 浪潮NF5468A5系統解析
浪潮NF5468A5系統解析
NF5468A5是浪潮推出的一款面向AI訓練和AI推理、視頻編解碼等多種應用場景的全能型GPU服務器,在4U空間內搭載2顆AMD EPYC處理器,支持多達8張雙寬加速卡。浪潮官網顯示,這款產品已經支持NVIDIA、AMD、Intel、寒武紀、燧原等多家業界主流AI加速卡。
本次拿到的樣機采用如下配置:
型號NF5468A5
CPU2*AMD 7543,32核2.8 GHz主頻,L3 Cache 256MB
內存512GB,16*32GB DDR4 3200ER
硬盤4*1.92TB NVME U.2
加速卡8*NVIDIA A100 GPU 1*NVIDIA T4 GPU 1*NVIDIA RTX3090顯卡 1*寒武紀MLU270-S4智能加速卡 1*浪潮M10A 視頻轉碼卡
電源4*2200W
接下來,筆者將從系統解析、性能測試這兩個方面對浪潮NF5468A5服務器進行測評。
1.NF5468A5系統解析
1.1 整體系統設計
浪潮NF5468M5 AI服務器采用了4U機架式機箱,高x寬x深為175mm x 478mm x 830mm。整體風格簡約、硬朗,不論做工、還是用料、細節,均彰顯出大廠品質。
前面板沿用浪潮一貫穩重的黑色,六邊形的格柵結構由金屬制成,可以將風扇高速旋轉產生的湍流風切割成平穩的平流風,從而更平穩的吹向服務器內部。前面板右上角,電源鍵下方是ID、Reset按鍵和系統狀態指示燈,前面板左上角則是VGA、兩個USB 3.0接口和管理接口。前面版的豐富接口,充分考慮了運維人員的工作場景,十分便捷。
從后窗來看,NF5468A5在4U空間內提供了8個全高全長雙寬PCIe x16的物理插槽,支持最新PCIe Gen4,雙向通信帶寬高達64GB/s,相比PCIe Gen3,功耗不變,但通信性能提升1倍。在此基礎上產品還提供了3個全高全長單寬x16物理槽位,可支持25G/100G/200G雙口光纖,或者千兆/萬兆RJ45網卡以及8/16端口12Gb/s RAID卡,可滿足客戶對網絡及存儲的要求。同時可支持1個OCP 3.0網卡專用插槽,支持熱插拔,將網卡更換時間從20分鐘縮短到1分鐘,能夠大幅提高運維效率。
NF5468A5支持4個電源模組,可以提供1600W~3000W功率的80 PLUS鉑金電源模塊,效率高達94%,可選3+1冗余或者2+2冗余,多種組合的冗余電源設計,充分考慮了不同配置AI服務器的負載情況,保障穩定性。
整個服務器采用非常緊湊的布局設計,總共分成四個功能區域,從前往后依次是:磁盤存儲區、系統散熱區、處理器+內存區、GPU+IO擴展區。
下面我們先看下CPU和內存。這臺樣機搭配了2顆AMD EPYC 7543處理器,核心數達到了32核心64線程,基準主頻2.8GHz,最大加速時鐘頻率3.7GHz,L3 Cache 256MB,功耗225W。另外,浪潮官網介紹NF5468A5可支持2顆AMD基于“Zen3”微架構內核的EPYC Milan-X處理器,最高128個核心256線程、1536MB L3 Cache 以及18 GT/s XGMI互連鏈路,CPU TDP最大支持280W。樣機配置了16根32GDDR4內存,同時可以看到服務器主板整齊排布了32個DDR4內存插槽,最大容量可達8TB,內存總帶寬750GB/s,支持RDIMM/LRDIMM等類型的內存條。NF5468A5強勁的處理器性能、巨大的內存容量和帶寬,特別適合AI計算、云計算、HPC以及企業各類業務的工作負載。
