") RapidIO針對低延遲處理器連接進(jìn)行優(yōu)化
RapidIO針對低延遲處理器連接進(jìn)行優(yōu)化
隨著摩爾定律繼續(xù)推動(dòng)處理器的性能和集成,對更高速互連的需求也在持續(xù)增長。今天的互連通常運(yùn)動(dòng)速度從 10 Gbps 到 80 Gbps 不等,并且具有達(dá)到每秒數(shù)百千兆位的路線圖。
在爭取越來越快的互連速度的競賽中,一些話題很少被討論,包括支持的事務(wù)類型、通信延遲和開銷,以及可以輕松支持的拓?fù)漕愋汀TO(shè)計(jì)人員傾向于認(rèn)為所有互連都是平等的,并且具有僅基于峰值帶寬的品質(zhì)因數(shù)。
現(xiàn)實(shí)完全不同。正如針對通用、信號(hào)處理、圖形和通信應(yīng)用優(yōu)化的不同形式的處理器一樣,互連也針對不同的連接問題進(jìn)行設(shè)計(jì)和優(yōu)化。互連通常可以解決其設(shè)計(jì)的問題,并且可以投入使用以解決其他應(yīng)用程序,但在這些應(yīng)用程序中效率會(huì)降低。
RapidIO 設(shè)計(jì)目標(biāo)
在這種情況下查看 RapidIO 是有啟發(fā)性的。RapidIO 旨在用作低延遲處理器互連,用于需要高可靠性、低延遲和確定性操作的嵌入式系統(tǒng)。它旨在將來自不同制造商的不同類型的處理器連接到一個(gè)系統(tǒng)中。正因?yàn)槿绱耍琑apidIO 已在無線基礎(chǔ)設(shè)施設(shè)備中得到廣泛應(yīng)用,其中需要將通用、數(shù)字信號(hào)、FPGA 和通信處理器結(jié)合在一個(gè)緊密耦合的系統(tǒng)中,具有低延遲和高可靠性。
RapidIO 的使用模型需要提供對內(nèi)存到內(nèi)存事務(wù)的支持,包括原子讀取-修改-寫入操作。為滿足這些要求,RapidIO 提供了無需軟件干預(yù)即可實(shí)現(xiàn)的遠(yuǎn)程直接內(nèi)存訪問 (RDMA)、消息傳遞和信令結(jié)構(gòu)。例如,在 RapidIO 系統(tǒng)中,處理器可以發(fā)出加載或存儲(chǔ)事務(wù),或者集成的 DMA 引擎可以在兩個(gè)內(nèi)存位置之間傳輸數(shù)據(jù)。這些操作在其源或目標(biāo)地址所在的 RapidIO 結(jié)構(gòu)中執(zhí)行,并且通常無需任何軟件干預(yù)即可發(fā)生。從處理器看來,它們與普通的內(nèi)存事務(wù)沒有什么不同。
RapidIO 還旨在支持點(diǎn)對點(diǎn)交易。假設(shè)系統(tǒng)中有多個(gè)主機(jī)或主處理器,并且這些處理器需要通過共享內(nèi)存、中斷和消息相互通信。在 RapidIO 網(wǎng)絡(luò)中可以配置多個(gè)處理器(最高 16K),每個(gè)處理器都有自己的完整地址空間。
RapidIO 還在交換機(jī)和端點(diǎn)的功能之間提供了清晰的分界線。RapidIO 交換機(jī)僅根據(jù)明確的源/目標(biāo)地址對和明確的優(yōu)先級(jí)做出切換決策。這允許 RapidIO 端點(diǎn)添加新的事務(wù)類型,而無需更改或增強(qiáng)交換設(shè)備。
比較互連
