 詳解GPGPU與人工智能
詳解GPGPU與人工智能
GPGPU即通用計算GPU,實際不是通用計算,而是深度學習計算或者說AI人工智能計算,這種計算深入到最底層就是矩陣之間的乘積累加。GPGPU基本上被英偉達壟斷,英偉達之所以能壟斷這個市場,并在無人駕駛領域大放異彩,主要是靠2005年開發的CUDA。
對于GPGPU即通用計算型GPU,軟件棧是其生態系統得以擴展的核心。GPGPU在軟件棧上主要有兩個特點:一是掩蓋硬件細節,高度透明,讓硬件抽象為一個軟件系統,讓程序員感覺不到硬件;二是編程模型更友好,人人都能上手。這會產生一個問題,抽象掩藏掉的硬件細節越多,編程模型對用戶越友好,那么它會越難充分發揮硬件的全部潛力。因此GPGPU的抽象是分層次的:越靠近用戶的層次越易用,同時該層次的性能或者靈活性會越差。這樣特定應用領域的用戶,如果重心在開發效率,可以選擇高層次的編程模型;而需要充分發揮GPGPU性能潛力的用戶可以選擇低層次的編程模型。這也正是我們把GPGPU的編程模型稱為‘軟件棧’的原因。
英偉達的GPGPU帝國其核心不是其GPU架構,而是5層軟件棧打造的無可匹敵的生態系統,想要打破英偉達的壟斷必須也打造類似的生態系統,這難比登天,做硬件容易,GPGPU的IP唾手可得,舍得砸錢有辦法在臺積電那里拿到最先進的產能,堆核心面積可以輕松做出來比肩英偉達的高性能GPU,但是生態體系沒有15年時間是做不起來的。
英偉達的AI軟件棧自底向上至少可以分成5層:
SASS是硬件實際執行的指令集,類似CPU的匯編,處在最底層;
PTX是虛擬指令集,為不同代的NVIDIA GPGPU提供了一個統一的編程接口,處在倒數第二層;
CUDA是用戶在編寫高性能GPGPU程序時主要的編程模型,處在倒數第三層,當然這三層也可以理解為廣義的CUDA;
cuBLAS,cuDNN, cuFFT, CUTLASS等運算庫勉強算第四層,讓用戶可以通過調用NVIDIA針對自家GPGPU高度定制的算子庫,不需要花費太多精力進行性能調優就可以發揮英偉達GPGPU的最強性能,所有主流深度學習框架(Framework)都集成了這些算子庫中的最少一個算子(cuDNN基本都有);
TensorRT、Triton和Megastron則是英偉達針對特定AI應用場景深度定制,讓AI類用戶開箱即用的軟件平臺。
人工智能的運算流程通常是用戶用CUDA編譯代碼,編譯出架構的PTX指令,再由PTX指令轉化為底層的SASS指令,英偉達開放了PTX指令接口,程序員可以使用ASM寫PTX的內嵌匯編,SASS沒有開放,也不會開放,那是英偉達的核心,SASS應該是能和底層二進制或十六進制的計算機指令一一對應的指令。
CUDA
CUDA是我們接觸最多的,CUDA已形成了事實上的壟斷,AI或者說人工智能深度學習等高密度計算都離不開CUDA,反過來CUDA也讓英偉達的GPGPU熱賣,形成滾雪球的良性循環,讓英偉達的GPGPU也形成了壟斷。要想做GPGPU硬件,就必須兼容CUDA,但這就意味著性能沒有優化,這樣做出來的模型,在英偉達的設備上自然會運行的比較好。
