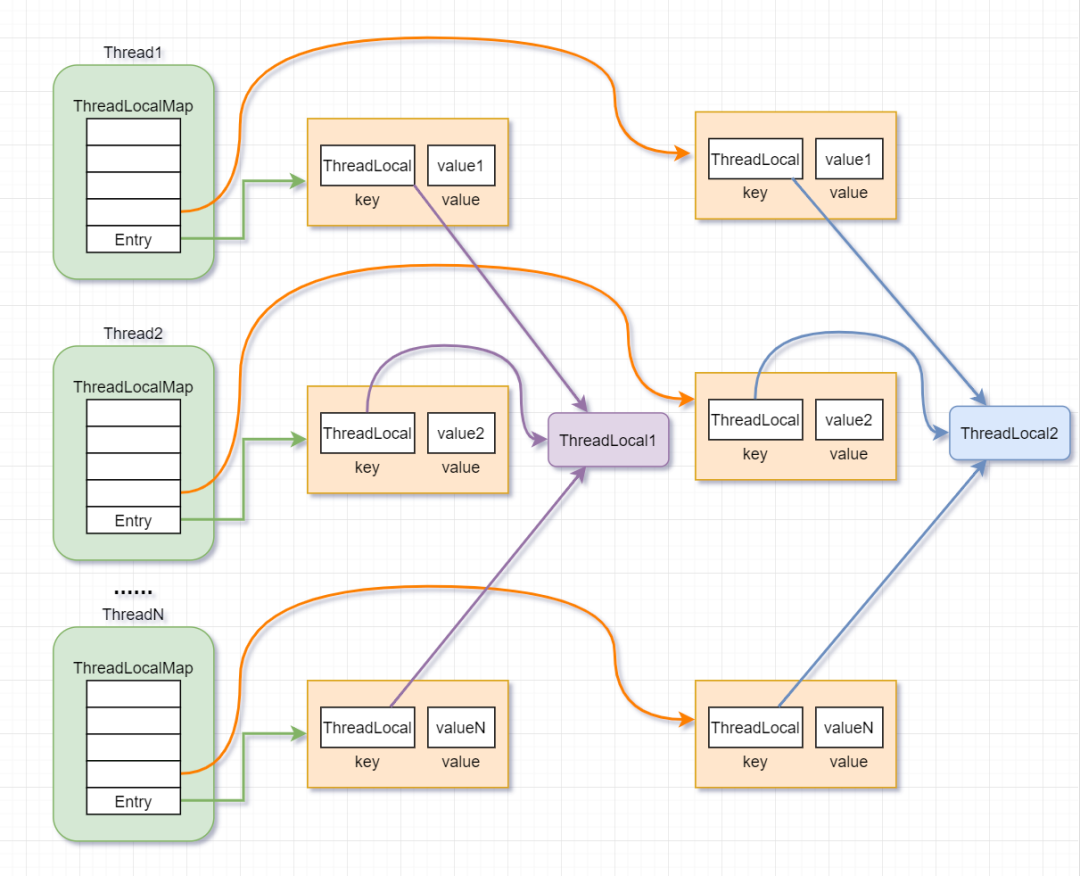
ThreadLocal原理
- Thread對象中持有一個ThreadLocal.ThreadLocalMap的成員變量。
- ThreadLocalMap內部維護了Entry數組,每個Entry代表一個完整的對象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
- 每個線程在往ThreadLocal里設置值的時候,都是往自己的ThreadLocalMap里存,讀也是以某個ThreadLocal作為引用,在自己的map里找對應的key,從而實現了線程隔離。
ThreadLocal 內存泄露問題
先看看一下的TreadLocal的引用示意圖哈,
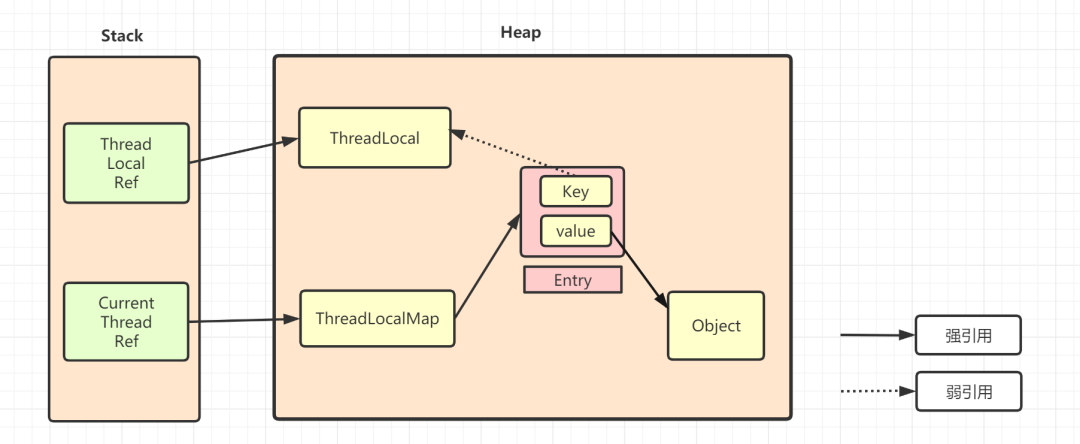