隨著越來越多的系統(tǒng)被集成到單個(gè)硅片上,PCI Express (PCIe) 和以太網(wǎng)正在集成到片上系統(tǒng) (SoC) 中。然而,這種集成并沒有改變這些互連提供的事務(wù)的性質(zhì)(參見圖 1)。
圖 1: RapidIO、PCI Express 和以太網(wǎng)為連接處理器、I/O 和系統(tǒng)提供了不同的選項(xiàng)。
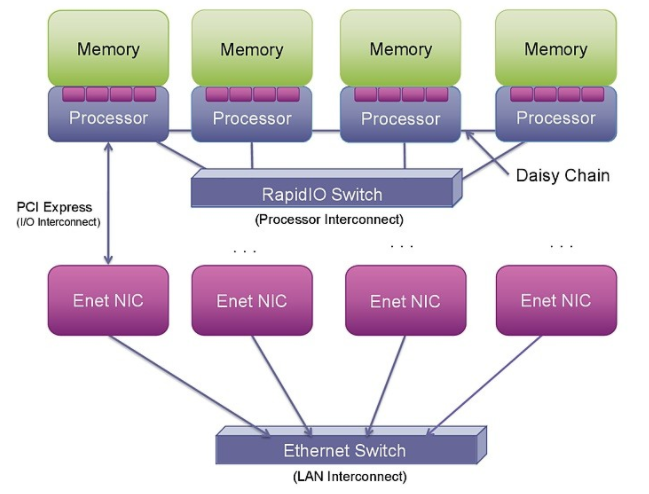
PCIe 本身并不支持點(diǎn)對點(diǎn)處理器連接。使用 PCIe 進(jìn)行這種連接可能非常復(fù)雜,因?yàn)樗辉O(shè)計(jì)為外圍組件互連(因此是 PCI)。它旨在將外圍設(shè)備(通常是 I/O 和圖形芯片等從屬設(shè)備)連接到主主機(jī)處理器。它不是作為處理器互連設(shè)計(jì)的,而是作為 PCI 總線的串行版本。從 PCI 構(gòu)建多處理器互連需要超越基本 PCI 規(guī)范的步驟,以創(chuàng)建在多個(gè)主機(jī)或根處理器之間映射地址空間和設(shè)備標(biāo)識(shí)符的新機(jī)制。迄今為止,執(zhí)行此操作的提議機(jī)制——高級(jí)交換 (AS)、非透明橋接 (NTB) 或多根 I/O 虛擬化 (MR-IOV)——都沒有在商業(yè)上取得成功。
對于有明確的單一主機(jī)設(shè)備且其他處理器和加速器作為從設(shè)備運(yùn)行的系統(tǒng),PCIe 是連接的不錯(cuò)選擇。然而,為了在更復(fù)雜的系統(tǒng)中將許多處理器連接在一起,PCIe 在拓?fù)浣Y(jié)構(gòu)和對等連接的支持方面存在很大限制。
許多開發(fā)人員正在尋求利用以太網(wǎng)作為連接系統(tǒng)中處理器的解決方案。在過去的 35 年中,以太網(wǎng)取得了長足的發(fā)展。與計(jì)算機(jī)處理速度的提高類似,其峰值帶寬也在穩(wěn)步增長。目前可用的以太網(wǎng)網(wǎng)絡(luò)接口控制器 (NIC) 卡可以支持 40 Gbps 運(yùn)行,通過四對 SERDES 和 10 Gbps 信號(hào)傳輸。這樣的 NIC 卡本身包含重要的處理,能夠以這些速度傳輸和接收數(shù)據(jù)包。
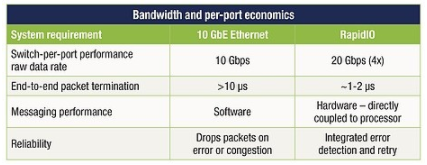
從解決方案到緊密耦合的處理器間通信,通過 NIC 發(fā)送和接收以太網(wǎng)數(shù)據(jù)包還有很長的路要走。與 PCIe 和以太網(wǎng)事務(wù)處理相關(guān)的開銷(兩個(gè)堆棧都必須在 NIC 中遍歷),加上相關(guān)的 SERDES 功能和以太網(wǎng)媒體訪問協(xié)議和交換增加了延遲、復(fù)雜性和更高的功耗以及系統(tǒng)成本可以使用更直接的連接方法(見表 1)。
表 1:以太網(wǎng)和 RapidIO 的比較顯示了更直接連接方法的優(yōu)勢。
將以太網(wǎng)用作集成嵌入式處理器互連需要對以太網(wǎng)媒體訪問控制器 (MAC) 以及以太網(wǎng)交換機(jī)設(shè)備本身進(jìn)行顯著的事務(wù)加速和增強(qiáng)。即使有了這些增強(qiáng),RDMA 操作也應(yīng)該僅限于大塊交易,以分?jǐn)偸褂靡蕴W(wǎng)的開銷。