沒有CUDA之前,GPU只能按照圖形渲染管線和API來執行操作。CUDA(Compute Unified Device Architecture),它包含了CUDA指令集架構(ISA)以及GPU內部的并行計算引擎。CUDA架起了一座普通程序員與GPU硬件間的橋梁,一方面讓GPU可以從事通用計算而不僅僅是圖形渲染,且能最大限度發揮GPU多核心的物理優勢,另一方面GPU對程序員來說完全透明,程序員可以像用CPU那樣為其開發程序。開發人員可以使用最常見的計算機語言即C語言來為CUDA架構編寫程序,所編寫出的程序可以在支持CUDA的處理器得以最大化發揮其性能。CUDA3.0 開始支持C++和FORTRAN。而這些語言一開始都是為CPU而設計的。
經常有人拿OpenCL與CUDA對比,其實CUDA和OpenCL的關系并不是沖突關系,而是包容關系。CUDA是一個并行計算的架構,包含有一個指令集架構和相應的硬件引擎。OpenCL是一個并行計算的應用程序編程接口(API),CUDA高于OpenCL,它是支持OpenCL的,在NVIDIA CUDA架構上OpenCL是除了C for CUDA外新增的一個CUDA程序開發途徑。CUDA C語言與OpenCL的定位不同,或者說是使用人群不同。CUDA C是一種高級語言,那些對硬件了解不多的非專業人士也能輕松上手;而OpenCL則是針對硬件的應用程序開發接口,它能給程序員更多對硬件的控制權,相應的上手及開發會比較難一些。那些在X86 CPU平臺使用C語言的人員,會很容易接受基于CUDA GPU平臺的C語言;而習慣于使用ARM平臺的程序員,看到OpenCL會更加親切一些,在其基礎上開發與圖形、視頻有關的計算程序會非常容易。基于C語言的CUDA被包裝成一種容易編寫的代碼,因此即使是不熟悉芯片構造的科研人員,也可能利用CUDA工具編寫出實用的程序。而OpenCL雖然句法上與CUDA接近,但是它更加強調底層操作,因此難度較高,但正因為如此,OpenCL才能跨平臺運行。CUDA最初就是為科研人員開發的。
OpenCL開發的過程中,技術平臺均為NVIDIA的GPU,實際上OpenCL是基于NVIDIA GPU的平臺進行開發的,當然它是可以跨平臺的。另外OpenCL的第一次演示也是運行在NVIDIA的GPU上。從本質上來說,OpenCL就是一個相當于Windows平臺中DirectX那樣的技術。或者說,它是一個連接硬件和軟件的API接口。在這一點上,它與OpenGL類似,不過OpenCL的涉及范圍要比OpenGL大得多,它不僅是用來作用于3D圖形。如果用一句話描述,OpenCL的作用就是通過調用處理器和GPU的計算資源,釋放硬件潛力,讓程序運行得更快更好。順便說一下,OpenCL是蘋果在2008年牽頭發起的。
