 幾種基于深度學習的中文糾錯模型
幾種基于深度學習的中文糾錯模型
1 簡介
在之前的篇章我們對中文文本糾錯做了一個系統的介紹,曾經盛行的糾錯系統都是基于混淆集+n-gram語言模型的,其中混淆集構建成本巨大,同時相對笨重,而n-gram語言模型也沒考到句子的語義信息,所以導致最終的F1得分都比較小,很難滿足真實場景的需要,泛化能力很比較差。同時以往的糾錯系統都是基于pipeline的,檢測任務跟糾錯任務是相互分開的,各個環節緊急相連,前面的環節如果出現了錯誤,后面的環節也很難進行修正。任何一個環節出現了問題,都會影響整體的結果。
隨著深度學習的興起,人們逐漸用深度學習模型去替換以往的混淆集+n-gram語言模型的方式,根據句子的語義信息去進行糾錯,同時,還將檢測任務跟糾正任務聯合到一起,做成一個end2end的系統,避免pipeline方式帶來的問題。在這里我們介紹幾種基于深度學習的中文糾錯模型,讓大家對于中文文本糾錯有更加深入的理解。
2Confusionset-guided Pointer Network
Confusionset-guided Pointer Network是一個seq2seq模型,同時學習如何從原文本復制一個正確的字或者從混淆集中生成一個候選字。整個模型分為encoder跟decoder兩部分。其中encoder用的BiLSTM用于獲取原文本的高層次表征,例如圖中左下角部分,decoder部分用的帶注意力機制的循環神經網絡,在解碼的每個時刻,都能生成相應的上下文表征。