 TiFlash整體模塊分層及DeltaTree 引擎優化方案
TiFlash整體模塊分層及DeltaTree 引擎優化方案
作者:黃俊深,PingCAP TiFlash 資深研發工程師
TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形態的關鍵組件。TiFlash 源碼閱讀系列文章將從源碼層面介紹 TiFlash 的內部實現。本文為系列文章的第一篇,將對 TiDB HTAP 的整體形態進行介紹,并詳細解析存儲層 DeltaTree 引擎進行優化的設計思路以及其子模塊。
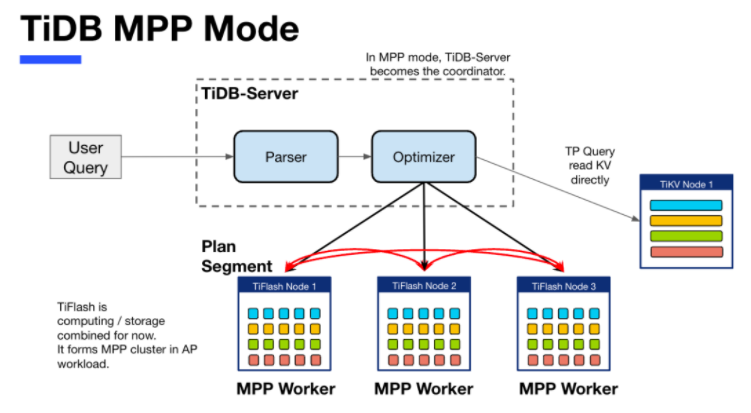
今天的主角 -- TiFlash 是 TiDB HTAP 形態的關鍵組件,它是 TiKV 的列存擴展,通過 Raft Learner 協議異步復制,但提供與 TiKV 一樣的快照隔離支持。我們用這個架構解決了 HTAP 場景的隔離性以及列存同步的問題。自 5.0 引入 MPP 后,也進一步增強了 TiDB 在實時分析場景下的計算加速能力。

上圖描述了 TiFlash 整體邏輯模塊的劃分,通過 Raft Learner Proxy 接入到 TiDB 的 multi-raft 體系中。我們可以對照著 TiKV 來看:計算層的 MPP 能夠在 TiFlash 之間做數據交換,擁有更強的分析計算能力;作為列存引擎,我們有一個 schema 的模塊負責與 TiDB 的表結構進行同步,將 TiKV 同步過來的數據轉換為列的形式,并寫入到列存引擎中;最下面的一塊,是稍后會介紹的列存引擎,我們將它命名為 DeltaTree 引擎。
有持續關注 TiDB 的用戶可能之前閱讀過 《TiDB 的列式存儲引擎是如何實現的?》 這篇文章,近期隨著 TiFlash 開源 ,也有新的用戶想更多地了解 TiFlash 的內部實現。這篇文章會從更接近代碼層面,來介紹 TiFlash 內部實現的一些細節。
這里是 TiFlash 內一些重要的模塊劃分以及它們對應在代碼中的位置。在今天的分享和后續的系列里,會逐漸對里面的模塊開展介紹。
# TiFlash 模塊對應的代碼位置
dbms/
└── src
├── AggregateFunctions, Functions, DataStreams # 函數、算子
├── DataTypes, Columns, Core # 類型、列、Block
├── IO, Common, Encryption # IO、輔助類
├── Debug # TiFlash Debug 輔助函數
├── Flash # Coprocessor、MPP 邏輯
├── Server # 程序啟動入口
├── Storages
│ ├── IStorage.h # Storage 抽象
│ ├── StorageDeltaMerge.h # DeltaTree 入口