CUDA雖然是英偉達獨家開發,但其源頭卻是微軟,2005年底,微軟推出DirectX 10,DirectX 10最大的革新就是統一渲染架構(Unified Shader Architecture)。各類圖形硬件和API均采用分離渲染架構,即頂點渲染和像素渲染各自獨立進行,前者的任務是構建出含三維坐標信息的多邊形頂點,后者則是將這些頂點從三維轉換為二維。這為實現GPU通用計算奠定了基礎。第一代CUDA在2006年底發布的首款DX10規范的G80架構上實現,到了GT 200時代,GTX 200系列顯卡實現了硬件級雙精度算術(GT200核心中擁有30個64位浮點單元)。
英偉達的顯卡架構都有對應的CUDA版本,比如3.x稱為Kepler,包括3.0、3.5、3.7等,5.x稱為Maxwell,包括5.0、5.2、5.3等,6.x是Pascal,包括6.0、6.1、6.2等。7.0是Volta,7.5是Turing。目前最常見的Ampere架構卡A100是8.0,目前Ampere架構最高到11.6版,最新的Hopper架構應該是12.x版。隨著英偉達在CPU領域的持續發力,未來CUDA可能會有比較大的變化。
CUDA架構

圖片來源:互聯網
CUDA主要提供了4個重要的東西:CUDA C和對應的COMPILER,CUDA庫、CUDA RUNTIME和CUDA DRIVER。CUDA C其實就是C的變種,它加入4大特性:
1)可以定義程序的哪部分運行在GPU或CPU上;
2)可以定義變量位于GPU的存儲類型;
3)利用KERNEL、BLOCK、GRID來定義最原始的并行計算;
4)State變量。
CUDA庫包含了很多有用的數學應用,如cuFFT,CUDA RUNTIME其實就是個JIT編譯器,動態地將PTX中間代碼編譯成符合實際平臺的硬件代碼,并做特定優化。Driver便是相應API直接與GPU打交道的接口了。
在CUDA中程序執行區域分為兩部分,CPU和GPU——HOST和DEVICE,任務組織和發送是在CPU里完成的,但并行計算是在GPU里完成,每當CPU遇到需要并行計算的任務,則將要做的運算組織成kernel,即數據并行處理函數(核函數),然后發給GPU去執行,在GPU上執行的程序,一個Kernel對應一個Grid網格,網格是一維或多維線程塊(block),CUDA在把任務正式提交給GPU前,會對kernel做些處理,讓kernel符合GPU體系架構,把GPU想成擁有上百個核的CPU,kernel當成一個要創建為線程的函數,所以CUDA現在要用kernel創建出上百個thread,然后將這些thread送到GPU中的各個核上去運行,為了更好利用GPU資源,提高并行度,CUDA還要將這些thread加以優化組織,將能利用共有資源的線程組織到一個thread block中,同一thread block中的thread可以共享數據,每個thread block最高可擁有512個線程。擁有同樣維度同樣kernel的thread block被組織成一個grid,而CUDA處理任務的最大單元便是grid了。
