 存內計算并不滿足于現有的算力
存內計算并不滿足于現有的算力
談到存內計算,大部分人的第一印象就是超低功耗和大算力。存內計算技術打破了馮諾依曼架構的限制,沖破了內存墻,為半導體產業帶來了新的創新。但你可能會問,存內計算的應用場景到底有哪些呢?
邊緣計算的下一步
邊緣計算可以說是眾多存內計算技術與公司走的第一步,存內計算憑借其低功耗的特性,可穿戴等端側設備可以說是為該技術量身定制的。在其架構的優越性之下,存內計算又比一眾傳統邊緣AI芯片有著更加可觀的算力。所以,對于智能手表、智能眼鏡這類對功耗需求高,又有一定AI計算需求的應用來說,存內計算芯片無疑是不二之選。
不過如今的MCU已經將功耗降到了極低的水準,部分也能完成一些簡單的AI運算,如果僅僅是在語音識別、事件檢測這些應用上來競爭的話,即便這些存內計算有優勢,可能在實際使用過程中,除了續航之外,用戶的切身感知到的變化會比較小。

WTM2101存內計算芯片 / 知存科技
但邊緣計算并不只局限于此,還有圖像處理這一老大難亟待解決,這一應用相比上述那些又有著更高的算力要求。國內領先的存內計算公司知存科技近日透露,他們正在打造算力更強的下一代存內計算芯片就是面向超清視頻處理的,根據其給出的演示所示,該芯片主要針對AI插幀、AI超分辨率、AI視頻降噪和AI高動態分辨率,這些在邊緣端感知更加明顯的AI應用。
而以上這些AI應用,也僅僅只是存內計算往智能手機等消費級邊緣端走的下一步,邊緣AI芯片的終極目標都是自動駕駛。如若能做到更高的算力,存內計算芯片就有機會沖進汽車市場,與自動駕駛芯片的玩家硬碰硬。
超越GPU的算力
既然存內計算已經證實了自己在邊緣端的算力優勢,那有沒有機會與GPU這類算力猛禽一決高下呢?我們以波動仿真為例,波動仿真在許多應用中都有普及,比如醫學影像、石油勘探、減輕地震災害以及國防系統等。然而大部分應用在使用波動仿真時,都要用到超級計算機對波動方程多重求解。雖然這類應用不像可穿戴一樣,對于成本和體積要求不高,但對于速度和能耗還是比較重視的。
目前主導的波動仿真解決方案還是CPU和GPU,但由于本身的并行性缺失,即便是高端的CPU運行再小的問題,也需要大量時間才能完成計算。而GPU憑借其巨大的內存帶寬優勢,無疑擁有著更高的速度。即便如此,在實際應用中,波動仿真是一個極端的數據移動過程,GPU依然會遇到瓶頸,即便幾百GB/s的內存帶寬沒法免受影響,最終導致用于數據移動的功耗甚至高于計算的功耗。
而存內計算可以減少處理器之間的數據移動,因為它消除了片外與片內存儲之間的數據移動,但存內之間的數據移動依然是一大問題。埃克森美孚的研究人員就想出了Wave-PIM這種存內計算方案,利用超大規模集成電路常用的H樹架構,來減少內存區塊之間數據移動的延遲。他們以900GB/s帶寬的16GB HBM2內存進行模擬,得出了52.8TFLOPS(FP32)的成績,超過了Tesla V100 GPU。這證明了存內計算芯片,即使是在服務器級和HPC級的應用上,也有著獨到的優勢。

UPMEM PIM / UPMEM
不過如今GPU內存帶寬已經隨著HBM3和英偉達的H100芯片做到了3TB/s,而業界目前在內存帶寬上占優的存內計算方案,法國公司UPMEM的DDR4 PIM,也只做到了2.5TB/s。哪怕存內計算有著功耗上的巨大優勢,但性能上要想進一步超越GPU,還是需要更先進的內存技術和更多的架構創新。好在如今越來越多的公司開始走上存內計算的商業化嘗試,存儲廠商們雖然還沒有確定走這一方向,但存內計算與其發展技術并無沖突,而且從生產創新和投資方向來看,他們已經開始布局這一技術了,未來高性能計算上很有可能出現存儲廠商與GPU廠商互卷的情況。
-
半導體產業
+關注
關注
6文章
509瀏覽量
34344 -
邊緣計算
+關注
關注
22文章
3092瀏覽量
48965 -
算力
+關注
關注
1文章
977瀏覽量
14822
發布評論請先 登錄
相關推薦
存算于芯 · 智啟未來 — 2024蘋芯科技產品發布會盛大召開

aic3106作為slave,sclk與Wclk是否可以不滿足sclk=2*wclk*采樣位數?
存力與算力并重:數據時代的雙刃劍
當運放用作比較器時,虛短特性是不滿足的,為什么還會出現?
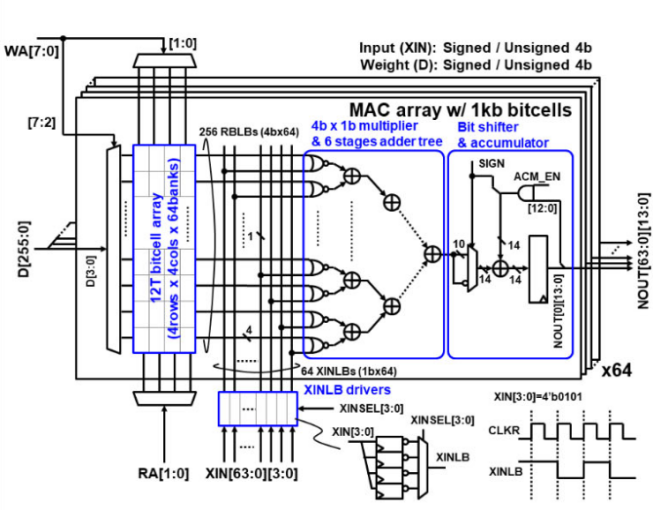

探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究






 工商網監
工商網監
評論