") i.MXRT上提升代碼執(zhí)行性能的十八般武藝
i.MXRT上提升代碼執(zhí)行性能的十八般武藝
今天給大家介紹的是在串口波特率識(shí)別實(shí)例里逐步展示i.MXRT上提升代碼執(zhí)行性能的十八般武藝。
恩智浦 MCU SE 團(tuán)隊(duì)近期一直在加班加點(diǎn)趕 SBL 項(xiàng)目(解決客戶產(chǎn)品 OTA 需求),這個(gè)項(xiàng)目里集成了 ISP 本地升級(jí)(UART/USB)功能,其中 UART 口下載升級(jí)實(shí)現(xiàn)里加入了自動(dòng)波特率識(shí)別支持,具體識(shí)別方法見(jiàn) 《串口(UART)自動(dòng)波特率識(shí)別程序設(shè)計(jì)與實(shí)現(xiàn)(中斷)》 一文,這一套 ISP 代碼其實(shí)是移植于 i.MXRT Flashloader(更早期的時(shí)候叫 KBOOT)。
ISP 代碼放在 SBL 工程里會(huì)出現(xiàn)高波特率(比如115200)無(wú)法識(shí)別的問(wèn)題,但在低波特率的情況下(比如9600,19200),ISP 代碼是功能正常的,說(shuō)明代碼本身并不存在邏輯缺陷,但高波特率下就異常了,大概率是遇到了代碼執(zhí)行性能瓶頸。今天痞子衡就嘗試在 i.MXRT 上使用各種方法去提升性能來(lái)解決這個(gè)高波特率無(wú)法識(shí)別問(wèn)題:
一、SBL項(xiàng)目里ISP串口高波特率識(shí)別問(wèn)題
SBL 項(xiàng)目是支持全系列 i.MXRT 平臺(tái)的,為了具體化問(wèn)題,我們就選取 i.MXRT1062 型號(hào)為例,官方配套 MIMXRT1060-EVK 板子上搭配了一顆四線串行 NOR Flash(芯成IS25WP064A)用于存放代碼。
SBL 程序主體是 XIP 執(zhí)行的,僅部分涉及 IAP 操作的代碼被分散加載到了 RAM 里。SBL 中 ISP 功能代碼主體當(dāng)然也是 XIP 為主,且在 SBL 程序里是最先執(zhí)行的(本地升級(jí)超時(shí)后才進(jìn)入 SBL 主體),SBL 工程里跟串口波特率識(shí)別相關(guān)的源文件一共如下三個(gè):
microseconds_pit.c -- 存放 PIT 計(jì)時(shí)函數(shù)
autobaud_irq.c -- 存放 GPIO 中斷回調(diào)、波特率識(shí)別計(jì)算函數(shù)
pinmux_utility_imxrt_series.c -- 存放 GPIO 配置與中斷處理函數(shù)
MIMXRT1060-EVK 板子上串口是 GPIO1[13:12],其中 RXD - GPIO1[13] 是核心的用于波特率識(shí)別的引腳,為了便于直觀地感受代碼執(zhí)行性能,我們用另一個(gè) GPIO1[12] 來(lái)輔助,將其配置為 GPIO 輸出模式,初值為高電平,在 GPIO 中斷處理函數(shù)里保持低電平來(lái)標(biāo)示執(zhí)行總時(shí)間:
- Note :下述代碼里中斷處理函數(shù)實(shí)際上有點(diǎn)小缺陷,《中斷處理函數(shù)(IRQHandler)的標(biāo)準(zhǔn)流程》 一文里給出了改進(jìn)方法,但這里為了觀察中斷處理代碼是否能在下一次中斷來(lái)臨前執(zhí)行完畢特意舍棄了文中 2.2.2 小節(jié)里的改進(jìn))
voidGPIO1_Combined_0_15_IRQHandler(void)
{
//****輔助調(diào)試:進(jìn)入中斷時(shí)拉低 GPIO1[12],標(biāo)志執(zhí)行時(shí)間起點(diǎn)
