") NVIDIA TensorRT加速打造實時數(shù)字化運動場景
NVIDIA TensorRT加速打造實時數(shù)字化運動場景
案例簡介
GALA Sports 的 Arena4D 方案使用多個高清攝像機,將數(shù)據(jù)傳輸?shù)揭粋€本地 HPC 中,經(jīng)過一系列的神經(jīng)網(wǎng)絡流水線,實時計算出每個運動員的位置與姿態(tài),從而將整個比賽場景數(shù)字化。
Arena4D 的中央處理 HPC 需要以 30FPS 的速度處理 4-12 個 4K 相機的數(shù)據(jù),流水線包括圖像前處理、運動員追蹤與識別、球的追蹤識別、骨骼關鍵點識別,多幀時間軸降噪等多個算法模塊,為了達到實時計算,Arena4D 使用了 NVIDIA A100 GPU 加速神經(jīng)網(wǎng)絡計算,并使用 Tensor RT、CUDA 進行深度優(yōu)化,經(jīng)過優(yōu)化部署的算法計算速度相對于早期算法原型有 10 倍以上的性能提升。
本案例主要應用到 NVIDIA A100 GPU、TensorRT和CUDA。
客戶簡介及應用背景
望塵科技(GALA Sports)于 2013 年在深圳成立,是一家以技術為驅(qū)動的互聯(lián)網(wǎng)公司,多年來一直專注于體育游戲和賽場數(shù)字化,致力于為用戶提供高品質(zhì)的體育在線娛樂體驗,目前團隊成員 300 余人,分別于深圳、成都設有辦公地點。
憑借歷年來在體育游戲市場的深耕與穩(wěn)定的高質(zhì)量產(chǎn)品研發(fā),望塵科技推出了《足球大師》、《NBA 籃球大師》、《最佳 11 人》等多款體育類手游,與 FIFPro、NBA、中超、拜仁、巴薩、曼聯(lián)、皇馬、國米等體育聯(lián)盟及豪門俱樂部保持著長期的合作關系。目前,擁有全球超過 2000 萬的下載用戶,全球日活躍用戶量超 50 萬人次;在賽場三維重構、人體運動模擬、球類競技 AI、表情與肌肉物理模擬、超寫實數(shù)字人、大場景渲染等幾個領域處于國內(nèi)外領先地位。
客戶挑戰(zhàn)
多臺高清攝像頭每幀圖像需上傳到顯卡進行實時轉(zhuǎn)碼、降噪等前處理工作,數(shù)據(jù)吞吐量較大。
基于神經(jīng)網(wǎng)絡的計算流水線,需要實時進行多個視角、多個運動員的追蹤、識別、姿態(tài)估計與降噪計算。
在多個 AI 模型級聯(lián)計算流水線中,每個 AI 模型之間的數(shù)據(jù)處理與拷貝占用了大量的時間。
應用方案
基于以上挑戰(zhàn),GALA Sports 選擇了 NVIDIA 提供的 AI 加速解決方案——TensorRT。
針對多相機從內(nèi)存到顯存大量數(shù)據(jù)拷貝 IO bound 問題,我們使用 CUDA 多流技術實現(xiàn)了內(nèi)存拷貝與數(shù)據(jù)處理并行化,降低了 overhead,4 路 4k 相機數(shù)據(jù)的拷貝與轉(zhuǎn)碼從約 50ms 減少到 30ms。
針對神經(jīng)網(wǎng)絡流水線的計算延遲問題,首先我們根據(jù)體育比賽的使用場景與相機視角對模型結構進行了優(yōu)化,根據(jù)不同體育類型的相機機位和球場尺度,設計了專門針對特定比賽的識別網(wǎng)絡,大大降低了網(wǎng)絡的復雜度;然后使用量化工具對網(wǎng)絡進行 fp16 量化加速,最后使用 TensorRT 針對 A100 編譯,在 A100 上能達到最優(yōu)性能的模型。
