") NVIDIA Triton助力騰訊PCG加速在線推理
NVIDIA Triton助力騰訊PCG加速在線推理
案例簡(jiǎn)介
本案例中通過(guò)NVIDIA T4 GPU,通過(guò)Ronda平臺(tái)調(diào)用Triton以及TensorRT, 整體提升開(kāi)發(fā)和推理效能, 幫助騰訊PCG的多個(gè)服務(wù)整體效能提升2倍,吞吐量最大提升6倍,同時(shí)降低了40%的延時(shí)。本案例主要應(yīng)用到 NVIDIA T4 GPU、TensorRT和Triton。
本案例主要應(yīng)用到 NVIDIA T4 GPU、TensorRT和Triton。
客戶簡(jiǎn)介及應(yīng)用背景
騰訊平臺(tái)與內(nèi)容事業(yè)群(簡(jiǎn)稱 騰訊PCG)負(fù)責(zé)公司互聯(lián)網(wǎng)平臺(tái)和內(nèi)容文化生態(tài)融合發(fā)展,整合QQ、QQ空間等社交平臺(tái),和應(yīng)用寶、瀏覽器等流量平臺(tái),以及新聞資訊、視頻、體育、直播、動(dòng)漫、影業(yè)等內(nèi)容業(yè)務(wù),推動(dòng)IP跨平臺(tái)、多形態(tài)發(fā)展,為更多用戶創(chuàng)造海量的優(yōu)質(zhì)數(shù)字內(nèi)容體驗(yàn)。
騰訊PCG機(jī)器學(xué)習(xí)平臺(tái)部旨在構(gòu)建和持續(xù)優(yōu)化符合PCG技術(shù)中臺(tái)戰(zhàn)略的機(jī)器學(xué)習(xí)平臺(tái)和系統(tǒng),提升PCG機(jī)器學(xué)習(xí)技術(shù)應(yīng)用效率和價(jià)值。建設(shè)業(yè)務(wù)領(lǐng)先的模型訓(xùn)練系統(tǒng)和算法框架;提供涵蓋數(shù)據(jù)標(biāo)注、模型訓(xùn)練、評(píng)測(cè)、上線的全流程平臺(tái)服務(wù),實(shí)現(xiàn)高效率迭代;在內(nèi)容理解和處理領(lǐng)域,輸出業(yè)界領(lǐng)先的元能力和智能策略庫(kù)。機(jī)器學(xué)習(xí)平臺(tái)部正服務(wù)于PCG所有業(yè)務(wù)產(chǎn)品。
客戶挑戰(zhàn)
業(yè)務(wù)繁多,場(chǎng)景復(fù)雜
業(yè)務(wù)開(kāi)發(fā)語(yǔ)言包括C++/Python
模型格式繁多,包括ONNX、Pytorch、TensorFlow、TensorRT等
模型預(yù)處理涉及圖片下載等網(wǎng)絡(luò)io
多模型融合流程比教復(fù)雜,涉及循環(huán)調(diào)用
支持異構(gòu)推理
模型推理結(jié)果異常時(shí),難以方便地調(diào)試定位問(wèn)題
需要與公司內(nèi)現(xiàn)有協(xié)議/框架/平臺(tái)進(jìn)行融合
應(yīng)用方案
基于以上挑戰(zhàn),騰訊PCG選擇了采用NVIDIA 的Triton推理服務(wù)器,以解決新場(chǎng)景下模型推理引擎面臨的挑戰(zhàn),在提升用戶研效的同時(shí),大幅降低了服務(wù)成本。
NVIDIA Triton 是一款開(kāi)源軟件,對(duì)于所有推理模式都可以簡(jiǎn)化模型在任一框架中以及任何 GPU 或 CPU 上的運(yùn)行方式,從而在生產(chǎn)環(huán)境中使用 AI。Triton 支持多模型ensemble,以及 TensorFlow、PyTorch、ONNX 等多種深度學(xué)習(xí)模型框架,可以很好的支持多模型聯(lián)合推理的場(chǎng)景,構(gòu)建起視頻、圖片、語(yǔ)音、文本整個(gè)推理服務(wù)過(guò)程,大大降低多個(gè)模型服務(wù)的開(kāi)發(fā)和維護(hù)成本。