GPIO1->DR&=(uint32_t)~(1U<12);
uint32_tinterrupt_flag=(1U<13);
//僅當(dāng)GPIO1[13]下降沿中斷發(fā)生時(shí)
if((GPIO_GetPinsInterruptFlags(GPIO1)&interrupt_flag)&&s_pin_irq_func)
{
//執(zhí)行一次回調(diào)函數(shù)
s_pin_irq_func();
//清除GPIO1[13]中斷標(biāo)志
GPIO_ClearPinsInterruptFlags(GPIO1,interrupt_flag);
__DSB();
}
//****輔助調(diào)試:退出中斷時(shí)拉高 GPIO1[12],標(biāo)志執(zhí)行時(shí)間結(jié)束
GPIO1->DR|=(1U<12);
}
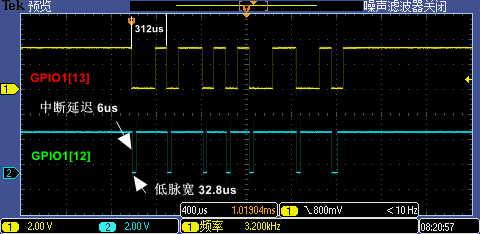
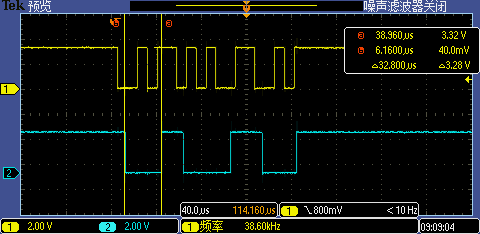
現(xiàn)在我們用示波器同時(shí)抓取 GPIO1[13:12] 信號(hào),分別測(cè)試 9600 低波特率(下圖一)和 115200 高波特率(下圖二)下實(shí)際波形,根據(jù)測(cè)量第一次 GPIO 中斷處理執(zhí)行時(shí)間大概是 32.8us(7 次中斷因代碼分支執(zhí)行不同略有區(qū)別),這個(gè)時(shí)間對(duì)于 9600 波特率下單 bit 傳輸耗時(shí)約 104us 的情況來(lái)說(shuō)是足夠快的,但是對(duì)于 115200 波特率下單 bit 傳輸耗時(shí)約 8.68us 的情況來(lái)說(shuō)就顯得有點(diǎn)慢了(最小的下降沿之間間隔是 2bit 傳輸耗時(shí) 17.36us ),這也是 115200 無(wú)法被識(shí)別的原因,因?yàn)橛?4 個(gè)下降沿中斷被漏掉了。
二、提升代碼性能的多種方法
既然代碼執(zhí)行性能不夠,那就努力提升性能,文章標(biāo)題叫十八般武藝,這只是一種夸張說(shuō)法,不過(guò)痞子衡確實(shí)收集了如下六種提升性能的方法,讓我們一一嘗試吧,注意下述結(jié)果都是疊加前面方法而得的(所有測(cè)試均是在 115200 波特率下進(jìn)行)。
Level 1:提升CPU主頻
ISP 功能代碼里配置的 CPU 主頻是 396MHz,實(shí)際上這是根據(jù) BootROM 默認(rèn)運(yùn)行配置而來(lái)的,而 i.MXRT1062 是可以跑到 600MHz 主頻的,將 SDK 代碼里 armPllConfig_BOARD_BootClockRUN.loopDivider 由 66 調(diào)大到 100 即可。
constclock_arm_pll_config_tarmPllConfig_BOARD_BootClockRUN={
.loopDivider=100,/*PLLloopdivider,Fout=Fin*50*/
.src=0,/*Bypassclocksource,0-OSC24M,1-CLK1_PandCLK1_N*/
};
voidBOARD_BootClockRUN(void)
{
//...
CLOCK_SetDiv(kCLOCK_AhbDiv,0);
CLOCK_SetDiv(kCLOCK_ArmDiv,1);
CLOCK_InitArmPll(&armPllConfig_BOARD_BootClockRUN);
CLOCK_SetMux(kCLOCK_PrePeriphMux,3);
CLOCK_SetMux(kCLOCK_PeriphMux,0);
//...