針對計算流水線模型之間數(shù)據(jù)處理耗時的問題,首先我們通過合并部分神經(jīng)網(wǎng)絡模型重新訓練,然后對于必須保留的數(shù)據(jù)處理代碼,我們用 CUDA C++ 重寫了大部分數(shù)據(jù)處理的 kernel,并針對 A100 的硬件結構對并行參數(shù)進行調(diào)優(yōu),最終將數(shù)據(jù)處理 30ms 的計算時間降低到 5ms。
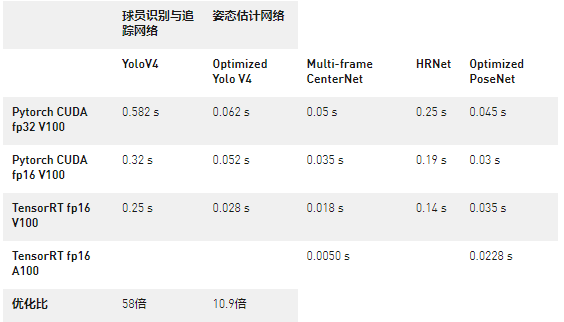
最終,以足球場場景為例,追蹤目標為 1 個足球 + 22 名球員 + 3 名教練的位置與骨骼,在 1 張 A100 設備上我們實現(xiàn)了平均 50ms/幀的速度,在 2 張 A100 設備上能達到平均 30ms/幀的速度,整個流水線比原型提升了 18 倍。
方案效果及影響
將整個推理端算法流水線經(jīng)過上述方法優(yōu)化后,相較于未用 TensorRT 與 CUDA 優(yōu)化的算法原型,我們實現(xiàn)了 18 倍的性能提升,使超大規(guī)模體育場景的姿態(tài)捕捉與重建的實時計算成為可能,在體育比賽過程中的實時計算產(chǎn)生了許多新的用途,我們的客戶能夠?qū)⑦@些數(shù)字化內(nèi)容用于直播解說、實時戰(zhàn)術分析、自由視角回放、比賽結果預測等新場景,提升了系統(tǒng)方案的價值。
我們的硬件方案也從 4 臺 HPC 縮減到 1 臺 HPC 搭載 2 張 A100 GPU,不僅顯著地降低了成本,也顯著降低了系統(tǒng)維護和使用的復雜度,提升了系統(tǒng)可靠度。
后續(xù),我們計劃:
通過將流水線中部分網(wǎng)絡使用 Int8 量化以進一步提升性能;
將整體流水線遷移到 CUDA C++ 代碼中進一步提升性能;
把性能提升空余的計算資源用于提升網(wǎng)絡模型的復雜度以提升精度;
將 CenterNet 與 Dense Sematic 網(wǎng)絡特征提取部分替換成 Vision Transformer 以提升精度;
使用 Nsight 在 A100 真實環(huán)境中進一步 profile,減少 overhead。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5026瀏覽量
103287 -
攝像機
+關注
關注
3文章
1608瀏覽量
60148 -
CUDA
+關注
關注
0文章
121瀏覽量
13644
發(fā)布評論請先 登錄
相關推薦
智能工廠的數(shù)字化應用場景

LITESTAR 4D應用:運動場照明設計流程
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開發(fā)布

NVIDIA Omniverse加速零售數(shù)字化轉(zhuǎn)型
阿爾特汽車借助NVIDIA Omniverse打造全方位數(shù)字化平臺
實時數(shù)據(jù)與數(shù)字孿生的關系
數(shù)字化技術如何加速精益生產(chǎn)策略的實施與成效?
高速數(shù)字化儀的技術原理和應用場景
HT for Web并力ARMxy工業(yè)計算機實現(xiàn)數(shù)字化轉(zhuǎn)型可視化解決方案

深耕不輟 喜訊頻傳!鼎捷軟件榮膺“新能源數(shù)字化杰出服務商”
智慧園區(qū)數(shù)字化能源云平臺的多元化應用場景,您知道哪些?
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型

廠礦企業(yè)數(shù)字化智慧能源物聯(lián)網(wǎng)解決方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論