筆者手上的這臺NF5468A5,最吸引眼球的是本次測試樣機搭配了8顆NVIDIA A100 40G加速卡,從京東網上的報價看,8張A100的價格已經與一款中高端轎車相當,這究竟是一款什么樣的AI服務器,筆者將帶大家一探究竟。
我們來重點看一下NF5468A5的GPU模組。樣機搭配了8張NVIDIAA100 PCIE 40GB GPU加速卡,由于每張卡功耗高達250W,服務器也給GPU板卡配置了單獨供電線,保證GPU卡的穩定工作。為了滿足PCIE卡的高功率運行,我們看到NF5468A5在GPU板上專門設計了4個用于大電流通流的bus bar,據浪潮的工程師介紹,bus bar的通流能力可以達到2880W,這對于各類PCIE加速卡的支持是非常強勁的。
NF5468A5提供了對豐富外插卡的支持,針對A100這種全高全長的卡配置了專用支架,搭配尾部鎖片進行固定,這樣能增強產品在運輸過程中震動、跌落情況下的可靠性。我們翻開尾部鎖片,旋轉藍色旋鈕,就能非常順利的取下GPU進行更換,這種針對PCIE卡免工具的操作非常人性化。
1.2 系統散熱設計
從浪潮官網產品介紹中看到NF5468A5可以支持2顆280W CPU+8顆300W的GPU,在177mm的空間內浪潮究竟是如何實現的?筆者找浪潮工程師拿到了系統風流圖,從中可以看出,系統整體風道采用前進后出的方式,散熱風流主要從前面板的硬盤及下方開孔處進入系統。風流經系統風扇后通過導風罩的分配,一部分進入下層前排CPU和內存通道,一部分繼續往后吹;經過CPU和內存后的風及未被預熱的風大部分流向后方上面3U空間的GPU,小部分流向下面1U空間;最后經后面板流出系統。如此巧妙的風道設計和精準的風流控制,足見浪潮作為全球AI領導廠商深厚的設計功底。
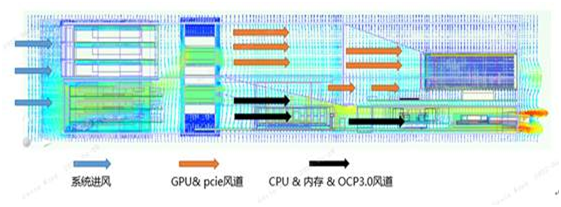
系統分離式風流設計
這款服務器將整機柜產品中“風扇墻”的設計理念搬到了4U機箱中,“風扇墻”一共由6組可以單獨維護的子風扇模組組成,風扇后部搭配了流線型設計的導風罩,覆蓋了從風扇到GPU中間的區域,但整個導風罩并沒有完全擋住風扇的出風區域,結合上面系統風流圖也證明是為實現CPU和GPU獨立風道的引流設計,避免風流的串擾,無論多“強悍”的CPU和GPU都可以馴服。
1.3 架構設計
筆者查找了海外網站相關浪潮產品的介紹資料,找到一張產品的拓撲圖,發現有別于傳統CPU-PCIE Switch-GPU的設計,浪潮產品采用CPU-GPU直連方式。跟浪潮工程師確認,送測的NF5468A5也采用類似設計。工程師介紹,由于省去了PCIE Switch,2顆CPU與GPU的通訊延遲能降低200~300ns,同時GPU到CPU的通信帶寬可以達到256GB/s,較GPU通過PCIESwitch只有1條與CPU PCIE通路比,帶寬提升4倍,這種極致的互聯架構設計,有助于提升GPU與CPU間數據通信的帶寬,有效降低數據的處理延遲。
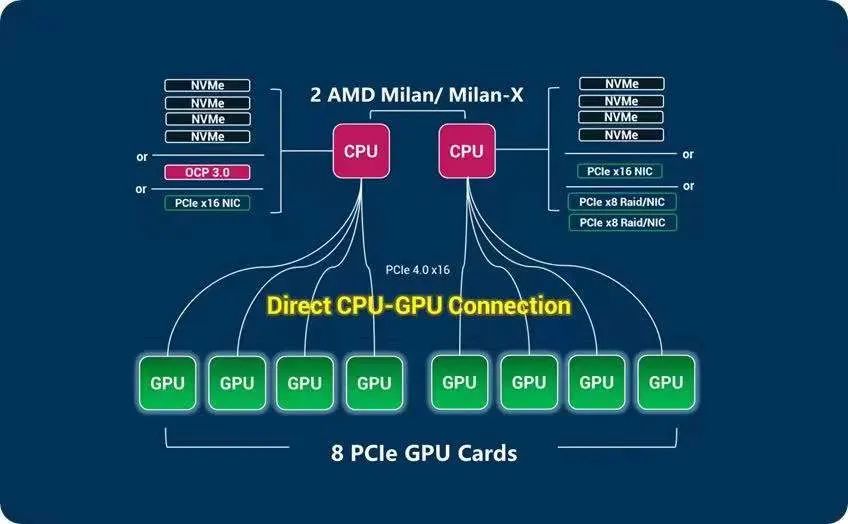
2. NF5468A5性能測評
2.1HPL測試
樣機搭配2顆AMDEPYC 7543處理器,這款處理器是32 核 64 線程,基準主頻2.8GHz,L3 Cache 256MB,最大加速時鐘頻率最高可達3.7GHz,功耗225W。為了能夠了解CPU實際性能,下面將采用HPL基準軟件進行測試。
在計算機基準測試軟件中,HPL是應用最廣泛的基準測試程序之一。通過使用高斯消元法對稠密線性方程組進行求解,HPL可以準確測試系統浮點計算指標。在每年全球超級計算機排名TOP500中,HPL測試性能是唯一的評價標準。
