") 如何在CUDA中使用驅(qū)動(dòng)程序API
如何在CUDA中使用驅(qū)動(dòng)程序API
驅(qū)動(dòng)程序 API 在 cuda 動(dòng)態(tài)庫(kù)(cuda.dll或cuda.so)中實(shí)現(xiàn),該庫(kù)在安裝設(shè)備驅(qū)動(dòng)程序期間復(fù)制到系統(tǒng)上。 它的所有入口點(diǎn)都以 cu 為前綴。
它是一個(gè)基于句柄的命令式 API:大多數(shù)對(duì)象都由不透明的句柄引用,這些句柄可以指定給函數(shù)來(lái)操作對(duì)象。
驅(qū)動(dòng)程序 API 中可用的對(duì)象匯總在下表中。Table 16. Objects Available in the CUDA Driver API

在調(diào)用驅(qū)動(dòng)程序 API 的任何函數(shù)之前,必須使用cuInit()初始化驅(qū)動(dòng)程序 API。 然后必須創(chuàng)建一個(gè)附加到特定設(shè)備的 CUDA 上下文,并使其成為當(dāng)前調(diào)用主機(jī)線(xiàn)程,如上下文中所述。
在 CUDA 上下文中,內(nèi)核作為 PTX 或二進(jìn)制對(duì)象由主機(jī)代碼顯式加載,如模塊中所述。 因此,用 C++ 編寫(xiě)的內(nèi)核必須單獨(dú)編譯成 PTX 或二進(jìn)制對(duì)象。 內(nèi)核使用 API 入口點(diǎn)啟動(dòng),如內(nèi)核執(zhí)行中所述。
任何想要在未來(lái)設(shè)備架構(gòu)上運(yùn)行的應(yīng)用程序都必須加載 PTX,而不是二進(jìn)制代碼。 這是因?yàn)槎M(jìn)制代碼是特定于體系結(jié)構(gòu)的,因此與未來(lái)的體系結(jié)構(gòu)不兼容,而 PTX 代碼在加載時(shí)由設(shè)備驅(qū)動(dòng)程序編譯為二進(jìn)制代碼。
以下是使用驅(qū)動(dòng)程序 API 編寫(xiě)的內(nèi)核示例的主機(jī)代碼:
int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Initialize input vectors
...
// Initialize
cuInit(0);
// Get number of devices supporting CUDA
int deviceCount = 0;
cuDeviceGetCount(&deviceCount);
if (deviceCount == 0) {
printf("There is no device supporting CUDA.\n");
exit (0);
}
// Get handle for device 0
CUdevice cuDevice;
cuDeviceGet(&cuDevice, 0);
// Create context
CUcontext cuContext;
cuCtxCreate(&cuContext, 0, cuDevice);
// Create module from binary file
CUmodule cuModule;
cuModuleLoad(&cuModule, "VecAdd.ptx");
// Allocate vectors in device memory
CUdeviceptr d_A;
cuMemAlloc(&d_A, size);
CUdeviceptr d_B;
cuMemAlloc(&d_B, size);
CUdeviceptr d_C;
cuMemAlloc(&d_C, size);
// Copy vectors from host memory to device memory
cuMemcpyHtoD(d_A, h_A, size);
cuMemcpyHtoD(d_B, h_B, size);
// Get function handle from module
CUfunction vecAdd;
cuModuleGetFunction(&vecAdd, cuModule, "VecAdd");
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
void* args[] = { &d_A, &d_B, &d_C, &N };
cuLaunchKernel(vecAdd,
blocksPerGrid, 1, 1, threadsPerBlock, 1, 1,
0, 0, args, 0);
...