}
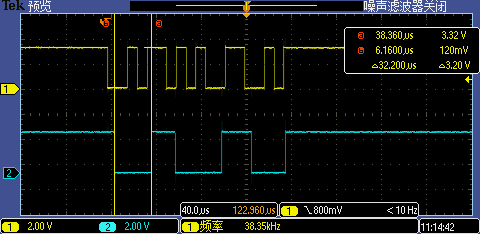
CPU 主頻提升后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 32.8us 下降到了 32.2us,性能僅有微小提升,看來(lái)此時(shí)主要性能瓶頸不在 CPU 主頻上,應(yīng)該是 Flash 訪問(wèn)性能在拖后腿。
Level 2:提升Flash訪問(wèn)速度
SBL 工程里啟動(dòng)頭 FDCB 配置的是 100MHz Flash 工作頻率,但 MIMXRT1060-EVK 板載 Flash(芯成IS25WP064A)最大工作頻率是 133MHz,所以我們可以提升 Flash 工作頻率。修改 qspiflash_config.memConfig.serialClkFreq 為 kFlexSpiSerialClk_133MHz 即可。不了解 FDCB 結(jié)構(gòu)體工作機(jī)制的可以翻閱痞子衡舊文 《從頭開(kāi)始認(rèn)識(shí)i.MXRT啟動(dòng)頭FDCB里的lookupTable》 。
constflexspi_nor_config_tqspiflash_config={
.memConfig=
{
.tag=FLEXSPI_CFG_BLK_TAG,
.version=FLEXSPI_CFG_BLK_VERSION,
.readSampleClkSrc=kFlexSPIReadSampleClk_LoopbackFromDqsPad,
.csHoldTime=3u,
.csSetupTime=3u,
.sflashPadType=kSerialFlash_4Pads,
//.serialClkFreq=kFlexSpiSerialClk_100MHz,
.serialClkFreq=kFlexSpiSerialClk_133MHz,
.sflashA1Size=8u*1024u*1024u,
.lookupTable=
{
FLEXSPI_LUT_SEQ(CMD_SDR,FLEXSPI_1PAD,0xEB,RADDR_SDR,FLEXSPI_4PAD,0x18),
FLEXSPI_LUT_SEQ(DUMMY_SDR,FLEXSPI_4PAD,0x06,READ_SDR,FLEXSPI_4PAD,0x04),
},
},
.pageSize=256u,
.sectorSize=4u*1024u,
.blockSize=64u*1024u,
.isUniformBlockSize=false,
};
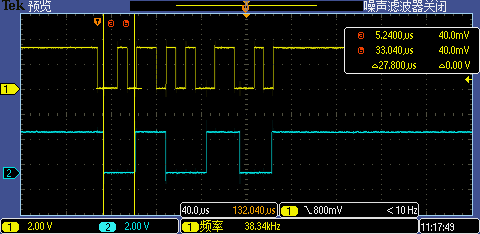
Flash 工作頻率提升后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 32.2us 下降到了 27.8us,這次的性能提升算有點(diǎn)明顯了,但是還是不夠,解決不了問(wèn)題。
Level 3:配置FlexSPI至最優(yōu)模式
讓我們繼續(xù)從 Flash 傳輸模式上做文章,ISP 功能代碼里配置的是普通 SPI 下 Fast Read Quad I/O SDR Non-Continuous 工作模式,這個(gè)模式已經(jīng)算是非常高效的傳輸模式了,如果還想改進(jìn),要么是切換到 QPI 模式(將 CMD 子序列也從一線變到四線)要么是使能 Continuous Read(除了第一個(gè) CMD 子序列,其后 CMD 子序列全部省掉),綜合考慮應(yīng)該是使能 Continuous Read 性能提升更大一些,具體方法參考 《在i.MXRT啟動(dòng)頭FDCB里使能串行NOR Flash的Continuous read模式》。
constflexspi_nor_config_tqspiflash_config={
.memConfig=
{
//...