由于筆者拿到的設備是一臺未預裝任何軟件的裸金屬服務器,為了進行相關測試,首先在上面安裝了Ubuntu20.04操作系統。
然后用HPL軟件測試了系統的浮點運行能力。通過如下命令,將測試進程和CCD進行綁定。
# mpi_options=“--mca mpi_leave_pinned 1 --bind-to none --report-bindings --mca btl self,vader”
# mpi_options=“$mpi_options --map-by pprl3cache -x OMP_NUM_THREADS=4 -x OMP_PROC_BIND=TRUE -x OMP_PLACES=cores”
# mpirun $mpi_options -app 。/appfile_ccx
在運行之前,還需要設置核心運行在最高頻率,清除系統緩存,并開啟大頁內存等設置,保證獲得當前平臺最高性能。
echo 3 》 /proc/sys/vm/drop_caches
echo 1 》 /proc/sys/vm/compact_memory
echo 0 》 /proc/sys/kernel/numa_balancing
echo ‘always‘ 》 /sys/kernel/mm/transparent_hugepage/enabled
echo ‘always‘ 》 /sys/kernel/mm/transparent_hugepage/defrag sudo cpupower frequency-set -g performance
最終測試浮點計算速度為2.69 TFLOPS,根據當前AMD平臺理論浮點計算速度,計算效率達到93.74%。
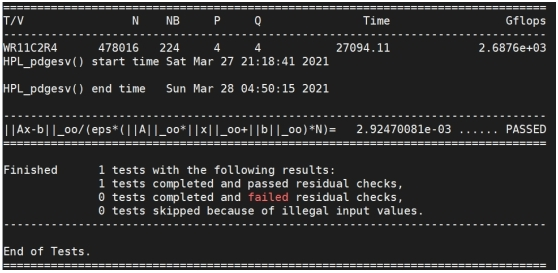
處理器浮點計算測試結果
2.2 內存帶寬測試
我們用業界主流的測試軟件STREAM對NF5468A5的內存帶寬進行了測試,測試參數如下:
#Thread Binding Options for AMD EPYC 7742/7763 Processor $ export GOMP_CPU_AFFINITY=0-64:8 $ export OMP_NUM_THREADS=8
在運行前,清除系統緩存并且開啟透明大頁內存設置等,設置參數如下:
$ echo madvise | tee /sys/kernel/mm/transparent_hugepage/enabled $ echo madvise | tee /sys/kernel/mm/transparent_hugepage/defrag $ echo 3 》 /proc/sys/vm/drop_caches $ echo 1 》 /proc/sys/kernel/numa_balancing
通過以上編譯和運行過程中優化,STREAM測試結果為373 GB/s,根據當前平臺理論內存帶寬409.6 GB/s,實測內存帶寬效率達到91.1%。應該說,這個效率非常高了。
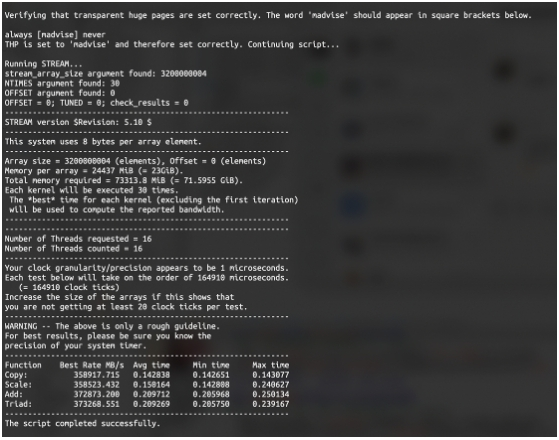
內存帶寬測試結果
2.3 訓練性能測試
下面我們來測試NF5468A5的AI訓練性能。樣機配置8張NVIDIAA100 PCIE 40GB GPU,這款GPU采用Ampere架構,基于7nm制造工藝,包含了超過540億個晶體管,擁有6912個CUDA核心,搭載了40GBHBM2內存,具備1.6TB/s的內存帶寬,FP64性能9.7 TFLOPS,FP32性能19.5TFLOPS,FP16性能312 TFLOPS。
