") MLPerf是邊緣AI推理的新行業(yè)基準(zhǔn)
MLPerf是邊緣AI推理的新行業(yè)基準(zhǔn)
最高額。翻牌。GFLOPS。AI 處理器供應(yīng)商以多種方式計算其架構(gòu)的最大推理性能。
這些數(shù)字還重要嗎?它們中的大多數(shù)是在實驗室類型的環(huán)境中生產(chǎn)的,理想的條件和工作負載允許被測設(shè)備 (SUT) 為營銷目的生成盡可能高的分數(shù)。另一方面,大多數(shù)工程師可能不太關(guān)心這些理論上的可能性。他們更關(guān)心技術(shù)如何影響推理設(shè)備的準(zhǔn)確性、吞吐量和/或延遲。
將計算元素與特定工作負載進行比較的行業(yè)標(biāo)準(zhǔn)基準(zhǔn)更加有用。例如,圖像分類工程師可以識別出多個滿足其性能要求的選項,然后根據(jù)功耗、成本等因素對其進行縮減。語音識別設(shè)計人員可以使用基準(zhǔn)測試結(jié)果來分析各種處理器和內(nèi)存組合,然后決定是否合成本地或云中的語音。
但 AI 和 ML 模型、開發(fā)框架和工具的快速引入使此類比較變得復(fù)雜。如圖 1 所示,AI 技術(shù)堆棧中越來越多的選項也意味著可用于判斷推理性能的排列呈指數(shù)級增長。那是在考慮可以針對給定系統(tǒng)架構(gòu)優(yōu)化模型和算法的所有方式之前。
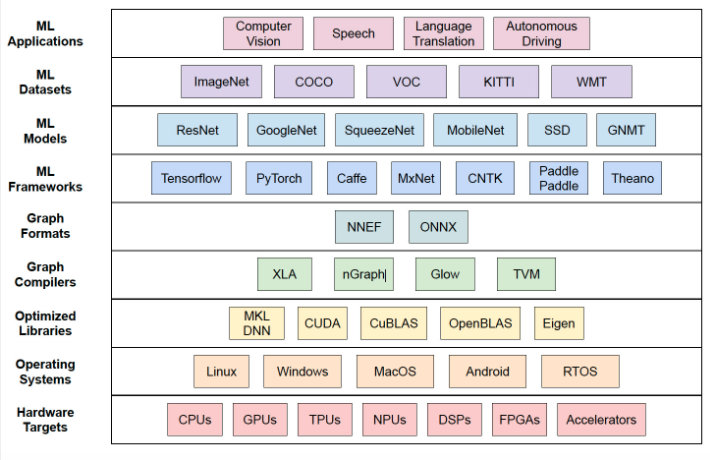
圖 1. AI 開發(fā)堆棧中越來越多的選項具有復(fù)雜的行業(yè)標(biāo)準(zhǔn)基準(zhǔn)測試。
不用說,開發(fā)這樣一個全面的基準(zhǔn)超出了大多數(shù)公司的能力或愿望。即使有能力完成這一壯舉,工程界真的會接受它作為“標(biāo)準(zhǔn)基準(zhǔn)”嗎?