}
完整的代碼可以在 vectorAddDrv CUDA 示例中找到。
L.1. Context
CUDA 上下文類(lèi)似于 CPU 進(jìn)程。驅(qū)動(dòng) API 中執(zhí)行的所有資源和操作都封裝在 CUDA 上下文中,當(dāng)上下文被銷(xiāo)毀時(shí),系統(tǒng)會(huì)自動(dòng)清理這些資源。除了模塊和紋理或表面引用等對(duì)象外,每個(gè)上下文都有自己獨(dú)特的地址空間。因此,來(lái)自不同上下文的 CUdeviceptr 值引用不同的內(nèi)存位置。
主機(jī)線(xiàn)程一次可能只有一個(gè)設(shè)備上下文當(dāng)前。當(dāng)使用 cuCtxCreate() 創(chuàng)建上下文時(shí),它對(duì)調(diào)用主機(jī)線(xiàn)程是當(dāng)前的。如果有效上下文不是線(xiàn)程當(dāng)前的,則在上下文中操作的 CUDA 函數(shù)(大多數(shù)不涉及設(shè)備枚舉或上下文管理的函數(shù))將返回 CUDA_ERROR_INVALID_CONTEXT。
每個(gè)主機(jī)線(xiàn)程都有一堆當(dāng)前上下文。 cuCtxCreate() 將新上下文推送到堆棧頂部。可以調(diào)用 cuCtxPopCurrent() 將上下文與主機(jī)線(xiàn)程分離。然后上下文是“浮動(dòng)的”,并且可以作為任何主機(jī)線(xiàn)程的當(dāng)前上下文推送。 cuCtxPopCurrent() 還會(huì)恢復(fù)先前的當(dāng)前上下文(如果有)。
還為每個(gè)上下文維護(hù)使用計(jì)數(shù)。 cuCtxCreate() 創(chuàng)建使用計(jì)數(shù)為 1 的上下文。cuCtxAttach() 增加使用計(jì)數(shù),而 cuCtxDetach() 減少使用計(jì)數(shù)。當(dāng)調(diào)用 cuCtxDetach() 或 cuCtxDestroy() 時(shí)使用計(jì)數(shù)變?yōu)?0,上下文將被銷(xiāo)毀。
驅(qū)動(dòng)程序 API 可與運(yùn)行時(shí)互操作,并且可以通過(guò) cuDevicePrimaryCtxRetain() 從驅(qū)動(dòng)程序 API 訪(fǎng)問(wèn)由運(yùn)行時(shí)管理的主上下文(參見(jiàn)初始化)。
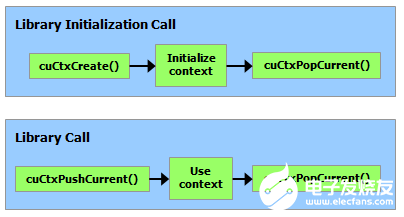
使用計(jì)數(shù)有助于在相同上下文中運(yùn)行的第三方編寫(xiě)的代碼之間的互操作性。例如,如果加載三個(gè)庫(kù)以使用相同的上下文,則每個(gè)庫(kù)將調(diào)用 cuCtxAttach() 來(lái)增加使用計(jì)數(shù),并在庫(kù)使用上下文完成時(shí)調(diào)用 cuCtxDetach() 來(lái)減少使用計(jì)數(shù)。對(duì)于大多數(shù)庫(kù),預(yù)計(jì)應(yīng)用程序會(huì)在加載或初始化庫(kù)之前創(chuàng)建上下文;這樣,應(yīng)用程序可以使用自己的啟發(fā)式方法創(chuàng)建上下文,并且?guī)熘恍鑼?duì)傳遞給它的上下文進(jìn)行操作。希望創(chuàng)建自己的上下文的庫(kù)(可能會(huì)或可能沒(méi)有創(chuàng)建自己的上下文的 API 客戶(hù)端不知道)將使用 cuCtxPushCurrent() 和 cuCtxPopCurrent(),如下圖所示。
L.2. Module
模塊是設(shè)備代碼和數(shù)據(jù)的動(dòng)態(tài)可加載包,類(lèi)似于 Windows 中的 DLL,由 nvcc 輸出(請(qǐng)參閱使用 NVCC 編譯)。 所有符號(hào)的名稱(chēng),包括函數(shù)、全局變量和紋理或表面引用,都在模塊范圍內(nèi)維護(hù),以便獨(dú)立第三方編寫(xiě)的模塊可以在相同的 CUDA 上下文中互操作。
此代碼示例加載一個(gè)模塊并檢索某個(gè)內(nèi)核的句柄:
CUmodule cuModule; cuModuleLoad(&cuModule, "myModule.ptx"); CUfunction myKernel; cuModuleGetFunction(&myKernel, cuModule, "MyKernel");
此代碼示例從 PTX 代碼編譯和加載新模塊并解析編譯錯(cuò)誤:
#define BUFFER_SIZE 8192
CUmodule cuModule;
CUjit_option options[3];
void* values[3];
char* PTXCode = "some PTX code";
char error_log[BUFFER_SIZE];
int err;
options[0] = CU_JIT_ERROR_LOG_BUFFER;
values[0] = (void*)error_log;