ThreadLocalMap中使用的 key 為 ThreadLocal 的弱引用,如下
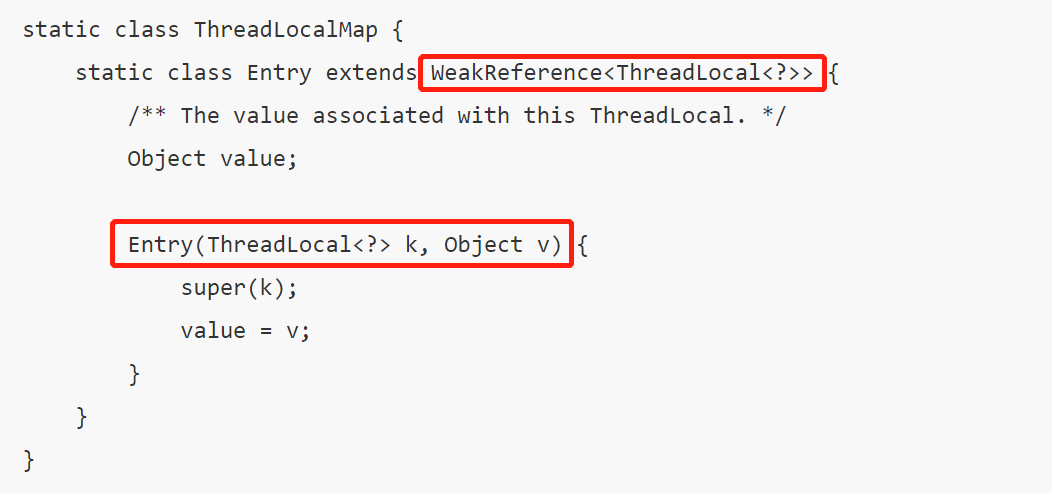
弱引用:只要垃圾回收機制一運行,不管JVM的內存空間是否充足,都會回收該對象占用的內存。
弱引用比較容易被回收。因此,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是因為ThreadLocalMap生命周期和Thread是一樣的,它這時候如果不被回收,就會出現這種情況:ThreadLocalMap的key沒了,value還在,這就會造成了內存泄漏問題。
如何解決內存泄漏問題?使用完ThreadLocal后,及時調用remove()方法釋放內存空間。
8、kafka是如何保證消息的有序性?