人工智能、機器學習、深度學習基礎
所謂人工智能實際可以等同于機器學習,人是能夠提出問題發現問題的,而機器永遠做不到這一點,從這個角度講,人工智能永遠都無法實現,因為人類一切科學的源頭,智能的源頭就是人類有好奇心,能夠發現問題,而機器只能解決問題。
機器學習中最常見的是深度學習,深度學習可以按照訓練方式分為六大類,分別是:
監督學習(supervised learning):已知數據和其一一對應的標注(標簽),也就是說訓練數據集需要全部標注。訓練一個智能算法,將輸入數據映射到標注的過程。監督學習是最常見的深度學習,也是ADAS自動駕駛感知領域幾乎唯一的深度學習方式,就是人們口中常說的分類(Classification)問題。
無監督學習(unsupervised learning):已知數據沒有任何標注,按照一定的偏好,訓練一個智能算法,將所有的數據映射到多個不同標簽的過程。
強化學習(reinforcement learning):智能算法在沒有人為指導的情況下,通過不斷的試錯來提升任務性能的過程。“試錯”的意思是還是有一個衡量標準,用棋類游戲舉例,我們并不知道棋手下一步棋是對是錯,不知道哪步棋是制勝的關鍵,但是我們知道結果是輸還是贏,如果算法這樣走最后的結果是勝利,那么算法就學習記憶,如果按照那樣走最后輸了,那么算法就學習以后不這樣走。
弱監督學習(weakly supervised learning):已知數據和其一一對應的弱標簽,訓練一個智能算法,將輸入數據映射到一組更強的標簽的過程。標簽的強弱指的是標簽蘊含的信息量的多少,比如相對于分割的標簽來說,分類的標簽就是弱標簽。
半監督學習(semi supervised learning) :已知數據和部分數據一一對應的標簽,有一部分數據的標簽未知,訓練一個智能算法,學習已知標簽和未知標簽的數據,將輸入數據映射到標簽的過程。半監督通常是一個數據的標注非常困難,比如說醫院的檢查結果,醫生也需要一段時間來判斷健康與否,可能只有幾組數據知道是健康還是非健康。
多示例學習(multiple instance learning) :已知包含多個數據的數據包和數據包的標簽,訓練智能算法,將數據包映射到標簽的過程,在有的問題中也同時給出包內每個數據的標簽。多事例學習引入了數據包的概念。
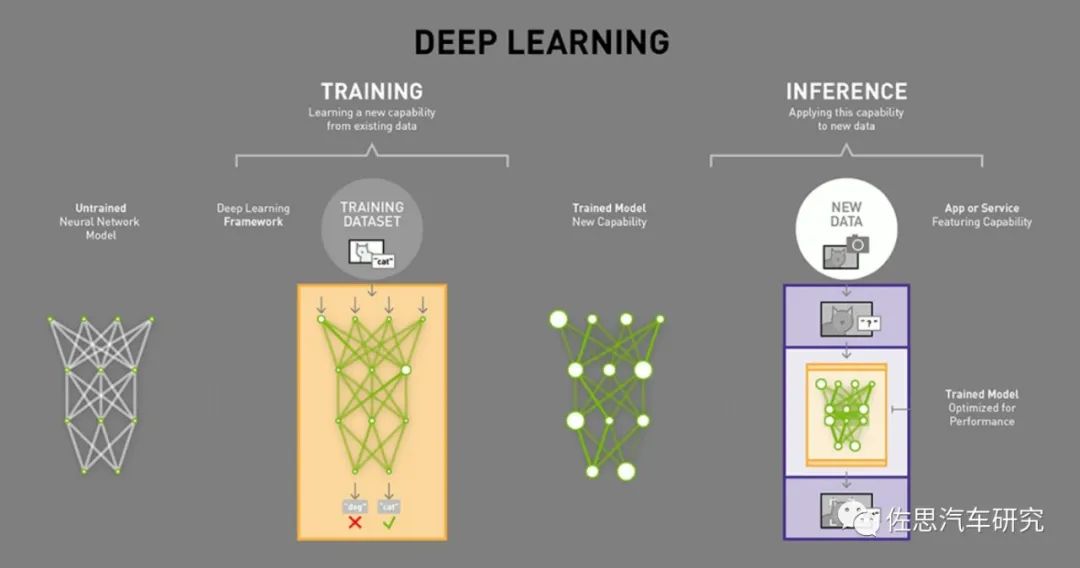
圖片來源:互聯網
深度學習分為訓練和推理兩部分,訓練就好比我們在學校的學習,但神經網絡的訓練和我們人類接受教育的過程之間存在相當大的不同。神經網絡對我們人腦的生物學——神經元之間的所有互連——只有一點點拙劣的模仿。我們的大腦中的神經元可以連接到特定物理距離內任何其它神經元,而深度學習卻不是這樣——它分為很多不同的層(layer)、連接(connection)和數據傳播(data propagation)的方向,因為多層,又有眾多連接,所以稱其為神經網絡。