生成的上下文表征有兩個用途,第一個是利用這部分表征作為輸入,通過矩陣乘法跟softmax來計算當前位置生成全詞表中各個字的概率(右邊的概率圖)。第二個用途是利用這部分上下文表征加上位置信息來計算當前時刻復制原文本某個位置的字的概率或者需要生成原文本中不存在的字的概率(左邊的概率圖,這里其實是一個分類模型,假設原文本的長度是n,那么全部分類有n+1種,其中1至n的標簽的概率代表當前時刻要復制原文本第i個位置的字的概率,第n+1的類別代表當前時刻要生成原文本不存在的字的概率。如果是1至n中某個類別的概率最大,那么當前位置的解碼結果就是復制對應概率最大的原文本的某個字,如果是第n+1個類別概率最大,那么就會用到前面提及的第一個用途,計算當前位置詞表中各個字的概率,取其中概率最大的字作為當前時刻解碼的結果)。這里要注意的是,生成新字為了保證結果更加合理,會事先構建好一個混淆集,對于每個字,都有若干個可能錯別字(形近字或者同音字等),模型會對生成的候選會限制在這個字的混淆集中,也不是在全詞表中選擇,所以才稱為confusionset-guided。訓練時會聯合encoder跟decoder一同訓練,以預測各個類別的交叉熵損失作為模型優化目標。
Confusionset-guided Pointer Network看起來跟之前提及的CopyNet思路很接近文本生成系列之文本編輯,同時考慮到copy原文跟生成新字兩種可能性,相對于之前的seq2seq模型的改進主要是引入混淆集來控制可能的候選字符。這種設置也比較合理,中文的錯別字多是在形狀或者發音上有一定相似之處,通過混淆集可以進一步約束糾錯的結果,防止糾錯的不可控。但是由于生成的結果一定來源于混淆集,所以混淆集的質量也影響了最終糾錯的效果。一個合理的混淆集的構建都需要付出比較大的代價。