kafka這樣保證消息有序性的:
- 一個 topic,一個 partition,一個 consumer,內部單線程消費,單線程吞吐量太低,一般不會用這個。(全局有序性)
- 寫 N 個內存 queue,具有相同 key 的數據都到同一個內存 queue;然后對于 N 個線程,每個線程分別消費一個內存 queue 即可,這樣就能保證順序性。
大家可以看下消息隊列的有序性是怎么推導的哈:
消息的有序性,就是指可以按照消息的發送順序來消費。有些業務對消息的順序是有要求的,比如先下單再付款,最后再完成訂單,這樣等。假設生產者先后產生了兩條消息,分別是下單消息(M1),付款消息(M2),M1比M2先產生,如何保證M1比M2先被消費呢。
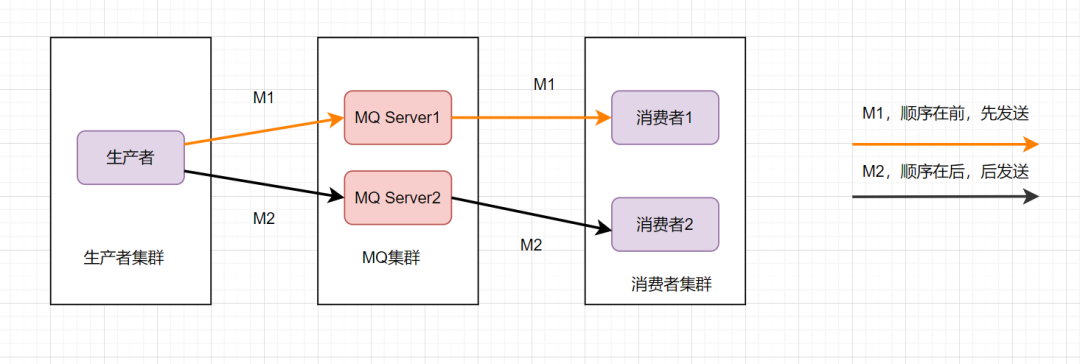
為了保證消息的順序性,可以將將M1、M2發送到同一個Server上,當M1發送完收到ack后,M2再發送。如圖:
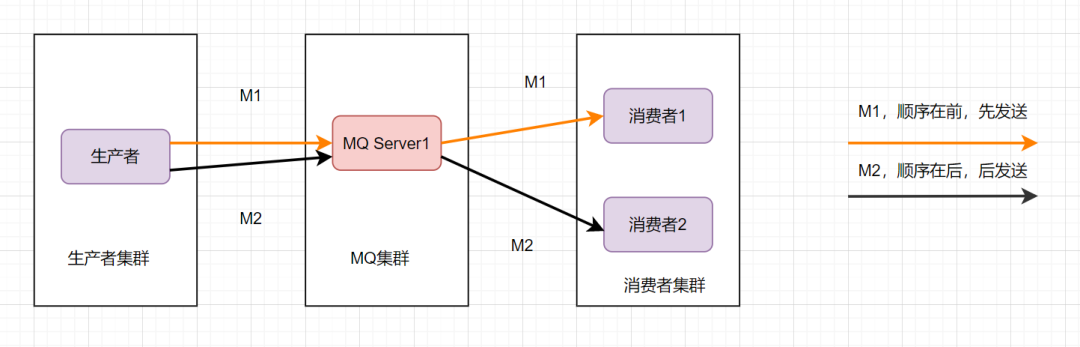
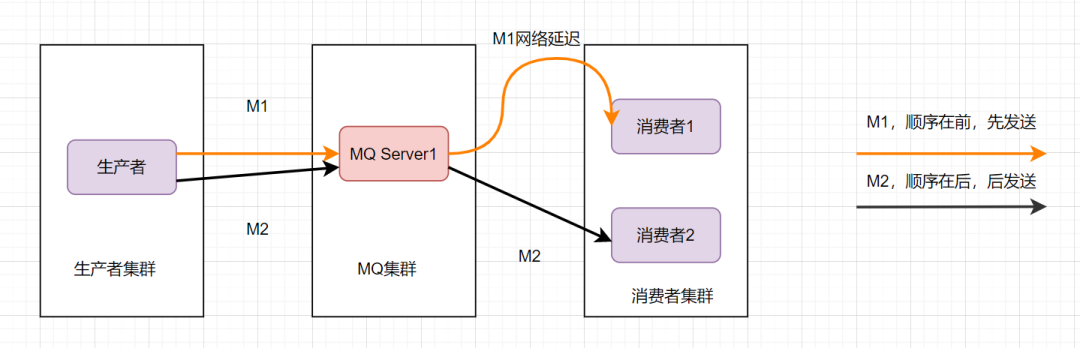
這樣還是可能會有問題,因為從MQ服務器到服務端,可能存在網絡延遲,雖然M1先發送,但是它比M2晚到。
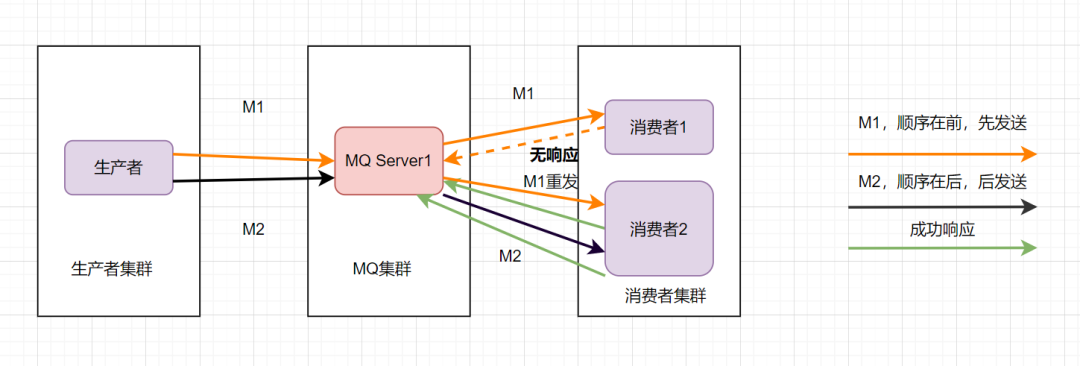