訓練神經網絡的時候,訓練數據被輸入到網絡的第一層。然后所有的神經元,都會根據任務執行的情況,根據其正確或者錯誤的程度如何,分配一個權重參數(權重值)。在一個用于圖像識別的網絡中,第一層可能是用來尋找圖像的邊。第二層可能是尋找這些邊所構成的形狀——矩形或圓形。第三層可能是尋找特定的特征——比如閃亮的眼睛或按鈕式的鼻子。每一層都會將圖像傳遞給下一層,直到最后一層;最后的輸出由該網絡所產生的所有這些權重總體決定。
經過初步(是初步,這個是隱藏的)訓練后得到全部權重模型后,我們就開始考試它,比如注入神經網絡幾萬張含有貓的圖片(每張圖片都需要在貓的地方標注貓,這個過程一般是手工標注,也有自動標注,但準確度肯定不如手工),然后拿一張圖片讓神經網絡識別圖片里的是不是貓。如果答對了,這個正確會反向傳播到該權重層,給予獎勵就是保留,如果答錯了,這個錯誤會回傳到網絡各層,讓網絡再猜一下,給出一個不同的論斷,這個錯誤會反向地傳播通過該網絡的層,該網絡也必須做出其它猜測,網絡并不知道自己錯在哪里,也無需知道。在每一次嘗試中,它都必須考慮其它屬性——在我們的例子中是「貓」的屬性——并為每一層所檢查的屬性賦予更高或更低的權重。然后它再次做出猜測,一次又一次,無數次嘗試……直到其得到正確的權重配置,從而在幾乎所有的考試中都能得到正確的答案。
得到正確的權重配置,這是一個巨大的數據庫,顯然無法實際應用,特別是嵌入式應用,于是我們要對其修剪,讓其瘦身。首先去掉神經網絡中訓練之后就不再激活的部分。這些部分已不再被需要,可以被「修剪」掉。其次是壓縮,這和我們常用的圖像和視頻壓縮類似,保留最重要的部分,如今模擬視頻幾乎不存在,都是壓縮視頻的天下,但我們并未感覺到壓縮視頻與原始視頻有區別。壓縮的理論基礎是信息論(它與算法信息論密切相關)以及率失真理論,這個領域的研究工作主要是由上世紀40年代的 Claude Shannon 奠定的,實際機器學習所有的理論基礎在上世紀50年代就已經全部具備,絕大部分理論基礎也來自Claude Shannon 的信息論,唯一差的就是算力,是英偉達的GPU造就了深度學習時代的到來,目前的深度學習沒有理論上的突破,只是應用上的擴展。經過壓縮后,多個神經網絡層被合為一個單一的計算。最后得到的這個就是推理Inference用模型或者說算法模型,實際我覺得叫Prediction猜測更準確。
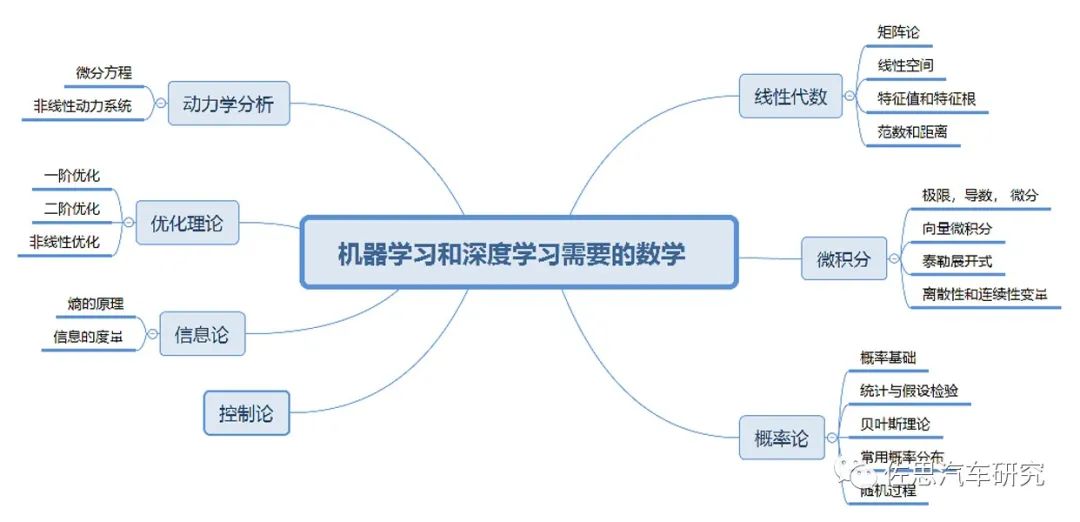
圖片來源:互聯網