options[1] = CU_JIT_ERROR_LOG_BUFFER_SIZE_BYTES;
values[1] = (void*)BUFFER_SIZE;
options[2] = CU_JIT_TARGET_FROM_CUCONTEXT;
values[2] = 0;
err = cuModuleLoadDataEx(&cuModule, PTXCode, 3, options, values);
if (err != CUDA_SUCCESS)
printf("Link error:\n%s\n", error_log);
此代碼示例從多個(gè) PTX 代碼編譯、鏈接和加載新模塊,并解析鏈接和編譯錯(cuò)誤:
#define BUFFER_SIZE 8192
CUmodule cuModule;
CUjit_option options[6];
void* values[6];
float walltime;
char error_log[BUFFER_SIZE], info_log[BUFFER_SIZE];
char* PTXCode0 = "some PTX code";
char* PTXCode1 = "some other PTX code";
CUlinkState linkState;
int err;
void* cubin;
size_t cubinSize;
options[0] = CU_JIT_WALL_TIME;
values[0] = (void*)&walltime;
options[1] = CU_JIT_INFO_LOG_BUFFER;
values[1] = (void*)info_log;
options[2] = CU_JIT_INFO_LOG_BUFFER_SIZE_BYTES;
values[2] = (void*)BUFFER_SIZE;
options[3] = CU_JIT_ERROR_LOG_BUFFER;
values[3] = (void*)error_log;
options[4] = CU_JIT_ERROR_LOG_BUFFER_SIZE_BYTES;
values[4] = (void*)BUFFER_SIZE;
options[5] = CU_JIT_LOG_VERBOSE;
values[5] = (void*)1;
cuLinkCreate(6, options, values, &linkState);
err = cuLinkAddData(linkState, CU_JIT_INPUT_PTX,
(void*)PTXCode0, strlen(PTXCode0) + 1, 0, 0, 0, 0);
if (err != CUDA_SUCCESS)
printf("Link error:\n%s\n", error_log);
err = cuLinkAddData(linkState, CU_JIT_INPUT_PTX,
(void*)PTXCode1, strlen(PTXCode1) + 1, 0, 0, 0, 0);
if (err != CUDA_SUCCESS)
printf("Link error:\n%s\n", error_log);
cuLinkComplete(linkState, &cubin, &cubinSize);
printf("Link completed in %fms. Linker Output:\n%s\n", walltime, info_log);
cuModuleLoadData(cuModule, cubin);
cuLinkDestroy(linkState);
完整的代碼可以在 ptxjit CUDA 示例中找到。
L.3. Kernel Execution
cuLaunchKernel() 啟動(dòng)具有給定執(zhí)行配置的內(nèi)核。
參數(shù)可以作為指針數(shù)組(在 cuLaunchKernel() 的最后一個(gè)參數(shù)旁邊)傳遞,其中第 n 個(gè)指針對(duì)應(yīng)于第 n 個(gè)參數(shù)并指向從中復(fù)制參數(shù)的內(nèi)存區(qū)域,或者作為額外選項(xiàng)之一( cuLaunchKernel()) 的最后一個(gè)參數(shù)。
當(dāng)參數(shù)作為額外選項(xiàng)(CU_LAUNCH_PARAM_BUFFER_POINTER 選項(xiàng))傳遞時(shí),它們作為指向單個(gè)緩沖區(qū)的指針傳遞,在該緩沖區(qū)中,通過(guò)匹配設(shè)備代碼中每個(gè)參數(shù)類(lèi)型的對(duì)齊要求,參數(shù)被假定為彼此正確偏移。
表 4 列出了內(nèi)置向量類(lèi)型的設(shè)備代碼中的對(duì)齊要求。對(duì)于所有其他基本類(lèi)型,設(shè)備代碼中的對(duì)齊要求與主機(jī)代碼中的對(duì)齊要求相匹配,因此可以使用 __alignof() 獲得。唯一的例外是當(dāng)宿主編譯器在一個(gè)字邊界而不是兩個(gè)字邊界上對(duì)齊 double 和 long long(在 64 位系統(tǒng)上為 long)(例如,使用 gcc 的編譯標(biāo)志 -mno-align-double ) 因?yàn)樵谠O(shè)備代碼中,這些類(lèi)型總是在兩個(gè)字的邊界上對(duì)齊。
