") 如何改進(jìn)和加速擴散模型采樣的方法1
如何改進(jìn)和加速擴散模型采樣的方法1
這是一系列關(guān)于 NVIDIA 研究人員如何改進(jìn)和加速擴散模型采樣的方法的一部分,擴散模型是一種新穎而強大的生成模型。 Part 2 介紹了克服擴散模型中緩慢采樣挑戰(zhàn)的三種新技術(shù)。
生成模型是一類機器學(xué)習(xí)方法,它可以學(xué)習(xí)所訓(xùn)練數(shù)據(jù)的表示形式,并對數(shù)據(jù)本身進(jìn)行建模。它們通常基于深層神經(jīng)網(wǎng)絡(luò)。相比之下,判別模型通常預(yù)測給定數(shù)據(jù)的單獨數(shù)量。
生成模型允許您合成與真實數(shù)據(jù)不同但看起來同樣真實的新數(shù)據(jù)。設(shè)計師可以在汽車圖像上訓(xùn)練生成性模型,然后讓生成性人工智能計算出具有不同外觀的新穎汽車,從而加速藝術(shù)原型制作過程。
深度生成學(xué)習(xí)已成為機器學(xué)習(xí)領(lǐng)域的一個重要研究領(lǐng)域,并有許多相關(guān)應(yīng)用。生成模型廣泛用于圖像合成和各種圖像處理任務(wù),如編輯、修復(fù)、著色、去模糊和超分辨率。
生成性模型有可能簡化攝影師和數(shù)字藝術(shù)家的工作流程,并實現(xiàn)新水平的創(chuàng)造力。類似地,它們可能允許內(nèi)容創(chuàng)建者高效地為游戲、動畫電影或 metaverse 生成虛擬 3D 內(nèi)容。
基于深度學(xué)習(xí)的語音和語言合成已經(jīng)進(jìn)入消費品領(lǐng)域。醫(yī)學(xué)和醫(yī)療保健等領(lǐng)域也可能受益于生成性模型,例如生成對抗疾病的分子候選藥物的方法。
當(dāng)神經(jīng)網(wǎng)絡(luò)被用于不同的生成性學(xué)習(xí)任務(wù)時,尤其是對于不同的生成性學(xué)習(xí)任務(wù),神經(jīng)網(wǎng)絡(luò)和神經(jīng)網(wǎng)絡(luò)也可以被用于合成。
生成性學(xué)習(xí)三位一體
為了在實際應(yīng)用中得到廣泛采用,生成模型在理想情況下應(yīng)滿足以下關(guān)鍵要求:
High-quality sampling :許多應(yīng)用程序,尤其是那些直接與用戶交互的應(yīng)用程序,需要高生成質(zhì)量。例如,在語音生成中,語音質(zhì)量差是很難理解的。類似地,在圖像建模中,期望的輸出在視覺上與自然圖像無法區(qū)分。
模式覆蓋和樣本多樣性 :如果訓(xùn)練數(shù)據(jù)包含復(fù)雜或大量的多樣性,一個好的生成模型應(yīng)該在不犧牲生成質(zhì)量的情況下成功捕獲這種多樣性。