已部署用于解決此問題的標(biāo)準(zhǔn)包括來自 Internet 工程任務(wù)組的 iWARP RDMA 協(xié)議和基于融合以太網(wǎng)的 RDMA (RoCE)。iWARP 和 RoCE 通常都是通過加速協(xié)處理器實(shí)現(xiàn)的。盡管有這種加速,但仍必須仔細(xì)管理 RDMA 事務(wù)以減少通信開銷。原因是盡管以太網(wǎng)提供了高帶寬,尤其是在 10 GbE 和 40 GbE 實(shí)施中,但它也具有通常以微秒為單位測量的高事務(wù)延遲。
當(dāng)前的 RapidIO 應(yīng)用程序
多年來,RapidIO 的價(jià)值主張已在嵌入式市場中得到廣泛認(rèn)可。同樣的價(jià)值主張現(xiàn)在可以擴(kuò)展到更主流的數(shù)據(jù)處理市場,這些市場正在演變?yōu)樾枰?a href="http://www.xsypw.cn/tongxin/" target="_blank">通信網(wǎng)絡(luò)長期以來需要的許多相同的系統(tǒng)屬性。
其中使用 RapidIO 的一種眾所周知的應(yīng)用是無線基站。該應(yīng)用程序結(jié)合了多種形式的處理(DSP、通信和控制),必須在很短的時(shí)間內(nèi)完成。處理設(shè)備之間的通信應(yīng)盡可能快速和確定,以確保實(shí)現(xiàn)實(shí)時(shí)約束。
例如,在 4G 長期演進(jìn) (LTE) 無線網(wǎng)絡(luò)中,每 10 毫秒發(fā)送一次幀。這些幀包含多個(gè)并發(fā)移動(dòng)會(huì)話的數(shù)據(jù),分布在多個(gè)子載波上,由多個(gè) DSP 設(shè)備支持。DSP 和通用處理設(shè)備之間的通信必須具有確定性和低延遲,以確保每 10 毫秒就有一個(gè)新幀準(zhǔn)備好傳輸。同時(shí),接收路徑必須支持來自連接到網(wǎng)絡(luò)的移動(dòng)設(shè)備的數(shù)據(jù)。除了這種復(fù)雜性之外,系統(tǒng)還必須實(shí)時(shí)跟蹤移動(dòng)設(shè)備的位置并管理設(shè)備的信號(hào)功率。
RapidIO 應(yīng)用的另一個(gè)例子是半導(dǎo)體晶圓加工。與無線基礎(chǔ)設(shè)施應(yīng)用類似,半導(dǎo)體晶圓加工具有實(shí)時(shí)限制,包括傳感器、處理和執(zhí)行器的控制回路。前沿系統(tǒng)通常有數(shù)百個(gè)傳感器收集信息,傳感器數(shù)據(jù)由數(shù)十到數(shù)百個(gè)處理節(jié)點(diǎn)處理。處理節(jié)點(diǎn)生成的命令發(fā)送到執(zhí)行器和交流和直流電機(jī),以重新定位晶片和晶片成像子系統(tǒng)。這一切都是在頻率高達(dá) 100 kHz 或 10 微秒的循環(huán)控制循環(huán)中執(zhí)行的。像這樣的系統(tǒng)受益于設(shè)備之間可能的最低延遲通信。
高性能計(jì)算的未來