MLPerf:更好的 AI 推理基準(zhǔn)
更廣泛地說,工業(yè)界和學(xué)術(shù)界在過去幾年中開發(fā)了幾個推理基準(zhǔn),但他們傾向于關(guān)注新生人工智能市場的更多利基領(lǐng)域。一些例子包括 EEMBC 用于嵌入式圖像分類和對象檢測的 MLMark,蘇黎世聯(lián)邦理工學(xué)院針對 Android 智能手機上的計算機視覺的 AI 基準(zhǔn),以及哈佛的 Fathom 基準(zhǔn),它強調(diào)各種神經(jīng)網(wǎng)絡(luò)的吞吐量,但不強調(diào)準(zhǔn)確性。
可以在 MLPerf 最近發(fā)布的 Inference v0.5 基準(zhǔn)測試中找到對 AI 推理環(huán)境的更完整評估。MLPerf Inference 是一個社區(qū)開發(fā)的測試套件,可用于測量 AI 硬件、軟件、系統(tǒng)和服務(wù)的推理性能。這是來自 30 多家公司的 200 多名工程師合作的結(jié)果。
正如您對任何基準(zhǔn)測試所期望的那樣,MLPerf Inference 定義了一套標(biāo)準(zhǔn)化的工作負載,這些工作負載被組織成用于圖像分類、對象檢測和機器翻譯用例的“任務(wù)”。每個任務(wù)都由與正在執(zhí)行的功能相關(guān)的 AI 模型和數(shù)據(jù)集組成,圖像分類任務(wù)支持 ResNet-50 和 MobileNet-v1 模型,對象檢測任務(wù)利用具有 ResNet34 或 MobileNet-v1 主干的 SSD 模型,以及使用 GNMT 模型的機器翻譯任務(wù)。
除了這些任務(wù)之外,MLPerf 推理開始偏離傳統(tǒng)基準(zhǔn)的規(guī)范。由于不同用例對準(zhǔn)確性、延遲、吞吐量和成本的重要性的權(quán)重不同,MLPerf Inference 通過根據(jù)移動設(shè)備、自動駕駛汽車、機器人和云這四個關(guān)鍵應(yīng)用領(lǐng)域的質(zhì)量目標(biāo)對推理性能進行分級來進行權(quán)衡。
為了在盡可能接近在這些應(yīng)用程序領(lǐng)域運行的真實系統(tǒng)的上下文中有效地對任務(wù)進行評分,MLPerf Inference 引入了負載生成器工具,該工具根據(jù)四種不同的場景生成查詢流量:
樣本大小為 1 的連續(xù)單流查詢,在移動設(shè)備中很常見
每個流具有多個樣本的連續(xù)多流查詢,如在延遲至關(guān)重要的自動駕駛汽車中發(fā)現(xiàn)的那樣
請求隨機到達的服務(wù)器查詢,例如在延遲也很重要的 Web 服務(wù)中
執(zhí)行批處理且吞吐量是一個突出考慮因素的離線查詢
Load Generator 以測試準(zhǔn)確性和吞吐量(性能)的模式提供這些場景。圖 2 描述了 SUT 如何接收來自負載生成器的請求,從而將數(shù)據(jù)集中的樣本加載到內(nèi)存中,運行基準(zhǔn)測試并將結(jié)果返回給負載生成器。然后,準(zhǔn)確性腳本會驗證結(jié)果。
