") 使用NVIDIA QAT工具包實(shí)現(xiàn)TensorRT量化網(wǎng)絡(luò)的設(shè)計(jì)
使用NVIDIA QAT工具包實(shí)現(xiàn)TensorRT量化網(wǎng)絡(luò)的設(shè)計(jì)
出身背景
加速深層神經(jīng)網(wǎng)絡(luò)( DNN )推理是實(shí)現(xiàn)實(shí)時(shí)應(yīng)用(如圖像分類(lèi)、圖像分割、自然語(yǔ)言處理等)延遲關(guān)鍵部署的重要步驟。
改進(jìn) DNN 推理延遲的需要引發(fā)了人們對(duì)以較低精度運(yùn)行這些模型的興趣,如 FP16 和 INT8 。在 INT8 精度下運(yùn)行 DNN 可以提供比其浮點(diǎn)對(duì)應(yīng)項(xiàng)更快的推理速度和更低的內(nèi)存占用。 NVIDIA TensorRT 支持訓(xùn)練后量化( PTQ )和 QAT 技術(shù),將浮點(diǎn) DNN 模型轉(zhuǎn)換為 INT8 精度。
在這篇文章中,我們討論了這些技術(shù),介紹了用于 TensorFlow 的 NVIDIA QAT 工具包,并演示了一個(gè)端到端工作流,以設(shè)計(jì)最適合 TensorRT 部署的量化網(wǎng)絡(luò)。
量化感知訓(xùn)練
QAT 背后的主要思想是通過(guò)最小化訓(xùn)練期間的量化誤差來(lái)模擬低精度行為。為此,可以通過(guò)在所需層周?chē)砑恿炕腿チ炕?QDQ )節(jié)點(diǎn)來(lái)修改 DNN 圖。這使得量化網(wǎng)絡(luò)能夠?qū)⒂捎谀P土炕统瑓?shù)的微調(diào)而導(dǎo)致的 PTQ 精度損失降至最低。
另一方面, PTQ 在模型已經(jīng)訓(xùn)練之后,使用校準(zhǔn)數(shù)據(jù)集執(zhí)行模型量化。由于量化沒(méi)有反映在訓(xùn)練過(guò)程中,這可能導(dǎo)致精度下降。圖 1 顯示了這兩個(gè)過(guò)程。
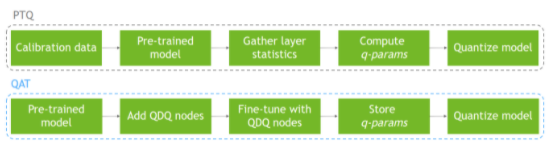
圖 1 通過(guò) PTQ 和 QAT 的量化工作流
用于 TensorFlow 的 NVIDIA QAT 工具包
該工具包的目標(biāo)是使您能夠以最適合于 TensorRT 部署的方式輕松量化網(wǎng)絡(luò)。
目前, TensorFlow 在其開(kāi)源軟件 模型優(yōu)化工具包 中提供非對(duì)稱(chēng)量化。他們的量化方法包括在所需層的輸出和權(quán)重(如果適用)處插入 QDQ 節(jié)點(diǎn),并提供完整模型或部分層類(lèi)類(lèi)型的量化。這是為 TFLite 部署而優(yōu)化的,而不是 TensorRT 部署。
需要此工具包來(lái)獲得一個(gè)量化模型,該模型非常適合 TensorRT 部署。 TensorRT optimizer 傳播 Q 和 DQ 節(jié)點(diǎn),并通過(guò)網(wǎng)絡(luò)上的浮點(diǎn)操作將它們?nèi)诤显谝黄穑宰畲蠡?INT8 中可以處理的圖形比例。這將導(dǎo)致 NVIDIA GPU 上的最佳模型加速。我們的量化方法包括在所需層的輸入和權(quán)重(如果適用)處插入 QDQ 節(jié)點(diǎn)。
我們還執(zhí)行對(duì)稱(chēng)量化( TensorRT 使用),并通過(guò)層名稱(chēng)和 基于模式的層量化 的部分量化提供擴(kuò)展量化支持。
表 1 總結(jié)了 TFMOT 和用于 TensorFlow 的 NVIDIA QAT 工具包之間的差異。