那還能怎么辦才能保證消息的順序性呢?將M1和M2發往同一個消費者,且發送M1后,等到消費端ACK成功后,才發送M2就得了。
消息隊列保證順序性整體思路就是這樣啦。比如Kafka的全局有序消息,就是這種思想的體現: 就是生產者發消息時,1個Topic只能對應1個Partition,一個Consumer,內部單線程消費。
但是這樣吞吐量太低,一般保證消息局部有序即可。在發消息的時候指定Partition Key,Kafka對其進行Hash計算,根據計算結果決定放入哪個Partition。這樣Partition Key相同的消息會放在同一個Partition。然后多消費者單線程消費指定的Partition。
9、Nacos的選舉機制了解嘛?說下Raft算法?
Nacos作為配置中心的功能是基于Raft算法來實現的。
Raft 算法是分布式系統開發首選的共識算法,它通過“一切以領導者為準”的方式,實現一系列值的共識和各節點日志的一致。
Raft選舉過程涉及三種角色和任期(Term):
- Follower:默默地接收和處理來自Leader的消息,當等待Leader心跳信息超時的時候,就主動站出來,推薦自己當Candidate。
- Candidate:向其他節點發送投票請求,通知其他節點來投票,如果贏得了大多數(N/2+1)選票,就晉升Leader。