快速且計算成本低廉的采樣 :許多交互式應(yīng)用程序需要快速生成,例如實時圖像編輯。
雖然目前大多數(shù)深層生成性學(xué)習(xí)方法都注重高質(zhì)量的生成,但第二和第三個要求也非常重要。
忠實地表示數(shù)據(jù)的多樣性對于避免數(shù)據(jù)分布中遺漏少數(shù)模式至關(guān)重要。這有助于減少學(xué)習(xí)模型中不希望出現(xiàn)的偏差。
另一方面,在許多應(yīng)用程序中,數(shù)據(jù)分布的長尾巴特別有趣。例如,在交通建模中,人們感興趣的正是罕見的場景,即與危險駕駛或事故相對應(yīng)的場景。
降低計算復(fù)雜度和采樣時間不僅可以實現(xiàn)交互式實時應(yīng)用。它還通過降低發(fā)電所需的總功率使用量,減少了運行昂貴的深層神經(jīng)網(wǎng)絡(luò)(發(fā)電模型的基礎(chǔ))所造成的環(huán)境足跡。
在本文中,我們將這三個需求帶來的挑戰(zhàn)定義為 生成性學(xué)習(xí)三位一體 ,因為現(xiàn)有方法通常會做出權(quán)衡,無法同時滿足所有需求。
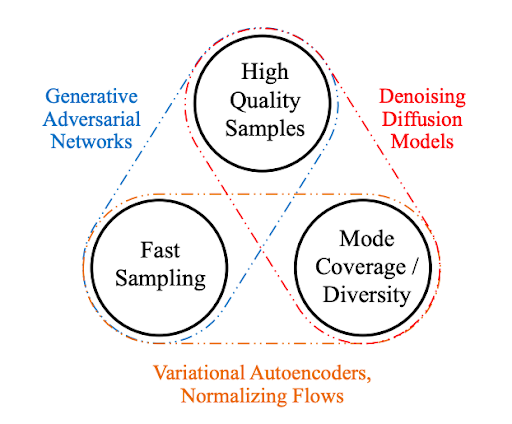
圖 1 生成性學(xué)習(xí)三位一體
基于擴散模型的生成性學(xué)習(xí)
最近,擴散模型已經(jīng)成為一種強大的生成性學(xué)習(xí)方法。這些模型,也被稱為去噪擴散模型或基于分?jǐn)?shù)的生成模型,表現(xiàn)出驚人的高樣本質(zhì)量,通常優(yōu)于生成性對抗網(wǎng)絡(luò)。它們還具有強大的模式覆蓋和樣本多樣性。
擴散模型已經(jīng)應(yīng)用于各種生成任務(wù),如圖像、語音、三維形狀和圖形合成。
擴散模型包括兩個過程:正向擴散和參數(shù)化反向擴散。
前向擴散過程通過逐漸擾動輸入數(shù)據(jù)將數(shù)據(jù)映射為噪聲。這是通過一個簡單的隨機過程正式實現(xiàn)的,該過程從數(shù)據(jù)樣本開始,使用簡單的高斯擴散核迭代生成噪聲較大的樣本。也就是說,在這個過程的每一步,高斯噪聲都會逐漸添加到數(shù)據(jù)中。
第二個過程是一個參數(shù)化的反向過程,取消正向擴散并執(zhí)行迭代去噪。這個過程代表數(shù)據(jù)合成,并經(jīng)過訓(xùn)練,通過將隨機噪聲轉(zhuǎn)換為真實數(shù)據(jù)來生成數(shù)據(jù)。它也被正式定義為一個隨機過程,使用可訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò)對輸入圖像進(jìn)行迭代去噪。
正向和反向過程通常使用數(shù)千個步驟來逐步注入噪聲,并在生成過程中進(jìn)行去噪。