深度學習的關鍵理論是線性代數和概率論,因為深度學習的根本思想就是把任何事物轉化成高維空間的向量,強大無比的神經網絡,說來歸齊就是無數的矩陣運算和簡單的非線性變換的結合。在19世紀中期,矩陣理論就已經成熟。概率論在18世紀中期就有托馬斯貝葉斯,在1900年俄羅斯的馬爾科夫發表概率演算,概率論完全成熟。優化理論主要來自微積分,包括拉格朗日乘子法及其延伸的KKT,而拉格朗日是18世紀中葉的法國數學家。RNN則和非線性動力學關聯甚密,其基礎在20世紀初已經完備。至于GAN網絡,則離不開19世紀末偉大的奧地利物理學家波爾茲曼。強化學習的理論基礎是1906年俄羅斯數學家馬爾科夫發表的弱大數定律(weak law of large numbers)和中心極限定理(central limit theorem),也就是馬爾科夫鏈。
深度學習的理論基礎已經不可能出現大的突破,因為目前人類的數學特別是非確定性數學已經走火入魔了。
實際深度學習就是靠蠻力計算(當然也有1X1卷積、池化等操作降低參數量和維度)代替了精妙的科學。深度學習沒有數學算法那般有智慧,它知其然,不知其所以然,它只是概率預測(深度學習里最重要的置信度)。所以在目前的深度學習方法中,參數的調節方法依然是一門“藝術”,而非“科學”。深度學習方法深刻地轉變了人類幾乎所有學科的研究方法。以前學者們所采用的觀察現象,提煉規律,數學建模,模擬解析,實驗檢驗,修正模型的研究套路被徹底顛覆,被數據科學的方法所取代:收集數據,訓練網絡,實驗檢驗,加強訓練。這也使得算力需求越來越高。機械定理證明驗證了命題的真偽,但是無法明確地提出新的概念和方法,實質上背離了數學的真正目的。這是一種“相關性”而非“因果性”的科學。歷史上,人類積累科學知識,在初期總是得到“經驗公式”,但是最終還是尋求更為深刻本質的理解。例如從煉丹術到化學、量子力學的發展歷程。人類智能獨特之處也在于數學推理,特別是機械定理證明,對于這一點,機器學習永遠無能為力的。
對于深度學習推理階段來說,分解到最底層,其運算核心就是數據矩陣與權重模型之間的乘積累加,乘積累加運算(英語:Multiply Accumulate, MAC)。這種運算的操作,是將乘法的乘積結果和累加器A的值相加,再存入累加器:
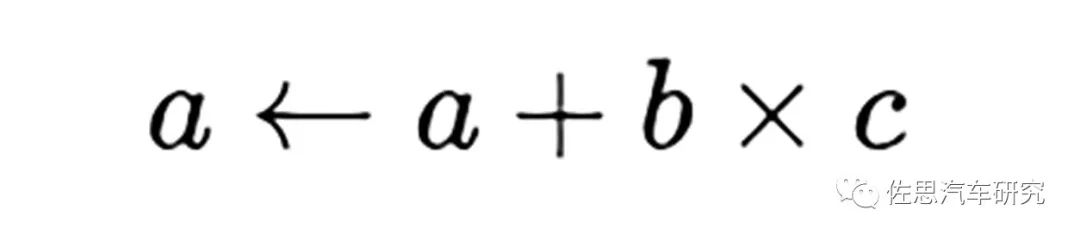
若沒有使用MAC指令,上述的程序需要二個指令,但MAC指令可以使用一個指令完成。而許多運算(例如卷積運算、點積運算、矩陣運算、數字濾波器運算、乃至多項式的求值運算,基本上全部的深度學習類型都可以對應)都可以分解為數個MAC指令,因此可以提高上述運算的效率。推理階段要求精度不高,一般是整數8位,即INT8。
對于訓練階段,要求比較高,常見的是FP64和FP32兩種精度,近來又出現Bfloat16,Bfloat16就是截斷浮點數(truncated 16-bit floating point),它是由一個float32截斷前16位而成。它和IEEE定義的float16不同,主要用于取代float32來加速訓練網絡,同時降低梯度消失(vanishing gradient)的風險,也可以防止出現NaN這樣的異常值。深層神經網絡每次梯度相乘的系數如果小于1,那就是浮點數,如果層數越來越多,那這個系數會越來越大,傳播到最底層可以學習到的參數就很小了,所以需要截斷來防止(或降低)梯度消失。在float32和bfloat16之間進行轉換時非常容易,事實上 Tensorflow也只提供了bfloat16和float32之間的轉換,不過畢竟還是需要轉換的。