.lookupTable=
{
FLEXSPI_LUT_SEQ(CMD_SDR,FLEXSPI_1PAD,0xEB,RADDR_SDR,FLEXSPI_4PAD,0x18),
//FLEXSPI_LUT_SEQ(DUMMY_SDR,FLEXSPI_4PAD,0x06,READ_SDR,FLEXSPI_4PAD,0x04),
//插入JUMP_ON_CS子序列
FLEXSPI_LUT_SEQ(MODE8_SDR,FLEXSPI_4PAD,0xA0,DUMMY_SDR,FLEXSPI_4PAD,0x04),
FLEXSPI_LUT_SEQ(READ_SDR,FLEXSPI_4PAD,0x04,JMP_ON_CS,FLEXSPI_1PAD,0x01),
},
},
//...
};
使能 Flash Continuous Read 后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 27.8us 下降到了 27.4us,性能僅有微小提升,這應(yīng)該跟我們使能了 FlexSPI prefetch 特性有關(guān),1KB AHB RX Buffer 的存在導(dǎo)致 CMD 子序列在總傳輸時(shí)序中占比不明顯。不過(guò)有點(diǎn)收獲的是漏掉的下降沿中斷從 4 個(gè)減少到了 3 個(gè)。
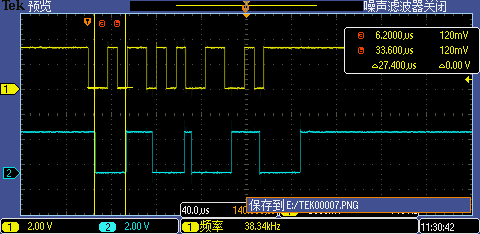
Level 4:打開(kāi)L1 Cache
對(duì)于 XIP 工程來(lái)說(shuō),不開(kāi) L1 I-Cache 加速性能是非常吃虧的一件事,i.MXRT1062 內(nèi)部有 32KB I-Cache,不把這個(gè) Cache 用起來(lái)簡(jiǎn)直是暴殄天物。雖然工程 SystemInit() 函數(shù)里會(huì)執(zhí)行一次 SCB_EnableICache(),但這只是一個(gè) Cache 總開(kāi)關(guān),要想 Cache 對(duì) Flash 映射地址(0x60000000 之后)產(chǎn)生作用還得借助 BOARD_ConfigMPU() 函數(shù)來(lái)具體配置 MPU。關(guān)于 Cache 對(duì) Flash 讀取的性能提升見(jiàn) 《實(shí)抓Flash信號(hào)波形來(lái)看i.MXRT的FlexSPI外設(shè)下AHB讀訪問(wèn)情形(全加速)》 。
intmain(void)
{
//將MPU配置提到ISP代碼之前
BOARD_ConfigMPU();
#if(defined(COMPONENT_MCU_ISP))
boolisInfiniteIsp=false;
isp_boot_main(isInfiniteIsp);
#endif
//BOARD_ConfigMPU();
//...