- Leader:負責處理客戶端請求,進行日志復制等操作,每一輪選舉的目標就是選出一個領導者;領導者會不斷地發送心跳信息,通知其他節點“我是領導者,我還活著,你們不要發起新的選舉,不用找個新領導者來替代我。”
- Term:這跟民主社會的選舉很像,每一屆新的履職期稱之為一屆任期
領導選舉過程
- 在初始時,集群中所有的節點都是Follower狀態,都被設定一個隨機選舉超時時間(一般150ms-300ms):
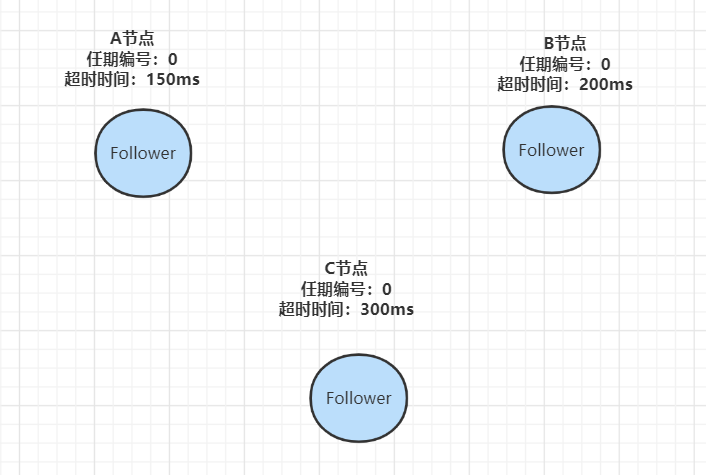
- 如果Follower在規定的超時時間,都沒有收到來自Leader的心跳,它就發起選舉:將自己的狀態切為 Candidate,增加自己的任期編號,然后向集群中的其它Follower節點發送請求,詢問其是否選舉自己成為Leader:
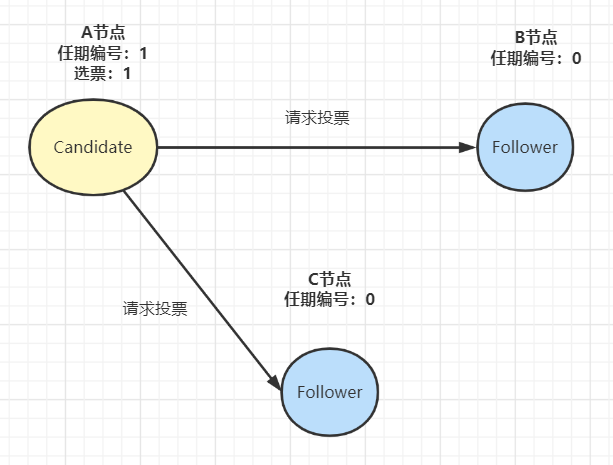
- 其他節點收到候選人A的請求投票消息后,如果在編號為1的這屆任期內還沒有進行過投票,那么它將把選票投給節點A,并增加自己的任期編號:
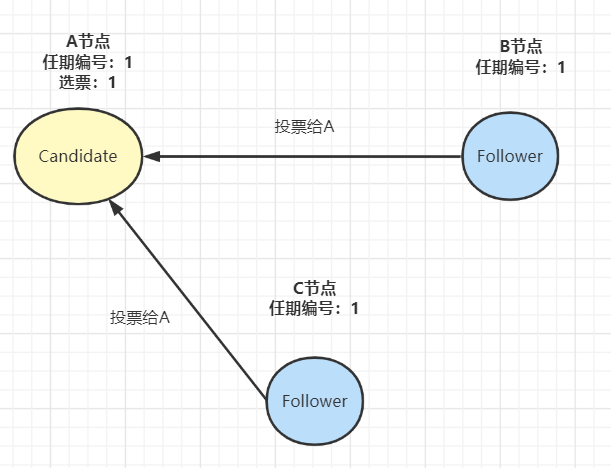
- 當收到來自集群中過半節點的接受投票后,A節點即成為本屆任期內 Leader,他將周期性地發送心跳消息,通知其他節點我是Leader,阻止Follower發起新的選舉:
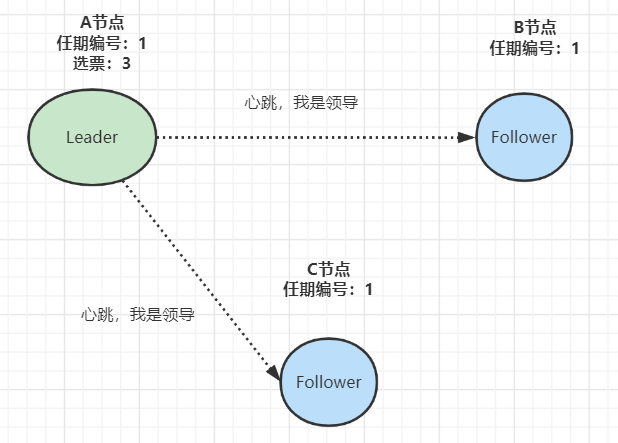