│ ├── DeltaMerge # DeltaTree 內部各個組件
│ ├── Page # PageStorage
│ └── Transaction # Raft 接入、Scehma 同步等。 待重構 https://github.com/pingcap/tiflash/issues/4646
└── TestUtils # Unittest 輔助類
TiFlash 中的一些基本元素抽象
TiFlash 這款引擎的代碼是 18 年從 ClickHouse fork。ClickHouse 為 TiFlash 提供了一套性能十分強勁的向量化執行引擎,我們將其當做 TiFlash 的單機的計算引擎使用。在此基礎上,我們增加了針對 TiDB 前端的對接,MySQL 兼容,Raft 協議和集群模式,實時更新列存引擎,MPP 架構等等。雖然和原本的 Clickhouse 已經完全不是一回事,但代碼自然地 TiFlash 代碼繼承自 ClickHouse,也沿用著 CH 的一些抽象。比如:
IColumn 代表內存里面以列方式組織的數據。IDataType 是數據類型的抽象。Block 則是由多個 IColumn 組成的數據塊,它是執行過程中,數據處理的基本單位。
在執行過程中,Block 會被組織為流的形式,以 BlockInputStream 的方式,從存儲層 “流入” 計算層。而 BlockOutputStream,則一般從執行引擎往存儲層或其他節點 “寫出” 數據。
IStorage 則是對存儲層的抽象,定義了數據寫入、讀取、DDL 操作、表鎖等基本操作。

DeltaTree 引擎
雖然 TiFlash 基本沿用了 CH 的向量化計算引擎,但是存儲層最終沒有沿用 CH 的 MergeTree 引擎,而是重新研發了一套更適合 HTAP 場景的列存引擎,我們稱為 DeltaTree,對應代碼中的 " StorageDeltaMerge "。
DeltaTree 引擎解決的是什么問題
A. 原生支持高頻率數據寫入,適合對接 TP 系統,更好地支持 HTAP 場景下的分析工作。
B. 支持列存實時更新的前提下更好的讀性能。它的設計目標是優先考慮 Scan 讀性能,相對于 CH 原生的 MergeTree 可能部分犧牲寫性能
C. 符合 TiDB 的事務模型,支持 MVCC 過濾
D. 數據被分片管理,可以更方便的提供一些列存特性,從而更好的支持分析場景,比如支持 rough set index
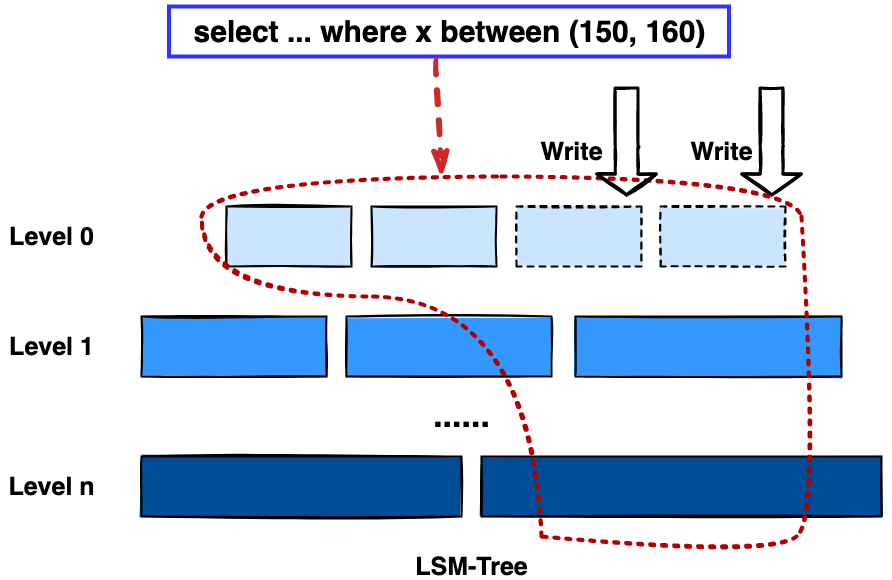
為什么我們說 DeltaTree 引擎具備上面特性呢
