 騰訊廣告視頻抽幀的全流程GPU加速
騰訊廣告視頻抽幀的全流程GPU加速
案例簡介
騰訊廣告的開發人員改進了視頻抽幀的實現方式,使得全流程的操作均在 GPU 上完成,取代了原有的 CPU 抽幀流程,提高了性能,并降低了成本。
本案例涉及 GPU 加速的視頻解碼與圖像處理
線上測試集顯示,單個 GPU 的視頻解碼算力與 8 個 CPU 核大致相當
GPU 做圖像處理比 CPU 更有性能和成本優勢,尤其與 GPU 視頻解碼聯合使用時
本案例使用了 NVIDIA T4 GPU 以及相關軟件
客戶簡介及應用背景
視頻已成為內容和廣告的主要媒介形式,但目前的視頻內容理解或審核等 AI 能力,主流依然是先抽幀,再基于圖像幀做特征提取和預測。
騰訊廣告部門日常處理大量的視頻信息,而抽幀是視頻分析的第一步。抽幀由于步驟多、計算重,在視頻 AI 推理場景很容易成為性能瓶頸。
客戶挑戰
在騰訊廣告的流量中,視頻所占比例逐年快速提升,視頻抽幀這里如果出現時耗或吞吐瓶頸(特別是針對高 FPS 抽幀的情況),很容易影響到后續的特征提取以及模型預測性能。在當前的廣告視頻 AI 推理服務中,抽幀往往占據了其中大部分時耗,因此,視頻抽幀的性能對于視頻內容理解服務的時耗和整體資源開銷,有著舉足輕重的地位。
視頻抽幀的幾個步驟,計算量非常大,傳統的 CPU 方式抽幀往往受限于 CPU 整體的計算吞吐,很難滿足低時延高性能要求。因此,使用 GPU 加速等手段,來對視頻抽幀做極致的性能優化是必然。
應用方案
NVIDIA GPU 具備單獨的硬件編解碼計算單元,從早期發布的 Maxwell 架構到最新的 Ampere 架構,都有完善的 API 支持,并且 GPU 上為數眾多的 CUDA 核心也特別適用于圖像數據并行處理加速。目前廣泛使用的推理芯片 NVIDIA T4 GPU,包含兩個獨立于 CUDA 的解碼單元,且支持大部分主流的視頻格式,是本案例的應用型號。
視頻抽幀流程大體上包括以下幾個步驟:視頻解碼、幀色彩空間轉換、落盤方式的 JPEG 編碼,如果非落盤,則對解碼出來的視頻幀做預處理,然后交給模型進行特征提取或預測。
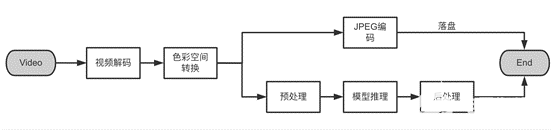
其中幀色彩空間轉換、JPEG 編碼都涉及像素級別計算,非常適合使用 GPU CUDA kernel 來做并行計算加速。此外,視頻解碼后得到的幀都是未經壓縮的原始數據,數據量很大,如果解碼是在 CPU 上進行,或者 GPU 解碼后自動傳回了 CPU,則需要頻繁做 device(顯存)與 host(主存)之間的原始幀數據來回拷貝,IO 時耗長且數據帶寬擁塞,導致時延明顯增加。 因此,該方案的主要目標是盡可能減少 host 與 device 間的數據 IO 交換,做到抽幀過程全流程 GPU 異構計算,充分利用 NVIDIA GPU 自帶的硬件解碼單元 NVDEC,最大限度減少視頻解碼對于 CPU 以及 GPU CUDA 核心占用的同時,盡可能低延時、高吞吐地處理視頻抽幀以及后續的模型推理。
具體來說,本方案主要從計算和 IO 兩個方面著手,解碼部分充分利用了 GPU 通常閑置的 NVDEC 解碼器,其他步驟以像素或像素塊計算為主,因此使用 CUDA kernel 做并行加速。IO 方面,由于中間過程是原始幀,GPU 數據帶寬有限,該方案實現了全流程 CPU 和 GPU 無幀數據交換,最大程度提升性能和吞吐,確保視頻 AI 推理服務的 GPU 利用率。
計算優化
1. 硬解碼
當前線上主力的 GPU 推理卡 T4、P40,以及后續即將升級的 A 系列,主流的視頻編碼格式基本都已支持,各卡型支持的具體格式如下:
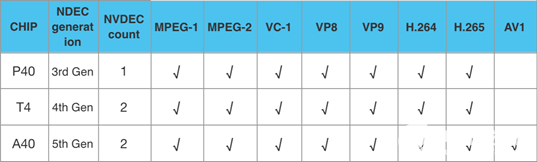
調用 GPU 硬解碼主要有兩種方式,一種是直接使用 NVIDIA 官方提供的 Video Codec SDK,另一種方式是使用 FFmpeg,其已經封裝了對 GPU 硬解碼的支持。考慮到目前 T4 GPU 對視頻格式的支持還不夠完善,因此本文使用的是 FFmpeg 方式,如果遇到 GPU 不支持的視頻格式,只需修改解碼器類型即可快速降級到 CPU 解碼方案,CPU 和 GPU 兩種模式抽幀的代碼邏輯也較為統一。
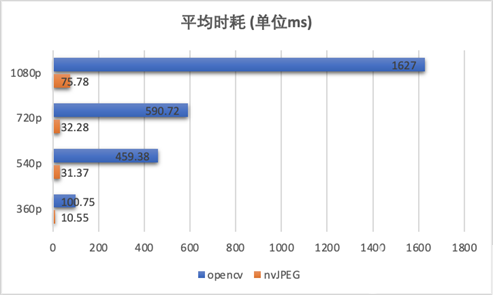
以下分別以 FFmpeg CPU 4、8、16 線程,以及 GPU 硬解碼方式,抽取線上 100 個廣告視頻做離線測試,平均時耗對比如下(CPU 為 2020 年發布的主流服務器 CPU):
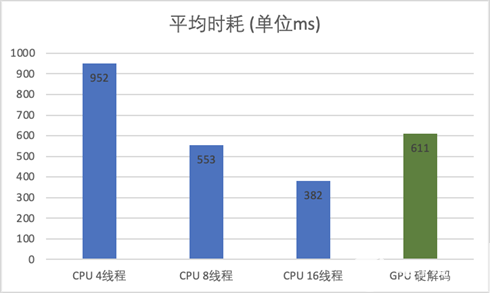
注:視頻平均大小約 15M,平均時長 26s,大部分為 720P 視頻;FFmpeg 建議最大解碼線程數 16
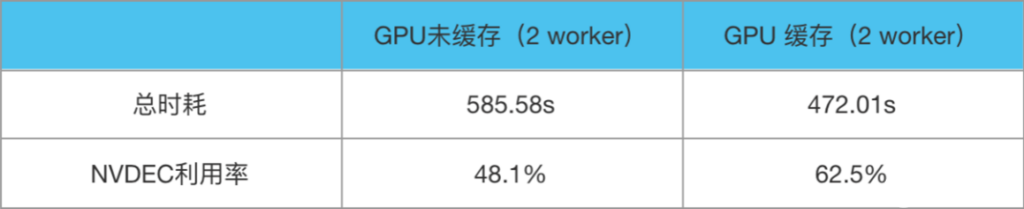
分配給 GPU 模型推理服務的 CPU 核數一般不會太多,因此以 FFmpeg 8 線程、2 worker(在本文中是指單進程多實例的方式)做性能壓測,1000 個廣告視頻測試數據如下:

由此可見,在 GPU 線上推理環境,如果充分利用 T4 GPU 2 個 NVDEC 硬件解碼模塊,可在幾乎不影響線上服務 CPU、CUDA 原有 workloads 計算的情況下,額外增加一倍解碼算力,抽幀 QPS 可在原有基礎上翻倍。此處應注意,不同架構 GPU 所附帶的 NVDEC 硬解模塊數不同,并且 NVDEC 不支持外部再用多線程操作解碼,應當根據 NVDEC 模塊數選擇正確的多實例多 worker 進行解碼。例如 T4 GPU 有 2 個 NVDEC 硬解碼模塊,如果只用單實例,則硬解模塊利用率將不會超過 50%。如果服務對吞吐的要求高于時延,則此處 GPU 硬解碼的 worker 數可以設為大于 n,充分壓榨硬件解碼模塊。
2. CUDA 色彩空間轉換
視頻解碼后得到的幀為 YUV 格式,而通常模型預測或其他后續處理一般需要 RGB/BGR 像素格式,因此需要做一次色彩空間轉換,將 YUV 幀轉換為模型需要的 RGB 格式。傳統方式是調用 FFmpeg 的 swscale 模塊來實現,但是該方式只支持在 CPU 進行計算,需要做一次 device 到 host 的數據 IO,并且非常消耗 CPU 資源,計算并行度也不高。統計發現,swscale 計算耗時占比接近 40%。
YUV 到 RGB 格式的轉換是 3×3 的常量矩陣與 YUV 三維向量相乘,即逐像素地將明度 Y、色度 U、濃度 V 三個分量按公式線性變換為 R、G、B 三色值(這里的常量矩陣的值取決于視頻所采用的顏色標準,比如 BT.601/BT.709/BT.2020,可參見 Video Codec SDK 里面的示例),因此可以很方便地將計算過程改為一維或二維線程塊的 CUDA kernel 調用,充分利用 GPU 數以千記的 CUDA 核心并行計算來做提速。
**性能:**對線上 100 個廣告視頻做性能對比評測,CUDA kernel 調用相對于 CPU 的 swscale 方式平均提速在 20 倍以上,并且視頻清晰度越高,優勢越明顯。
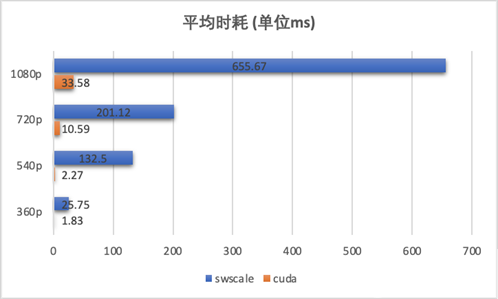
3. CUDA JPEG 編碼