CUdeviceptr是一個(gè)整數(shù),但是代表一個(gè)指針,所以它的對(duì)齊要求是__alignof(void*)。
以下代碼示例使用宏 (ALIGN_UP()) 調(diào)整每個(gè)參數(shù)的偏移量以滿(mǎn)足其對(duì)齊要求,并使用另一個(gè)宏 (ADD_TO_PARAM_BUFFER()) 將每個(gè)參數(shù)添加到傳遞給 CU_LAUNCH_PARAM_BUFFER_POINTER 選項(xiàng)的參數(shù)緩沖區(qū)。
#define ALIGN_UP(offset, alignment) \
(offset) = ((offset) + (alignment) - 1) & ~((alignment) - 1)
char paramBuffer[1024];
size_t paramBufferSize = 0;
#define ADD_TO_PARAM_BUFFER(value, alignment) \
do { \
paramBufferSize = ALIGN_UP(paramBufferSize, alignment); \
memcpy(paramBuffer + paramBufferSize, \
&(value), sizeof(value)); \
paramBufferSize += sizeof(value); \
} while (0)
int i;
ADD_TO_PARAM_BUFFER(i, __alignof(i));
float4 f4;
ADD_TO_PARAM_BUFFER(f4, 16); // float4's alignment is 16
char c;
ADD_TO_PARAM_BUFFER(c, __alignof(c));
float f;
ADD_TO_PARAM_BUFFER(f, __alignof(f));
CUdeviceptr devPtr;
ADD_TO_PARAM_BUFFER(devPtr, __alignof(devPtr));
float2 f2;
ADD_TO_PARAM_BUFFER(f2, 8); // float2's alignment is 8
void* extra[] = {
CU_LAUNCH_PARAM_BUFFER_POINTER, paramBuffer,
CU_LAUNCH_PARAM_BUFFER_SIZE, ¶mBufferSize,
CU_LAUNCH_PARAM_END
};
cuLaunchKernel(cuFunction,
blockWidth, blockHeight, blockDepth,
gridWidth, gridHeight, gridDepth,
0, 0, 0, extra);
結(jié)構(gòu)的對(duì)齊要求等于其字段的對(duì)齊要求的最大值。 因此,包含內(nèi)置向量類(lèi)型 CUdeviceptr 或未對(duì)齊的 double 和 long long 的結(jié)構(gòu)的對(duì)齊要求可能在設(shè)備代碼和主機(jī)代碼之間有所不同。 這種結(jié)構(gòu)也可以用不同的方式填充。 例如,以下結(jié)構(gòu)在主機(jī)代碼中根本不填充,但在設(shè)備代碼中填充了字段 f 之后的 12 個(gè)字節(jié),因?yàn)樽侄?f4 的對(duì)齊要求是 16。
typedef struct {
float f;
float4 f4;
} myStruct;
L.4. Interoperability between Runtime and Driver APIs
應(yīng)用程序可以將運(yùn)行時(shí) API 代碼與驅(qū)動(dòng)程序 API 代碼混合。
如果通過(guò)驅(qū)動(dòng)程序 API 創(chuàng)建上下文并使其成為當(dāng)前上下文,則后續(xù)運(yùn)行時(shí)調(diào)用將獲取此上下文,而不是創(chuàng)建新上下文。
如果運(yùn)行時(shí)已初始化(如 CUDA 運(yùn)行時(shí)中提到的那樣),cuCtxGetCurrent() 可用于檢索在初始化期間創(chuàng)建的上下文。 后續(xù)驅(qū)動(dòng)程序 API 調(diào)用可以使用此上下文。
從運(yùn)行時(shí)隱式創(chuàng)建的上下文稱(chēng)為主上下文(請(qǐng)參閱初始化)。 它可以通過(guò)具有主要上下文管理功能的驅(qū)動(dòng)程序 API 進(jìn)行管理。
可以使用任一 API 分配和釋放設(shè)備內(nèi)存。 CUdeviceptr 可以轉(zhuǎn)換為常規(guī)指針,反之亦然:
CUdeviceptr devPtr; float* d_data; // Allocation using driver API cuMemAlloc(&devPtr, size); d_data = (float*)devPtr; // Allocation using runtime API cudaMalloc(&d_data, size); devPtr = (CUdeviceptr)d_data;
