") 如何理解比較處理器
如何理解比較處理器
每個新處理器都聲稱是最快、最便宜或最省電的處理器,但這些聲明的衡量方式和支持信息可能非常有用,也可能無關(guān)緊要。
芯片行業(yè)在提供信息性指標(biāo)方面比過去更加努力。二十年前,衡量處理器性能相對容易。它是指令執(zhí)行速度、每條指令執(zhí)行多少有用工作以及信息可以從內(nèi)存讀取和寫入內(nèi)存的速度的組合。這與它消耗的電量和成本進行了權(quán)衡,這當(dāng)然不是那么重要。
當(dāng)Dennard Scaling下降時,許多市場的時鐘速度不再增加,MIPS 評級停滯不前。在架構(gòu)的其他地方、內(nèi)存連接以及通過添加更多處理器進行了改進。但是沒有創(chuàng)建新的性能指標(biāo)。
西門子 EDA高級副總裁兼總經(jīng)理 Ravi Subramanian 表示:“在過去二十年的大部分時間里,一直處于令人毛骨悚然的沉默之中。 ” “這種沉默是由英特爾和微軟創(chuàng)造的,它們控制著計算機架構(gòu)與其上運行的工作負(fù)載、應(yīng)用程序之間存在的契約。這推動了計算的很大一部分,尤其是企業(yè)。我們現(xiàn)在有一些非常具體的計算類型,它們更針對特定領(lǐng)域或利基市場,脫離了傳統(tǒng)的馮諾依曼架構(gòu)。每兆赫每毫瓦每秒的數(shù)百萬次操作已經(jīng)趨于平緩,為了獲得更高的計算效率,必須在工作負(fù)載所有者和計算機架構(gòu)師之間建立新的合同。”
在嘗試測量處理器的質(zhì)量時,考慮應(yīng)用程序變得很重要。該處理器執(zhí)行特定任務(wù)的性能如何,在什么條件下?
GPU 和 DSP 使該行業(yè)走上了特定領(lǐng)域計算的道路,但今天它正在邁向一個新的水平。“隨著經(jīng)典摩爾定律的放緩,創(chuàng)新已經(jīng)轉(zhuǎn)向特定領(lǐng)域的架構(gòu),” Synopsys Fusion Compiler 產(chǎn)品營銷經(jīng)理 James Chuang 說。“這些新架構(gòu)可以在相同的工藝技術(shù)上實現(xiàn)每瓦性能數(shù)數(shù)量級的提升。它們?yōu)樵O(shè)計探索開辟了廣闊的未知空間,無論是在架構(gòu)層面還是物理設(shè)計層面。”
已經(jīng)嘗試定義模仿上一個時代的新指標(biāo)。“人工智能應(yīng)用程序需要處理器具備某些特定功能,尤其是大量的乘法/累加運算,” AMD自適應(yīng)和嵌入式計算事業(yè)部的人工智能和軟件和解決方案產(chǎn)品營銷總監(jiān) Nick Ni 說。“處理器定義了它們可以執(zhí)行的每秒數(shù)萬億次操作 (TOPS),并且這些評級一直在迅速增加,(如圖 1 所示)。但就每瓦性能或每美元性能而言,真正的性能是什么?”