如果是在視頻預處理等場景,則需要對抽幀結果做 JPEG 編碼后再落盤保存。JPEG 編碼具體流程如下:

雖然不同于色彩空間轉換的逐像素操作,但也是將整張圖片劃分為 8×8 像素的小分塊分別進行離散余弦變換、量化、Huffman 編碼等處理,同樣非常適合用 GPU CUDA core 計算單元來做并行加速。NVIDIA 從 CUDA Toolkit 10 開始也已經封裝了 nvJPEG 模塊提供 JPEG 編碼能力。
需要說明的是,使用 GPU 做 JPEG 編碼,與 CPU JPEG 編碼存在一定比例的像素差異。確保 JPEG 文件頭中各項參數一致的情況下(壓縮質量、量化表、Huffman 表均相同),實測像素差異比在 0.5% 左右。由于 JPEG 編碼為有損壓縮,因此解碼后依然存在像素差異,有可能導致模型給出的預測結果存在偏差。例如 OCR 的目標檢測模塊,分別使用 CPU 和 GPU 編碼的 JPEG 圖像作為輸入,預測得到的檢測框坐標值在部分 case 上存在一定偏差,從而有概率導致文字識別結果出現不一致。一種可行的解決方案,是模型訓練也使用 GPU JPEG 編碼的圖片作為輸入,保證模型訓練和推理的輸入一致性,從而確保模型推理效果。
**性能:**實測線上 1000 個廣告視頻,CUDA 方式 JPEG 編碼約有 15~20 倍性能提升,同樣清晰度越高性能優勢越大:
IO優化
FFmpeg 使用 GPU 硬解碼后,得到的視頻幀格式為 AV_PIX_FMT_NV12,通過 NVIDIA 提供的 cudaPointerGetAttributes API 做指針類型檢查,為 Host 端內存指針。也就是說調用 NVDEC 模塊解碼后,默認對視頻幀做了一次 device 到 host 的傳輸。
由于這里的視頻幀均為未壓縮的原始像素幀,且原始視頻的所有 FPS 幀都會做該處理,會占用大量 GPU 與 host 端內存的數據帶寬。若有辦法做到 GPU 硬解后的視頻幀,不默認傳回到 host 端,而是直接緩存在顯存等待后續計算,則可以無縫對接后續的模型推理或 JPEG 落盤,省去 device 與 host 端的來回兩次數據交換時耗,且大幅減輕 GPU 與 CPU 間的數據 IO 吞吐壓力。
為此,可使用 FFmpeg 的 hwdevice 相關接口,直接得到顯存中的視頻幀。這樣得到的視頻幀格式變為 AV_PIX_FMT_CUDA,且 Y 和 UV plane 的 data linesize 也由 1088 變為 1280,使用時需要注意。此時使用 cudaPointerGetAttributes 檢查 frame data 指針類型,已經是 device 端指針,由此打通了全流程異構抽幀的關鍵一環。
通過 NVIDIA Nsight Systems 抓取到的性能數據可見,cudaMemcpy 由之前的 DtoH & HtoD 來回傳輸變為一次顯存內部的 DtoD,時耗由 173ms x 2 變為 25ms,吞吐也有不少提升。此外,CUDA kernel 計算時間片的連續性也得到不少改善。
**性能:**實測線上 1000 個廣告視頻,整體性能相較于非硬件緩沖區方式有 25% 左右的提升,GPU 硬解碼器 NVDEC 資源利用率提升約 30%。
工程優化
本文以介紹 GPU 全流程抽幀方案為主,過程中為了把性能做到極致也涉及到一些工程優化:
通過顯存預分配+復用、AVHWDeviceContext 緩沖區 & JPEG 編碼器復用等手段,單次抽幀時耗可再優化百 ms 級別。
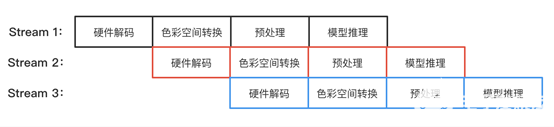