圖2顯示了一個(gè)簡(jiǎn)單模型的前/后示例,用 Netron 可視化。QDQ節(jié)點(diǎn)放置在所需層的輸入和權(quán)重(如適用)中,即卷積(Conv)和完全連接(MatMul)。
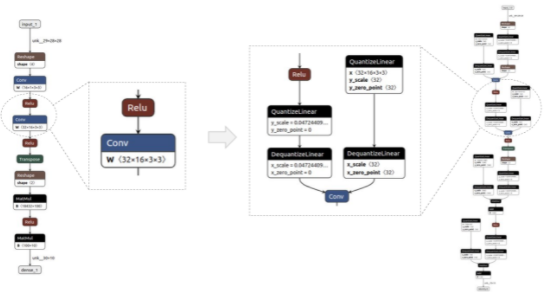
圖 2 量化前后的模型示例(分別為基線和 QAT 模型)
TensorRT 中部署 QAT 模型的工作流
圖 3 顯示了在 TensorRT 中部署 QAT 模型的完整工作流,該模型是通過(guò) QAT 工具包獲得的。

圖 3 TensorRT 使用 QAT 工具包獲得的 QAT 模型的部署工作流
假設(shè)預(yù)訓(xùn)練的 TensorFlow 2 模型為 SavedModel 格式,也稱(chēng)為基線模型。
使用quantize_model功能對(duì)該模型進(jìn)行量化,該功能使用 QDQ 節(jié)點(diǎn)克隆并包裝每個(gè)所需的層。
微調(diào)獲得的量化模型,在訓(xùn)練期間模擬量化,并將其保存為SavedModel格式。
將其轉(zhuǎn)換為 ONNX 。
然后, TensorRT 使用 ONNX 圖來(lái)執(zhí)行層融合和其他圖優(yōu)化,如 專(zhuān)用 QDQ 優(yōu)化 ,并生成一個(gè)用于更快推理的引擎。
ResNet-50v1 示例
在本例中,我們將向您展示如何使用 TensorFlow 2 工具包量化和微調(diào) QAT 模型,以及如何在 TensorRT 中部署該量化模型。有關(guān)更多信息,請(qǐng)參閱完整的 example_resnet50v1.ipynb Jupyter 筆記本。
要求
要跟進(jìn),您需要以下資源:
Python 3.8
TensorFlow 2.8
NVIDIA TF-QAT 工具包
TensorRT 8.4
準(zhǔn)備數(shù)據(jù)
對(duì)于本例,使用 ImageNet 2012 數(shù)據(jù)集 進(jìn)行圖像分類(lèi)(任務(wù) 1 ),由于訪問(wèn)協(xié)議的條款,需要手動(dòng)下載。 QAT 模型微調(diào)需要此數(shù)據(jù)集,它還用于評(píng)估基線和 QAT 模型。
登錄或注冊(cè)鏈接網(wǎng)站,下載列車(chē)/驗(yàn)證數(shù)據(jù)。您應(yīng)該至少有 155 GB 的可用空間。
工作流支持 TFRecord 格式,因此請(qǐng)使用以下說(shuō)明(從 TensorFlow 說(shuō)明 ) 轉(zhuǎn)換下載的。將 ImageNet 文件轉(zhuǎn)換為所需格式:
set IMAGENET_HOME=/path/to/imagenet/tar/files in data/imagenet_data_setup.sh 。
將 imagenet_to_gcs.py 下載到$IMAGENET_HOME。
Run 。/data/imagenet_data_setup.sh.
您現(xiàn)在應(yīng)該可以在$IMAGENET_HOME中看到兼容的數(shù)據(jù)集。
量化和微調(diào)模型