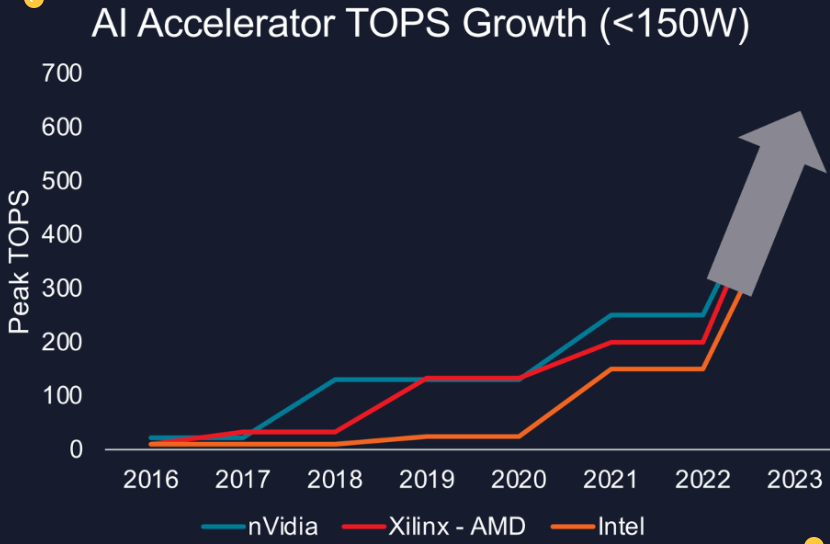
圖 1:AI TOPS 評級的增長。資料來源:AMD/賽靈思
隨著芯片尺寸達到分劃板限制,在芯片上包含額外的晶體管變得更加昂貴和困難,即使工藝規(guī)模擴大,因此性能提升只能來自架構(gòu)變化或新的封裝技術(shù)。
多個較小的處理器通常比單個較大的處理器好。將多個裸片放在一個封裝中還允許與內(nèi)存和其他計算內(nèi)核的連接也進行架構(gòu)改進。Synopsys 的產(chǎn)品營銷經(jīng)理 Priyank Shukla 說:“您可能將多個處理單元組合在一起以提供更好的性能。” “這個包含多個芯片的封裝將作為一個更大或更強大的計算基礎(chǔ)設(shè)施工作。該系統(tǒng)提供了一種業(yè)界習(xí)慣于看到的摩爾定律縮放比例。我們正在達到單個模具無法提高您的性能的極限。但現(xiàn)在這些系統(tǒng)可以在 18 個月內(nèi)為您提供 2 倍的性能提升,這正是我們所習(xí)慣的。”
工作負(fù)載正在推動計算機體系結(jié)構(gòu)的新要求。“這些超越了傳統(tǒng)的馮諾依曼架構(gòu),”西門子的 Subramanian 說。“許多新型工作負(fù)載需要分析,并且需要創(chuàng)建模型。人工智能和機器學(xué)習(xí)本質(zhì)上已成為推動模型開發(fā)的勞動力。我如何根據(jù)訓(xùn)練數(shù)據(jù)進行建模,以便我可以使用該模型進行預(yù)測?這是一種非常新型的工作負(fù)載。這正在推動一種關(guān)于計算機體系結(jié)構(gòu)的全新觀點。計算機架構(gòu)如何與這些工作負(fù)載相匹配?你可以實現(xiàn)一個神經(jīng)網(wǎng)絡(luò)或傳統(tǒng) x86 CPU 上的 DNN。但是,如果您查看每毫瓦、每兆赫茲的數(shù)百萬次操作,并考慮這些字長、權(quán)重和深度,通過與計算機體系結(jié)構(gòu)的工作量。”
工作負(fù)載和性能指標(biāo)因位置而異。“超大規(guī)模廠商提出了不同的指標(biāo)來衡量不同類型的計算能力,”Synopsys 的 Shukla 說。“最初他們會談?wù)撁棵?Petaflops,即他們可以執(zhí)行浮點運算的速率。但隨著工作負(fù)載變得越來越復(fù)雜,他們正在定義新的指??標(biāo)來同時評估硬件和軟件。這不僅僅是原始硬件。這是兩者的結(jié)合。我們看到他們專注于一個名為 PUE 的指標(biāo),即電源使用效率。他們一直在努力減少維護該數(shù)據(jù)中心所需的電力。”
丟失的是比較任何兩個處理器的方法,除非在最佳條件下運行特定應(yīng)用程序。即使這樣,也有問題。處理器和使用它的系統(tǒng)能否長期維持其性能?還是因為熱而節(jié)流?當(dāng)多個應(yīng)用程序同時在處理器上運行時,會導(dǎo)致不同的內(nèi)存訪問模式怎么辦?數(shù)據(jù)中心之外的處理器最重要的特性是它的性能,還是電池壽命和功耗,還是兩者之間的某種平衡?
