 Zero-shot-CoT是multi-task的方法
Zero-shot-CoT是multi-task的方法
1 簡介
Prompt learning中的prompt如同一種心理暗示,可以驅使語言模型按照特定的方向去預測。就像一種解題技巧,只要加入了它,就能更準確的解決問題。在之前prompt系列的文章中,我們介紹過各種形式的prompt,也強調過一個合適的prompt對于下游任務的效果影響重大,為此如何尋找一個合適的prompt的顯得尤為重要。
今天介紹一個最近剛被發現的“寶藏prompt”,Let’s think step by step,通過使用特定的prompt“Let’s think step by step”和相應的兩階段prompt技巧,提高了大規模語言模型在的推理能力,在多個推理相關的zero-shot任務取得驚人的提升,遠超之前的zero-shot方法。
2背景
大規模預訓練語言模型借助于針對特定任務設計的prompt(無論是few shot還是zero shot),在單步驟的system-1任務上有著出色表現,但是對于那些緩慢和需要多步推理的system-2任務表現不佳。(system-1跟system-2是心理學家定義的一些推理任務,可以理解為system-1是那些一步就可以推出答案的任務,,而system-2則是那些需要通過多步推理才能解決的任務)。
為了解決大規模語言模型在system-2任務中表現不佳的問題,CoT(Chain of thought prompting)被提出來,它將原本的few shot的樣例,調整為逐步推理的答案,從而讓語言模型去學習few shot樣例的逐步推理過程,從而控制模型推理能力的方向,在復雜的system-2任務中獲得明顯提升。細節可以見下圖中的樣例,其中左上角就是原本的few shot prompt,而右上角就是將few shot樣例調整為逐步推理樣例的CoT(為了跟后面的Zero-shot-CoT區分而稱為Few-shot- CoT),可以看出Few-shot-CoT是將few shot樣例里的推理過程展開了,讓語言模型能更好的學習其中的細節。