基于C++ 的基礎(chǔ)架構(gòu)、Dynamic-batch、以及對(duì) TensorRT 的支持,同時(shí)配合 T4 的 GPU,將整體推理服務(wù)的吞吐能力最大提升 6 倍,延遲最大降低 40%,既滿足了業(yè)務(wù)的低延時(shí)需求,成本也降低了20%-66%。
通過(guò)將Triton編譯為動(dòng)態(tài)鏈接庫(kù),可以方便地鏈入公司內(nèi)部框架,對(duì)接公司的平臺(tái)治理體系。符合C語(yǔ)言規(guī)范的API也極大降低了用戶的接入成本。
借助Python Backend和Custom Backend,用戶可以自由選擇使用C++/Python語(yǔ)言進(jìn)行二次開(kāi)發(fā)。
Triton的Tracing能力可以方便地捕捉執(zhí)行過(guò)程中的數(shù)據(jù)流狀態(tài)。結(jié)合Metrics 和 Perf Analysis等組件,可以快速定位開(kāi)發(fā)調(diào)試,甚至是線上問(wèn)題,對(duì)于開(kāi)發(fā)和定位問(wèn)題的效率有很大提升。
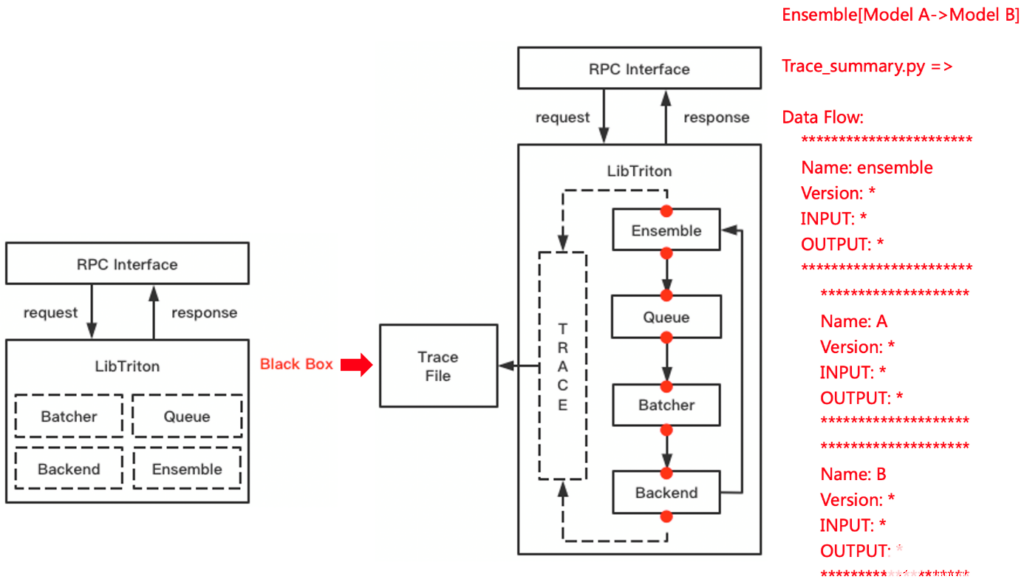
NVIDIA DALI 是 GPU 加速的數(shù)據(jù)增強(qiáng)和圖像加載庫(kù)。DALI Backend可以用于替換掉原來(lái)的圖片解碼、resize等操作。FIL Backend也可以替代Python XGBoost模型推理,進(jìn)一步提升服務(wù)端推理性能。
方案效果及影響
借助NVIDIA Triton 推理框架,配合 DALI/FIL/Python 等Backend,以及 TensorRT,整體推理服務(wù)的吞吐能力最大提升 6 倍,延遲最大降低 40%。幫助騰訊PCG各業(yè)務(wù)場(chǎng)景中,以更低的成本構(gòu)建了高性能的推理服務(wù),同時(shí)更低的延遲降低了整條系統(tǒng)鏈路的響應(yīng)時(shí)間,優(yōu)化了用戶體驗(yàn)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4986瀏覽量
103058 -
C++
+關(guān)注
關(guān)注
22文章
2108瀏覽量
73651 -
python
+關(guān)注
關(guān)注
56文章
4797瀏覽量
84689
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Triton編譯器在機(jī)器學(xué)習(xí)中的應(yīng)用
Triton編譯器功能介紹 Triton編譯器使用教程
NVIDIA助力Figure發(fā)布新一代對(duì)話式人形機(jī)器人
FPGA和ASIC在大模型推理加速中的應(yīng)用

NVIDIA助力麗蟾科技打造AI訓(xùn)練與推理加速解決方案

NVIDIA與思科合作打造企業(yè)級(jí)生成式AI基礎(chǔ)設(shè)施
NVIDIA助力提供多樣、靈活的模型選擇
英偉達(dá)推出全新NVIDIA AI Foundry服務(wù)和NVIDIA NIM推理微服務(wù)
LLM大模型推理加速的關(guān)鍵技術(shù)
NVIDIA加速計(jì)算和 AI助力數(shù)字銀行揭穿金融欺詐騙局
英特爾助力京東云用CPU加速AI推理,以大模型構(gòu)建數(shù)智化供應(yīng)鏈






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論