筆者從github網站上的公共倉庫https://github.com/mlcommons/training_results_v1.0中下載了MLPerf Training V1.0代碼,并使用這套代碼按照以下測試步驟在NF5468A5上訓練ResNet50模型。MLPerf是一套衡量機器學習系統性能的權威標準,將在標準目標下訓練或推理機器學習模型的時間,作為一套系統性能的測量標準。MLPerf由圖靈獎得主大衛·帕特森(David?Patterson)聯合谷歌、斯坦福、哈佛大學等單位共同成立,是國際上最有影響力的人工智能基準測試之一。ResNet50是計算機視覺領域中最經典的圖像分類模型,廣泛應用于圖像識別、自動駕駛等場景。
MLPerf代碼提供了容器配置文件,我們可以很方便的通過配置文件在自己的服務器設備上創建鏡像環境,鏡像中包含cuda、cudnn、nccl、mxnet等上層組件。但是在運行容器之前,還需要在Host OS中安裝NVIDIA GPU Driver、docker、nvidia-docker這些基礎軟件。
首先,筆者參考https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html#runfile 教程在Ubuntu20.04操作系統中下載并安裝了R470.82.01版本的驅動;然后按照https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker 教程安裝docker和nvidia-docker。
通過以下命令構建容器鏡像:
$ cd ~/training_results_v1.0/NVIDIA/benchmarks/resnet/implementations /mxnet $ docker build -t mlperf1.0-nvidia:image_classification 。
在測試之前,通過在nf5468a5_cxx.sh文中添加以下內容綁定核心與進程,最大化的利用系統中的計算資源,達到良好的負載均衡,保證獲得最優的性能結果。
bind_cpu_cores=([0]=“48-63,176-191”[1]=“32-47,160-175” [2]=“16-31,144-159” [3]=“0-15,128-143” [4]=“112-127,240-254” [5]=“96-111,224-239” [6]=“80-95,208-223” [7]=“64-79,192-207”) bind_mem=([0]=“3” [1]=“2” [2]=“1” [3]=“0” [4]=“7” [5]=“6” [6]=“5” [7]=“4”)
測試環境準備完成,執行以下指令開始測試:
激活環境變量: $ source config_NF5468A5.sh $ export CONT=mlperf1.0-nvidia:image_classification $ export DATADIR=/home/data/mxnet_imagenet/ $ export LOGDIR=/home/resnet50/ 執行測試腳本: $ 。/run_with_docker.sh
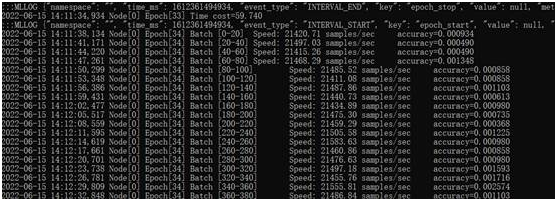