圖1:Few-shot, Few-shot-CoT, Zero-shot, Zero-shot-CoT示例
3 Zero-shot-CoT
跟前面提及的Few-shot Cot不同,Zero-shot-CoT不需要經過調整的逐步推理的few shot樣例,也不同大多數prompt,它不依賴于特定的任務,可以利用當前問題逐步的推理過程推導得到一個簡單的prompt模版,從而控制語言模型預測的方向。Zero-shot Cot的核心是利用“Let’s think step by step”去抽取當前問題的逐步推理過程。雖然Zero-shot-CoT的概念很簡單,它的巧妙之處在于整個過程使用了兩次prompt,具體過程如下,同時可以查看下圖樣例加深理解。
a)推論抽取
首先將問題X通過一個簡單的模版”Q:[X].A:[Z]”調整為一個prompt,其中[X]是一個輸入槽位,通過問題X來填充,而[Z]是一個觸發器槽位,用一個人工構建的觸發器句子來填充,使得語言模型可以從中抽取回答問題X所需的逐步推理過程,論文中用的觸發器句子是“Let’s think step by step.”。然后將構造好的模版輸入到語言模型,從而生成后續的句子Z(可以使用任何解碼策略,論文為了簡便使用了貪婪解碼策略)。
b)答案抽取
將第一步構造好的模版Q:[X].A:[Z],生成的句子Z,和一個新的觸發器句子[A]拼接到一起輸入到同一個語言模型,利用語言模型生成的結果進行解析得到最終的答案。這一步的觸發器句子[A]跟第一步的觸發器句子不同,它依賴于具體的答案形式,例如圖中樣例用的觸發器句子是“Therefore, the answer (arabic numerals) is”
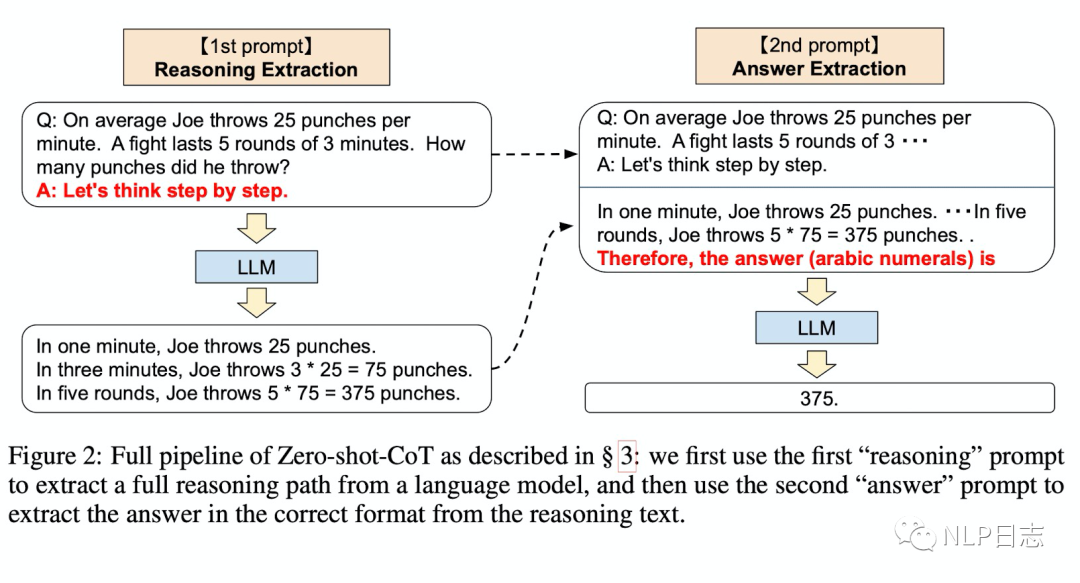