將 NVDEC 硬解碼、色彩空間轉換、JPEG 編碼、模型推理等步驟,利用 CUDA 多流,并對每個環節做 Pipeline overlap 并行化處理,可充分釋放每個步驟的最大計算性能,進一步提升計算吞吐和資源利用率。
目前有不少算法服務是基于 Python 進行開發&部署,本方案為保障高性能,使用 C++ 開發。通過 pybind11 基于 C++ 封裝 Python 抽幀 API,保障算法開發部署的靈活性與效率的同時,確保高性能的抽幀能力。
不落盤方式,對接模型推理之前一般需要先做預處理操作,如果要做到全流程 GPU,需要將預處理改寫為 CUDA kernel 調用。這里可以將常用的 CV 類預處理操作封裝為 CUDA 基礎函數庫,也可以使用 NVIDIA 已經封裝好的 NPP 模塊、DALI 預處理加速框架等方案。
使用效果及影響
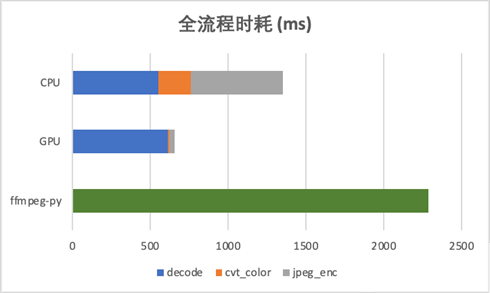
全流程時耗對比:
相較于 CPU 8 線程解碼,全流程有一倍左右的速度優勢,并且由于幾乎不占用 PCIe 數據帶寬,對模型推理等 device&host 間數據 IO 基本無影響,在吞吐上也有不少提升。
相較于 Python 算法常用的 ffmpeg-python 方式,有數倍性能提升。
視頻抽幀優化是視頻 AI 推理優化中的重要一環,本方案從 GPU 硬件加速的角度出發,分別針對抽幀各步驟做性能分析&計算優化,解決了中間過程大數據量的原始視頻幀 host 與 device 端數據 IO 交換問題,避免 GPU 與 CPU 間的 PCI-E 數據帶寬瓶頸,真正做到全流程 GPU 異構抽幀。基于此,可在 GPU 無縫對接后續的模型推理(不落盤)以及 JPEG 編碼(落盤)兩種主流的抽幀使用場景,是實現全流程 GPU 視頻 AI 推理能力的先決條件。同時,充分利用了 GPU 推理環境通常閑置的 NVDEC 解碼芯片,對于整體服務時耗、吞吐,以及硬件資源利用率均有不錯的提升,降低了視頻 AI 推理服務 GPU/CPU 算力成本,在算力緊缺的 AI2.0 時代有著非常重要的意義。
目前該方案已在騰訊廣告多媒體 AI 的視頻人臉服務落地,解決了其最主要的抽幀性能瓶頸,滿足廣告流水對于服務的性能要求。更多視頻 AI 算法,特別是高 FPS 抽幀場景也在逐步接入優化中。
“目前該方案已在騰訊廣告多媒體 AI 的視頻人臉服務落地,解決了其最主要的抽幀性能瓶頸,滿足廣告流水實時處理對于服務的性能要求。更多騰訊內部視頻 AI 算法,特別是高 FPS 抽幀場景也在逐步接入優化中。后續,我們還將與英偉達一起,探索視頻抽幀與模型推理的最佳結合方式,力求實現視頻AI推理的極致性能。”
向乾彪,騰訊廣告AI工程架構師,GPU視頻抽幀項目負責人
審核編輯:郭婷
-
cpu
+關注
關注
68文章
10879瀏覽量
212194 -
gpu
+關注
關注
28文章
4753瀏覽量
129061 -
AI
+關注
關注
87文章
31133瀏覽量
269456
發布評論請先 登錄
相關推薦
GPU加速云服務器怎么用的
《CST Studio Suite 2024 GPU加速計算指南》
虛擬制作技術在廣告領域中的應用與挑戰
騰訊混元大模型上線并開源文生視頻能力

PyTorch GPU 加速訓練模型方法
GPU深度學習應用案例
GPU加速計算平臺是什么

聚徽觸控-GPU 工控機是什么產品
【RTC程序設計:實時音視頻權威指南】視頻采集與渲染
【國產FPGA+OMAPL138開發板體驗】(原創)7.硬件加速Sora文生視頻源代碼
利用GPU加速在Orange Pi?5上跑LLMs:人工智能愛好者High翻了!






 工商網監
工商網監
評論