 Python pacp模塊:自動識別文字中的省市區并將其繪圖
Python pacp模塊:自動識別文字中的省市區并將其繪圖
一個用于提取簡體中文字符串中省,市和區并能夠進行映射,檢驗和簡單繪圖的python模塊。
舉個例子:
["徐匯區虹漕路461號58號樓5樓", "泉州市洛江區萬安塘西工業區"]
↓ 轉換
|省 |市 |區 |地址 |
|上海市|上海市|徐匯區|虹漕路461號58號樓5樓 |
|福建省|泉州市|洛江區|萬安塘西工業區 |
注:“地址”列代表去除了省市區之后的具體地址
也可以將大段文本中所有提到的地址提取出來,并且自動將相鄰的存在所屬關系的地址歸并到一條記錄中(0.5.5版本新功能):
"分店位于徐匯區虹漕路461號58號樓5樓和泉州市洛江區萬安塘西工業區以及南京鼓樓區"
↓ 轉換
|省 |市 |區 |
|上海市|上海市|徐匯區|
|福建省|泉州市|洛江區|
|江蘇省|南京市|鼓樓區|
代碼目前僅僅支持python3
pip install cpca
注:cpca是chinese province city area的縮寫
如果覺得本模塊對你有用的話,施舍個star,謝謝。
常見安裝問題:
在 windows 上可能會出現類似如下問題
Building wheel for pyahocorasick (setup.py) ... error
先去下載 Microsoft Visual C++ Build Tools, 安裝完成后,再重新使用 pip install cpca 安裝,即可解決問題
開始使用
本模塊中最主要的方法是cpca.transform,該方法可以輸入任意的可迭代類型(如list,pandas的Series類型等),然后將其轉換為一個DataFrame,下面演示一個最為簡單的使用方法:
location_str = ["徐匯區虹漕路461號58號樓5樓", "泉州市洛江區萬安塘西工業區", "北京朝陽區北苑華貿城"]
import cpca
df = cpca.transform(location_str)
df
輸出的結果為(adcode為官方地址編碼):
省 市 區 地址 adcode
0 上海市 上海市 徐匯區 虹漕路461號58號樓5樓 310104
1 福建省 泉州市 洛江區 萬安塘西工業區 350504
2 北京市 市轄區 朝陽區 北苑華貿城 110105
如果你想獲知程序是從字符串的那個位置提取出省市區名的,可以添加一個pos_sensitive=True參數:
location_str = ["徐匯區虹漕路461號58號樓5樓", "泉州市洛江區萬安塘西工業區", "北京朝陽區北苑華貿城"]
import cpca
df = cpca.transform(location_str, pos_sensitive=True)
df
輸出如下:
省 市 區 地址 adcode 省_pos 市_pos 區_pos
0 上海市 上海市 徐匯區 虹漕路461號58號樓5樓 310104 -1 -1 0
1 福建省 泉州市 洛江區 萬安塘西工業區 350504 -1 0 3
2 北京市 市轄區 朝陽區 北苑華貿城 110105 -1 -1 0
從大段文本中提取多個地址(0.5.5版本新功能):
import cpca
df = cpca.transform_text_with_addrs("分店位于徐匯區虹漕路461號58號樓5樓和泉州市洛江區萬安塘西工業區以及南京鼓樓區")
df
結果為(注意 transform_text_with_addrs 獲得的數據,“地址”列都是空的):
省 市 區 地址 adcode
0 上海市 市轄區 徐匯區 310104
1 福建省 泉州市 洛江區 350504
2 江蘇省 南京市 鼓樓區 320106
transform_text_with_addrs 還支持和 transform 類似的 index, pos_sensitive 以及 umap 參數
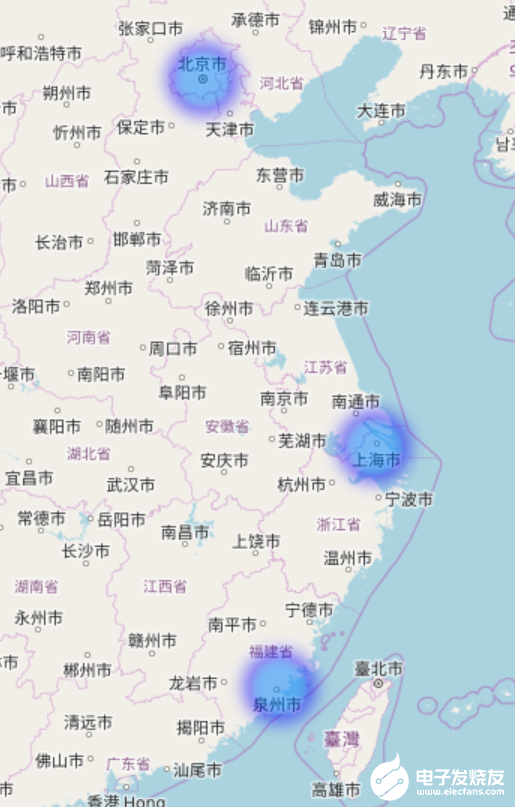
繪圖:
模塊中還自帶一些簡單繪圖工具,可以在地圖上將上面輸出的數據以熱力圖的形式畫出來.
這個工具依賴folium,為了減小本模塊的體積,所以并不會預裝這個依賴,在使用之前請使用pip install folium .
代碼如下:
import cpca
from cpca import drawer
df = cpca.transform_text_with_addrs("分店位于徐匯區虹漕路461號58號樓5樓和泉州市洛江區萬安塘西工業區以及南京鼓樓區")
drawer.draw_locations(df[cpca._ADCODE], "df.html")
審核編輯 黃昊宇
-
自動識別
+關注
關注
3文章
222瀏覽量
22856 -
python
+關注
關注
56文章
4802瀏覽量
84890
發布評論請先 登錄
相關推薦
垃圾短信?手機自動識別垃圾短信邏輯的分析

客流統計自動識別攝像頭

中國物品編碼中心一行蒞臨新大陸自動識別參觀調研
基于改進ResNet50網絡的自動駕駛場景天氣識別算法

MCU串口自動識別波特率原理分析
PCM9211的默認模式下,ADC和RXIN2( 光纖輸入)是自動識別的嗎,并且光纖具有輸入優先級?
智能化升級:機載無人機攝像頭如何自動識別目標?

光學識別字符是自動識別技術嗎
水位自動識別攝像機

多光譜明火自動識別攝像機

RFID軍標單裝自動識別銘牌 - 提升效率首選
自動識別水位預警攝像機

通道堵塞自動識別攝像機

護目鏡佩戴自動識別預警攝像機






 工商網監
工商網監
評論