ResNet50訓練測試結果
測試結果為21486 images/sec,也就是35分鐘即可完成ResNet50模型的訓練。參考最近幾期MLPerf訓練榜單,搭載8張NVIDIAA100 40G GPU卡的服務器的最好成績是36.2分鐘。可以說,在同等GPU配置的服務器中,浪潮NF5468A5的ResNet50訓練性能是最好的。
2.4 推理性能測試
筆者也測試在目前推理場景中熱度最高的NVIDIA TeslaT4,這款精致的GPU卡只有75W,采用Turing架構, 在半高卡的尺寸內集成320個Turing Tensor Core和2560個Turing CUDA Core,配備16GB GDDR6,支持FP32/FP16/INT8/INT4等多種精度的運算,FP16的峰值性能為65T,INT8為130T,INT4為260T。
推理性能測試同樣使用了MLPerf測試工具,本次測試是基于MLPerf Inference V1.0.復用了訓練測試時使用的OS、docker、nvidia-docker等基礎軟件環境。
我們在NF5468A5搭載1張NVIDIA T4 GPU,使用github網站上的公開代碼https://github.com/mlcommons/inference_results_v1.0,按照如下步驟測試了ResNet50模型的推理性能:
同訓練時一樣,首先要構建容器鏡像:
# unzip mlperf-inference-release.zip # cd /mlperf-inference-release/closed/Inspur # export MLPERF_SCRATCH_PATH=/home/inspur/data/data_mlperf/ # make prebuild (備注:prebuild后會自動進入容器實例)
然后執行以下指令開始測試:
sudo CUDA_VISIBLE_DEVICES=0make run RUN_ARGS=“--benchmark=resnet50 --scenarios=Offline --config_ver=default --test_mode=PerformanceOnly --fast”
在圖像分類應用場景中,使用ImageNet數據集,ResNet50測試結果是每秒處理5671.9 張圖片。我們了解到NVIDIA T4的ResNet50推理性能為每秒5000張圖片左右。應該說,在NF5468A5上測得的T4推理性能非常好了。
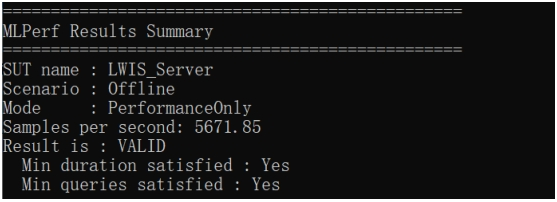
ResNet50推理測試結果
筆者也拿到了寒武紀MLU270-S4推理加速卡。MLU270-S4采用TSMC 16nm工藝制造,集成16GB DDR4 內存,支持ECC,同時兼容INT4和INT16運算,理論峰值分別達到256TOPS和64TOPS。
我們發現NF5468A5對寒武紀的板卡也做了很好的兼容性適配,BMC可以顯示MLU270-S4的資產信息,風扇轉速也根據MLU270-S4的功耗進行了調整,相比A100,能夠明顯感覺到風扇轉速主動降低了。不得不說,浪潮服務器的散熱控制做得很精細。
我們在NF5468A5上插了1張MLU270-S4,測試了Caffe框架下的ResNet18、PyTorch框架下的GoogleNet以及TensorFlow下的ResNet101v1.5、VGG16和InceptionV3這幾個模型的推理性能,在使用int8精度時,計算性能分別為每秒7440、5800、2400、1400和1000張。