10、聊一聊TCC補償機制
TCC是分布式事務的一種解決方案。它采用了補償機制,其核心思想是:針對每個操作,都要注冊一個與其對應的確認和補償(撤銷)操作。TCC(Try-Confirm-Cancel)包括三段流程:
- try階段:嘗試去執行,完成所有業務的一致性檢查,預留必須的業務資源。
- Confirm階段:該階段對業務進行確認提交,不做任何檢查,因為try階段已經檢查過了,默認Confirm階段是不會出錯的。
- Cancel 階段:若業務執行失敗,則進入該階段,它會釋放try階段占用的所有業務資源,并回滾Confirm階段執行的所有操作。
下面再拿用戶下單購買禮物作為例子來模擬TCC實現分布式事務的過程:
假設用戶A余額為100金幣,擁有的禮物為5朵。A花了10個金幣,下訂單,購買10朵玫瑰。余額、訂單、禮物都在不同數據庫。
TCC的Try階段:
- 生成一條訂單記錄,訂單狀態為待確認。
- 將用戶A的賬戶金幣中余額更新為90,凍結金幣為10(預留業務資源)
- 將用戶的禮物數量為5,預增加數量為10。
- Try成功之后,便進入Confirm階段
- Try過程發生任何異常,均進入Cancel階段
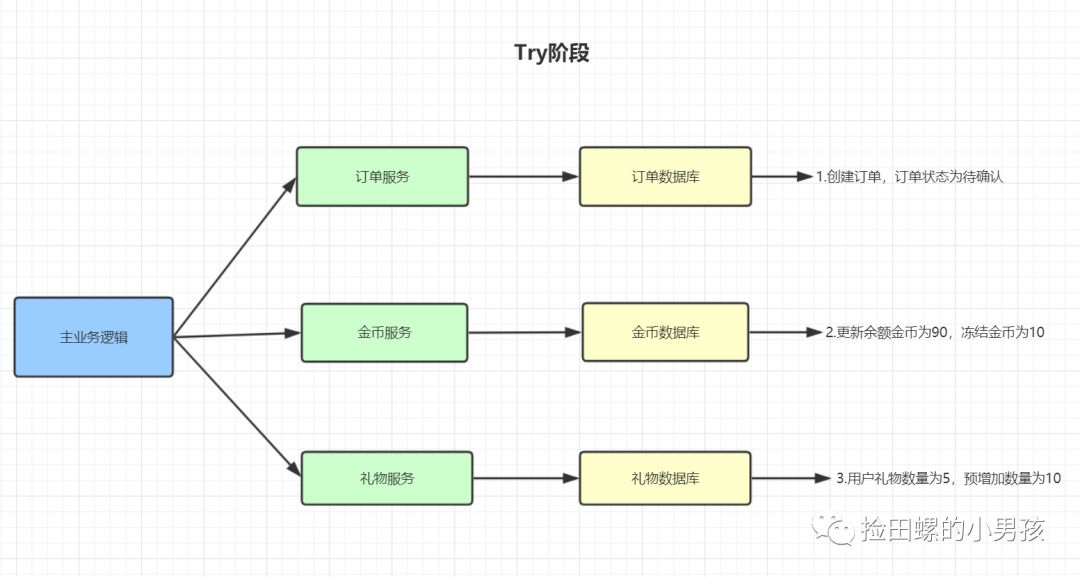
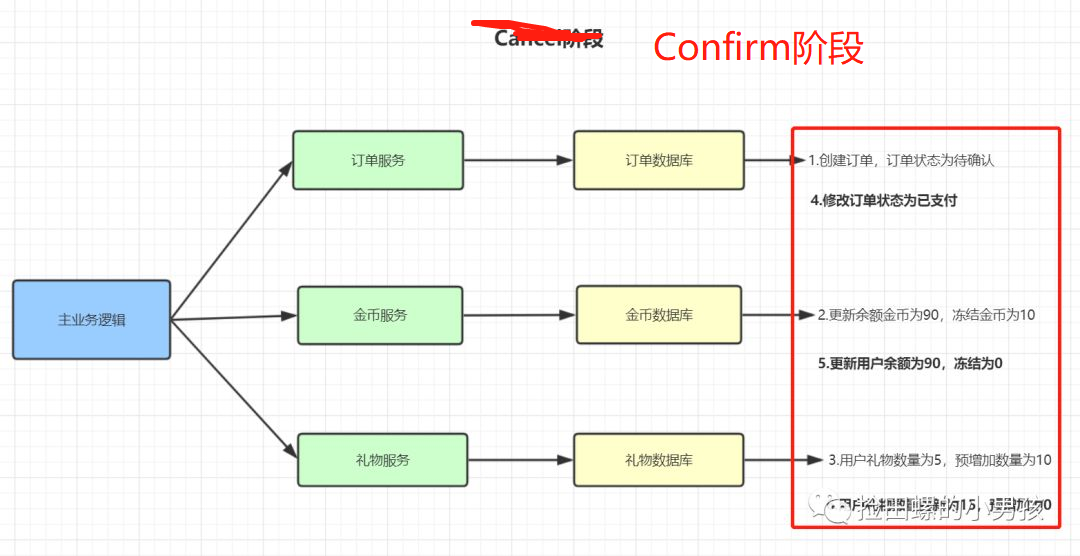