圖 2 擴散模型處理數(shù)據(jù)和噪聲之間的移動
圖 2 顯示,在擴散模型中,固定前向過程以逐步方式逐漸擾動數(shù)據(jù),使其接近完全隨機噪聲。學(xué)習(xí)一個參數(shù)化的反向過程來執(zhí)行迭代去噪,并從噪聲中生成數(shù)據(jù),如圖像。
在形式上,通過x0表示一個數(shù)據(jù)點,例如圖像,通過xt表示時間步長t的擴散版本,正向過程由以下公式定義:

雖然離散時間擴散模型和連續(xù)時間擴散模型看起來可能不同,但它們有一個幾乎相同的生成過程。事實上,很容易證明離散時間擴散模型是連續(xù)時間模型的特殊離散化。
在實踐中使用連續(xù)時間擴散模型基本上要容易得多:
它們更通用,可以通過簡單的時間離散化轉(zhuǎn)換為離散時間模型。
它們是用 SDE 描述的, SDE 在各個科學(xué)領(lǐng)域都得到了很好的研究。
生成性 SDE 可以使用現(xiàn)成的數(shù)值 SDE 解算器進(jìn)行求解。
它們可以轉(zhuǎn)換為相關(guān)的常微分方程( ODE ),這些方程也得到了很好的研究,并且易于使用。
如前所述,擴散模型通過遵循反向擴散過程生成樣本,該過程將簡單的基本分布(通常為高斯分布)映射到復(fù)雜的數(shù)據(jù)分布。在生成 SDE 表示的連續(xù)時間擴散模型中,由于神經(jīng)網(wǎng)絡(luò)逼近分?jǐn)?shù)函數(shù)
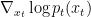
,這種映射通常很復(fù)雜。
用數(shù)值積分技術(shù)解決這個問題需要調(diào)用 1000 次深層神經(jīng)網(wǎng)絡(luò)來生成樣本。正因為如此,擴散模型在生成樣本時通常很慢,需要幾分鐘甚至幾小時的計算時間。這與生成性對抗網(wǎng)絡(luò)( GANs )等競爭性技術(shù)形成了鮮明對比,后者只需對神經(jīng)網(wǎng)絡(luò)進(jìn)行一次調(diào)用即可生成樣本。
總結(jié)
盡管擴散模型實現(xiàn)了較高的樣本質(zhì)量和多樣性,但不幸的是,它們在采樣速度方面存在不足。這限制了擴散模型在實際應(yīng)用中的廣泛采用,并導(dǎo)致了從這些模型加速采樣的研究領(lǐng)域的活躍。在 Part 2 中,我們回顧了 NVIDIA 為克服擴散模型的主要局限性而開發(fā)的三種技術(shù)。
關(guān)于作者
Arash Vahdat 是 NVIDIA research 的首席研究科學(xué)家,專攻計算機視覺和機器學(xué)習(xí)。在加入 NVIDIA 之前,他是 D-Wave 系統(tǒng)公司的研究科學(xué)家,從事深度生成學(xué)習(xí)和弱監(jiān)督學(xué)習(xí)。在 D-Wave 之前,阿拉什是西蒙·弗雷澤大學(xué)( Simon Fraser University , SFU )的一名研究人員,他領(lǐng)導(dǎo)了深度視頻分析的研究,并教授大數(shù)據(jù)機器學(xué)習(xí)的研究生課程。阿拉什在格雷格·莫里( Greg Mori )的指導(dǎo)下獲得了 SFU 的博士和理學(xué)碩士學(xué)位,致力于視覺分析的潛變量框架。他目前的研究領(lǐng)域包括深層生成學(xué)習(xí)、表征學(xué)習(xí)、高效神經(jīng)網(wǎng)絡(luò)和概率深層學(xué)習(xí)。
Karsten Kreis 是 NVIDIA 多倫多人工智能實驗室的高級研究科學(xué)家。在加入 NVIDIA 之前,他在 D-Wave Systems 從事深度生成建模工作,并與他人共同創(chuàng)立了變分人工智能,這是一家利用生成模型進(jìn)行藥物發(fā)現(xiàn)的初創(chuàng)公司。卡斯滕在馬克斯·普朗克光科學(xué)研究所獲得量子信息理論理學(xué)碩士學(xué)位,并在馬克斯·普朗克聚合物研究所獲得計算和統(tǒng)計物理博士學(xué)位。目前,卡斯滕的研究重點是開發(fā)新的生成性學(xué)習(xí)方法,以及將深層生成模型應(yīng)用于計算機視覺、圖形和數(shù)字藝術(shù)等領(lǐng)域的問題。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4991瀏覽量
103137 -
人工智能
+關(guān)注
關(guān)注
1791文章
47336瀏覽量
238696
發(fā)布評論請先 登錄
相關(guān)推薦
【「具身智能機器人系統(tǒng)」閱讀體驗】2.具身智能機器人大模型
淺談加密芯片的一種破解方法和加密方案改進(jìn)設(shè)計
浙大、微信提出精確反演采樣器新范式,徹底解決擴散模型反演問題

PyTorch GPU 加速訓(xùn)練模型方法
擴散模型的理論基礎(chǔ)

FPGA加速深度學(xué)習(xí)模型的案例
NVIDIA CorrDiff生成式AI模型能夠精準(zhǔn)預(yù)測臺風(fēng)
LLM大模型推理加速的關(guān)鍵技術(shù)
深度學(xué)習(xí)模型量化方法

python訓(xùn)練出的模型怎么調(diào)用
如何加速大語言模型推理
基于FPGA加速的熱擴散模擬器

谷歌推出AI擴散模型Lumiere
加速度傳感器的基本力學(xué)模型是什么
基于DiAD擴散模型的多類異常檢測工作






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論