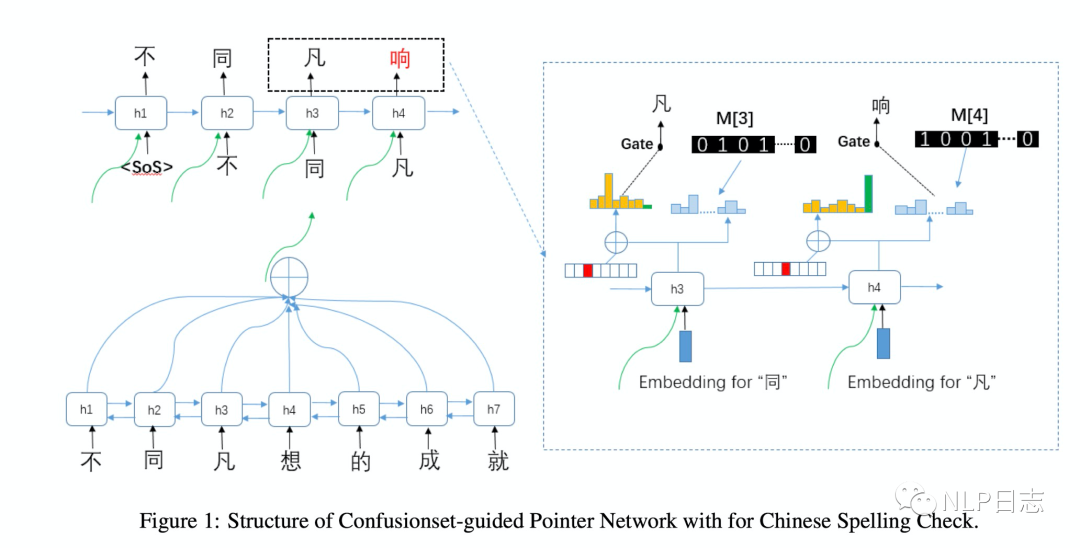
圖1:Confusionset-guided Pointer Network框架
3 FASPell
這是愛奇藝發布在EMNLP2019的基于詞的中文糾錯的方法,FASPell有兩個特別的點,一個是用BERT為基礎的DAE取代了傳統的混淆集,另一點是使用置信度-相似度的解碼器來過濾候選集,從而提高糾錯效果。
FASPell首先利用Bert來生成句子每個字符的可能候選結果,但是Bert的預訓練任務MLM中選中的token有10%是被隨機替代的,這跟文本糾錯的場景不符,所以需要對Bert進行一定的微調。具體過程就是對MLM任務做一定調整,調整策略如下
a)如果文本沒有錯誤,那么沿用之前Bert的策略。
b)如果文本有錯誤,那么隨機選擇的要mask的位置的字,如果處于錯誤的位置,那么設置對應的標簽為糾錯后的字,也就是相對應的正確的字。如果不是處于錯誤的位置,那么設置對應的標簽為原來文本中的字。
在獲得文本可能的候選結果后,FASPell利用置信度-相似度的解碼器來過濾這些候選結果。這里為什么需要對Bert生成的候選字進行過濾呢?因為漢語中常見的錯誤大部分在字形或者發音有一定相似之處,但是Bert生成的候選字并沒有考慮到中文糾錯的背景,所以Bert提供的候選結果很多都是糾錯任務不相關的。