}
使能 Cache 后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 27.4us 下降到了 19us,后面的 GPIO 中斷執(zhí)行耗時(shí)更是大大縮短(原因是中斷處理函數(shù)相關(guān)代碼在第一次中斷觸發(fā)執(zhí)行時(shí)被順便放到 Cache 里了),這時(shí)候 115200 高波特率已經(jīng)能夠被正常識(shí)別了。
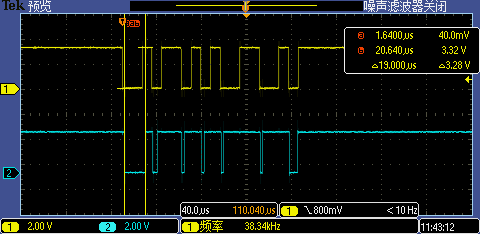
到這里問(wèn)題已經(jīng)解決了,但我們還沒(méi)有榨干 MCU 最后一滴血,優(yōu)化繼續(xù)。上圖波形里第一次 GPIO 中斷處理執(zhí)行時(shí)間相比其后面的 6 次中斷執(zhí)行耗時(shí)要明顯長(zhǎng),這還是有風(fēng)險(xiǎn)的,比如再高的波特率 256000 還是無(wú)法正常識(shí)別(至少第一次識(shí)別會(huì)失敗,后面上位機(jī)再重復(fù)發(fā)暗號(hào)做第二次識(shí)別就可以了)。為了讓第一次 GPIO 中斷處理時(shí)間也大大縮短,我們可以在系統(tǒng)初始化的時(shí)候故意調(diào)用一下這些中斷處理相關(guān)函數(shù),將這些代碼事先裝載到 I-Cache里。
voidautobaud_init(void)
{
s_transitionCount=0;
s_firstByteTotalTicks=0;
s_secondByteTotalTicks=0;
s_lastToggleTicks=0;
s_ticksBetweenFailure=microseconds_convert_to_ticks(kMaximumTimeBetweenFallingEdges);
enable_autobaud_pin_irq(pin_transition_callback);
//故意調(diào)用一下,讓I-Cache事先將代碼Cache住
GPIO1_Combined_0_15_IRQHandler();
pin_transition_callback();//即第一節(jié)代碼中的s_pin_irq_func()
}
將中斷處理函數(shù)相關(guān)代碼預(yù)裝載到 I-Cache 后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 19us 銳降到了 2.12us,跟其他中斷處理執(zhí)行差不多的耗時(shí),現(xiàn)在即使是 256000 高波特率也能一次識(shí)別成功。
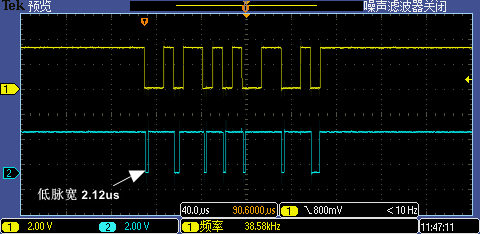
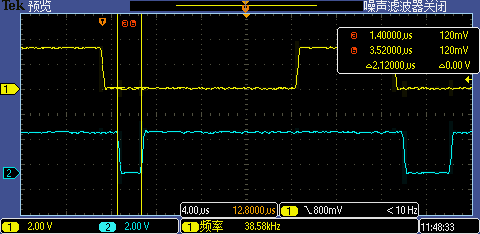
Level 5:拷貝到TCM里
靠 Cache 這種無(wú)法精準(zhǔn)控制的優(yōu)化策略始終讓我們無(wú)法放心,還是將中斷處理相關(guān)代碼直接放到 TCM 里更可靠,我們?cè)诠こ替溄游募∕IMXRT1062xxxxx_flexspi_nor.icf)里做如下修改將第一節(jié)里列出了三個(gè)源文件全部弄到 RAM 區(qū)里執(zhí)行(對(duì)于 XIP 工程來(lái)說(shuō),RAM 區(qū)是 DTCM, 當(dāng)然對(duì)于代碼來(lái)說(shuō) ITCM 效率要更高,不過(guò) DTCM 也夠用了)。
initialize by copy {
readwrite,
/* Place in RAM flash and performance dependent functions */
object microseconds_pit.o,
object autobaud_irq.o,
object pinmux_utility_imxrt_series.o,
// ...