英特爾的內嵌匯編格式GNU Gas添加了BFloat16支持,英特爾在2019年4月發布補丁,支持GNU編譯器集合(GCC)中的BFloat16支持。和IEEE float16相比,動態范圍更大(和float32一樣大),但是尾數位更少(精度更低)。更大的動態范圍意味著不容易下溢(上溢在實踐中幾乎不會發生,這里不考慮)。另一個優勢是Bfloat16既可以用于訓練又可以用于推斷。Amazon也證明Deep Speech模型使用BFloat16的訓練和推斷的效果都足夠好。Uint8在大部分情況下不能用于訓練,只能用于推斷,大多數的Uint8模型都從FP32轉換而來。所以,Bfloat16可能是未來包括移動端的主流格式,尤其是需要語言相關的模型時候。當然英偉達認為Bfloat16犧牲了部分精度,對于某些場合如HPC,精度比運算效率和成本更重要。
一個MAC單元通常包括三部分:乘法器、加法器和累加器。
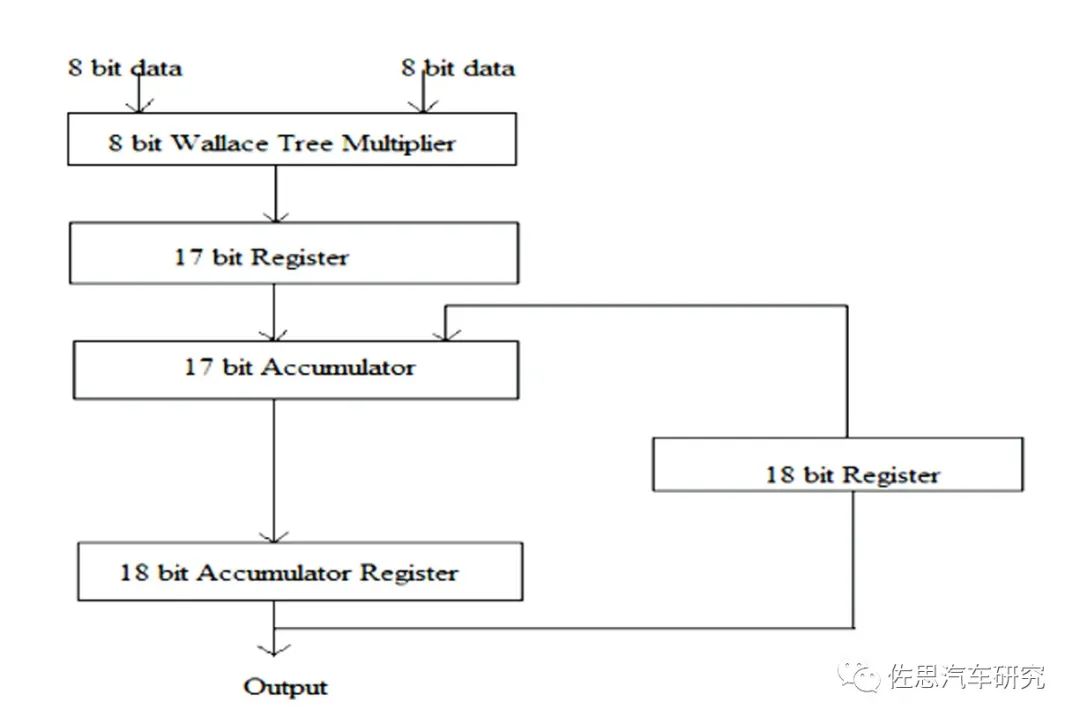
圖片來源:互聯網
上圖為一個典型的MAC單元。計算機體系中的乘法和加法都歷經了長時間的研究改進,純粹的乘法器和加法器肯定是不會有人用。乘法器最常用的Wallace樹,這是1963年C.S.Wallace提出的一種高效快速的加法樹結構,被后人稱為Wallace樹。人工智能95%的理論工作都是在1970年前完成的,只是沒有高性能計算系統,才沒有在那個時代鋪展開。加法器多是CSA,即進位保存加法器(Carry Save Adder,CSA)。使用進位保存加法器在執行多個數加法時具有極小的進位傳播延遲,它的基本思想是將3個加數的和減少為2個加數的和,將進位c和s分別計算保存,并且每比特可以獨立計算c和s,所以速度極快。這些都已經非常成熟,剛出校門的學生都可以做到。
除了降低精度以外,還可以結合一些數據結構轉換來減少運算量,比如通過快速傅里葉變換(FFT)來減少矩陣運算中的乘法;還可以通過查表的方法來簡化MAC的實現等。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4764瀏覽量
129174 -
人工智能
+關注
關注
1793文章
47566瀏覽量
239415 -
汽車系統
+關注
關注
1文章
135瀏覽量
19794
原文標題:深入了解汽車系統級芯片SoC連載之九:詳解GPGPU與人工智能
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論