虛擬化、基于 ARM 的服務(wù)器和高度集成的 SoC 設(shè)備的引入正在為下一階段的高性能計(jì)算發(fā)展鋪平道路。這種演變正朝著更緊密耦合的處理器集群發(fā)展,這些集群代表為托管數(shù)百或數(shù)千臺(tái)虛擬機(jī)而構(gòu)建的處理場。這些處理器集群將由多達(dá)數(shù)千個(gè)通過高性能、低延遲處理器互連連接的多核 SoC 設(shè)備組成。這種互連的效率越高,系統(tǒng)的性能和經(jīng)濟(jì)性就越好。
PCIe 和 10 GbE 等技術(shù)不會(huì)很快消失,但它們不會(huì)成為這些未來緊密耦合計(jì)算系統(tǒng)的基礎(chǔ)。PCIe 不是一種結(jié)構(gòu),只能支持少量處理器和/或外圍設(shè)備的連接。它可以簡單地充當(dāng)?shù)浇Y(jié)構(gòu)網(wǎng)關(guān)設(shè)備的橋梁。雖然 10 GbE 可用作結(jié)構(gòu),但它具有重要的硬件和軟件協(xié)議處理要求。其廣泛可變的幀大小(巨型幀為 46 B 到 9,000 B)推動(dòng)了對快速處理邏輯的需求,以支持多個(gè)小數(shù)據(jù)包和大型內(nèi)存緩沖區(qū)以支持端點(diǎn)和交換機(jī)中的大數(shù)據(jù)包,從而提高了芯片成本。使用 PCIe 或 10 GbE 將限制可用的拓?fù)浜瓦B接,或者增加系統(tǒng)的成本和開銷。
實(shí)施集成的服務(wù)器、存儲(chǔ)和網(wǎng)絡(luò)系統(tǒng)為 OEM 提供了創(chuàng)新的機(jī)會(huì)。該創(chuàng)新的一個(gè)關(guān)鍵組成部分將是內(nèi)部系統(tǒng)連接。RapidIO 是一項(xiàng)成熟的、經(jīng)過充分驗(yàn)證的技術(shù),具有在該市場取得成功所需的屬性。與無線基礎(chǔ)設(shè)施的情況一樣,RapidIO 從早期創(chuàng)新發(fā)展成為事實(shí)上的基站互連標(biāo)準(zhǔn),RapidIO 在服務(wù)器、存儲(chǔ)和高性能計(jì)算方面的最大挑戰(zhàn)將是跨越當(dāng)今創(chuàng)新者和早期采用者市場的鴻溝大眾市場的擴(kuò)散。
審核編輯:郭婷
-
處理器
+關(guān)注
關(guān)注
68文章
19388瀏覽量
230565 -
soc
+關(guān)注
關(guān)注
38文章
4192瀏覽量
218659 -
服務(wù)器
+關(guān)注
關(guān)注
12文章
9265瀏覽量
85787
發(fā)布評論請先 登錄
相關(guān)推薦
恩智浦i.MX 94應(yīng)用處理器如何變革工業(yè)和汽車連接
EE-340: SHARC處理器和Blackfin處理器的SPI連接

EE-295:在SHARC處理器上實(shí)現(xiàn)延遲塊
EE-171:ADSP-BF535 Blackfin處理器多周期指令和延遲
EE-324:Blackfin處理器的系統(tǒng)優(yōu)化技術(shù)
盛顯科技:解決投影融合處理器連接超時(shí)問題的步驟

盛顯科技:拼接處理器連接大屏方法是什么?

盛顯科技:投影融合處理器連接出現(xiàn)超時(shí),該怎么辦?

針對TI汽車處理器新的SAFERTOS庫評估包

新加坡服務(wù)器延遲大嗎?如何進(jìn)行優(yōu)化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論