筆者分析,浪潮NF5468A5在訓練和推理測試中能取得這么好的成績主要有三個原因:第一,ResNet50模型從算法上還是需要CPU進行一定的圖像預取和處理操作,本次送測的AMD 7543具備32核心2.8GHz主頻,有助于圖像在CPU端的預處理工作;第二,NF5468A5采用CPU和GPU直連設計,有效降低數據的處理延遲,同時單個CPU與GPU通信帶寬高達128GB/s;第三,NF5468A5可以支持NVME SSD作為數據盤,通過將多顆NVME SDD數據盤組建RAID,可以極大的提升磁盤IO能力,在AI這種需要頻繁讀取數據的場景中,能夠非常有效的避免因為IO短板帶來的性能瓶頸。
2.5 視頻編解碼性能測試
筆者在NF5468A5服務器上也評測了浪潮自研的M10A加速卡。
據浪潮官網介紹,M10A是一款面向AI場景優化設計的VPU(Video Processing Unit), VPU是一種全新的視頻處理核心引擎,將視頻處理功能做成ASIC芯片,具有硬件編碼、硬件解碼、硬件轉碼等視頻加速功能,可以減少服務器在視頻處理業務上的計算性能消耗和降低視頻傳輸對網絡帶寬的需求。
M10A在8W功耗下可以提供16路1080P30視頻的加速能力,相當于每路1080P視頻加速僅需0.5W。M10A針對H.265視頻格式壓縮算法進行了特殊優化,實測數據表明M10A的H.265編碼效果可以使得網絡帶寬利用率翻倍,同時計算CPU負荷最低可降至2%,適用于直播、短視頻、云游戲、視頻會議等場景。
在FFMPEG視頻框架下,我們直接用軟件SDK中的demo腳本,測試了M10A在不同視頻分辨率下的性能數據,如下是16路1080P全高清視頻實時轉碼的性能測試情況:
在測試的過程中,我們發現M10A VPU芯片內部是“多核”結構,這將進一步降低視頻處理延遲,提高多路視頻轉碼時的性能穩定性。
從測試結果看到,M10A進行16路1080P全高清視頻轉碼時,每路視頻轉碼性能都能達到33fps,達到了浪潮官方宣傳的性能。

M10A視頻轉碼性能測試結果
另外,我們還測試了4K超高清和720P高清分辨率下的M10A的性能數據,分別可以達到4K 120fps和720P 960fps,解碼、編碼和轉碼的性能都是一致的。
在我們跟視頻行業技術大咖的交流中了解到,一張M10A的視頻處理能力相當于一臺雙路服務器的性能,M10A具有高性能、低功耗的優點,這對視頻行業來說是一個非常高性價比的解決方案。
2.6 HASH性能測試
除了前面講到的幾張加速卡,筆者也嘗試了其他板卡,比如主流的消費級顯卡RTX3090等,發現NF5468A5都做了很好的適配工作。
RTX3090采用第2代NVIDIA RTX架構-NVIDIAAmpere架構,采用8納米工藝,擁有10496個CUDA核心,搭載了24 GB GDDR6X內存,384bit位寬。
下面,我們來看看浪潮5468A5搭載RTX3090顯卡在區塊鏈場景的性能。基于T-Rex這個知名的應用軟件,筆者對業界主流的哈希算法進行了性能測試。T-Rex不僅支持區塊鏈場景中最常用的ETHASH算法,也支持其他諸如BLAKE3、MTP等哈希算法。

ETHASH算法性能測試過程
針對每種HASH算法,我們使用了t-rex軟件的benchmark模型,在單個3090顯卡上進行測試,每次測試持續10分鐘時間,并記錄了最終的性能數據,如下表所示。
浪潮NF5468A5+單卡RTX3090 HASH算法測試