回答這個疑問之前,我們先回顧下 CH 原生的 MergeTree 引擎存在什么問題。MergeTree 引擎可以理解為經典的 LSM Tree(Log Structured Merge Tree)的一種列存實現,它的每個 "part 文件夾" 對應 SSTFile(Sorted Strings Table File)。最開始,MergeTree 引擎是沒有 WAL 的,每次寫入,即使只有 1 條數據,也會將數據需要生成一個 part。因此如果使用 MergeTree 引擎承接高頻寫入的數據,磁盤上會形成大量碎片的文件。這個時候,MergeTree 引擎的寫入性能和讀取性能都會出現嚴重的波動。這個問題直到 2020 年,CH 給 MergeTree 引擎引入了 WAL,才部分緩解這個壓力 ClickHouse/8290 。
那么是不是有了 WAL,MergeTree 引擎就可以很好地承載 TiDB 的數據了呢?還不足夠。因為 TiDB 是一個通過 MVCC 實現了 Snapshot Isolation 級別事務的關系型數據庫。這就決定了 TiFlash 承載的負載會有比較多的數據更新操作,而承載的讀請求,都會需要通過 MVCC 版本過濾,篩選出需要讀的數據。而以 LSM Tree 形式組織數據的話,在處理 Scan 操作的時候,會需要從 L0 的所有文件,以及其他層中 與查詢的 key-range 有 overlap 的所有文件,以堆排序的形式合并、過濾數據。在合并數據的這個入堆、出堆的過程中, CPU 的分支經常會 miss,cache 命中也會很低。測試結果表明,在處理 Scan 請求的時候,大量的 CPU 都消耗在這個堆排序的過程中。
另外,采用 LSM Tree 結構,對于過期數據的清理,通常在 level compaction 的過程中,才能被清理掉(即 Lk-1 層與 Lk 層 overlap 的文件進行 compaction)。而 level compaction 的過程造成的寫放大會比較嚴重。當后臺 compaction 流量比較大的時候,會影響到前臺的寫入和數據讀取的性能,造成性能不穩定。
MergeTree 引擎上面的三點:寫入碎片、Scan 時 CPU cache miss 嚴重、以及清理過期數據時的 compaction ,造成基于 MergeTree 引擎構建的帶事務的存儲引擎,在有數據更新的 HTAP 場景下,讀、寫性能都會有較大的波動。
DeltaTree 的解決思路以及模塊劃分
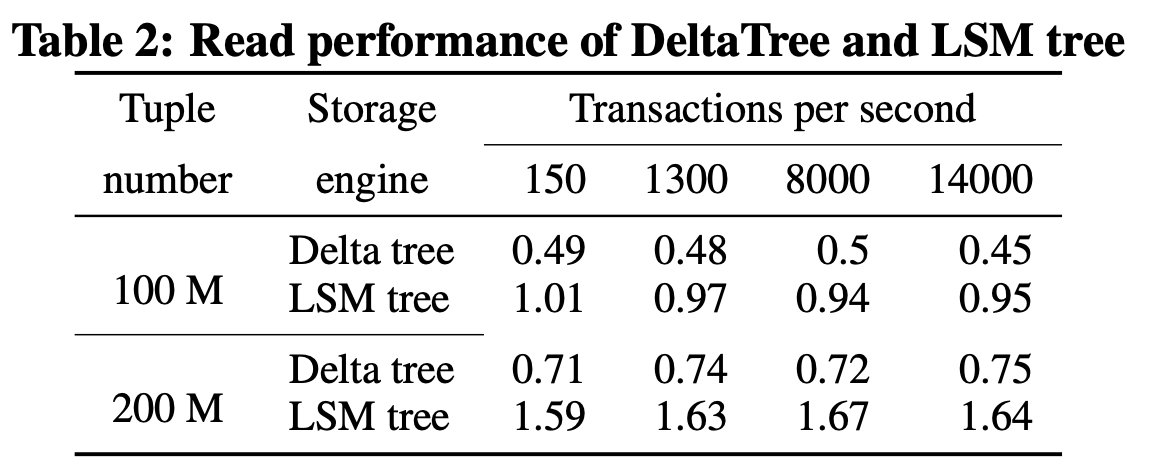
在看實現之前,我們來看看 DeltaTree 的療效如何。上圖是 Delta Tree 與基于 MergeTree 實現的帶事務支持的列存引擎在不同數據量(Tuple number)以及不同更新 TPS (Transactions per second) 下的讀 (Scan) 耗時對比。可以看到 DeltaTree 在這個場景下的讀性能基本能達到后者的兩倍。
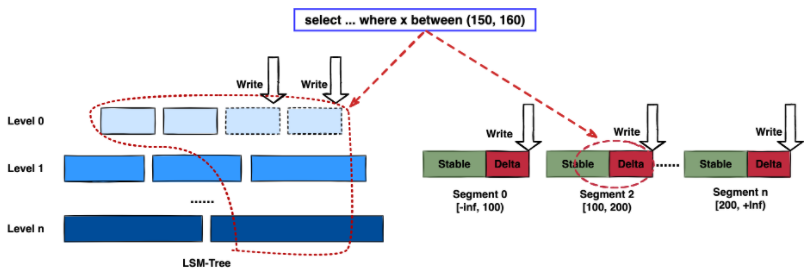
那么 DeltaTree 具體面對上述問題,是如何設計的呢?