TCC的Confirm階段:
- 訂單狀態更新為已支付
- 更新用戶余額為90,可凍結為0
- 用戶禮物數量更新為15,預增加為0
- Confirm過程發生任何異常,均進入Cancel階段
- Confirm過程執行成功,則該事務結束
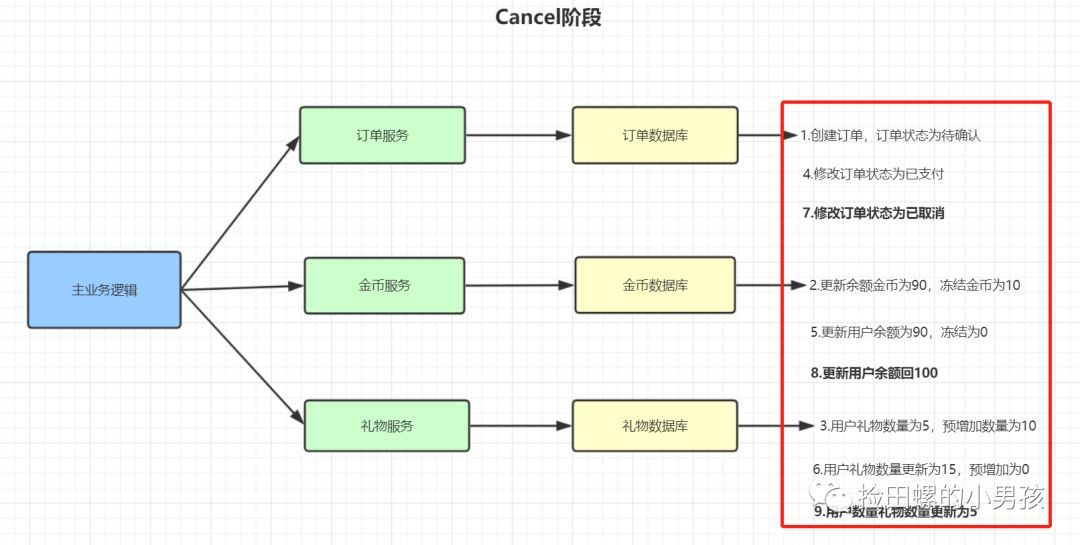
TCC的Cancel階段:
- 修改訂單狀態為已取消
- 更新用戶余額回100
- 更新用戶禮物數量為5
- TCC的優點是可以自定義數據庫操作的粒度,降低了鎖沖突,可以提升性能
- TCC的缺點是應用侵入性強,需要根據網絡、系統故障等不同失敗原因實現不同的回滾策略,實現難度大,一般借助TCC開源框架,ByteTCC,TCC-transaction等。
審核編輯 :李倩
-
存儲
+關注
關注
13文章
4346瀏覽量
86052 -
函數
+關注
關注
3文章
4344瀏覽量
62864 -
MySQL
+關注
關注
1文章
826瀏覽量
26667
原文標題:小廠后端十連問(附答案)
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
求一份evl-32px10的資料
求一份evl-32px10評估板的資料
【面試題】人工智能工程師高頻面試題匯總:機器學習深化篇(題目+答案)





 工商網監
工商網監
評論