瑞薩電子物聯(lián)網(wǎng)和基礎(chǔ)設(shè)施業(yè)務(wù)部執(zhí)行副總裁兼總經(jīng)理Sailesh Chittipeddi 表示:“如果你退后一步,從一個非常高的水平來看,它仍然是在最低功耗下實現(xiàn)最大計算能力。” “所以你可以考慮你需要什么樣的計算能力,以及它是否針對工作負(fù)載進行了優(yōu)化。但最終的因素是它仍然必須處于最低功耗。然后問題就變成了,‘你是把連接放在船上,還是把它放在外面。或者在優(yōu)化功耗方面你會怎么做。這是必須在系統(tǒng)層面解決的問題。”
測量是困難的。基準(zhǔn)測試結(jié)果不僅反映了硬件,還反映了相關(guān)的軟件和編譯器,它們比過去復(fù)雜得多。這意味著特定任務(wù)的性能可能會隨著時間而改變,而底層硬件沒有任何變化。
架構(gòu)方面的考慮并不僅僅停留在封裝的引腳上。“考慮在先進的智能手機上拍照,”舒克拉說。“在捕獲圖像的 CMOS 傳感器中執(zhí)行 AI 推理。其次,手機有四個核心用于額外的 AI 處理。第三級發(fā)生在數(shù)據(jù)中心邊緣。超大規(guī)模器在距數(shù)據(jù)捕獲的不同距離處推出了不同級別的推理。最后,您將擁有真正的大數(shù)據(jù)中心。AI 推理發(fā)生在四個級別,當(dāng)我們計算功率時,我們應(yīng)該計算所有這些。它從物聯(lián)網(wǎng)開始,你手中的手機,一直到最終的數(shù)據(jù)中心。”
由于有如此多的初創(chuàng)公司在創(chuàng)造新的處理器,許多公司的成功或失敗很可能是因為他們的軟件堆棧的質(zhì)量,而不是硬件本身。更難的是,硬件必須在知道它可能運行什么應(yīng)用程序之前設(shè)計好。在這些情況下,甚至沒有什么可以對處理器進行基準(zhǔn)測試。
基準(zhǔn)
基準(zhǔn)旨在提供一個公平的競爭環(huán)境,以便可以直接比較兩件事,但它們?nèi)匀豢梢员徊倏v。
當(dāng)特定應(yīng)用變得足夠重要時,市場需要基準(zhǔn),以便對其進行評級。“有不同類型的人工智能訓(xùn)練的基準(zhǔn),”舒克拉說。“ResNet 是圖像識別的基準(zhǔn),但這是一個性能基準(zhǔn),而不是功率基準(zhǔn)。Hyperscaler 將展示基于硬件和軟件的計算效率。有些甚至構(gòu)建了定制硬件、加速器,它可以比普通 GPU 或基于普通 FPGA 的實現(xiàn)更好地執(zhí)行任務(wù)。TensorFlow 就是與 Google TPU 結(jié)合的一個例子。他們以此為基礎(chǔ)對他們的人工智能性能進行了基準(zhǔn)測試,但到目前為止,功率并不是等式的一部分。主要是表演。”
忽視權(quán)力是一種操縱形式。“2012 年旗艦手機的峰值時鐘頻率為 1.4GHz,” Arm技術(shù)副總裁兼研究員 Peter Greenhalgh 說。“與今天達到 3GHz 的旗艦手機相比。對于臺式機 CPU,情況更加微妙。雖然 Turbo 頻率僅比 20 年前高一點,但 CPU 能夠在更高的頻率下停留更長時間。”
但并非所有基準(zhǔn)測試的規(guī)模或運行時復(fù)雜性都達到了這一點。“隨著電力消耗,溫度會升高,” Ansys PowerArtist 產(chǎn)品管理負(fù)責(zé)人 Preeti Gupta 說。 “一旦超過某個閾值,你就必須降低性能,(如圖 2 所示)。功率、熱量和性能非常緊密地聯(lián)系在一起。不考慮其電源效率的設(shè)計將不得不為運行速度變慢付出代價。在開發(fā)過程中,您必須采用真實的用例,運行數(shù)十億次循環(huán),并分析它們的熱效應(yīng)。查看熱圖后,您可能需要移動部分邏輯以分配熱量。至少,您需要將傳感器放置在不同的位置,以便知道何時降低性能。”
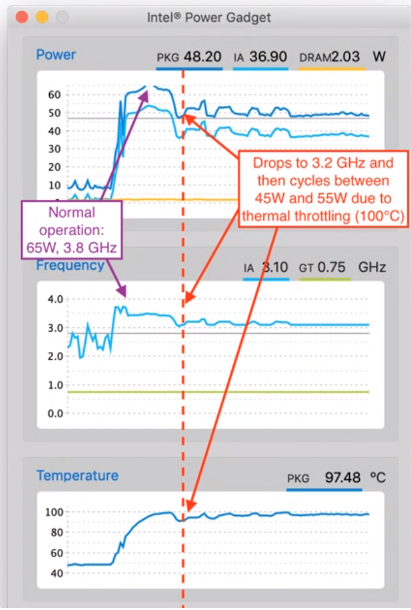
圖 2:性能限制會影響所有處理器。資料來源:Ansys