首先,我們在表內,把數據按照 handle 列的 key-range,橫向分割進行數據管理,每個分片稱為 Segment。這樣在 compaction 的時候,不同 Segment 間的數據就獨立地進行數據整理,能夠減少寫放大。這方面與 PebblesDB[1] 的思路有點類似。
另外,在每個 Segment 中,我們采用了 delta-stable 的形式,即最新的修改數據寫入的時候,被組織在一個寫優化的結構的末尾( DeltaValueSpace.h ),定期被合并到一個為讀優化的結構中( StableValueSpace.h )。Stable Layer 存放相對老的,數據量較大的數據,它不能被修改,只能被 replace。當 Delta Layer 寫滿之后,與 Stable Layer 做一次 Merge(這個動作稱為 Delta Merge),從而得到新的 Stable Layer,并優化讀性能。很多支持更新的列存,都是采用類似 delta-stable 這種形式來組織數據,比如 Apache Kudu[2]。有興趣的讀者還可以看看《Fast scans on key-value stores》[3] 的論文,其中對于如何組織數據,MVCC 數據的組織、對過期數據 GC 等方面的優劣取舍都做了分析,最終作者也是選擇了 delta-main 加列存這樣的形式。
Delta Layer 的數據,我們通過一個 PageStorage 的結構來存儲數據,Stable Layer 我們主要通過 DTFile 來存儲數據、通過 PageStorage 來管理生命周期。另外還有 Segment、DeltaValueSpace、StableValueSpace 的元信息,我們也是通過 PageStorage 來存儲。上面三者分別對應 DeltaTree 中 StoragePool 這一數據結構的 log, data 以及 meta。
PageStorage 模塊

上面提到, Delta Layer 的數據和 DeltaTree 存儲引擎的一些元數據,這類較小的數據塊,在序列化為字節串之后,作為 "Page" 寫入到 PageStorage 來進行存儲。PageStorage 是 TiFlash 中的一個存儲的抽象組件,類似對象存儲。它主要設計面向的場景是 Delta Layer 的高頻讀取:比如在 snapshot 上,以 PageID (或多個 PageID) 做點查的場景;以及相對于 Stable Layer 較高頻的寫入。PageStorage 層的 "Page" 數據塊典型大小為數 KiB~MiB。
PageStorage 是一個比較復雜的組件,今天先不介紹它內部的構造。讀者可以先理解 PageStorage 至少提供以下 3 點功能:
提供 WriteBatch 接口,保證寫入 WriteBatch 的原子性
提供 Snapshot 功能,可以獲取一個不阻塞寫的只讀 view
提供讀取 Page 內部分數據的能力(只讀選擇的列數據)
讀索引 DeltaTree Index

前面提到,在 LSM-Tree 上做多路歸并比較耗 CPU,那我們是否可以避免每次讀都要重新做一次呢?答案是可以的。事實上有一些內存數據庫已經實踐了類似的思路。具體的思路是,第一次 Scan 完成后,我們把多路歸并算法產生的信息想辦法存下來,從而使下一次 Scan 可以重復利用。這份可以被重復利用的信息我們稱為 Delta Index,它由一棵 B+ Tree 實現。利用 Delta Index,把 Delta Layer 和 Stable Layer 合并到一起,輸出一個排好序的 Stream。Delta Index 幫助我們把 CPU bound、而且存在很多 cache miss 的 merge 操作,轉化為大部分情況下一些連續內存塊的 copy 操作,進而優化 Scan 的性能。
Rough Set Index