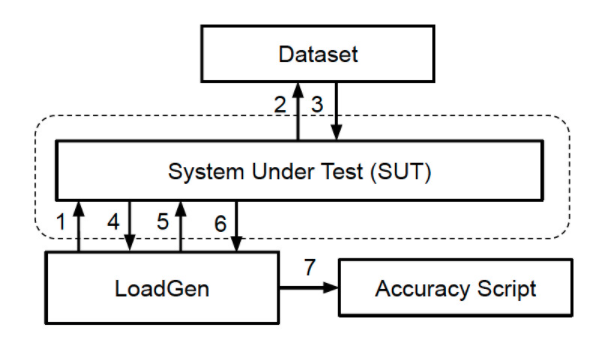
圖 2. MLPerf Inference 基準(zhǔn)測試依賴于負載生成器,該負載生成器根據(jù)許多實際場景查詢被測系統(tǒng) (SUT)。
作為基準(zhǔn)測試的一部分,每個 SUT 必須執(zhí)行最少數(shù)量的查詢以確保統(tǒng)計可信度。
提高靈活性
如前所述,人工智能技術(shù)市場中使用的各種框架和工具是任何推理基準(zhǔn)測試的關(guān)鍵挑戰(zhàn)。前面提到的另一個考慮因素是模型和算法的調(diào)整,以從 AI 推理系統(tǒng)中擠出最高的準(zhǔn)確性、吞吐量或最低的延遲。就后者而言,量化和圖像重塑等技術(shù)現(xiàn)在已成為常見做法。
MLPerf Inference 是語義級別的基準(zhǔn)測試,這意味著,雖然基準(zhǔn)測試提供了特定的工作負載(或一組工作負載)和執(zhí)行它的一般規(guī)則,但實際實施取決于執(zhí)行基準(zhǔn)測試的公司。公司可以優(yōu)化提供的參考模型,使用他們想要的工具鏈,并在他們選擇的硬件目標(biāo)上運行基準(zhǔn)測試,只要它們保持在一定的指導(dǎo)范圍內(nèi)。
然而,重要的是要注意,這并不意味著提交公司可以隨意使用 MLPerf 模型或數(shù)據(jù)集,并且仍然有資格獲得主要基準(zhǔn)。MLPerf 推理基準(zhǔn)分為兩個部分 - 封閉式和開放式 - 封閉式部分對可以使用哪些類型的優(yōu)化技術(shù)以及禁止使用其他優(yōu)化技術(shù)有更嚴格的要求。
要獲得封閉部門的資格,提交者必須使用提供的模型和數(shù)據(jù)集,但允許量化。為確保兼容性,封閉部門的參賽者不能使用經(jīng)過重新訓(xùn)練或修剪的模型,也不能使用經(jīng)過調(diào)整以具有基準(zhǔn)或數(shù)據(jù)集感知能力的緩存或網(wǎng)絡(luò)。
另一方面,開放部門旨在促進人工智能模型和算法的創(chuàng)新。提交給開放部門仍然需要執(zhí)行相同的任務(wù),但可以更改模型類型、重新訓(xùn)練和修剪其模型、使用緩存等。
盡管封閉部門聽起來很嚴格,但有 150 多個條目成功地獲得了 MLPerf Inference v0.5 發(fā)布的資格。圖 3 和圖 4 展示了參賽者使用的 AI 技術(shù)堆棧的多樣性,涵蓋了幾乎所有類型的處理器架構(gòu)和軟件框架,從 ONNX 和 PyTorch 到 TensorFlow、OpenVINO 和 Arm NN。
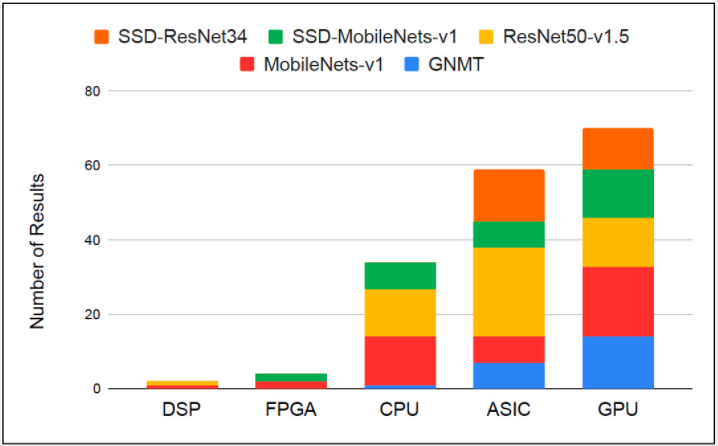
圖 3. DSP、FPGA、CPU、ASIC 和 GPU 均成功完成了 MLPerf Inference 封閉劃分要求。