圖2: Zero-shot-Cot全過程
Zero-shot-CoT跟Few-shot-CoT的區別在于,對于每個任務,Few-shot-CoT需要謹慎的人工工程將few shot樣例轉化為特定的答案格式,就是其中的逐步推理過程,而Zero-shot-CoT則不需要這些工程,只需要調用兩次語言模型即可實現。Zero-shot-CoT跟Zero-shot的區別在于,Zero-shot-Cot多了生成多步推論的過程,最終輸入語言模型的文本會更加豐富,語言模型能按照逐步推論的方向進行預測,從而更好的控制語言模型的輸出。
4 實驗結果
論文在算術推理跟常識推理相關的任務做了實驗,有以下一些實驗結論。
a)Zero-shot-CoT在需要多步推理的算術推理任務,符號推理任務,其他邏輯推理任務上大幅超越zero-shot,在不需要多步推理的算數推理任務上(SingleEq和AddSub)上跟zero-shot水平相當。在常識推理任務上,Zero-shot-Cot表現沒有提升。
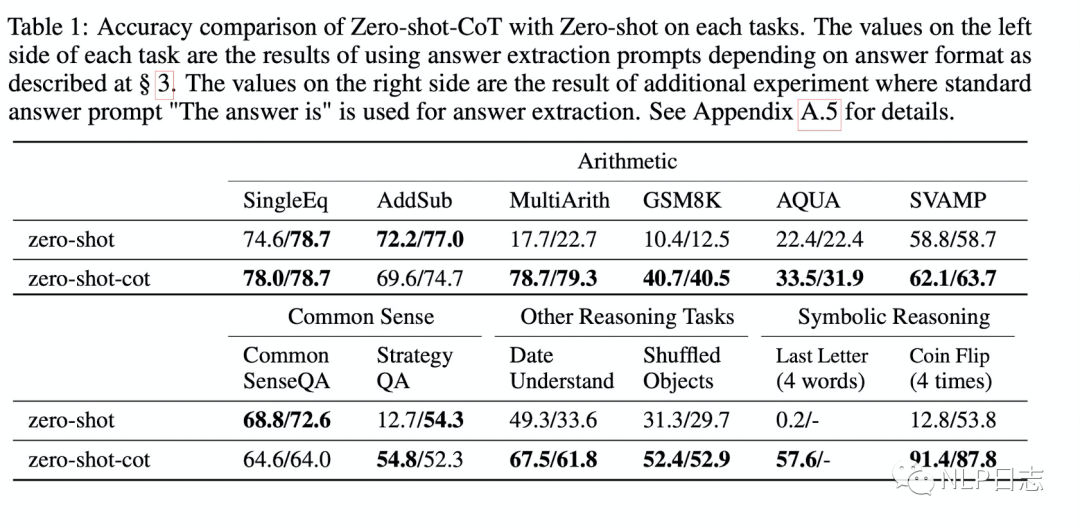
圖3: Zero-shot-CoT跟Zero-shot在多個任務上的表現
b)在算術推理任務中,雖然Zero-shot-CoT不及Few-shot-CoT,但明顯優于標準的Few-shot,即便是帶8個樣例的Fes-shot方法。
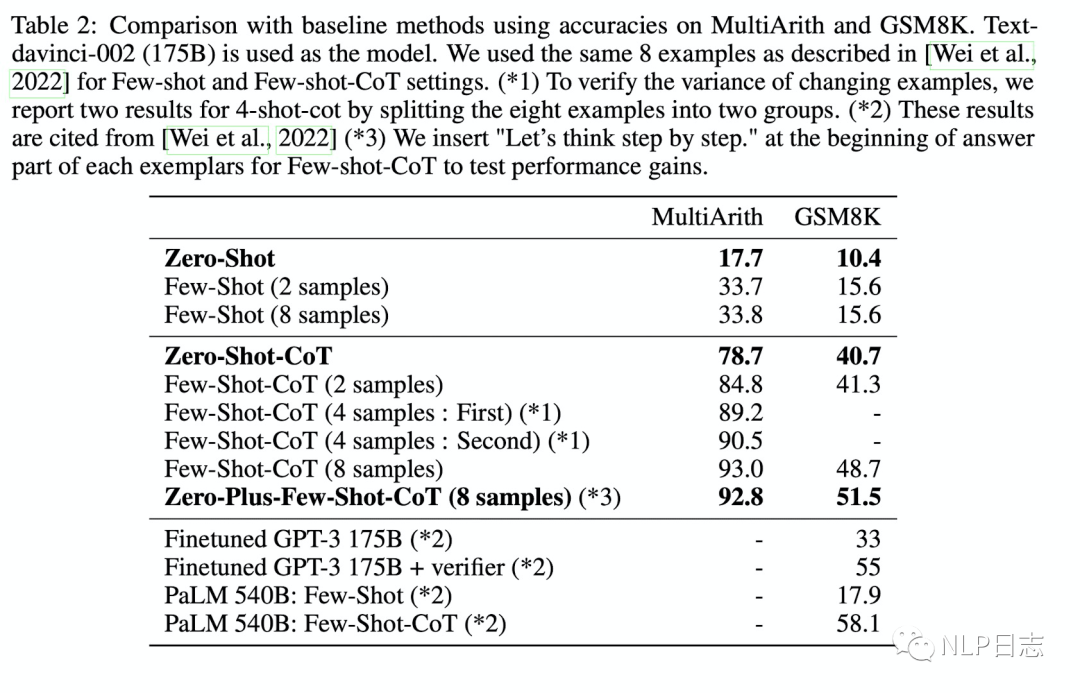
圖4: 在多步算法推理任務上多種方法的效果對比
c)對于常識推理問題,Zero-shot-CoT通常能生成靈活合理的推論,即便最終預測是錯誤的(下圖左邊樣例)。同時當模型發現很難將答案選項縮小時,Zero-shot-CoT經常輸出多個答案選項(下圖右邊樣例)。

圖5: Zero-shot-CoT在常識推理任務的若干bad case
5討論
a)語言模型規模跟zero-shot推理是否相關?