這里每個位置的候選詞的置信度由Bert計算得到,相似度這里包括字形相似度跟音素相似度,其中因素相似度考慮到在多種語言中的發音。對于每個位置的候選詞,只有當置信度,字形相似度跟音素相似度滿足某個條件時,才會用這個候選字符替代到原文對應字符。至于這個過濾條件,一般是某種加權組合,通常需要置信度跟相似度的加權和超過一定閾值才會進行糾錯,加權相關的參數可以通過訓練集學習得到,在推理時就可以直接使用。
FASPell沒有單獨的檢測模塊,利用BERT來生成每個位置的候選字,避免了以往構建混淆集的工作,同時利用后續的置信度-相似度的解碼器,對候選結果進行過濾,從而進一步提高糾錯效果。
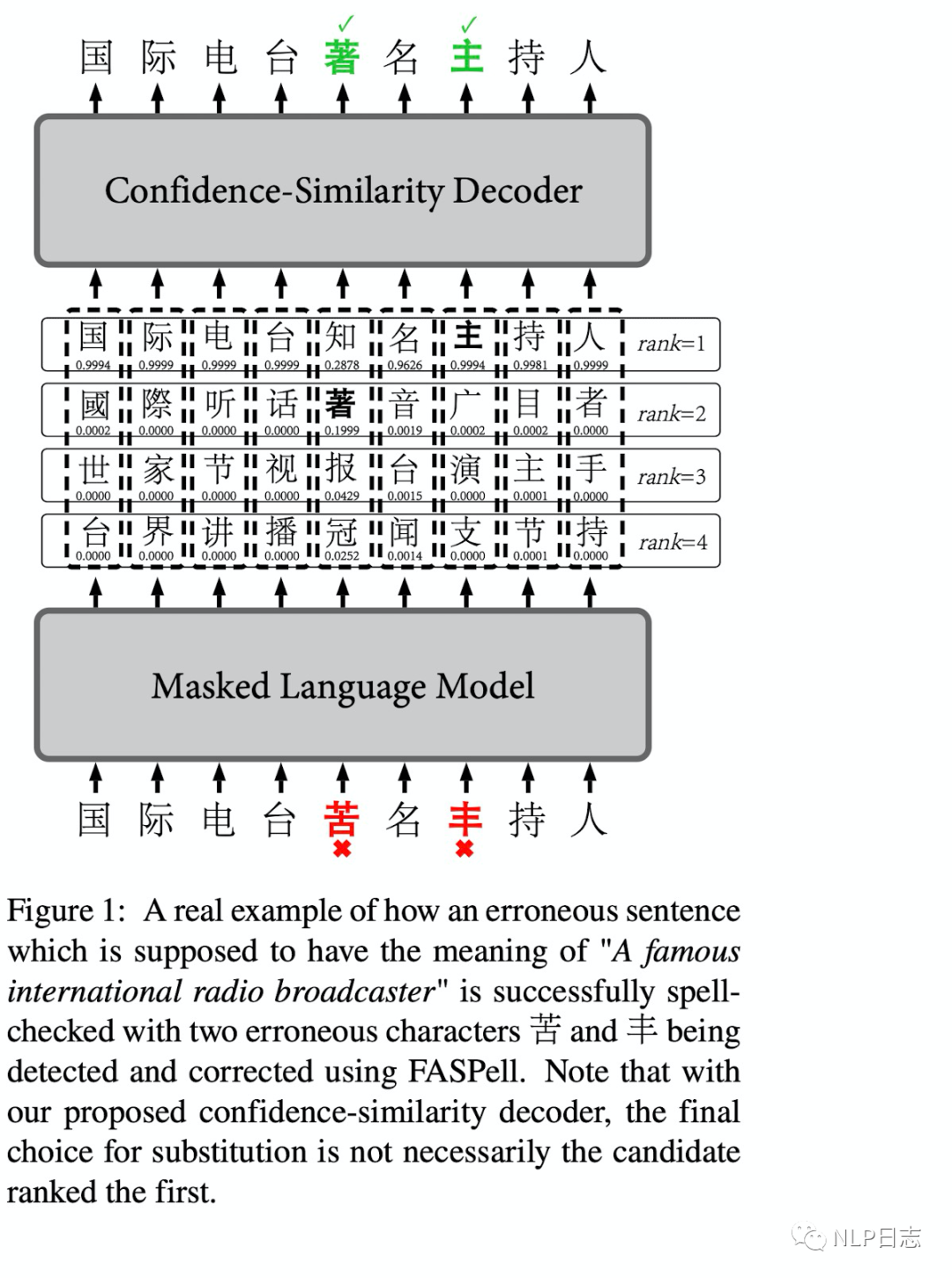
圖2: FASPell框架
4Soft-Masked BERT
Soft-masked Bert是字節發表在ACL 2020的中文糾錯方法,針對目前主流的深度學習糾錯方法都是利用Bert生成各個位置的可能候選,但是Bert本身缺乏判斷每個位置是否需要糾錯的能力,也就是缺乏檢測能力。為此,提出了一個包含檢測網絡跟糾正網絡的中文糾錯方法。整個流程是經過檢測網絡,然后再經過糾錯網絡。其中檢測網絡是的雙向GRU+全連接層做一個二分類任務,計算原文本每個位置是否有錯誤的概率。每個位置有錯別字的概率為p,沒有錯別字的概率是1-p,如圖中左邊部分。