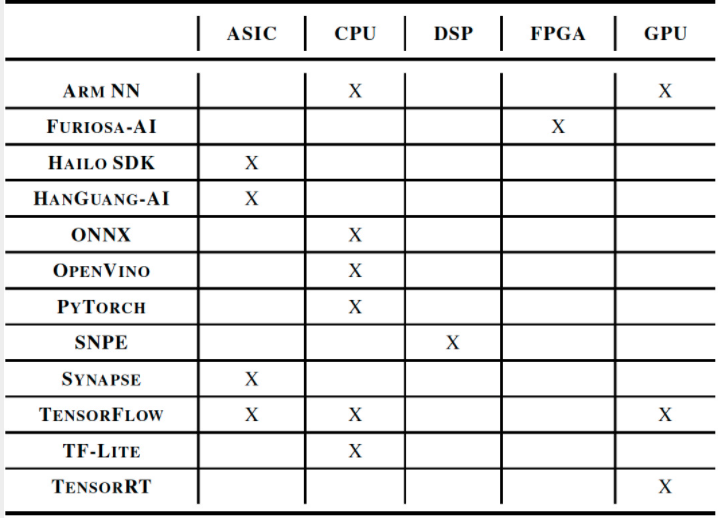
圖 4. AI 軟件開發(fā)框架(如 ONNX、PyTorch、TensorFlow、OpenVINO、Arm NN 等)用于開發(fā)符合封閉劃分基準(zhǔn)的 MLPerf 推理系統(tǒng)。
將猜測排除在評估之外
雖然 MLPerf Inference 的初始版本包含一組有限的模型和用例,但基準(zhǔn)測試套件是以模塊化、可擴展的方式構(gòu)建的。隨著技術(shù)和行業(yè)的發(fā)展,這將使 MLPerf 能夠擴展任務(wù)、模型和應(yīng)用領(lǐng)域,并且該組織已經(jīng)計劃這樣做。
最新的 AI 推理基準(zhǔn)顯然具有重要意義,因為它是目前可用的最接近真實世界 AI 推理性能的衡量標(biāo)準(zhǔn)。但隨著它的成熟和吸引更多的提交,它也將成為成功部署技術(shù)堆棧的晴雨表和新實施的試驗場。
為什么不讓技術(shù)自己說話,而不是處理特定于供應(yīng)商的數(shù)據(jù)表數(shù)字呢?畢竟,更少的猜測意味著更強大的解決方案和更快的上市時間。
審核編輯:郭婷
-
處理器
+關(guān)注
關(guān)注
68文章
19313瀏覽量
230070 -
嵌入式
+關(guān)注
關(guān)注
5085文章
19138瀏覽量
305778 -
AI
+關(guān)注
關(guān)注
87文章
30998瀏覽量
269328
發(fā)布評論請先 登錄
相關(guān)推薦
漢威科技集團推出Ai200邊緣計算網(wǎng)關(guān),引領(lǐng)智慧監(jiān)測新潮流
MLCommons推出AI基準(zhǔn)測試0.5版
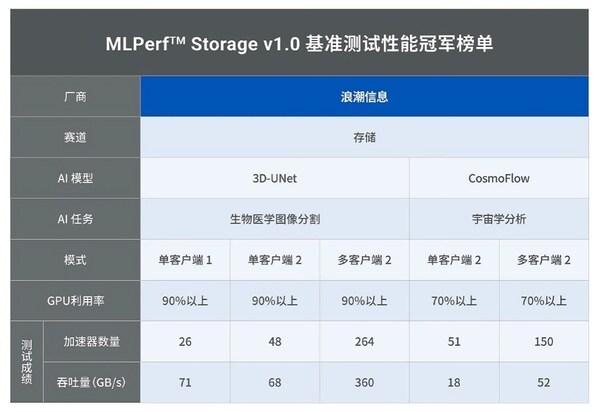
浪潮信息AS13000G7榮獲MLPerf? AI存儲基準(zhǔn)測試五項性能全球第一
什么是邊緣AI?邊緣AI的供電挑戰(zhàn)

智能邊緣放大招!英特爾舉辦2024網(wǎng)絡(luò)與邊緣計算行業(yè)大會,邊緣AI創(chuàng)新助力多元化應(yīng)用

如何基于OrangePi?AIpro開發(fā)AI推理應(yīng)用

ai邊緣盒子有哪些用途?ai視頻分析邊緣計算盒子詳解

邊緣側(cè)AI芯片提供商超星未來完成數(shù)億元 Pre-B輪融資
除英偉達Jetson系列外,AI邊緣計算盒子還能搭載哪些算力芯片
開發(fā)者手機 AI - 目標(biāo)識別 demo
UL Procyon AI 發(fā)布圖像生成基準(zhǔn)測試,基于Stable Diffusion
深度探討VLMs距離視覺演繹推理還有多遠?

基于EdgeX+OpenVINO?的邊緣智能融合網(wǎng)關(guān)YiFUSION實戰(zhàn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論