 使用Transformers的企業數據挑戰解決方案
使用Transformers的企業數據挑戰解決方案
大數據、新算法和快速計算是使現代 AI 革命成為可能的三個主要因素。然而,數據給企業帶來了許多挑戰:數據標記困難、數據治理效率低下、數據可用性有限、數據隱私等。
綜合生成的數據是解決這些挑戰的潛在解決方案,因為它通過從模型中采樣來生成數據點。連續采樣可以生成無限多的數據點,包括標簽。這允許跨團隊或外部共享數據。
生成合成數據還可以在不影響質量或真實性的情況下提供一定程度的數據隱私。成功的合成數據生成涉及在保持隱私的同時捕獲分布,并有條件地生成新數據,然后這些數據可用于建立更穩健的模型或用于時間序列預測。
在這篇文章中,我們以 NVIDIA NeMo 為例,解釋如何用 transformer 模型人工生成合成數據。我們解釋了如何在 machine learning 算法中使用合成生成的數據作為真實數據的有效替代品,以保護用戶隱私,同時做出準確的預測。
變壓器:更好的合成數據發生器
Deep learning 生成模型自然適合對復雜的現實世界數據建模。兩種流行的生成模型在過去取得了一些成功:可變自動編碼器( VAE )和生成對抗網絡( GAN )。
然而,合成數據生成的 VAE 和 GAN 模型存在已知問題:
GAN 模型中的 模式崩潰問題 會導致生成的數據錯過訓練數據分布中的某些模式。
由于非自回歸損失, VAE 模型難以生成尖銳的數據點。
Transformer Models 最近在自然語言處理( NLP )領域取得了巨大的成功。 transformer 模型的自我注意編碼和解碼架構已被證明在建模數據分布方面是準確的,并且可擴展到更大的數據集。例如, NVIDIA Megatron-Turing NLG 模型使用 530B 參數獲得了優異的結果。
GPT
OpenAI’s GPT3 使用 transformer 模型的解碼器部分,具有 175B 參數。 GPT3 已廣泛應用于多個行業和領域,從生產力和教育到創意和游戲。
GPT 模型被證明是一種優越的生成模型。如你所知,任何聯合概率分布都可以根據 概率鏈規則 分解成一系列條件概率分布的乘積。 GPT 自回歸損失直接模擬圖 1 所示的數據聯合概率分布。
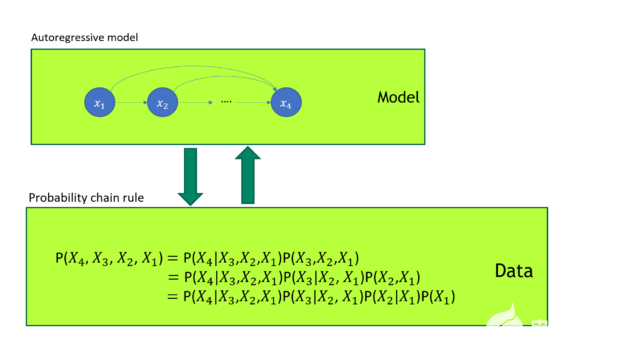
圖 1 GPT 模型訓練
在圖 1 中, GPT 模型訓練使用自回歸損失。它與概率鏈規則有一對一的映射。 GPT 直接建模數據的聯合概率分布。
由于表格數據由不同類型的數據(如行或列)組成, GPT 可以理解跨多個表格行和列的聯合數據分布,并生成合成數據,就好像它是 NLP 文本數據一樣。我們的 experiments 表明, GPT 模型確實可以生成更高質量的表格合成數據。
更高質量的表格數據標記器
盡管 GPT 具有優越性,但使用 GPT 對表格數據建模仍存在許多挑戰: GPT 模型的數據輸入是令牌 ID 序列。對于 NLP 數據集,可以使用 byte-pair encoding ( BPE )標記器將文本數據轉換為標記 ID 序列。
對于表格數據集,使用通用 GPT BPE 標記器 是很自然的;然而,這種方法存在一些問題。
首先,當 GPT BPE 標記器將表格數據拆分為標記時,同一列不同行的標記數通常不是固定的,因為標記數是由單個子項的出現頻率決定的。這意味著,如果使用普通 NLP 標記器,表中的列信息將丟失。
NLP 標記器的另一個問題是,列中的長字符串將由大量標記組成。考慮到 GPT 對令牌序列建模的能力有限,這是一種浪費。例如,商戶名稱 三井工程造船公司 需要 7 個令牌來使用 BPE 令牌化器對其進行編碼([448969019424122216656168941766])。
正如 TabFormer paper 中所討論的,一個可行的解決方案是為考慮表的結構信息的表格數據構建一個專門的標記器。 TabFormer 標記化器為每列使用一個標記,如果該列的標記數較小,則可能導致精度損失,如果標記數過大,則可能導致泛化能力較弱。
我們通過使用多個標記對列進行編碼來改進它。