section .textrw
};
do not initialize { section .noinit };
將中斷處理函數(shù)相關(guān)代碼重定位到 DTCM 執(zhí)行后第一次 GPIO 中斷處理執(zhí)行時(shí)間從 2.12us 再降到了 520ns,這下 1M 超高波特率也能被識(shí)別了。
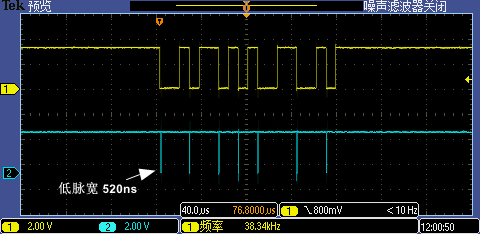
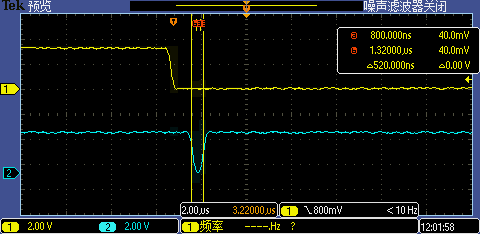
Level 6:指定函數(shù)地址以八字節(jié)對(duì)齊
性能提升結(jié)束了嗎?痞子衡還有一招,參見(jiàn) 《鏈接函數(shù)到8字節(jié)對(duì)齊地址或可進(jìn)一步提升i.MXRT1xxx內(nèi)核執(zhí)行性能》 一文,將中斷處理相關(guān)函數(shù)全部鏈接到八字節(jié)對(duì)齊地址還可以再利用 Cortex-M7 內(nèi)核指令雙發(fā)射特性。我們查看下工程映射文件(sbl.map),三個(gè)相關(guān)函數(shù)僅有計(jì)時(shí)函數(shù) microseconds_get_ticks() 被自動(dòng)分配到了八字節(jié)對(duì)齊的地址,其他兩個(gè)函數(shù)不是,所以還有提升空間。
Entry Address Size Type Object
;---- ------- ---- ---- ------
GPIO1_Combined_0_15_IRQHandler
0x2000'0b2f 0x3e Code Gb pinmux_utility_imxrt_series.o [1]
pin_transition_callback 0x2000'0175 0x8e Code Gb autobaud_irq.o [1]
microseconds_get_ticks 0x2000'08e9 0x22 Code Gb microseconds_pit.o [1]
將非八字節(jié)地址對(duì)齊的中斷處理相關(guān)函數(shù)調(diào)整到八字節(jié)地址對(duì)齊后(具體方法這里就不展開(kāi)介紹了),第一次 GPIO 中斷處理執(zhí)行時(shí)間從 520ns 降到了 480ns,這幾乎是性能極限了。
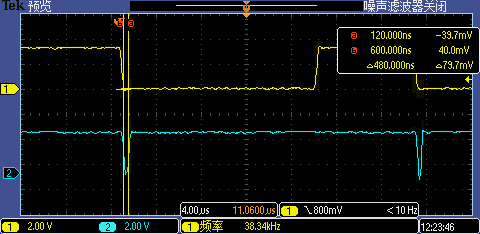
至此,在串口波特率識(shí)別實(shí)例里逐步展示i.MXRT上提升代碼執(zhí)行性能的十八般武藝痞子衡便介紹完畢了,掌聲在哪里~~~
審核編輯 :李倩
-
波特率
+關(guān)注
關(guān)注
2文章
308瀏覽量
34221 -
代碼
+關(guān)注
關(guān)注
30文章
4815瀏覽量
68852
原文標(biāo)題:提升MCU代碼執(zhí)行性能的十八般武藝
文章出處:【微信號(hào):mcu168,微信公眾號(hào):硬件攻城獅】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AN-840: 通過(guò)I2C接口更新代碼

怎么提升單片機(jī)代碼執(zhí)行效率
Triton編譯器如何提升編程效率
谷歌正式發(fā)布Gemini 2.0 性能提升近兩倍
NPU技術(shù)如何提升AI性能
韓國(guó)服務(wù)器的性能如何提升
不同J-Link版本對(duì)于i.MXRT1170連接復(fù)位后處理行為

助力全國(guó)一體化算力網(wǎng)建設(shè),神州鯤泰以算力構(gòu)建新質(zhì)生產(chǎn)力

ZR執(zhí)行器:提升生產(chǎn)效率的關(guān)鍵一環(huán)
HarmonyOS NEXT應(yīng)用開(kāi)發(fā)性能優(yōu)化入門引導(dǎo)
在i.MXRT1xxx系列上用NAND型啟動(dòng)設(shè)備時(shí)可用兩級(jí)設(shè)計(jì)縮短啟動(dòng)時(shí)間
如何提升代碼質(zhì)量與效率的秘訣
如何構(gòu)筑身份安全防線,避免被黑客“登入”企業(yè)網(wǎng)絡(luò)?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論