糾正網絡采用的是預訓練模型Bert,但是在嵌入層的地方有所不同,每個位置的嵌入是由原文本中對應位置的字的詞嵌入跟[MASK]的詞嵌入的加權和得到的,這里的[MASK]的權重等于檢測網絡預測的當前位置是錯別字的概率。具體如圖4所示,所以如果檢測網絡判斷當前位置是錯別字的概率較高,那么在糾正網絡中該位置的詞嵌入中[MASK]的權重就更高,反之,如果檢測網絡判斷當前位置是錯別字的概率很低,那么在糾正網絡中該位置的詞嵌入中[MASK]的權重就更低。利用Bert獲得每個位置的表征后,將Bert最后一層的輸出加上原文本中對應位置的詞嵌入作為每個時刻最終的表征,通過全連接層+Softmax去預測每個位置的字,最終選擇預測概率最大的字作為當前結果的輸出。訓練過程中聯合訓練檢測網絡跟糾正網絡的,模型的目標包括兩部分,一個是檢測網絡的對數似然函數,另一個是糾正網絡的對數似然函數,通過加權求和聯合這兩部分,使得加權和的負數盡可能小,從而同時優化這兩個網絡的參數。
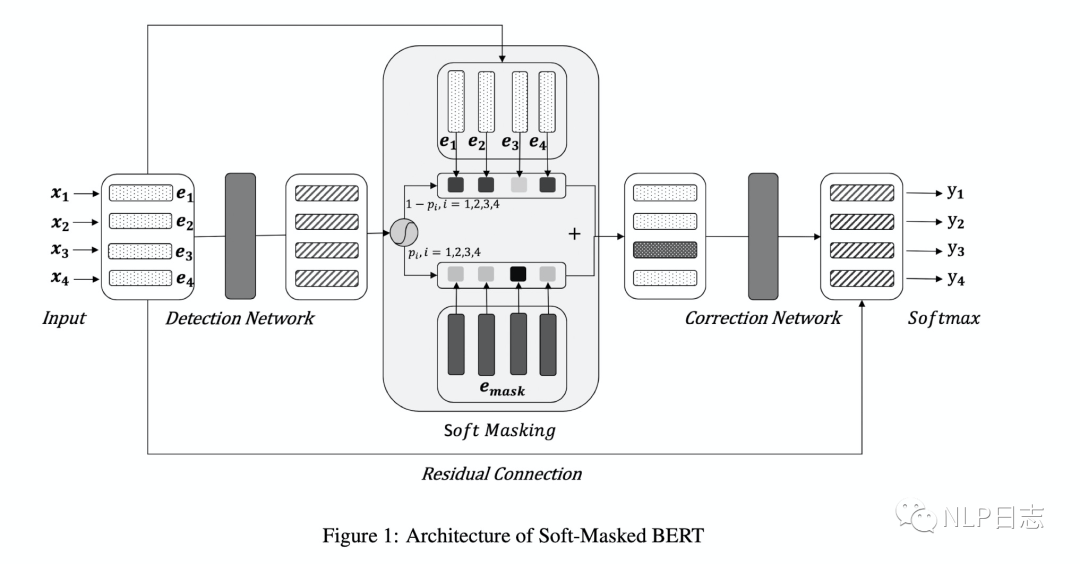
圖3: Soft-Masked BERT框架
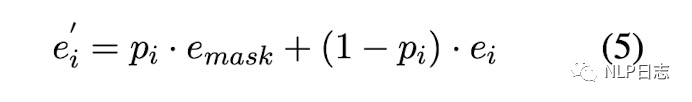
圖4: Softed-masked embedding
Soft-Masked BERT相比直接采用預訓練模型BERT,利用檢測網絡從而得到更合理的soft-masked embedding,緩解了Bert缺乏充足檢測能力的問題,雖然改動不大,但是效果提升明顯。
5 MLM-phonetics