特別是,這意味著使用驅(qū)動(dòng)程序 API 編寫(xiě)的應(yīng)用程序可以調(diào)用使用運(yùn)行時(shí) API 編寫(xiě)的庫(kù)(例如 cuFFT、cuBLAS…)。
參考手冊(cè)的設(shè)備和版本管理部分的所有功能都可以互換使用。
L.5. Driver Entry Point Access
L.5.1. Introduction
驅(qū)動(dòng)程序入口點(diǎn)訪(fǎng)問(wèn) API 提供了一種檢索 CUDA 驅(qū)動(dòng)程序函數(shù)地址的方法。 從 CUDA 11.3 開(kāi)始,用戶(hù)可以使用從這些 API 獲得的函數(shù)指針調(diào)用可用的 CUDA 驅(qū)動(dòng)程序 API。
這些 API 提供的功能類(lèi)似于它們的對(duì)應(yīng)物,POSIX 平臺(tái)上的 dlsym 和 Windows 上的 GetProcAddress。 提供的 API 將允許用戶(hù):
使用 CUDA 驅(qū)動(dòng)程序 API 檢索驅(qū)動(dòng)程序函數(shù)的地址。
使用 CUDA 運(yùn)行時(shí) API 檢索驅(qū)動(dòng)程序函數(shù)的地址。
請(qǐng)求 CUDA 驅(qū)動(dòng)程序函數(shù)的每線(xiàn)程默認(rèn)流版本。 有關(guān)更多詳細(xì)信息,請(qǐng)參閱檢索每個(gè)線(xiàn)程的默認(rèn)流版本
使用較新的驅(qū)動(dòng)程序訪(fǎng)問(wèn)舊工具包上的新 CUDA 功能。
L.5.2. Driver Function Typedefs
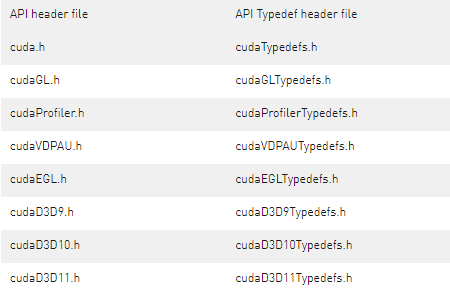
為了幫助檢索 CUDA 驅(qū)動(dòng)程序 API 入口點(diǎn),CUDA 工具包提供對(duì)包含所有 CUDA 驅(qū)動(dòng)程序 API 的函數(shù)指針定義的頭文件的訪(fǎng)問(wèn)。 這些頭文件與 CUDA Toolkit 一起安裝,并且在工具包的 include/ 目錄中可用。 下表總結(jié)了包含每個(gè) CUDA API 頭文件的 typedef 的頭文件。Table 17. Typedefs header files for CUDA driver APIs
上面的頭文件本身并沒(méi)有定義實(shí)際的函數(shù)指針; 他們?yōu)楹瘮?shù)指針定義了typedef。 例如,cudaTypedefs.h具有驅(qū)動(dòng) APIcuMemAlloc的以下typedef:
typedef CUresult (CUDAAPI *PFN_cuMemAlloc_v3020)(CUdeviceptr_v2 *dptr, size_t bytesize);
typedef CUresult (CUDAAPI *PFN_cuMemAlloc_v2000)(CUdeviceptr_v1 *dptr, unsigned int bytesize);
CUDA 驅(qū)動(dòng)程序符號(hào)具有基于版本的命名方案,其名稱(chēng)中帶有_v*擴(kuò)展名,但第一個(gè)版本除外。 當(dāng)特定 CUDA 驅(qū)動(dòng)程序 API 的簽名或語(yǔ)義發(fā)生變化時(shí),我們會(huì)增加相應(yīng)驅(qū)動(dòng)程序符號(hào)的版本號(hào)。 對(duì)于cuMemAlloc驅(qū)動(dòng)程序 API,第一個(gè)驅(qū)動(dòng)程序符號(hào)名稱(chēng)是cuMemAlloc,下一個(gè)符號(hào)名稱(chēng)是cuMemAlloc_v2。 CUDA 2.0 (2000) 中引入的第一個(gè)版本的typedef是PFN_cuMemAlloc_v2000。 CUDA 3.2 (3020) 中引入的下一個(gè)版本的typedef是PFN_cuMemAlloc_v3020。
typedef 可用于更輕松地在代碼中定義適當(dāng)類(lèi)型的函數(shù)指針:
PFN_cuMemAlloc_v3020 pfn_cuMemAlloc_v2;
PFN_cuMemAlloc_v2000 pfn_cuMemAlloc_v1;
如果用戶(hù)對(duì) API 的特定版本感興趣,則上述方法更可取。 此外,頭文件中包含所有驅(qū)動(dòng)程序符號(hào)的最新版本的預(yù)定義宏,這些驅(qū)動(dòng)程序符號(hào)在安裝的 CUDA 工具包發(fā)布時(shí)可用; 這些typedef沒(méi)有_v*后綴。 對(duì)于 CUDA 11.3 工具包,cuMemAlloc_v2是最新版本,所以我們也可以定義它的函數(shù)指針如下:
PFN_cuMemAlloc pfn_cuMemAlloc;
L.5.3. Driver Function Retrieval