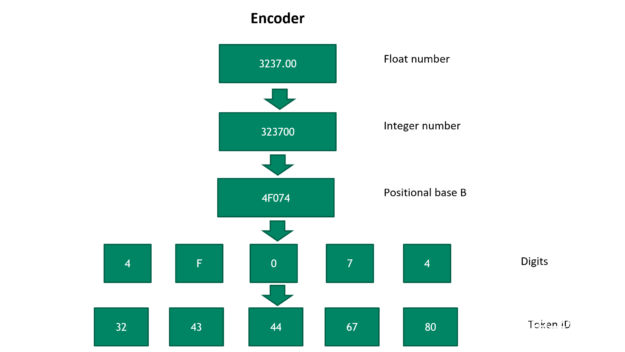
圖 2 將浮點數轉換為令牌 ID 序列
圖 2 顯示了將浮點數轉換為令牌 ID 序列的步驟。首先,我們可逆地將浮點數轉換為正整數。然后,它被轉換成一個具有位置基 B 的數字,其中 B 是一個超參數。基 B 號越大,表示該數字所需的令牌就越少。
然而,更大的基數 B 犧牲了新數字的通用性。在最后一步中,數字被映射到唯一的令牌 ID 。要將令牌 ID 轉換為浮點數,請按相反順序運行以下步驟。然后,浮點數解碼精度由令牌的數量和位置基的選擇決定 B 。
基于 NeMo 框架的伸縮模型訓練
NeMo 是用于培訓 對話人工智能 模型的框架。在 NeMo 存儲庫內的 released code 中,我們的表格數據標記器支持整數和分類數據,處理 NaN 值,并支持不同的標量轉換以最小化數字之間的差異。有關更多信息,請參閱我們的 源代碼實現 。
您可以使用特殊的表格數據標記器來訓練任何大小的表格合成數據生成 GPT 模型。由于內存限制,大型模型可能難以訓練。 NeMo megatron 是一個用于在 NeMo 中訓練大型語言模型的工具包,并提供 張量模型并行和管道模型并行 和 張量模型并行和管道模型并行 。
這使得 transformer 模型的訓練具有數十億個參數。除了模型并行性之外,您還可以在培訓期間應用數據并行性,以充分利用集群中的所有 GPU 。根據 OpenAI 的 自然語言的尺度律 和 深度學習模型的過度參數化理論 ,考慮到訓練數據的大小,建議訓練大型模型以獲得合理的驗證損失。
將 GPT 模型應用于實際應用
在我們最近的 GTC 談話 ,我們表明,經過訓練的大型 GPT 模型可以生成高質量的合成數據。如果我們繼續對經過訓練的表格 GPT 模型進行采樣,它可以產生無限多個數據點,這些數據點都像原始數據一樣遵循聯合分布。生成的合成數據提供了與原始數據相同的分析見解,但沒有透露個人的私人信息。這使得安全的數據共享成為可能。
此外,如果您根據過去的數據對生成模型進行調整,以生成未來的合成數據,那么該模型實際上是在預測未來。這對金融服務行業中處理金融時間序列數據的客戶很有吸引力。 與 Cohen & Steers 合作 ,我們實施了一個表格 GPT 模型,以預測經濟和市場指標,包括通貨膨脹、波動性和股票市場,并獲得高質量的結果。
彭博社在 2022 年 GTC 上介紹了他們如何應用我們提出的合成數據方法來分析信用卡交易數據的模式,同時保護用戶數據隱私。
運用你的知識
在本文中,我們介紹了使用 NeMo 生成合成表格數據的想法,并展示了如何將其用于解決實際問題。
關于作者
Yi Dong 是 NVIDIA 的深度學習解決方案架構師,負責提供金融服務業人工智能解決方案。易建聯獲得了博士學位。來自約翰·霍普金斯大學醫學院,研究計算神經科學。易在計算機軟件工程、機器學習和金融領域擁有 10 年的工作經驗。易建聯喜歡閱讀深度學習的最新進展,并將其應用于解決財務問題。
Emanuel Scoullos 是 NVIDIA 金融服務和技術團隊的數據科學家,他專注于 FSI 內的 GPU 應用。此前,他在反洗錢領域的一家初創公司擔任數據科學家,應用數據科學、分析和工程技術構建機器學習管道。他獲得了博士學位。普林斯頓大學化學工程碩士和羅格斯大學化學工程學士學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5025瀏覽量
103270 -
gpu
+關注
關注
28文章
4754瀏覽量
129080 -
人工智能
+關注
關注
1792文章
47444瀏覽量
239030
發布評論請先 登錄
相關推薦
企業AI解決方案包括哪些內容

PLC數據采集解決方案

PLM制造業解決方案:應對挑戰,提升效率與競爭力
邊緣計算的技術挑戰與解決方案

關于企業數據防泄密解決方案
深圳比創達電子|EMI一站式解決方案:提升企業電磁兼容性的路徑.
境外社交數據采集遇到的問題及云手機解決方案
DC電源模塊在醫療設備中的應用挑戰與解決方案

Transformers的功能概述





 工商網監
工商網監
評論