個人感覺MLM-phonetics是在soft-masked BERT的基礎上做的優化,思路也比較接近,同樣是包括檢測網絡跟糾正網絡,主要有幾點不同,
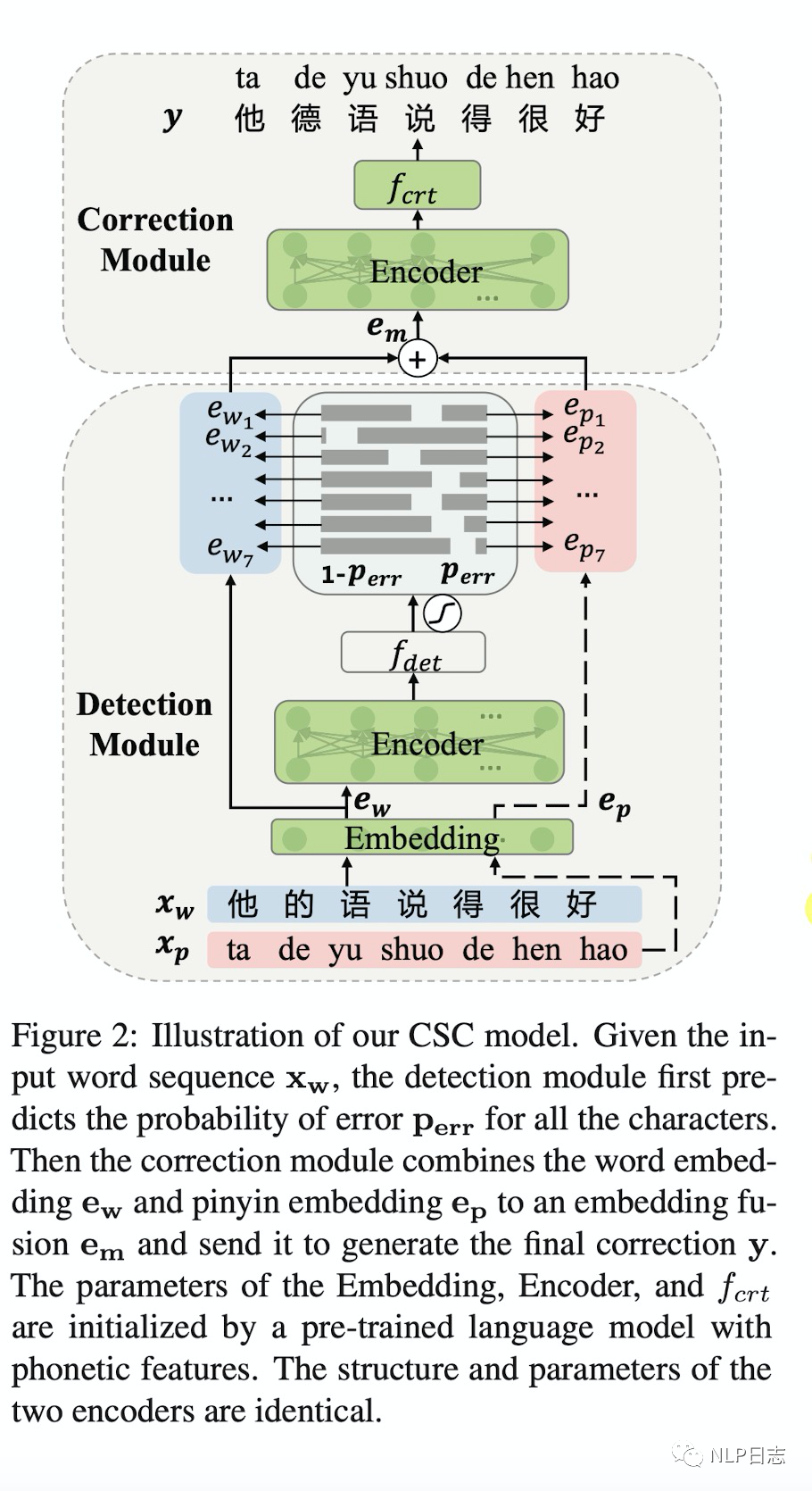
圖5: MLM-phonetics框架
a)糾正網絡的詞嵌入組成不同,Soft-Masked BERT的詞嵌入由原文本中各個位置本身的詞嵌入和[MASK]的詞嵌入組成,而MLM-phonetics則是將相應[MASK]的詞嵌入替換為相應位置對應的拼音序列的嵌入。
b)目標函數不同,MLM-phonetics在糾正網絡的目標函數中加入了檢測網絡的預測結果作為一個權重項。
c)檢測網絡不同,MLM-phonetics的檢測網絡采用了預訓練模型Bert。
d) BERT預訓練任務不同,為了更加適配中文糾錯任務的場景,MLM-phonetics的Bert的MLM任務中預測的字都是根據漢字常見的錯誤選取的,要不在字形上有相似之處,要不在發音上有相似之處。
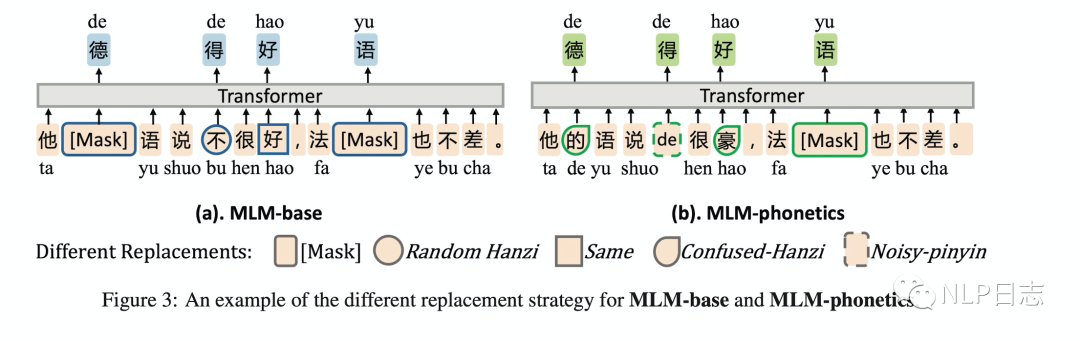
圖6: MLM-phonetics預訓練任務
6 總結
為了對比上述幾種中文糾錯方法之間的差異,可以直接比較這幾種方法在幾個常見中文糾錯數據集上的性能表現,在F1值上都遠超基于混淆集+n-gram語言模型的方式。
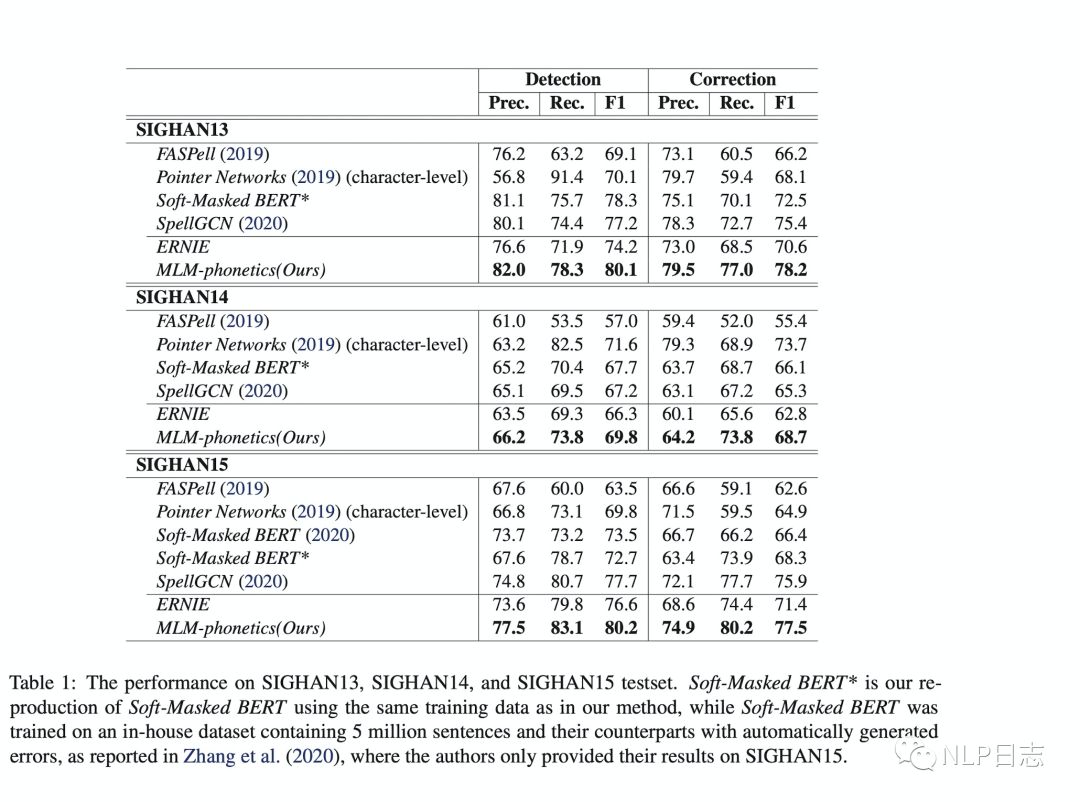
圖7:不同糾錯模型的效果對比
除此之外,關于中文糾錯任務,還有一些需要注意的點。