from tensorflow_quantization import quantize_model from tensorflow_quantization.custom_qdq_cases import ResNetV1QDQCase # Create baseline model model = tf.keras.applications.ResNet50(weights="imagenet", classifier_activation="softmax") # Quantize model q_model = quantize_model(model, custom_qdq_cases=[ResNetV1QDQCase()]) # Fine-tune q_model.compile( optimizer="sgd", loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=["accuracy"] ) q_model.fit( train_batches, validation_data=val_batches, batch_size=64, steps_per_epoch=500, epochs=2 ) # Save as TF 2 SavedModel q_model.save(“saved_model_qat”)
將 SavedModel 轉(zhuǎn)換為 ONNX
$ python -m tf2onnx.convert --saved-model=--output= --opset 13
部署 TensorRT 發(fā)動(dòng)機(jī)
將 ONNX 模型轉(zhuǎn)換為 TensorRT 引擎(還可以獲得延遲測(cè)量):
$ trtexec --onnx=--int8 --saveEngine= -v
獲取驗(yàn)證數(shù)據(jù)集的準(zhǔn)確性結(jié)果:
$ python infer_engine.py --engine=--data_dir= -b=
后果
在本節(jié)中,我們報(bào)告了 ResNet 和 EfficientNet 系列中各種型號(hào)的準(zhǔn)確性和延遲性能數(shù)字:
ResNet-50v1
ResNet-50v2
ResNet-101v1
ResNet-101v2
效率網(wǎng) -B0
效率網(wǎng) -B3
所有結(jié)果都是在 NVIDIA A100 GPU 上獲得的,批次大小為 1 ,使用 TensorRT 8.4 ( EA 用于 ResNet , GA 用于 EfficientNet )。
圖 4 顯示了基線 FP32 模型與其量化等效模型( PTQ 和 QAT )之間的精度比較。正如您所見(jiàn),基線模型和 QAT 模型之間的準(zhǔn)確性幾乎沒(méi)有損失。有時(shí),由于模型的進(jìn)一步整體微調(diào),精度甚至更高。由于 QAT 中模型參數(shù)的微調(diào), QAT 的精度總體上高于 PTQ 。
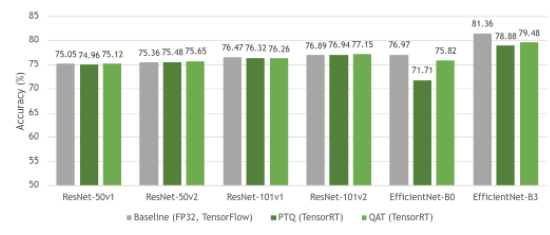
圖 4 FP32 (基線)、帶 PTQ 的 INT8 和帶 QAT 的 INT8 中 ResNet 和 EfficientNet 數(shù)據(jù)集的準(zhǔn)確性
ResNet 作為一種網(wǎng)絡(luò)結(jié)構(gòu),一般量化穩(wěn)定,因此 PTQ 和 QAT 之間的差距很小。然而, EfficientNet 從 QAT 中獲益匪淺,與 PTQ 相比,基線模型的準(zhǔn)確度損失有所減少。
有關(guān)不同模型如何從 QAT 中受益的更多信息,請(qǐng)參見(jiàn) 深度學(xué)習(xí)推理的整數(shù)量化:原理與實(shí)證評(píng)價(jià) (量化白皮書(shū))中的表 7 。
圖 5 顯示了 PTQ 和 QAT 具有相似的時(shí)間,與各自的基線模型相比,它們引入了高達(dá) 19 倍的加速。