算法ETHASHETCHASHAUTOLYKOS2BLAKE3MTPMTP-TCROCTOPUS
性能108MH/s108MH/s232MH/s2.44GH/s7.23MH/s28.78MH/s103.07MH/s
算法KAWPOWPROGPOWPROGPOW-VEILPROGPOW-VERIBLOCKPROGPOWZFIROPOW/
性能55MH/s54.4MH/s54.85MH/s27.31MH/s54.37MH/s54.91MH/s/
其中ETHASH算法的單卡性能達到了108MH/s。
這在很大程度上得益于NF5468A5優秀的散熱設計。RTX3090的功耗高達350W,在區塊鏈場景,顯卡通常是7*24小時運行,因此對散熱的要求非常高。筆者監控了整個測試過程中的GPU功耗和溫度情況,發現在長達半天的測試過程中,雖然GPU功耗長期維持在330~340W之間,但是GPU的溫度一直維持在60℃左右,甚至在多卡同時運行時,GPU的溫度也能保持在60℃左右,可以看出NF5468A5的散熱設計做得相當不錯。
3. NF5468A5服務器測評總結
通過對產品外觀和內部設計的評測,我們看到,浪潮NF5468A5在產品設計上,存儲、計算、風扇、GPU擴展等各模塊簡潔明朗,尤其是巧妙的分區散熱設計有效實現CPU與GPU模組的分流,豐富的存儲+IO擴展性,同時人性化的設計以扎實的做工,也彰顯出浪潮對產品細節的嚴謹和大廠雄厚的設計實力。
在整體實際性能的綜合測試,得益于浪潮高效的產品架構,最大發揮CPU與GPU之間的通訊效能,處理器計算效率達到93.74%,實測內存帶寬373 GB/s,搭配8張A100訓練ResNet50模型得到每秒處理21486張圖片的驚人算力,在ImageNet數據集下進行ResNet50推理測試展現超出T4標稱13%的圖片處理能力,這臺算力猛獸全方位的表現,相信給筆者和大家都留下了深刻的印象。
此外,ETHASH算法單卡性能突破100MH/s;很好地支持寒武紀國產推理卡,輕松實現每秒處理圖片超7000張;搭載視頻轉碼卡M10A展示了480fps1080P視頻轉碼性能。浪潮NF5468A5還有很多意想不到的潛能,筆者期待進一步的發掘,給大家帶來更精彩的評測。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4740瀏覽量
128951 -
服務器
+關注
關注
12文章
9164瀏覽量
85429 -
AI
+關注
關注
87文章
30897瀏覽量
269113
原文標題:算力猛獸:浪潮NF5468A5 GPU服務器深度測評
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
韓國NF功放:高性能、高保真,提供不同音頻解決方案
解析汽車電子用晶體諧振器:DST1610A、DST210AC 與 DST310S
長擎安全操作系統24與浪潮信息HF/AS存儲系列成功兼容
plc協議解析網關是什么

ZWS云平臺應用(5)-raw數據解析


LTC4364HDE-2芯片在檢測電流>5A的情況下,出線SHDN不受控問題怎么解決?
【中心動態】 走進浪潮信息

浪潮信息推出業界首個支持50℃進液溫度的服務器
浪潮信息突破浸沒式液冷服務器設計極限 業界首個支持50℃進液溫度
浪潮信息服務器NF5180G7榮獲SPECjbb2015性能冠軍
AD5933 2K頻率測量10nF級別電容不準是為什么?
智邦國際與KeyarchOS完成浪潮信息澎湃技術認證






 工商網監
工商網監
評論