很多數據庫都會在數據塊上加統計信息,以便查詢時可以過濾數據塊,減少不必要的 IO 操作。有的將這個輔助的結構稱為 KnowledgeNode、有的叫 ZoneMaps。TiFlash 參考了 InfoBright [4] 的開源實現,采用了 Rough Set Index 這個名字,中文叫粗粒度索引。
TiFlash 給 SelectQueryInfo 結構中添加了一個 MvccQueryInfo 的結構,里面會帶上查詢的 key-ranges 信息。DeltaTree 在處理的時候,首先會根據 key-ranges 做 segment 級別的過濾。另外,也會從 DAGRequest 中將查詢的 Filter 轉化為 RSFilter 的結構,并且在讀取數據時,利用 RSFilter,做 ColumnFile 中數據塊級別的過濾。
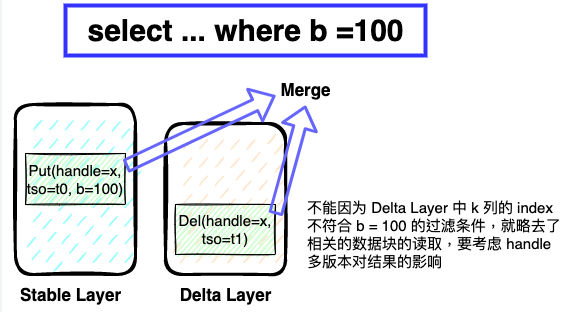
在 TiFlash 內做 Rough Set Filter,跟一般的 AP 數據庫不同點,主要在還需要考慮粗粒度索引對 MVCC 正確性的影響。比如表有三列 a、b 以及寫入的版本 tso,其中 a 是主鍵。在 t0 時刻寫入了一行 Insert (x, 100, t0),它在 Stable VS 的數據塊中。在 t1 時刻寫入了一個刪除標記 Delete(x, 0, t1),這個標記存在 Delta Layer 中。這時候來一個查詢 select * from T where b = 100,很顯然如果我們在 Stable Layer 和 Delta Layer 中都做索引過濾,那么 Stable 的數據塊可以被選中,而 Delta 的數據塊被過濾掉。這時候就會造成 (x, 100, t0) 這一行被錯誤地返回給上層,因為它的刪除標記被我們丟棄了。
因此 TiFlash Delta layer 的數據塊,只會應用 handle 列的索引。非 handle 列上的 Rough Set Index 主要應用于 Stable 數據塊的過濾。一般情況下 Stable 數據量占 90%+,因此整體的過濾效果還不錯。
代碼模塊
下面是 DeltaTree 引擎內各個模塊對應的代碼位置,讀者可以回憶一下前文,它們分別對應前文的哪一部分 ;)
# DeltaTree 引擎內各模塊對應的代碼位置
dbms/src/Storages/
├── Page # PageStorage
└── DeltaMerge
├── DeltaMergeStore.h # DeltaTree 引擎的定義
├── Segment.h # Segment
├── StableValueSpace.h # Stable Layer
├── Delta # Delta Layer
├── DeltaMerge.h # Stable 與 Delta merge 過程
├── File # Stable Layer 的存儲格式
├── DeltaTree.h, DeltaIndex.h # Delta Index
├── Index, Filter, FilterParser # Rough Set Filter
└── DMVersionFilterBlockInputStream.h # MVCC Filtering
小結
本篇文章主要介紹了 TiFlash 整體的模塊分層,以及在 TiDB 的 HTAP 場景下,存儲層 DeltaTree 引擎如何進行優化的思路。簡單介紹了 DeltaTree 內組件的構成和作用,但是略去了一些細節,比如 PageStorage 的內部實現,DeltaIndex 如何構建、應對更新,TiFlash 是如何接入 multi-Raft 等問題。
-
cpu
+關注
關注
68文章
10890瀏覽量
212425 -
存儲技術
+關注
關注
5文章
742瀏覽量
45832
發布評論請先 登錄
相關推薦
智能 整體廚房 解決 方案
LED調光引擎方案
分層優化低壓減載選址
基于Linux 的兩種分層存儲實現方案






 工商網監
工商網監
評論