使用驅(qū)動(dòng)程序入口點(diǎn)訪(fǎng)問(wèn) API 和適當(dāng)?shù)?typedef,我們可以獲得指向任何 CUDA 驅(qū)動(dòng)程序 API 的函數(shù)指針。
L.5.3.1. Using the driver API
驅(qū)動(dòng)程序 API 需要 CUDA 版本作為參數(shù)來(lái)獲取請(qǐng)求的驅(qū)動(dòng)程序符號(hào)的 ABI 兼容版本。 CUDA 驅(qū)動(dòng)程序 API 有一個(gè)以 _v* 擴(kuò)展名表示的按功能 ABI。 例如,考慮 cudaTypedefs.h 中 cuStreamBeginCapture 的版本及其對(duì)應(yīng)的 typedef:
// cuda.h
CUresult CUDAAPI cuStreamBeginCapture(CUstream hStream);
CUresult CUDAAPI cuStreamBeginCapture_v2(CUstream hStream, CUstreamCaptureMode mode);
// cudaTypedefs.h
typedef CUresult (CUDAAPI *PFN_cuStreamBeginCapture_v10000)(CUstream hStream);
typedef CUresult (CUDAAPI *PFN_cuStreamBeginCapture_v10010)(CUstream hStream, CUstreamCaptureMode mode);
從上述代碼片段中的typedefs,版本后綴_v10000和_v10010表示上述API分別在CUDA 10.0和CUDA 10.1中引入。
#include
// Declare the entry points for cuStreamBeginCapture
PFN_cuStreamBeginCapture_v10000 pfn_cuStreamBeginCapture_v1;
PFN_cuStreamBeginCapture_v10010 pfn_cuStreamBeginCapture_v2;
// Get the function pointer to the cuStreamBeginCapture driver symbol
cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_v1, 10000, CU_GET_PROC_ADDRESS_DEFAULT);
// Get the function pointer to the cuStreamBeginCapture_v2 driver symbol
cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_v2, 10010, CU_GET_PROC_ADDRESS_DEFAULT);
參考上面的代碼片段,要檢索到驅(qū)動(dòng)程序 API cuStreamBeginCapture 的 _v1 版本的地址,CUDA 版本參數(shù)應(yīng)該正好是 10.0 (10000)。同樣,用于檢索 _v2 版本 API 的地址的 CUDA 版本應(yīng)該是 10.1 (10010)。為檢索特定版本的驅(qū)動(dòng)程序 API 指定更高的 CUDA 版本可能并不總是可移植的。例如,在此處使用 11030 仍會(huì)返回 _v2 符號(hào),但如果在 CUDA 11.3 中發(fā)布假設(shè)的 _v3 版本,則當(dāng)與 CUDA 11.3 驅(qū)動(dòng)程序配對(duì)時(shí),cuGetProcAddress API 將開(kāi)始返回較新的 _v3 符號(hào)。由于 _v2 和 _v3 符號(hào)的 ABI 和函數(shù)簽名可能不同,使用用于 _v2 符號(hào)的 _v10010 typedef 調(diào)用 _v3 函數(shù)將表現(xiàn)出未定義的行為。
要檢索給定 CUDA 工具包的驅(qū)動(dòng)程序 API 的最新版本,我們還可以指定 CUDA_VERSION 作為版本參數(shù),并使用未版本化的 typedef 來(lái)定義函數(shù)指針。由于 _v2 是 CUDA 11.3 中驅(qū)動(dòng)程序 API cuStreamBeginCapture 的最新版本,因此下面的代碼片段顯示了檢索它的不同方法。
// Assuming we are using CUDA 11.3 Toolkit
#include
// Declare the entry point
PFN_cuStreamBeginCapture pfn_cuStreamBeginCapture_latest;
// Intialize the entry point. Specifying CUDA_VERSION will give the function pointer to the
// cuStreamBeginCapture_v2 symbol since it is latest version on CUDA 11.3.