隨著時間的推移,架構(gòu)會針對特定的基準(zhǔn)進行優(yōu)化。“基準(zhǔn)不斷發(fā)展并反映現(xiàn)實世界的使用情況,使用系統(tǒng)軟件級別或硅測試階段的成熟方法相對容易創(chuàng)建和部署,”Synopsys 的 Chuang 說。“然而,分析總是在事后進行。芯片設(shè)計中更大的挑戰(zhàn)是如何針對這些基準(zhǔn)進行優(yōu)化。在芯片設(shè)計階段,常見的功率基準(zhǔn)通常僅由統(tǒng)計切換曲線 (SAIF) 或非常短的采樣窗口(實際活動 (FSDB) 的 1 到 2 納秒)表示。更大的趨勢不是“測量什么”,而是“在哪里測量”。我們看到客戶在整個流程中推動端到端功率分析,以準(zhǔn)確推動優(yōu)化,
基準(zhǔn)可以識別應(yīng)用程序與其運行的硬件架構(gòu)之間何時存在根本不匹配。“當(dāng)您在某些架構(gòu)上運行實際工作負(fù)載時,可能會出現(xiàn)主要的暗芯片,”AMD/Xilinx 的 Ni 說。“問題實際上在于數(shù)據(jù)移動。您正在使引擎挨餓,這會導(dǎo)致計算效率低下。”
即使這樣也不能說明全部。“越來越多的標(biāo)準(zhǔn)基準(zhǔn)得到了人們的認(rèn)可,”Ni 補充道。“這些是人們認(rèn)為最先進的模型。但是它們在運行您可能關(guān)心的模型方面的效率如何?什么是絕對性能,或者您的每瓦性能或每美元性能是多少?這決定了您的機柜的實際運營支出,尤其是在數(shù)據(jù)中心。最佳性能或功率效率以及成本效率通常是最關(guān)心的兩個問題。”
其他人同意。“從我們的角度來看,有兩個指標(biāo)越來越重要,” Fraunhofer IIS 自適應(yīng)系統(tǒng)部工程高級系統(tǒng)集成組負(fù)責(zé)人兼高效電子部門負(fù)責(zé)人 Andy Heinig 說。“其中一個是功耗或每瓦的操作。隨著能源成本的增加,我們預(yù)計這將變得越來越重要。第二個增長的指標(biāo)是芯片短缺。我們希望銷售設(shè)備數(shù)量最少但性能要求最高的產(chǎn)品。這意味著需要越來越多的靈活架構(gòu)。我們需要一個性能指標(biāo)來描述解決方案在針對不同應(yīng)用程序進行更改時的靈活性。”
芯片設(shè)計的一個關(guān)鍵挑戰(zhàn)是你不知道未來的工作負(fù)載會是什么。“如果您不了解未來的工作負(fù)載,您如何實際設(shè)計與這些應(yīng)用程序完美匹配的架構(gòu)?” 蘇布拉曼尼安問道。“這就是我們看到計算機架構(gòu)真正出現(xiàn)的地方,首先是了解工作負(fù)載、剖析和了解數(shù)據(jù)流、控制流和內(nèi)存訪問的最佳類型,這將顯著降低功耗并提高計算的能效。 這真的歸結(jié)為您花費了多少精力來進行有用的計算,以及您花費了多少精力來移動數(shù)據(jù)?對于應(yīng)用程序類型,總體概況是什么樣的?”
-
處理器
+關(guān)注
關(guān)注
68文章
19384瀏覽量
230511 -
dsp
+關(guān)注
關(guān)注
554文章
8058瀏覽量
349576 -
gpu
+關(guān)注
關(guān)注
28文章
4761瀏覽量
129143
發(fā)布評論請先 登錄
相關(guān)推薦
EE-340: SHARC處理器和Blackfin處理器的SPI連接

使用TMS320C6416協(xié)處理器:Turbo協(xié)處理器(TCP)
使用TMS320C6416協(xié)處理器:Viterbi協(xié)處理器(VCP)
對稱多處理器和非對稱多處理器的區(qū)別
比較電壓和處理器監(jiān)控解決方案:分立式電壓監(jiān)控器和看門狗ICs
ARM處理器的寄存器組織及功能
ARM處理器和CISC處理器的區(qū)別

什么是ARM處理器?與x86的比較及其優(yōu)缺點

處理器的定義和種類
主流嵌入式微處理器的結(jié)構(gòu)與原理是什么 常見的嵌入式微處理器類型包括

嵌入式微處理器的原理和應(yīng)用







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論