a)由于糾錯任務可以分為檢測跟糾正兩個過程,所以相應的錯誤也可以分為這兩種類型。目前基于BERT的中文糾錯方法的檢測錯誤的比例要高于糾正錯誤的比例,這也得益于Bert訓練過程的MLM任務。
b)中文糾錯方法基本都是以字為基本單位,很大程度是因為以詞為單位的話會引入分詞模塊的錯誤,但是可以用分詞的結構來作為字的特征增強。
c)目前中文糾錯任務有兩種類型的錯誤還沒有很好的解決。第一種是模型需要強大推理能力才能解決,例如“他主動牽了姑娘的手,心里很高心,嘴上卻故作生氣。”這里雖然容易檢測出“高心”是錯別字,但是至于要把它糾正為“寒心”還是“高興”需要模型有強大的推理能力才可以。第二種錯誤是由于缺乏常識導致的(缺乏對這個世界的認識),例如“蕪湖:女子落入青戈江,眾人齊救援。”需要知道相關的地理知識才能把“青戈江”糾正為“青弋江”。
審核編輯 :李倩
-
檢測
+關注
關注
5文章
4507瀏覽量
91598 -
文本
+關注
關注
0文章
118瀏覽量
17098 -
深度學習
+關注
關注
73文章
5510瀏覽量
121338
原文標題:中文文本糾錯系列之深度學習篇
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度學習模型的魯棒性優化
深度學習模型有哪些應用場景
深度神經網絡模型量化的基本方法

深度學習模型中的過擬合與正則化
深度學習中的時間序列分類方法
深度學習中的模型權重
人工智能深度學習的五大模型及其應用領域
深度學習的典型模型和訓練過程
為什么深度學習的效果更好?






 工商網監
工商網監
評論