cuGetProcAddress("cuStreamBeginCapture", &pfn_cuStreamBeginCapture_latest, CUDA_VERSION, CU_GET_PROC_ADDRESS_DEFAULT);
請(qǐng)注意,請(qǐng)求具有無(wú)效 CUDA 版本的驅(qū)動(dòng)程序 API 將返回錯(cuò)誤 CUDA_ERROR_NOT_FOUND。 在上面的代碼示例中,傳入小于 10000 (CUDA 10.0) 的版本將是無(wú)效的。
L.5.3.2. Using the runtime API
運(yùn)行時(shí) API 使用 CUDA 運(yùn)行時(shí)版本來(lái)獲取請(qǐng)求的驅(qū)動(dòng)程序符號(hào)的 ABI 兼容版本。 在下面的代碼片段中,所需的最低 CUDA 運(yùn)行時(shí)版本將是 CUDA 11.2,因?yàn)楫?dāng)時(shí)引入了 cuMemAllocAsync。
#include
// Declare the entry point
PFN_cuMemAllocAsync pfn_cuMemAllocAsync;
// Intialize the entry point. Assuming CUDA runtime version >= 11.2
cudaGetDriverEntryPoint("cuMemAllocAsync", &pfn_cuMemAllocAsync, cudaEnableDefault);
// Call the entry point
pfn_cuMemAllocAsync(...);
L.5.3.3. Retrieve per-thread default stream versions
一些 CUDA 驅(qū)動(dòng)程序 API 可以配置為具有默認(rèn)流或每線(xiàn)程默認(rèn)流語(yǔ)義。具有每個(gè)線(xiàn)程默認(rèn)流語(yǔ)義的驅(qū)動(dòng)程序 API 在其名稱(chēng)中以 _ptsz 或 _ptds 為后綴。例如,cuLaunchKernel 有一個(gè)名為 cuLaunchKernel_ptsz 的每線(xiàn)程默認(rèn)流變體。使用驅(qū)動(dòng)程序入口點(diǎn)訪(fǎng)問(wèn) API,用戶(hù)可以請(qǐng)求驅(qū)動(dòng)程序 API cuLaunchKernel 的每線(xiàn)程默認(rèn)流版本,而不是默認(rèn)流版本。為默認(rèn)流或每線(xiàn)程默認(rèn)流語(yǔ)義配置 CUDA 驅(qū)動(dòng)程序 API 會(huì)影響同步行為。更多詳細(xì)信息可以在這里找到。
驅(qū)動(dòng)API的默認(rèn)流或每線(xiàn)程默認(rèn)流版本可以通過(guò)以下方式之一獲得:
使用編譯標(biāo)志 --default-stream per-thread 或定義宏 CUDA_API_PER_THREAD_DEFAULT_STREAM 以獲取每個(gè)線(xiàn)程的默認(rèn)流行為。
分別使用標(biāo)志 CU_GET_PROC_ADDRESS_LEGACY_STREAM/cudaEnableLegacyStream 或 CU_GET_PROC_ADDRESS_PER_THREAD_DEFAULT_STREAM/cudaEnablePerThreadDefaultStream 強(qiáng)制默認(rèn)流或每個(gè)線(xiàn)程的默認(rèn)流行為。
L.5.3.4. Access new CUDA features
始終建議安裝最新的 CUDA 工具包以訪(fǎng)問(wèn)新的 CUDA 驅(qū)動(dòng)程序功能,但如果出于某種原因,用戶(hù)不想更新或無(wú)法訪(fǎng)問(wèn)最新的工具包,則可以使用 API 來(lái)訪(fǎng)問(wèn)新的 CUDA 功能 只有更新的 CUDA 驅(qū)動(dòng)程序。 為了討論,讓我們假設(shè)用戶(hù)使用 CUDA 11.3,并希望使用 CUDA 12.0 驅(qū)動(dòng)程序中提供的新驅(qū)動(dòng)程序 API cuFoo。 下面的代碼片段說(shuō)明了這個(gè)用例:
int main()
{
// Assuming we have CUDA 12.0 driver installed.