大規模語言模型能帶來更合理的推理。對于不需要多步推理的任務,zero-shot表現隨著語言模型規模的增長可能不增長或者增長非常緩慢,但是對于需要多步推理的任務,隨著語言模型規模的增長,zero-shot的效果飛速增長。
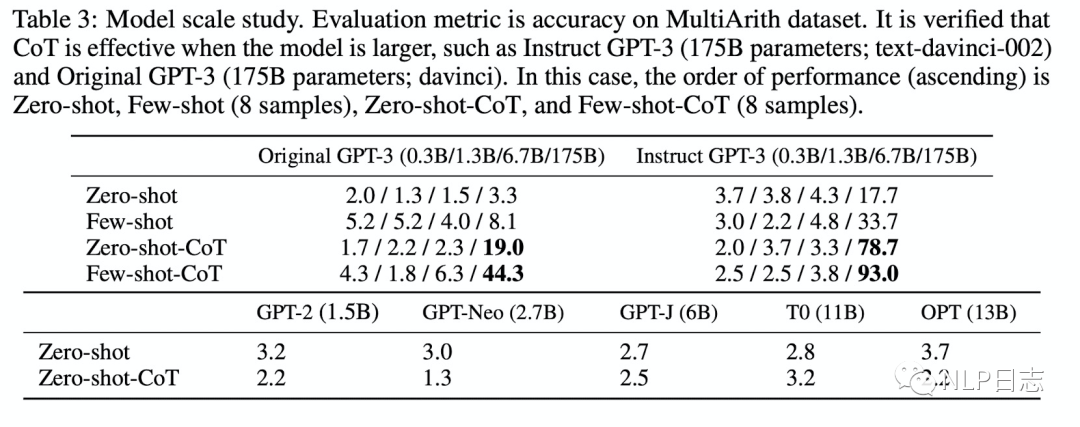
圖6:模型規模的影響
b)Prompt的選擇是否影響Zero-shot-CoT
如果文本被撰寫成有利于深度推理的樣子,模型效果也會得到提升。不同的prompt會驅使模型表示出迥然不同的推理能力,具體的差異取決了實際句子。在論文實驗中,其中一個prompt”Let’s think step by step”取得最優的效果。

圖7:不同prompt對于Zero-shot-CoT的影響
c)大規模語言模型的推理能力
部分研究表明預訓練模型通常不擅長推理任務,但是通過讓它進行逐步推理可以極大程度的提升它的推理性能,而不是通過微調。論文的實驗也佐證了大規模語言模型是一個合適的zero-shot推理器。
d)Multi-task prompting
大多數prompt都是針對特定任務而設計的,但是Zero-shot-CoT是支持多任務的,具有更強的泛化能力,能應用到更多不同的任務中去。Zero-shot-CoT可以為作為一種參考,不僅加速應用大規模語言模型進行邏輯推理的研究,也加速發現其他大規模語言模型的廣泛感知能力的研究。
6總結
個人覺得,相比其他prompt相關的文章,Zero-shot-CoT通過兩階段的prompt過程設計,擺脫了prompt工程的限制,也不受限于具體的任務,更好的控制模型的預測方向。雖然思想跟Few-shot-CoT很像,但是擺脫了其中的精心設計的將few shot樣例轉化為合適的prompt的過程。這一點還是很有價值的。
但是,看完這個文章還是有不少的疑問。文章提及Zero-shot-CoT是multi-task的方法,但是只在推理相關的任務上進行實驗,Let’s think step by step”在非推理的任務上也會是最優選擇嗎?在其他任務上,Zero-shot-CoT能取得多少增益?對于其他語言而言,找到自身最佳的“Let’s think step by step”只能把所有可能的prompt都測試一遍嗎?有其他自動化的手段嗎?有沒有跨語言的“Let’s think step by step”?
參考文獻
1.(2022,) Large Language Models are Zero-Shot Reasoners
https://arxiv.org/pdf/2205.11916.pdf
審核編輯 :李倩
-
自動化
+關注
關注
29文章
5579瀏覽量
79283 -
語言模型
+關注
關注
0文章
524瀏覽量
10277
原文標題:提示學習 | Let’s think step by step
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
?Banana Pi BPi-M4 Zero 開源硬件開發板評測試: 全志科技H618 方案設計

Multi-Scaler IP的Linux示例以及Debug(上)
應用COT與Flybuck技術的低成本小功率輔助電源解決方案

AN-1481在恒定導通時間(COT)調節器設計中控制輸出紋波并實現ESR獨立性
esp8266EX報\"event_task\"(stack_size = 0,task handle = 40108368) overflow the heap_size.是不是內存不夠用?
OpenAI收購遠程協作公司Multi
TE推出的MULTI-BEAM Plus電源連接器具有哪些優勢?-赫聯電子
esp32同時讓wifi和藍牙工作,會出現wifi task看門狗復位的情況怎么解決?
兼容TPS54628DDAR 18V 6A COT同步降壓轉換器





 工商網監
工商網監
評論