圖 5 ResNet 和 EfficientNet 系列中各種模型的延遲性能評(píng)估
PTQ 有時(shí)可能比 QAT 略快,因?yàn)樗噲D量化模型中的所有層,這通常會(huì)導(dǎo)致更快的推斷,而 QAT 僅量化用 QDQ 節(jié)點(diǎn)包裹的層。
有關(guān) TensorRT 如何使用 QDQ 節(jié)點(diǎn)的更多信息,請(qǐng)參閱 TensorRT 文檔中的 使用 INT8 和 走向 INT8 推理:使用 TensorRT 部署量化感知訓(xùn)練網(wǎng)絡(luò)的端到端工作流 GTC 會(huì)話。
有關(guān)各種受支持型號(hào)的性能數(shù)字的更多信息,請(qǐng)參閱 model zoo 。
結(jié)論
在本文中,我們介紹了 TensorFlow 2 的 NVIDIA QAT 工具包 。 我們討論了在 TensorRT 推理加速環(huán)境中使用該工具包的優(yōu)勢(shì)。然后,我們演示了如何將該工具包與 ResNet50 結(jié)合使用,并對(duì) ResNet 和 EfficientNet 數(shù)據(jù)集執(zhí)行準(zhǔn)確性和延遲評(píng)估。
實(shí)驗(yàn)結(jié)果表明,與 FP32 模型相比,用 QAT 訓(xùn)練的 INT8 模型的精度相差約 1% ,實(shí)現(xiàn)了 19 倍的延遲加速。
關(guān)于作者
Gwena Cunha Sergio 在 NVIDIA 擔(dān)任深度學(xué)習(xí)軟件工程師。在此之前,她是韓國(guó)京浦國(guó)立大學(xué)的一名博士生,致力于研究基于深度學(xué)習(xí)的方法,用于嘈雜的自然語(yǔ)言處理任務(wù)和從多模態(tài)數(shù)據(jù)生成序列。
Sagar Shelke 是 NVIDIA 的深度學(xué)習(xí)軟件工程師,專(zhuān)注于自主駕駛應(yīng)用程序。他的興趣包括用于部署和機(jī)器學(xué)習(xí)系統(tǒng)的神經(jīng)網(wǎng)絡(luò)優(yōu)化。薩加爾擁有圣地亞哥州立大學(xué)電氣和計(jì)算機(jī)工程碩士學(xué)位。
Dheeraj Peri 在 NVIDIA 擔(dān)任深度學(xué)習(xí)軟件工程師。在此之前,他是紐約羅切斯特理工學(xué)院的研究生,致力于基于深度學(xué)習(xí)的內(nèi)容檢索和手寫(xiě)識(shí)別方法。 Dheeraj 的研究興趣包括信息檢索、圖像生成和對(duì)抗性機(jī)器學(xué)習(xí)。他獲得了印度皮拉尼 Birla 理工學(xué)院的學(xué)士學(xué)位。
Josh Park 是 NVIDIA 的汽車(chē)解決方案架構(gòu)師經(jīng)理。到目前為止,他一直在研究使用 DL 框架的深度學(xué)習(xí)解決方案,例如在 multi-GPUs /多節(jié)點(diǎn)服務(wù)器和嵌入式系統(tǒng)上的 TensorFlow 。此外,他一直在評(píng)估和改進(jìn)各種 GPUs + x86 _ 64 / aarch64 的訓(xùn)練和推理性能。他在韓國(guó)大學(xué)獲得理學(xué)學(xué)士和碩士學(xué)位,并在德克薩斯農(nóng)工大學(xué)獲得計(jì)算機(jī)科學(xué)博士學(xué)位
審核編輯:郭婷
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100903 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5025瀏覽量
103266
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Labview聲音和振動(dòng)工具包示例文件Sound Level
最新Simplicity SDK軟件開(kāi)發(fā)工具包發(fā)布
解鎖NVIDIA TensorRT-LLM的卓越性能
NVIDIA TensorRT-LLM Roadmap現(xiàn)已在GitHub上公開(kāi)發(fā)布

基于EasyGo Vs工具包和Nl veristand軟件進(jìn)行的永磁同步電機(jī)實(shí)時(shí)仿真
TensorRT-LLM低精度推理優(yōu)化

FPGA仿真工具包軟件EasyGo Vs Addon介紹

采用德州儀器 (TI) 工具包進(jìn)行模擬前端設(shè)計(jì)應(yīng)用說(shuō)明

使用freeRTOS開(kāi)發(fā)工具包時(shí),在哪里可以找到freeRTOS的版本?
MediaTek與NVIDIA TAO加速物聯(lián)網(wǎng)邊緣AI應(yīng)用發(fā)展
存內(nèi)計(jì)算技術(shù)工具鏈——量化篇
Edge Impulse發(fā)布新工具,助 NVIDIA 模型大規(guī)模部署
QE for Motor V1.3.0:汽車(chē)開(kāi)發(fā)輔助工具解決方案工具包
求助,請(qǐng)問(wèn)有沒(méi)有l(wèi)abview opc ua工具包 2018 啊
利用ProfiShark 構(gòu)建便攜式網(wǎng)絡(luò)取證工具包






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論