// Manually define the prototype as cudaTypedefs.h in CUDA 11.3 does not have the cuFoo typedef
typedef CUresult (CUDAAPI *PFN_cuFoo)(...);
PFN_cuFoo pfn_cuFoo = NULL;
// Get the address for cuFoo API using cuGetProcAddress. Specify CUDA version as
// 12000 since cuFoo was introduced then or get the driver version dynamically
// using cuDriverGetVersion
int driverVersion;
cuDriverGetVersion(&driverVersion);
cuGetProcAddress("cuFoo", &pfn_cuFoo, driverVersion, CU_GET_PROC_ADDRESS_DEFAULT);
if (pfn_cuFoo) {
pfn_cuFoo(...);
}
else {
printf("Cannot retrieve the address to cuFoo. Check if the latest driver for CUDA 12.0 is installed.\n");
assert(0);
}
// rest of code here
關(guān)于作者
Ken He 是 NVIDIA 企業(yè)級(jí)開(kāi)發(fā)者社區(qū)經(jīng)理 & 高級(jí)講師,擁有多年的 GPU 和人工智能開(kāi)發(fā)經(jīng)驗(yàn)。自 2017 年加入 NVIDIA 開(kāi)發(fā)者社區(qū)以來(lái),完成過(guò)上百場(chǎng)培訓(xùn),幫助上萬(wàn)個(gè)開(kāi)發(fā)者了解人工智能和 GPU 編程開(kāi)發(fā)。在計(jì)算機(jī)視覺(jué),高性能計(jì)算領(lǐng)域完成過(guò)多個(gè)獨(dú)立項(xiàng)目。并且,在機(jī)器人和無(wú)人機(jī)領(lǐng)域,有過(guò)豐富的研發(fā)經(jīng)驗(yàn)。對(duì)于圖像識(shí)別,目標(biāo)的檢測(cè)與跟蹤完成過(guò)多種解決方案。曾經(jīng)參與 GPU 版氣象模式GRAPES,是其主要研發(fā)者。
審核編輯:郭婷
-
API
+關(guān)注
關(guān)注
2文章
1507瀏覽量
62223 -
應(yīng)用程序
+關(guān)注
關(guān)注
37文章
3285瀏覽量
57787 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13648
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
適用于Oracle的ODBC驅(qū)動(dòng)程序
Linux驅(qū)動(dòng)程序程序員指南

pcie設(shè)備驅(qū)動(dòng)程序安裝步驟
硬盤(pán)電機(jī)怎么驅(qū)動(dòng)程序?它有什么典型特征?
如何在TMS320DM643x器件上使用EDMA3驅(qū)動(dòng)程序
LSP 2.10 DaVinci Linux驅(qū)動(dòng)程序
Linux設(shè)備驅(qū)動(dòng)程序分類(lèi)有哪些
linux驅(qū)動(dòng)程序如何加載進(jìn)內(nèi)核
linux驅(qū)動(dòng)程序主要有哪些功能
linux驅(qū)動(dòng)程序的編譯方法是什么
linux驅(qū)動(dòng)程序運(yùn)行在什么空間
虹科技術(shù) Linux環(huán)境再升級(jí):PLIN驅(qū)動(dòng)程序正式發(fā)布

請(qǐng)問(wèn)cmakelists中的變量如何在程序中使用?
實(shí)現(xiàn)機(jī)器人操作系統(tǒng)——ADI Trinamic電機(jī)控制器ROS1驅(qū)動(dòng)程序簡(jiǎn)介

怎么編寫(xiě)Framebuffer驅(qū)動(dòng)程序






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論